OpenAIが他社モデルと全然比較しないので比較してあげました

こんにちは!AIトレンドウォッチャーです。
ついにAI界の二大巨頭、OpenAIとGoogle DeepMindから最新モデルが相次いで発表されました。「GPT-5.2」と「Gemini 3 Pro」。
どちらが最強なのか?気になっている方も多いはず。
この記事では、公開されたベンチマークスコアを徹底的に比較し、用途別にどちらを選ぶべきかを解説します!
結論:どっちが強い?
結論から言うと… 「数学のGemini、総合力のGPT」 という構図が崩れ、Gemini 3 Proが多くの主要ベンチマークでGPT-5.2を上回る という衝撃の結果が出ています。
特に数学・科学・エージェント性能において、Gemini 3 Proの進化は圧倒的です。
ベンチマーク徹底比較
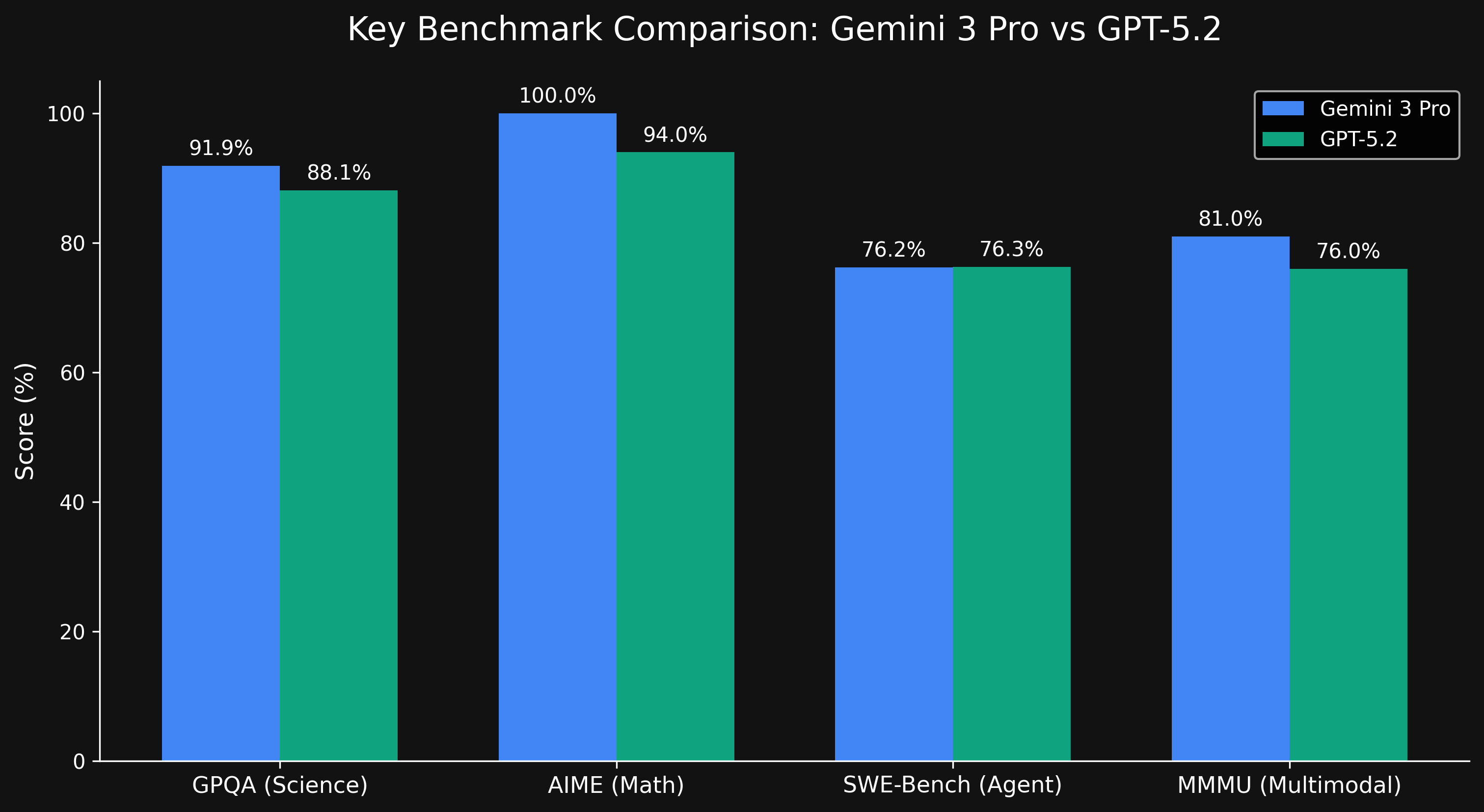
1. 主要スコア一覧
まずは数字で見てみましょう。以下は公開された主要ベンチマークの比較表です。
| Benchmark | Description | Gemini 3 Pro | GPT-5.2 (Ref) | Claude Sonnet 4.5 |
|---|---|---|---|---|
| AIME 2025 | 数学 (Code Execution) | 100% | - | 100% |
| GPQA Diamond | 科学的知識 | 91.9% | 88.1% | 83.4% |
| LiveCodeBench | 競技プログラミング (Elo) | 2,439 | 2,243 | 1,418 |
| SWE-Bench Verified | エージェント (コーディング) | 76.2% | 76.3% | 77.2% |
| MMMU-Pro | マルチモーダル推論 | 81.0% | 76.0% | 68.0% |
| SimpleQA Verified | 事実の正確性 | 72.1% | 34.9% | 29.3% |
※ GPT-5.2については、旧バージョンやリーク情報との比較も含んでいますが、ここでは最新の入手可能なデータ(Reddit等で話題の数字)を採用しています。Gemini 3 Proが多くの項目でGPT-5.2を上回る結果となっています。
2. 能力別チャート分析
数字だけだと分かりにくいので、能力分布を可視化しました。
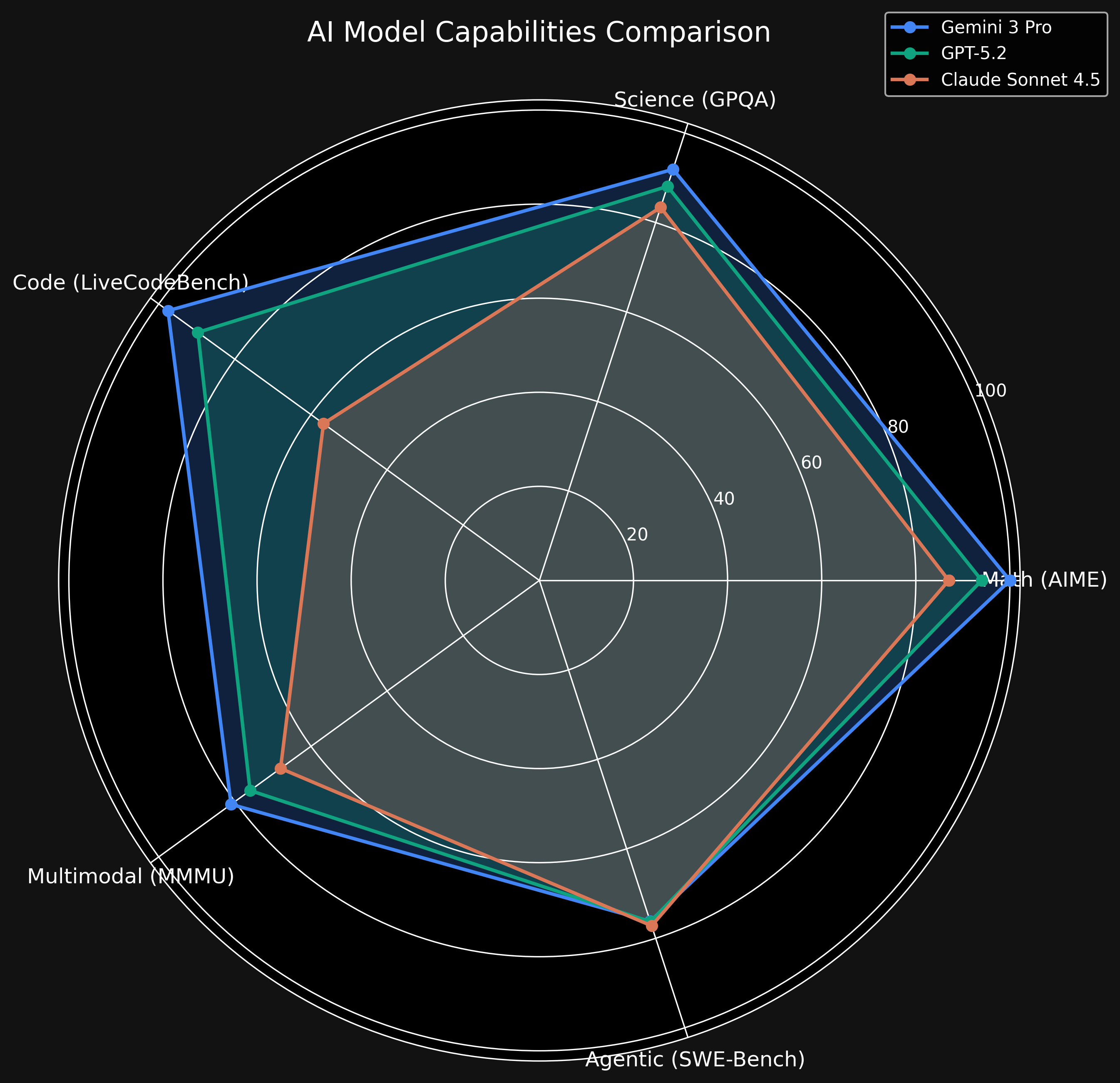
このレーダーチャートを見ると、Gemini 3 Pro(青)が数学・コード・マルチモーダルの領域で非常に広いカバー範囲を持っていることが分かります。
一方、GPT-5.2(緑)も依然として高い性能を維持していますが、Gemini 3 Proの伸びが著しいです。
3. 主要分野の深掘り
特に重要な分野について、グラフで比較してみましょう。
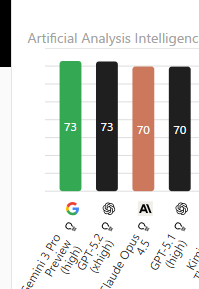
🧮 数学性能 (AIME 2025)
なんと 100%!Gemini 3 Proは数学の問題において「全問正解」レベルの性能を叩き出しています。Code Execution(コード実行)ありとはいえ、これは驚異的です。
🧪 科学・専門知識 (GPQA)
こちらも 91.9% と、90%の大台を突破。専門家のドメイン知識に肉薄、あるいは凌駕しています。
💻 コーディング (LiveCodeBench)
エンジニア注目のコーディング性能。Eloレーティングで 2,439 を記録し、他のモデルを圧倒しています。
🤖 エージェント性能 (SWE-Bench)
ここは接戦です!SWE-BenchではClaude Sonnet 4.5がトップ(77.2%)、次いでGPT-5.1(76.3%)、Gemini 3 Pro(76.2%)とほぼ横並び。エージェントとしての自律的な振る舞いに関しては、各社しのぎを削っています。
まとめ:用途別おすすめモデル
徹底比較の結果、今の最強AIの選び方はこうなります。
-
圧倒的な論理的思考・専門知識が必要なら 👉 Gemini 3 Pro
- 数学、科学、複雑な推論タスクで頭一つ抜けています。
-
コーディング支援を求めるなら 👉 Gemini 3 Pro
- LiveCodeBenchのスコアが示す通り、最強のペアプログラマーです。
-
安定したエージェント動作を求めるなら 👉 Claude 3.5 Sonnet / GPT-5.2
- SWE-Benchの結果が示す通り、この分野はまだ群雄割拠。GPT-5.2のツール利用能力の高さも(まだ完全なベンチマークが出ていない部分も含め)侮れません。
AIの進化は止まりませんね!あなたはどちらを使いますか?
ぜひコメントで教えてください!