概要
某データ分析会社による一流のデータサイエンティストを養成するのためのPython研修タイタニック編
オッス!!!
オラ@74kenshiro!!
いやー、やっぱぺぇそん(Python)むじぃなぁ!
重力3倍だとタイピングも一苦労だしこの記事作るのほんと骨が折れたぞぉ!!
ただ関数ってのはなかなかすげぇ機能だな!
あと、リスト内包表記もちょっとやってみたってばよ!
割とシンプルなやつだから俺みたいな下忍は一度試してみるってばよ!!
タイタニックのトレインデータをPython3標準モジュールで読込み、加工集計、CSVに出力してみた。
の皆さんお待ちかね第4弾です。
第1弾【Python3】第1回 タイタニックを標準モジュールだけで集計してみた。 ~データ読込み、None置換、CSV出力編~
・TSVデータを読込みする方法
・欠損値を置換する方法
・CSVへの出力の方法
・例として、for文、if文、dict.get()メソッドを使用したコードの書き方
第2弾【Python3】第2回 タイタニックを標準モジュールだけで集計してみた。 ~データ型操作練習編~
・リストから辞書を作成する方法
・辞書をCSVに出力する方法
第3弾【Python3】第3回 タイタニックを標準モジュールだけで集計してみた。 ~リスト集計編①~
・リストの要素数を知る方法
・二次元リストの要素同士を演算する方法
・リストの一部をCSVに出力する方法
目次
1.平均を出力する関数を作成する(小数点以下第2位まで)
2.中央値を出力する関数を作成する
3.標準偏差を出力する関数を作成する
4.最小値を出力する関数を作成する
5.最大値を出力する関数を作成する
6.作成した関数(平均、偏差、分散、標準偏差、最小値、最大値)をテストする。
7.各数値列の平均(小数点第2位まで),中央値, 最小値、最大値、標準偏差(小数点第2位まで)をCSVファイルに出力
この記事で分かること
pandasを使わずに、標準モジュールでの
・平均、中央値、標準偏差、最小値、最大値の求め方と関数の作り方
・if文を用い、Noneを無視する方法
・関数をつかったリストの作り方
・リストをCSVに出力する方法
・家族とタイタニック観た時の気まずい空気を圧倒的に打破する方法
データ概要
SIGNATE
【練習問題】タイタニックの生存予測
https://signate.jp/competitions/102/data
トレインデータ(TSV)
《データ説明》
| カラム | ヘッダ名称 | データ型 | 説明 |
|---|---|---|---|
| 0 | id | int | インデックスとして使用 |
| 1 | survived | boolean | 生還結果(1=生還, 0=死亡) |
| 2 | pclass | int | 客室のクラス(1,2,3の順に高級クラス) |
| 3 | sex | char | 性別 |
| 4 | age | int | 年齢 |
| 5 | sibsp | int | 乗船していた兄弟、配偶者の数 |
| 6 | parch | int | 乗船していた両親、子供の数 |
| 7 | fare | float | 運賃 |
| 8 | embarked | char | 乗船した港(S=Southampton, C=Cherbourg, Q=Queenstown) |
《データ一部抜粋》
各要素に一部欠損値有り
(下記一部抜粋)
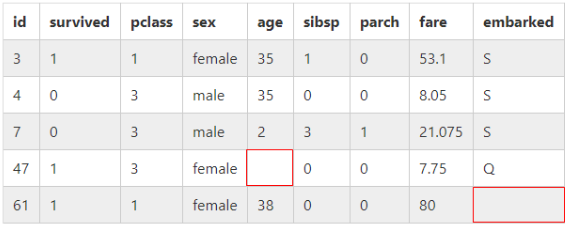
第1弾で作成した二次元リスト「list01new」を元にする。
中身は列名(ヘッダー)も含めた各行のリストとなっている。
第1弾で作成した「list01new」
list01 = []
list01new = []
# 1.データの読み込み
# 改行\nとタブ区切り\tを削除する
with open("train.tsv", mode="r") as f:
for line in f:
list01.append(line.rstrip('\n').split('\t'))
# 2.欠損値をNoneに置換する
# 「''」の場合は「None」、それ以外はそのままとし、list01newにappendする。
for line in list01:
new_line = []
for value in line:
if value == '':
value_after = None
else:
value_after = value
new_line.append(value_after)
list01new.append(new_line)
pprint.pprint(list01new[0:3])
print('--------' * 10)
none_list = [row for row in list01none if None in row]
pprint.pprint(none_list[7:9])
OUTPUT:「list01new」の中身
[['id','survived','pclass','sex','age','sibsp','parch','fare','embarked'],
['3', '1', '1', 'female', '35', '1', '0', '53.1', 'S'],
['4', '0', '3', 'male', '35', '0', '0', '8.05', 'S']]
--------------------------------------------------------------------------------
[['47', '1', '3', 'female', None, '0', '0', '7.75', 'Q'],
['61', '1', '1', 'female', '38', '0', '0', '80', None]]
1.平均を求める関数を作成する(小数点以下第2位まで)
平均とは観測値$x_1,x_2…,x_n$の和を観測値の総数$n$で割ったものである。
平均 \bar{x}=\frac{x_{1}+x_{2}+\cdots{x}_n}{n}=\frac1{n}\sum_{i=1}^nx_i
単純なコードはこうなる。
mean = sum(リスト)/ len(リスト)
data = [10,20,30,50,60,100,120]
mean = sum(data) / len(data)
print(mean)
=> 55.714285714285715
defで関数を作成してみる。
roundで小数点を第二位までに指定し、データが数字でもint型じゃない場合も踏まえ、int型に変換しておく。
def mean(data):
n = len(data)
# データが数字でもint型じゃない場合も踏まえ、ソートする前にint型に変換する。
intdata = [int(a) for a in data ]
mean = round(sum(intdata)/ n ,2)
return mean
# テスト
test_data = [10,20,30,50,60,100,120]
print('平均 =',mean(test_data))
=> 平均 = 55.71
2.中央値を求める関数を作成する
中央値$(Me)$:観測値$(x)$を小さい順に並べ、丁度真ん中に位置する値
観測値の総数$(n)$が奇数であれば、中央値は一つであるが、偶数の場合は中央値は2つとなるので、その2つの観測地の平均値が中央値となる。
中央値
\begin{align*} Me = \begin{cases} x_{\left(\frac{n+1}{2}\right)} & (n\,\text{が奇数}) & \\[5pt] \frac{x_{\left(\frac{n}{2}\right)}+x_{\left(\frac{n}{2}+1\right)}}{2} & (n\,\text{が偶数}) & \\[5pt] \end{cases} \end{align*}
総数が偶数の場合

総数が奇数の場合

data = [1,2,3,4,5,6]
n = len(data)
sortedata = sorted(data)
# リストの要素数nが偶数の場合
if n % 2 == 0:
m1 = int(n / 2)-1
m2 = int(n / 2)
m = (sortedata[m1] + sortedata[m2]) / 2
print('中央値 =',m)
# リストの要素数nが奇数の場合
else:
m = int((n +1) / 2)
m = sortedata[m -1]
print('中央値 =',m)
=> 中央値 = 3.5
def で関数化する。
データが数字でもint型じゃない場合も踏まえ、ソートする前にint型に変換する。
def median(data):
n = len(data)
# データが数字でもint型じゃない場合も踏まえ、ソートする前にint型に変換する。
intdata= [int(a) for a in data ]
sortedata = sorted(intdata)
if n % 2 == 0:
m1 = int(n / 2-1)
m2 = int(n / 2)
median = (sortedata[m1] + sortedata[m2]) / 2
return median
else:
m = int((n +1) / 2)
median = sortedata[m -1]
return median
# 奇数と偶数の文字型データでテスト
data_odd = ['odd','1','2','3','4','5','6','7','8','9']
data_even = ['even','1','2','3','4','5','6','7','8','9','10']
print('中央値 =',median(data_odd[1:]))
print('中央値 =',median(data_even[1:]))
=> 中央値 = 5
中央値 = 5.5
3.標準偏差を求める関数を作成する
標準偏差は、偏差、分散を求めることで、標準偏差を求めることが出来る。
偏差は平均値からの差でそれぞれプラスとマイナスが存在し、その散らばり具合の指標を標準偏差という。
ちなみに、分散以降の計算で、データが母数全てなのか、それとも抜き取った一部なのかにより、数式の分母が変わります。
今回作成するコードは、母数全てを前提とし、分母は$n$とします。
($n$と$n-1$の詳しい解説については長くなるので割愛します。気が向いたら書くかも。)
データが母数全ての場合 分散 s^2 = \frac{1}{n}\sum_{i=1}^n(x_i - \bar{x})^2
データが一部の場合 標本分散 s^2 = \frac{1}{n-1}\sum_{i=1}^n(x_i - \bar{x})^2
標準偏差 {s =\sqrt{s^2}
}
1.偏差(deviation)を出力する。
観測値と平均の差
偏差=観測値(x_i)-平均(\bar{x})
# 3行目のmeanは上記で作成した関数meanである
def deviation(data):
intdata = [int(a) for a in data]
deviation = [round(a - mean( data),2) for a in intdata]
return deviation
2.分散(variance)を出力する。
各偏差を二乗し$n$或いは($n-1$)で割ったもの
分散 = \frac{偏差^2}{n}
def variance(data):
n = len(data)
variance = [round(a ** 2 / n,2) for a in deviation(data)]
return variance
3.標準偏差(standard_deviation)を出力する。
def standard_deviation(data):
var_sum = sum(variance(data))
standard_deviation = round(var_sum ** 0.5,2)
return standard_deviation
4.最小値を出力する
def minimum(data):
intdata = [int(a) for a in data]
minimum = min(intdata)
return minimum
5.最大値を出力する
def maximum(data):
intdata = [int(a) for a in data]
maximum = max(intdata)
return maximum
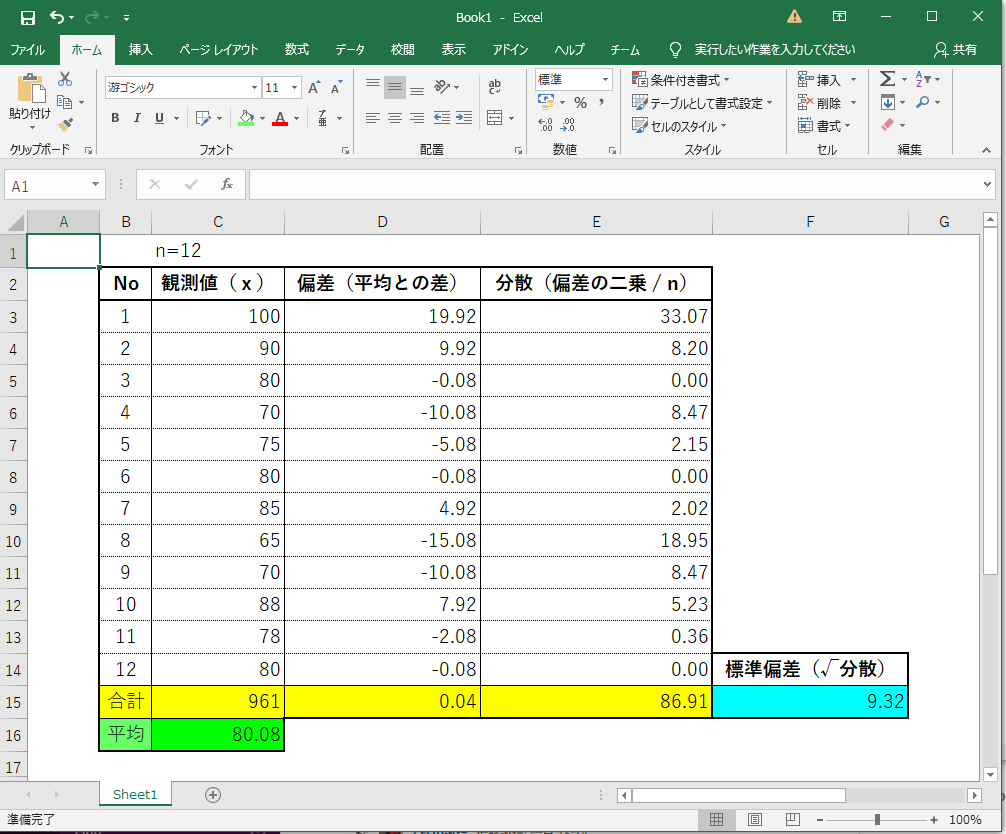
6.作成した関数(平均、偏差、分散、標準偏差、最小値、最大値)をテストしてする。
testdata = ['100','90','80','70','75','80','85','65','70','88','78','80']
# 平均の関数
def mean(data):
n = len(data)
intdata= [int(a) for a in data ]
mean=round(sum(intdata)/ n ,2)
return mean
print('平均 =',mean(testdata))
=>平均 = 80.08
# 偏差の関数
def deviation(data):
intdata = [int(a) for a in data]
deviation = [round(a - mean( data),2) for a in intdata]
return deviation
print('偏差',deviation(testdata))
=>偏差 [19.92, 9.92, -0.08, -10.08, -5.08, -0.08, 4.92, -15.08, -10.08, 7.92, -2.08, -0.08]
# 分散の関数
def variance(data):
n = len(data)
variance = [round(a ** 2 / n,2) for a in deviation(data)]
return variance
print('分散',variance(testdata))
=>分散 [33.07, 8.2, 0.0, 8.47, 2.15, 0.0, 2.02, 18.95, 8.47, 5.23, 0.36, 0.0]
# 標準偏差の関数
def standard_deviation(data):
var_sum = sum(variance(data))
standard_deviation = round(var_sum ** 0.5,2)
return standard_deviation
print('標準偏差 =',standard_deviation(testdata))
=>標準偏差 = 9.32
# 最小値の関数
def minimum(data):
intdata = [int(a) for a in data]
minimum = min(intdata)
return minimum
print('最小値 =',minimum(testdata))
=> 最小値 = 65
# 最大値の関数
def maximum(data):
intdata = [int(a) for a in data]
maximum = max(intdata)
return maximum
print('最大値 =',maximum(testdata))
=> 最大値 = 100
Excelの数式でも確認してみたが、同じ数字がでけた!!
7.各数値列 の平均(各小数点第2位まで),中央値, 最小値、最大値、標準偏差(各小数点第2位まで)をCSVファイルに出力
タイタニックデータの数値列は、id, survived, age, sibsp, parch, fareの6列である。
各列に一部Noneが含まれますが、今回は無視する形で処理をします。
列名,平均,中央値,最小値,最大値,標準偏差
id,xxx,yyy,zzz
survived,xxx,yyy,zzz,aaa,bbb
age,xxx,yyy,zzz,,aaa,bbb
sibsp,xxx,yyy,zzz,aaa,bbb
parch, xxx,yyy,zzz,aaa,bbb
fare,xxx,yyy,zzz,aaa,bbb
1.上記で作成した各関数のコードを一部変更。
①タイタニックデータは小数点が含まれるため、int型ではなくFloat型に変換。
②Noneを無視する処理
③対象の列にデータが存在しない場合は「データなし。」と出力
def mean(data):
new_list = []
# Noneの場合はスルーし、None以外のデータはnew_listにappend
for i in data:
if i == None:
continue
else:
new_list.append(i)
n = len(new_list)
# 要素数が0の場合は「データなし。」を出力
if n == 0:
none = "データなし。"
return none
else:
floatdata = [float(a) for a in new_list ]
mean = round(sum(floatdata)/ n ,2)
return mean
def median(data):
new_list = []
# Noneの場合はスルーし、None以外のデータはnew_listにappend
for i in data:
if i == None:
continue
else:
new_list.append(i)
n = len(new_list)
# 要素数が0の場合は「データなし。」を出力
if n == 0:
none = "データなし。"
return none
else:
# ソートする前にfloat型に変換する。
floatdata= [float(a) for a in new_list ]
sortedata = sorted(floatdata)
if n % 2 == 0:
m1 = int(n / 2-1)
m2 = int(n / 2)
median = (sortedata[m1] + sortedata[m2]) / 2
return median
else:
m = int((n +1) / 2)
median = sortedata[m -1]
return median
def deviation(data):
new_list = []
# Noneの場合はスルーし、None以外のデータはnew_listにappend
for i in data:
if i == None:
continue
else:
new_list.append(i)
n = len(new_list)
# 要素数が0の場合は「データなし。」を出力
if n == 0:
none = "データなし。"
return none
else:
floatdata = [float(a) for a in new_list]
deviation = [round(a - mean( data),2) for a in floatdata]
return deviation
def variance(data):
new_list = []
# Noneの場合はスルーし、None以外のデータはnew_listにappend
for i in data:
if i == None:
continue
else:
new_list.append(i)
n = len(new_list)
# 要素数が0の場合は「データなし。」を出力
if n == 0:
none = "データなし。"
return none
else:
variance = [round(a** 2 / n,2) for a in deviation(new_list)]
return variance
def standard_deviation(data):
new_list = []
# Noneの場合はスルーし、None以外のデータはnew_listにappend
for i in data:
if i == None:
continue
else:
new_list.append(i)
n = len(new_list)
# 要素数が0の場合は「データなし。」を出力
if n == 0:
none = "データなし。"
return none
else:
var_sum = sum(variance(new_list))
standard_deviation = round(var_sum ** 0.5,2)
return standard_deviation
def minimum(data):
new_list = []
# Noneの場合はスルーし、None以外のデータはnew_listにappend
for i in data:
if i == None:
continue
else:
new_list.append(i)
n = len(new_list)
# 要素数が0の場合は「データなし。」を出力
if n == 0:
none = "データなし。"
return none
else:
floatdata = [float(a) for a in new_list]
minimum = min(floatdata)
return minimum
def maximum(data):
new_list = []
# Noneの場合はスルーし、None以外のデータはnew_listにappend
for i in data:
if i == None:
continue
else:
new_list.append(i)
n = len(new_list)
# 要素数が0の場合は「データなし。」を出力
if n == 0:
none = "データなし。"
return none
else:
floatdata = [float(a) for a in new_list]
maximum = max(floatdata)
return maximum
2.各列のリストを作成する。
id, survived, age, sibsp, parch, fare
id=[]
for line in list01new:
a=[]
for line2 in line:
a.append(line2)
id.append(a[0])
print(id)
=> ['id', '3', '4', '7', '9', '11',,,,,]
survived=[]
for line in list01new:
a=[]
for line2 in line:
a.append(line2)
survived.append(a[1])
print(survived)
=> ['survived', '1', '0', '0', '1', '1',,,,]
age=[]
for line in list01new:
a=[]
for line2 in line:
a.append(line2)
age.append(a[4])
print(age)
=> ['age', '35', '35', '2', '14', '58',,,,]
sibsp=[]
for line in list01new:
a=[]
for line2 in line:
a.append(line2)
sibsp.append(a[5])
print(sibsp)
=> ['sibsp', '1', '0', '3', '1', '0',,,,]
parch=[]
for line in list01new:
a=[]
for line2 in line:
a.append(line2)
parch.append(a[6])
print(parch)
=> ['parch', '0', '0', '1', '0', '0',,,]
fare=[]
for line in list01new:
a=[]
for line2 in line:
a.append(line2)
fare.append(a[7])
print(fare)
=> ['fare', '53.1', '8.05', '21.075', '30.0708', '26.55',,,,]
3.出力する用の合算したリスト「summary_data」を作成する
datalist = [id,survived,age,sibsp,parch,fare]
summary_data = []
summary_data.append(['列名','平均値','中央値','最小値','最大値','標準偏差'])
for line in datalist:
a = [line[0],mean(line[1:]),median(line[1:]),minimum(line[1:]),maximum(line[1:]),standard_deviation(line[1:])]
summary_data.append(a)
pprint.pprint(summary_data)
=>
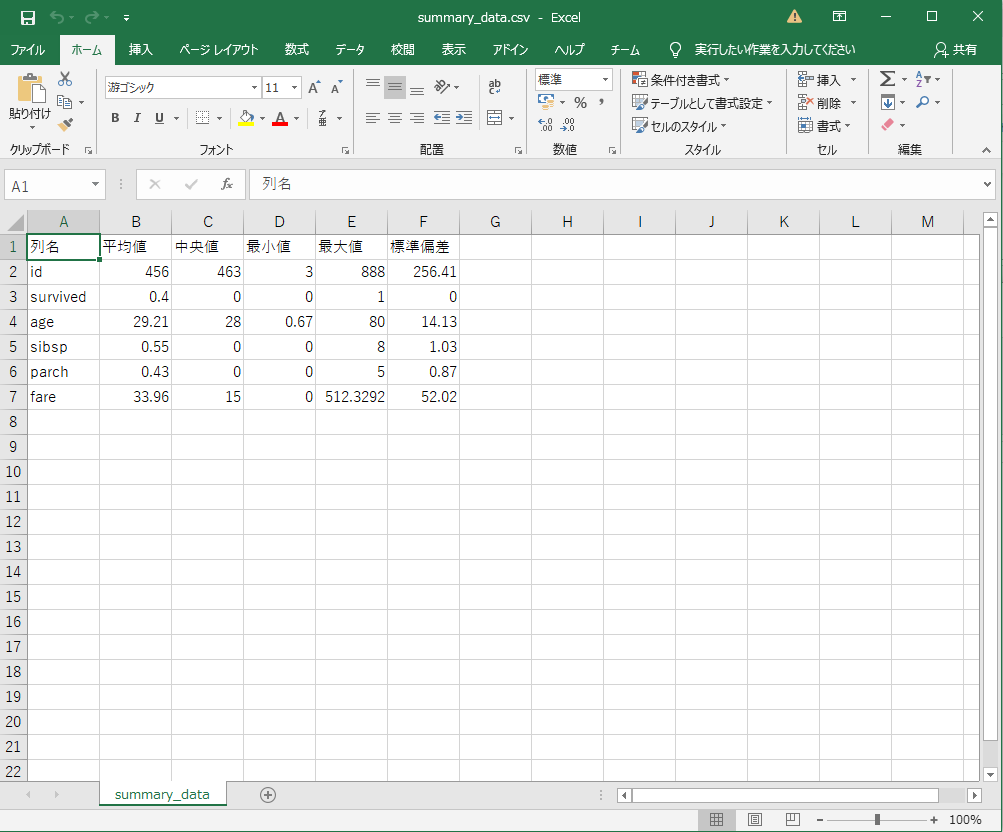
[['列名', '平均値', '中央値', '最小値', '最大値', '標準偏差'],
['id', 456.0, 463.0, 3.0, 888.0, 256.41],
['survived', 0.4, 0.0, 0.0, 1.0, 0.0],
['age', 29.21, 28.0, 0.67, 80.0, 14.13],
['sibsp', 0.55, 0.0, 0.0, 8.0, 1.03],
['parch', 0.43, 0.0, 0.0, 5.0, 0.87],
['fare', 33.96, 15.0, 0.0, 512.3292, 52.02]]
4.「summary_data」をCSVに出力する
with open(r"summary.csv", "w") as f:
for row in summary_data:
print(*row, sep=',', file=f)
Excelで確認してみる。 ドェケター!!
最後に
完璧なデータ分析などといったものは存在しない。
完璧なデータが存在しないようにね。
@74kenshiro (1988~2215年)
【お詫び】
今回、スペースの都合でお伝え出来なかった
・家族とタイタニック観た時の気まずい空気を圧倒的に打破する方法
は次回に繰り越しとさせて頂きます。
誠に申し訳ありませんが、皆様のご理解、ご協力のほど宜しくお願い致します。