概要#
某データ分析会社による一流のデータサイエンティストを養成するのためのPostgreSQL研修
よぉ、@74kenshiroだよい。
久々にSQLの話だよい。
今回は基本中の基本、今更聞けないスキーマとテーブルの作成方法だよい。
データベースはPostgreSQLだよい。
まだ慣れてない初心者はストックして何度も練習すると良いよい。
目次
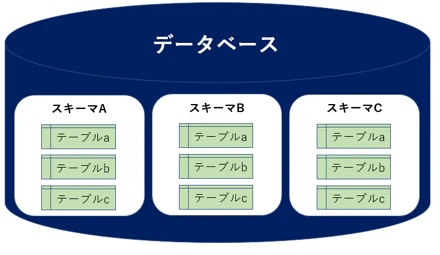
0.スキーマ、テーブルとは
1.スキーマを作る
2.空のテーブルを作る
3.空のテーブルにCSVデータを移す
4.データの確認をする
補足.データ型一覧
この記事で分かること##
スキーマの作成方法
テーブルの作成方法
CSVデータをテーブルに移す方法
PostgreSQL10.5のデータ型一覧
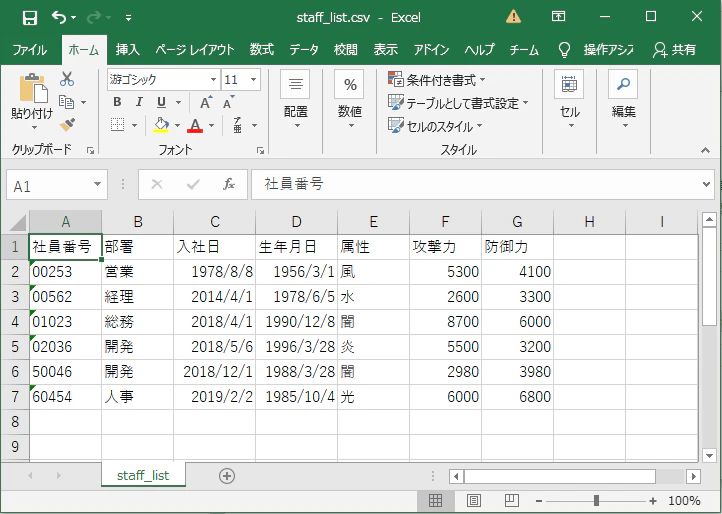
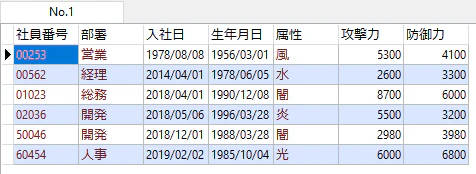
データ概要
CSVの元データ「staff_list」
(Excelで表示)
0.スキーマ、テーブルとは(ざっくり過ぎて逆にわかる説)
OSで例えると
スキーマ ➡ フォルダ
テーブル ➡ ファイル
スキーマの中にスキーマは作れない!!
同じテーブル名でもスキーマが違えば保存出来る!!やったね!!
こういう構造なのでテーブルを呼び出すときは
FROM スキーマ名. テーブル名 これマメな!!!
公式DOC10.5スキーマについて
公式DOC10.5テーブルについて
1.スキーマを作る
CREATE SCHEMA data;
2.カラムだけの空のテーブルを作る
予めExcel上でカラムとデータ型とカンマの表を作成するとコードの作成がラク。
データ型は主に文字型、日付け型、数値型があって、今回はVARCHAR,DATE,INT。
各データ型の詳細については記事の最後にまとめておくよい。

基本構文CREATE TABLE スキーマ名.テーブル名(カラム名 データ型,カラム名 データ型);
かっこ内にコピペするよい。
CREATE TABLE data.staff_list(
"社員番号" VARCHAR --文字型
, "部署" VARCHAR --文字型
, "入社日" DATE --日付け型
, "生年月日" DATE --日付け型
, "属性" VARCHAR --文字型
, "攻撃力" INT --整数型
, "防御力" INT --整数型
);
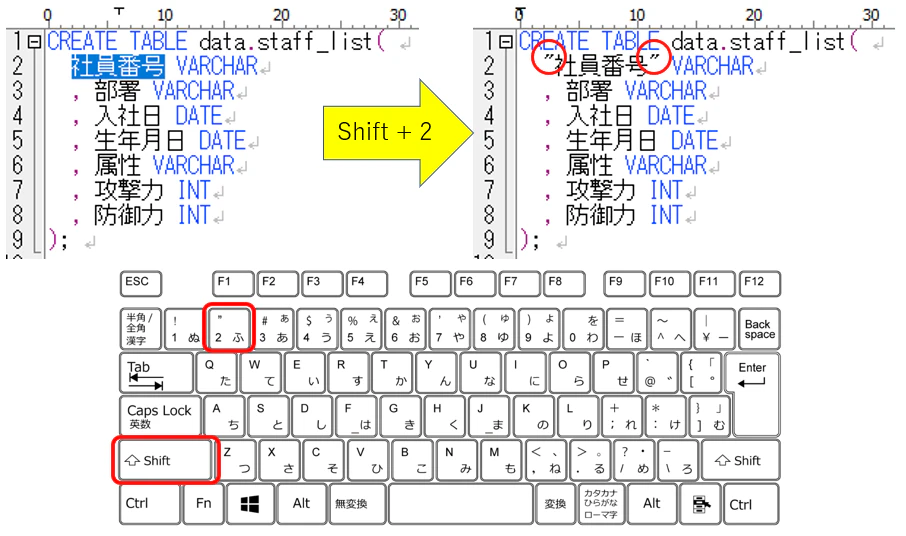
**THE 小ネタ:**マウスで選択した状態で、Shift + 2を入力するとダブルクォーテーションで囲めるよい(シングルクォーテーションも可能)。
空のテーブルが作成出来ているか確認するよい。
SELECT
*
FROM
data.staff_list;
空のテーブルの完成だよい。
(NULL)ってのはデータが存在しないって意味だよい。

3.空のテーブルにデータを移す
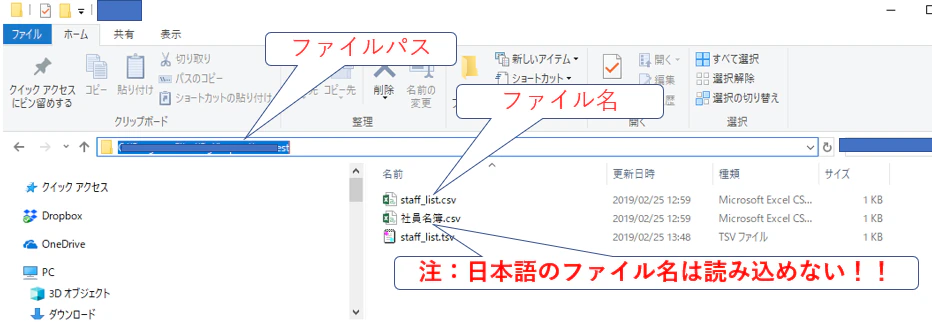
1.元データのファイルの種類をCSV UTF-8(コンマ区切り)(*.csv)に変換して保存しておくよい。

2.コピー構文を入力して、データを移すよい。
COPY スキーマ名.テーブル名
FROM
'ファイルパス¥ファイル名.csv' ENCODING 'utf8' CSV HEADER DELIMITER ',';
COPY スキーマ名.テーブル名
FROM
'ファイルパス¥ファイル名.tsv' ENCODING 'utf8' CSV HEADER DELIMITER E'\t';
ENCODING:ファイルがencoding_nameで符号化されていることを指定するよい。
'utf8':文字コードの指定(ファイルと同じにする)
CSV:ファイルの種類。と見せかけてTSV形式でもCSVと入力するよい!!!
HEADER:ファイルの1行名(ヘッダー)を無視する命令
DELIMITER:区切り文字の指定 CSVはカンマ区切りなので、’,’と入力。 TSVの場合はE'\t'と入力
テーブルを出力して、コピー出来ているか確認よい。
SELECT
*
FROM
data.staff_list;
出力結果 でけたよい。
4.データの確認をする
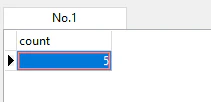
データのレコードが何千何万とある場合は、メモリをめっちゃ喰うからCOUNTで行数を確認するよい。
SELECT
COUNT (*)
FROM
data.staff_list;
出力結果
データがダブってないかも確認するよい。
SELECT
COUNT (*)
FROM
(SELECT DISTINCT * FROM data.staff_list) AS t1;
出力結果 さっきの全レコード数と同じならダブりデータは無いってことよい。
5.最後に
この記事がイイと思ったら素直にイイねするよい。
エンジニアとして最もやっちゃならねぇガン無視ストック、鉄の掟は破っちゃいけねぇよい。
補足:PostgreSQL10.5 データ型一覧
数値型
| 型名 | 格納サイズ | 説明 | 範囲 |
|---|---|---|---|
| smallint | 2バイト | 狭範囲の整数 | -32768から+32767 |
| integer、int | 4バイト | 典型的に使用する整数 | -2147483648から+2147483647 |
| bigint | 8バイト | 広範囲整数 | -9223372036854775808から+9223372036854775807 |
| decimal | 可変長 | ユーザ指定精度、正確 | 小数点前までは131072桁、小数点以降は16383桁 |
| numeric | 可変長 | ユーザ指定精度、正確 | 小数点前までは131072桁、小数点以降は16383桁 |
| real | 4バイト | 可変精度、不正確 | 6桁精度 |
| double precision | 8バイト | 可変精度、不正確 | 15桁精度 |
| smallserial | 2バイト | 狭範囲自動整数 | 1から32767 |
| serial | 4バイト | 自動増分整数 | 1から214748364 |
| bigserial | 8バイト | 広範囲自動増分整数 | 1から9223372036854775807 |
| money | 8バイト | 貨幣金額 | -92233720368547758.08 から +92233720368547758.07 |
日付/時刻データ型
|型名|格納サイズ|説明|最遠の過去|最遠の未来|精度|
|---|---|---|---|---|---|---|
|timestamp [ (p) ] [ without time zone ]|8 バイト|日付と時刻両方(時間帯なし)|4713 BC |294276 AD|1マイクロ秒
|timestamp [ (p) ] with time zone|8バイト|日付と時刻両方、時間帯付き|4713 BC|294276 AD|1マイクロ秒
|date|4バイト|日付(時刻なし)|4713 BC|5874897 AD|1日
|time [ (p) ] [ without time zone ]|8バイト|時刻(日付なし)|00:00:00|24:00:00|1マイクロ秒
|time [ (p) ] with time zone|12バイト|時刻(日付なし)、時間帯付き|00:00:00+1459|24:00:00-1459|1 マイクロ秒
|interval [ fields ] [ (p) ]|16バイト|時間間隔|-178000000年|178000000年|1マイクロ秒
文字型
| 型名 | 説明 |
|---|---|
| character varying(n), varchar(n) | 上限付き可変長 |
| character(n), char(n) | 空白で埋められた固定長 |
| text | 制限なし可変長 |