概要
某データ分析会社による一流のデータサイエンティストを養成するのためのPython研修タイタニック編
オッス!!!!!
オラ@74kenshiro!
いやー最近ずっとぺぇそん(Python)の勉強してるんだけんどよぉ。
なかなかみんなについてけねぇんだ。
壁にはまるとエラーばっかりだしオラもう限界だぞぉ!
まっ!そんなこと言ってもどうにもなんねぇから今日もいっちょやるかっ!!
タイタニックのトレインデータをPython3標準モジュールで読込み、加工集計、CSVに出力してみた。
の皆さんお待ちかね第3弾です。
目次
1.行数の出力(ヘッダー除く)
2.列数の出力
3.先頭5行の出力(ヘッダー含む) CSVファイルに出力
4.末尾5行の出力(ヘッダー含む) TSVファイルに出力
5.各列の欠損している個数と欠損率(%表記、小数点第2位まで)をCSVファイルに出力
6.id, sibsp, parch, family 列のみのリスト「families」を作成し、そのリストの10~100行をCSVファイルに出力(ヘッダー含む)
この記事で分かること
pandasを使わずに、標準モジュールでの
・リストの要素数を知る方法
・二次元リストの要素同士を演算する方法
・リストの一部をCSVに出力する方法
・家族とタイタニック観た時の気まずい空気を圧倒的に打破する方法
データ概要
SIGNATE
【練習問題】タイタニックの生存予測
https://signate.jp/competitions/102/data
トレインデータ(TSV)
《データ説明》
| カラム | ヘッダ名称 | データ型 | 説明 |
|---|---|---|---|
| 0 | id | int | インデックスとして使用 |
| 1 | survived | boolean | 生還結果(1=生還, 0=死亡) |
| 2 | pclass | int | 客室のクラス(1,2,3の順に高級クラス) |
| 3 | sex | char | 性別 |
| 4 | age | int | 年齢 |
| 5 | sibsp | int | 乗船していた兄弟、配偶者の数 |
| 6 | parch | int | 乗船していた両親、子供の数 |
| 7 | fare | float | 運賃 |
| 8 | embarked | char | 乗船した港(S=Southampton, C=Cherbourg, Q=Queenstown) |
《データ一部抜粋》
各要素に一部欠損値有り
(下記一部抜粋)
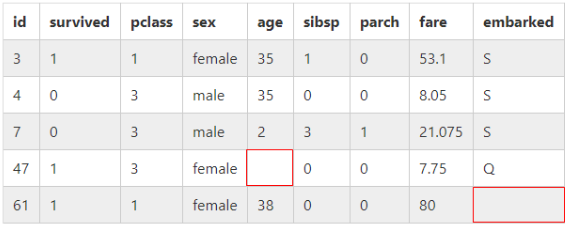
前回作成した二次元リスト「list01new」を元にする。
中身は列名(ヘッダー)も含めた各行のリストとなっている。
前回作成した「list01new」
list01 = []
list01new = []
# 1.データの読み込み
# 改行\nとタブ区切り\tを削除する
with open("train.tsv", mode="r") as f:
for line in f:
list01.append(line.rstrip('\n').split('\t'))
# 2.欠損値をNoneに置換する
# 「''」の場合は「None」、それ以外はそのままとし、list01newにappendする。
for line in list01:
new_line = []
for value in line:
if value == '':
value_after = None
else:
value_after = value
new_line.append(value_after)
list01new.append(new_line)
pprint.pprint(list01new[0:3])
print('--------' * 10)
none_list = [row for row in list01none if None in row]
pprint.pprint(none_list[7:9])
OUTPUT:「list01new」の中身
[['id','survived','pclass','sex','age','sibsp','parch','fare','embarked'],
['3', '1', '1', 'female', '35', '1', '0', '53.1', 'S'],
['4', '0', '3', 'male', '35', '0', '0', '8.05', 'S']]
--------------------------------------------------------------------------------
[['47', '1', '3', 'female', None, '0', '0', '7.75', 'Q'],
['61', '1', '1', 'female', '38', '0', '0', '80', None]]
1.行数の出力(ヘッダー除く)
1.リストの要素数を出力する場合は len()関数を使う。
print(len(リスト)) ➡ リストの要素数
今回の場合、1行目のヘッダーを除くので、インデックスを1番目以降と指定する。
# ヘッダーを除いた行数の出力
print(len(list01new[1:]))
=> 445
data = ['A','B','C','D']
print(data[:2])
=> ['A','B']
print(data[2:])
=> ['C','D']
print(data[1:2])
=> ['B']
2.列数の出力
1.これも同様にlen()関数だが、列数なので、ヘッダーの要素の数となる。
len()関数に「list01new」のインデックスにヘッダーをを指定する。
print(len(list01new[0]))
=> 9
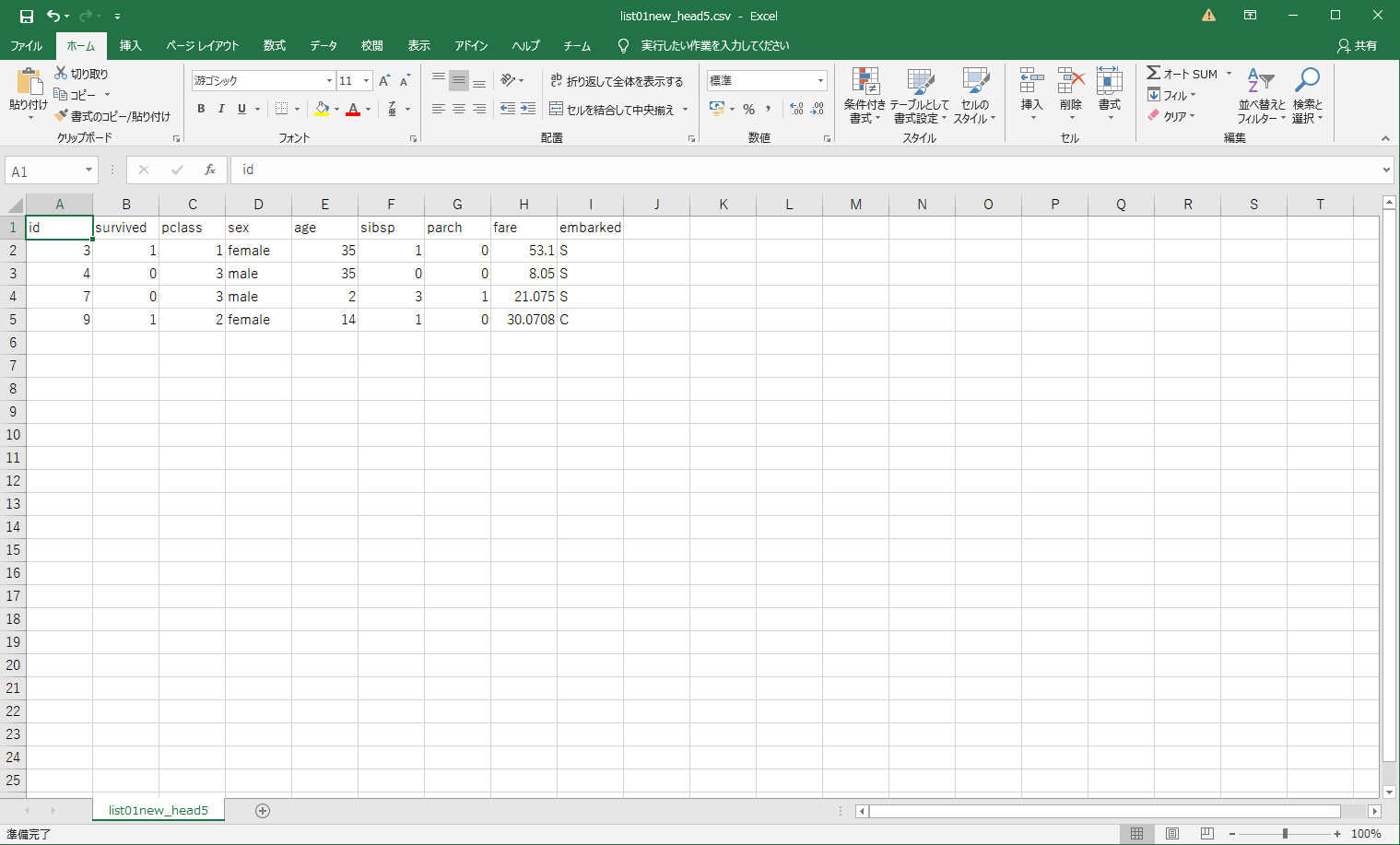
3.先頭5行の出力(ヘッダー含む) CSVファイルに出力
CSV出力でも同じように、インデックスの指定で事足りる。
先頭5行 ➡ リスト[:5]
with open(r"list01new_head5.csv", "w") as f:
for row in list01new[:5]:
print(*row, sep=',', file=f)
OUTPUT Excelで確認。無事出力出来た。
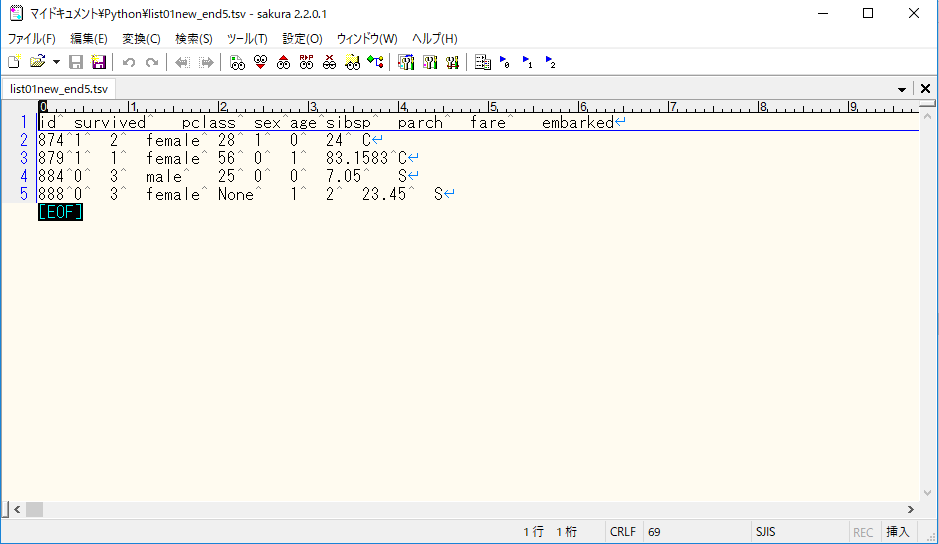
4.末尾5行の出力(ヘッダー含む) TSVファイルに出力
ヘッダーの出力と、末尾4行の出力を分ける。
TSVファイルへの出力はタブ区切りなので、「sep='\t'」となる。
CSV出力 →「sep=','」
TSV出力 →「sep='\t'」
with open(r"list01new_end5.tsv", "w") as f:
# 0行目のヘッダーのみ書き込み。
print(*list01new[0], sep='\t', file=f)
# 末尾から4行を指定して書き込み。
for row in list01new[-4:]:
print(*row, sep='\t', file=f)
OUTPUT サクラエディタで確認。 無事出力出来た。
5.各列の欠損している個数と欠損率(%表記、小数点第2位まで)をCSVファイルに出力
1.列ごとに計算する必要があるので、前回作成した辞書「dict01B」を使用する。
《前回作成した「dict01B」のおさらい》
各列ごとの値のリストを作成し、dict(zip())で辞書にする。
# 値のリスト
list01value = []
for i,key in enumerate(list01new[0]):
line_list = []
for j,value in enumerate(list01new[1:]):
a = list01new[1:][j][i]
line_list.append(a)
list01value.append(line_list)
pprint.pprint(list01value)
=>
[
['3','4','7','9',,,,
['1','0','0','1',,,,
['1','3','3','2',,,,
['female','male','male','female',,,,
['35','35','2','14',,,,
['1','0','3','1',,,,
['0','0','1','0',,,,
['53.1','8.05','21.075','30.0708',,,,
['S','S','S','C',,,,
]
dict01B = dict(zip(list01[0],list01value))
print(dict01B)
=>
{'age':['35','35','2','14',,,,],
'embarked': ['S','S','S','C',,,,],
'fare': ['53.1','8.05','21.075','30.0708',,,,],
'id': ['3','4','7','9',,,,],
'parch': ['0','0','1','0',,,,],
'pclass': ['1','3','3','2',,,,],
'sex': ['female','male','male','female',,,,],
'sibsp': ['1','0','3','1',,,,],
'survived': ['1','0','0','1',,,,]}
ーおさらい以上ー
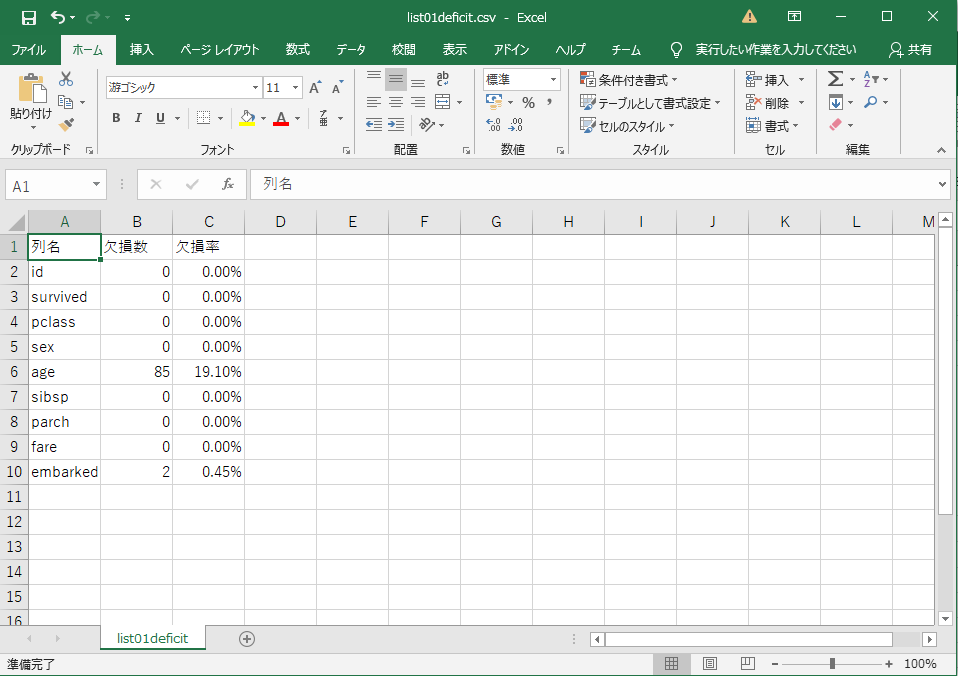
2.辞書「dict01B」を使い欠損率を計算したリストを作成 ➡「list01deficit」
list01deficit = []
for i,line in dict01B.items():
# kazu = 各列ごとのNoneの数をカウント
kazu = line.count(None)
# ritu = Noneの総数を要素数で割り、100を掛け、roundで小数点第3位を四捨五入
ritu = round((kazu/len(line)*100),2)
line2 = [i,kazu,str(ritu)+'%']
list01deficit.append(line2)
list01deficit.insert(0,['列名','欠損数','欠損率'])
pprint.pprint(list01deficit)
=>
[['列名', '欠損数', '欠損率'],
['id', 0, '0.0%'],
['survived', 0, '0.0%'],
['pclass', 0, '0.0%'],
['sex', 0, '0.0%'],
['age', 85, '19.1%'],
['sibsp', 0, '0.0%'],
['parch', 0, '0.0%'],
['fare', 0, '0.0%'],
['embarked', 2, '0.45%']]
3.作成した「list01deficit」をCSVに出力
with open(r"list01deficit.csv", "w") as f:
for row in list01deficit:
print(*row, sep=',', file=f)
OUTPUT Excelで確認。無事出力出来た。
6.id, sibsp, parch, family 列のみのリスト「families」を作成し、そのリストの10~100行をCSVファイルに出力(ヘッダー含む)
※familyはSibSp, Parchの和である。
今回は、各列の個別のリストを作成し、for文とzip() 関数で新たなリスト「families」を作成する
1.id, sibsp, parch,の各個別のリストを作成
《二次元リストから、列ごとにリストを作成するコードの例》
>>> data = [
... ['A','B','C','D'],
... ['1','2','3','4'],
... ['5','6','7','8']]
retsu = []
for line in data:
a=[]
for line2 in line:
a.append(line2)
retsu.append(a[2]) # このインデックスで指定する。
print(retsu)
=> ['C', '3', '7']
「list01new」の0番目の列「id」をリスト化してみる。
id = []
for line in list01new:
a = []
for line2 in line:
a.append(line2)
id.append(a[0])
print(id)
=>
['id', '3', '4', '7', '9', '11',,,,]
インデックスを変更してsibsp, parchも同様に作成する。
id = ['id', '3', '4', '7', '9', '11',,,,]
sibsp = ['sibsp', '1', '0', '3', '1', '0',,,,]
parch = ['parch', '0', '0', '1', '0', '0',,,,]
2.家族人数のリスト「family」を作成
「family = sibsp + parch」
要素同士の足し算となる。
今回は一つの二次元リストから作成するやり方と、二つのリストから作成するやり方を紹介します。
data = [['a','b','c'],[0,1,2],[3,4,5],[6,7,8],[9,10,11]]
data_sum = []
for line in data[1:]:
data_sum.append((line[1])+int(line[2]))
data_sum.insert(0,'bc_sum')
print(data_sum)
=>
['bc_sum', 3, 9, 15, 21]
上記のやり方を元にリスト「list01new」から作るコード
family = []
for line in list01new[1:]:
family.append(int(line[5])+int(line[6]))
family.insert(0,'family')
print(family)
=>
['family', 1, 0, 4, 1, 0,,,,,,]
二つのリスト「sibsp」と「parch」から作る場合
①enumerateでインデックスを引きだし、同じインデックスの要素を足していくコード
dataA = ['a',0,1,2]
dataB = ['b',3,4,5]
AB_sum = []
for i,line in enumerate(dataA[1:]):
AB_sum.append(int(line)+int(dataB[i+1]))
AB_sum.insert(0,'sum')
print(AB_sum)
=>
['sum', 3, 5, 7]
上記のやり方を元に二つのリスト「sibsp」と「parch」から作る場合
family = []
for i,line in enumerate(sibsp[1:]):
family.append(int(line)+int(parch[i+1]))
family.insert(0,'family')
print(family)
=>
['family', 1, 0, 4, 1, 0,,,,,,]
②zip()で一行ずつ抽出して作成しても可
dataA = ['a',0,1,2]
dataB = ['b',3,4,5]
AB_sum = []
for a,b in zip(dataA[1:],dataB[1:]):
AB_sum.append(int(a)+int(b))
AB_sum.insert(0,'sum')
print(AB_sum)
=>
['sum', 3, 5, 7]
3.4つのリストを合体させる。➡「families」
id, sibsp, parch, familyのリストが完成したので、0番目を列名、1番目以降を値のリストとなるようにする。
families = []
for a,b,c,d in zip(id,sibsp,parch,family):
families.append([a,b,c,d])
print(families)
=>
[
['id', 'sibsp', 'parch', 'family'],
['3', '1', '0', 1],
['4', '0', '0', 0],
['7', '3', '1', 4],
['9', '1', '0', 1],
,,,,,,
]
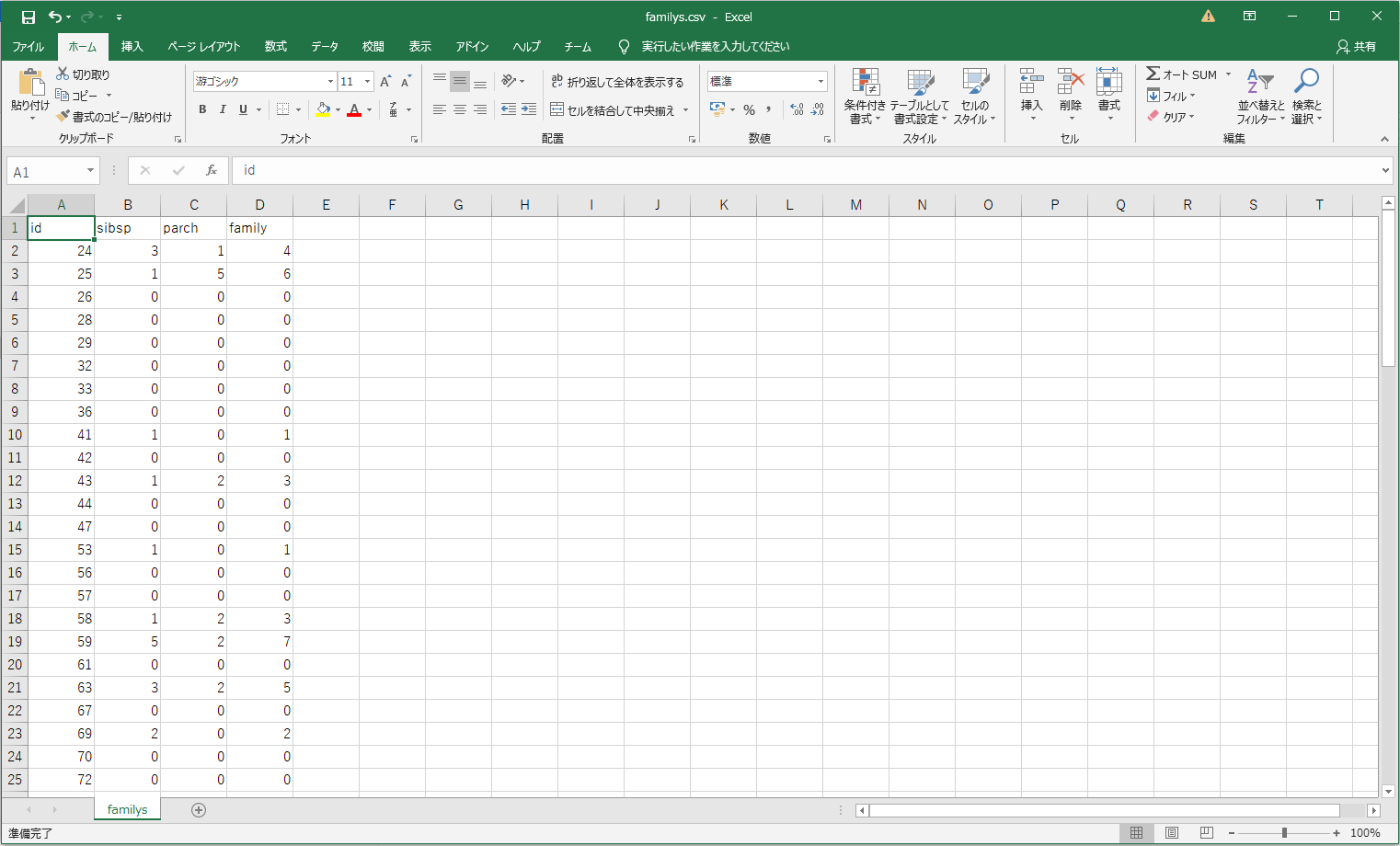
4.10~100行をCSVファイルに出力(ヘッダー含む)
最初に「families」のヘッダー(列名)のみ書き込み、以降10~100行目を書き込む。
with open(r"families.csv", "w") as f:
print(*families[0],sep=',',file = f)
for row in families[10:100]:
print(*row,sep=',',file = f)
OUTPUT Excelで確認。無事出力出来た。
最後に
この記事がイイと思ったら、イイね、フォロー頼むぞ!!!
コメントもじゃんじゃんくれよな!
この調子でぺぇそん(Python)完全マスターすっぞ!!
これからもオラに知識とモチベを分けてくれ!!
次回「ついに現れた初見殺し関数の定義!」
なんだか難しそうなやつでオラわくわくすっぞぉ!!
来週もぜってー読んでくれよな!!!!!
【お詫び】
今回、スペースの都合でお伝え出来なかった
・家族とタイタニック観た時の気まずい空気を圧倒的に打破する方法
は次回に繰り越しとさせて頂きます。
誠に申し訳ありませんが、皆様のご理解、ご協力のほど宜しくお願い致します。