TL;DR
- 翻訳モデルからAIエージェントまでの進化を一気通貫で整理!
- Seq2Seqの限界 → Attention → Transformer → GPT → Prompt Engineering → AIエージェントへ進化
- 初心者にも分かる具体例付きで徹底解説!
導入:AIはどう進化してきたのか?
自然言語処理(NLP)の進化は、「翻訳」という課題から始まりました。
しかし、気付けば ChatGPTのように対話し、AIエージェントとして自律行動する世界 まで到達しています。
この記事では、自然言語処理の進化ストーリーを具体例と共に一気に整理します。
① 翻訳の難しさ:なぜ言語処理は難しいのか?
例えば日本語から英語の翻訳はどのように変更されるのでしょうか?
| 日本語 | 英語 |
|---|---|
| 私はりんごを食べる | I eat an apple |
- 単語順(SOV vs SVO)が違う
- 助詞・活用が複雑
- 文脈依存性が高い
👉 単純な「単語並べ替え」では到底翻訳できません。
② Seq2Seq:最初の試み(でも限界あり)
仕組み
-
Encoder
- 日本語の文をコンピュータが理解できる形(要約ベクトル)に変える人
- 言葉 → 数字 に変換する係です
-
要約ベクトル
- エンコーダーによって変換された[0.23, -0.76, 1.54, ...] みたいな数字の集まりが「要約ベクトル」です
- 文章の大事なポイントを、できるだけコンパクトにまとめた数字の集まりです。
-
Decoder
- エンコーダーが作った要約ベクトルを受け取って、今度はそれを「英語の文」に戻します。
- 数字 → 英語 に変換する係です。
具体例
「私は昨日りんごをおいしく食べました」
→ 圧縮すると → [0.23, -0.76, 1.54, ...]
👉 全情報を1個に押し込むのは無理があった
当時の課題
-
エンコーダーが「全部をきれいに数字にまとめる」のがそもそも難しい。
-
デコーダーが「数字からちゃんと英語に戻す」のも難しい。
-
特に長い文章になると、圧縮しすぎて大事な情報が消える(ボトルネック)。
③ Attention革命:情報は圧縮しなくていい!
発明
2015年、研究者たちはこう気づきます:
全部まとめなくても、必要な時に必要な単語を参照すればいい
具体例
「食べました」は「りんご」や「おいしく」と密接に関係
→ Attentionがこれを自動で重み付け
Query・Key・Valueの考え方
| 名称 | 意味 | 具体例 |
|---|---|---|
| Query | 知りたい内容 | 「何を食べた?」 |
| Key | 各単語の特徴 | 「りんご=食べ物」 |
| Value | 実際の情報 | 「りんごの意味情報」 |
Attention計算
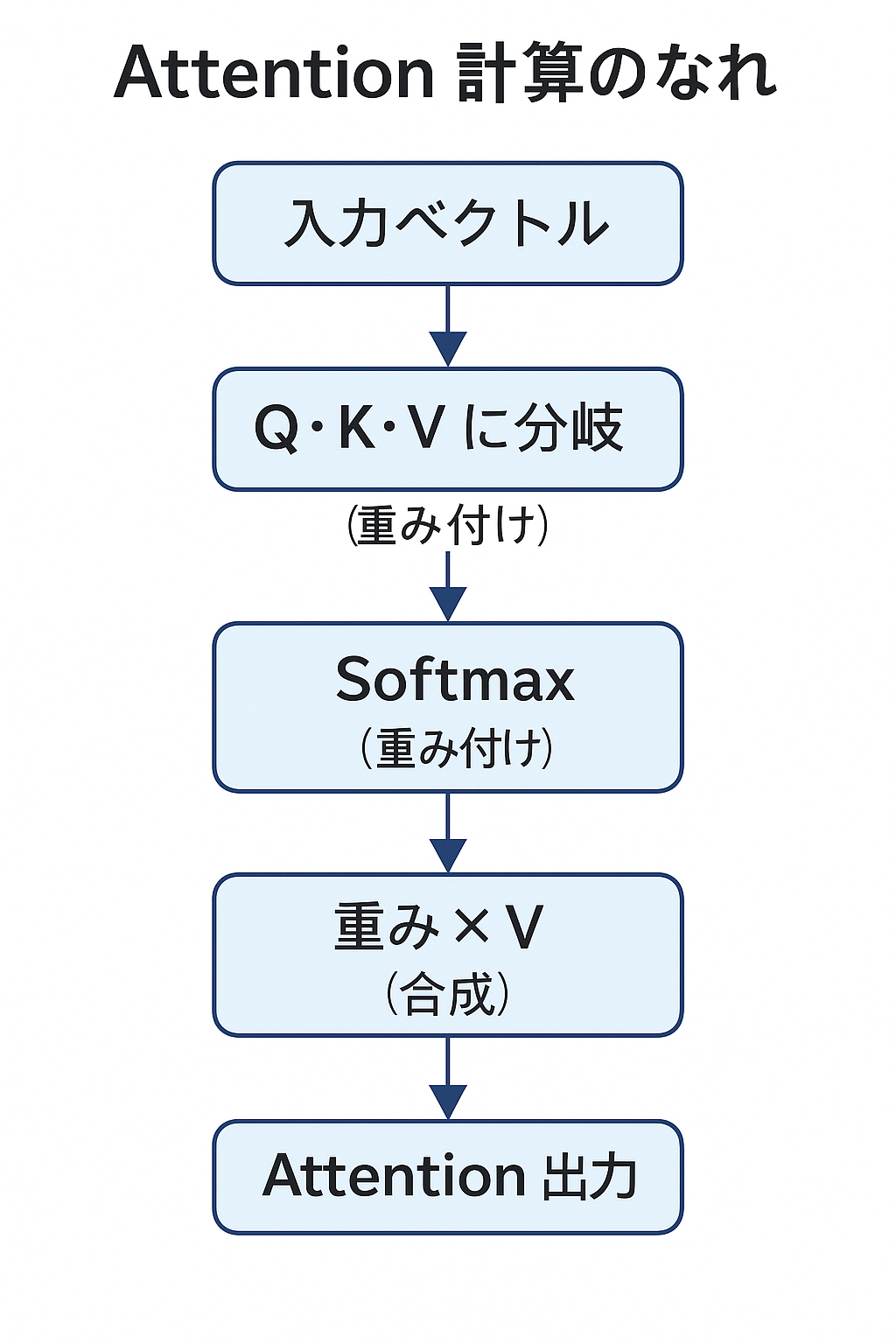
Attention計算の流れ
入力ベクトル
まず、各単語を「意味を持った数字のかたまり」に変えます。これが埋め込みベクトルです。
例えば:
- 「りんご」 →
[0.23, -0.76, 1.54, ...] - 「食べる」 →
[0.45, 0.12, -0.98, ...]
👉 これで、コンピュータが「単語の意味」を計算できるようになります。
Q・K・V に分岐
この埋め込みベクトルを、さらに3つに加工します。
この3つは、簡単に言うと 「会話での役割分担」 です。
| 略称 | 役割 | イメージ |
|---|---|---|
| Q (Query) | 質問役 | 「私は今、誰に注目すればいいの?」 |
| K (Key) | 自己紹介役 | 「私はこういう特徴を持っています」 |
| V (Value) | 情報役 | 「私が持っている具体的な情報はこれです」 |
👉 つまり:
- Qが探しにいく
- Kが特徴を提示する
- Vが情報を渡す
内積(Q × K^T)を計算
ここで、**Q(探したい)とK(どんな特徴か)**の内積を計算します。
👉 これは「どれくらい関係が深そうか?」を数字で出す作業です。
- 内積が大きい → すごく関連している
- 内積が小さい → あまり関係ない
例:
たとえば、「りんご」に注目している時(Q)に、他の単語のKと比べます:
| 相手 | 内積スコア | 意味 |
|---|---|---|
| 「果物」 | 高い | とても関係ありそう |
| 「昨日」 | 低い | そこまで関係ない |
👉 こうして、どの単語にどれだけ注意を向けるか(Attention)を決めます。
Softmax(重み付け)
スコアをSoftmaxで正規化し、全体の重み(注目度)を計算します。
→ 「りんごは80%注目、昨日は10%注目…」のように重みが決まります。
重み × V(合成)
計算した重みでValueを合成します。
→ 各単語の情報を、重要度に応じて加重平均するイメージ。
④ Transformer登場:Attentionが主人公に
2017年、Google論文「Attention is All You Need」でTransformer登場!
特徴
- 完全Attention設計
- 並列計算OK → 学習が高速化
- マルチヘッドAttentionで多角的に意味を理解
- 位置エンコーディングで順序情報も保持
Transformer構成図
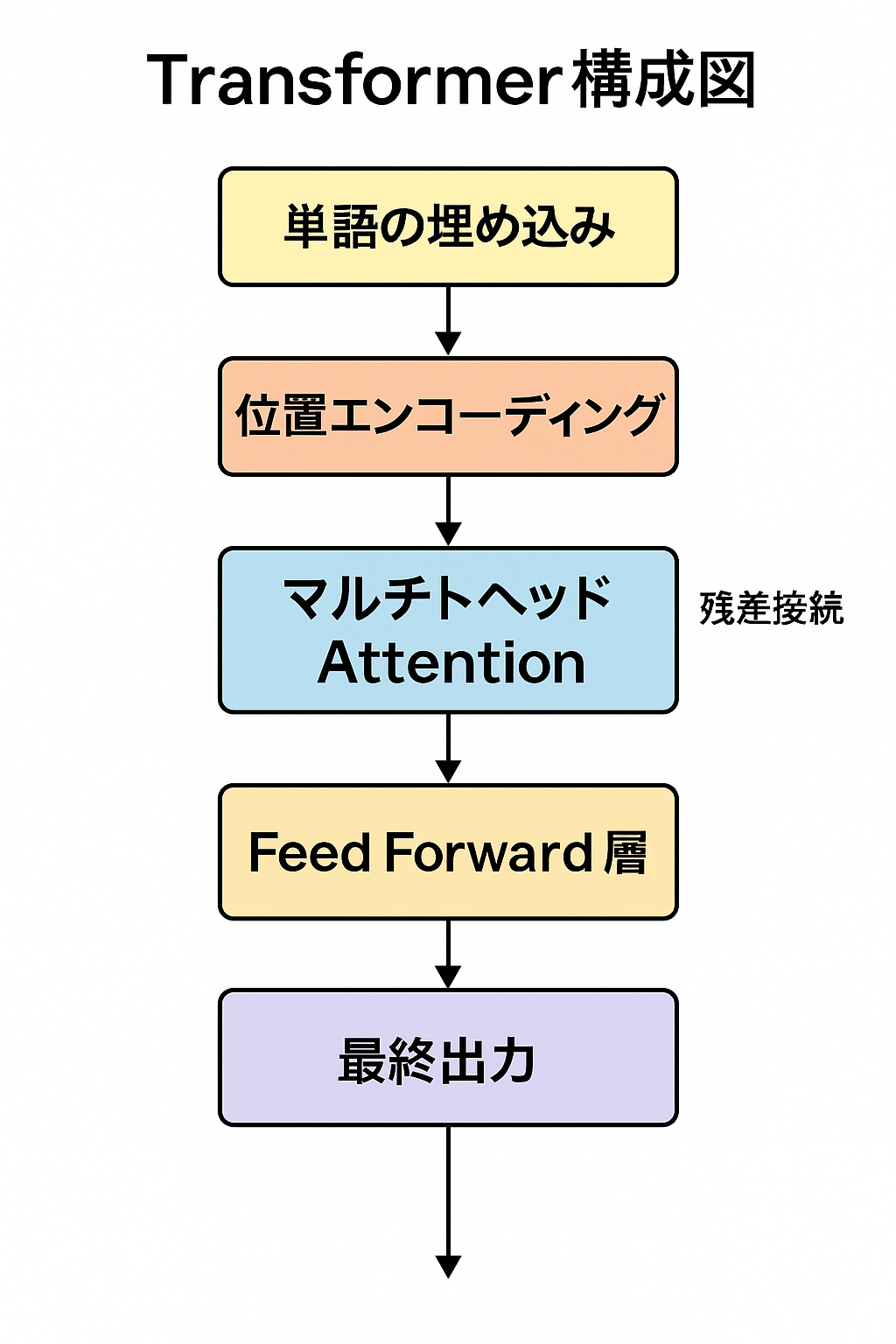
Transformer構成図の流れをざっくり整理
単語の埋め込み(Embedding)
まず文章中の各単語を、AIが扱いやすい「数値ベクトル」に変換します。
たとえば「りんご → [0.23, -0.76, 1.54, ...]」のように、意味を持った数字の配列にします。
位置エンコーディング(Positional Encoding)
単語が並ぶ順番も意味を持つので、位置情報も加えます。
「私は りんごを 食べる」と「食べる りんごを 私は」は同じ単語でも意味が違うため、順序を組み込むのがポイントです。
マルチヘッドAttention(Multi-Head Attention)
各単語が「他のどの単語に注目すべきか?」を計算します。
複数の視点(ヘッド)で同時に計算し、色々な関係性(文法・意味・文脈)を捕まえます。
※ここがTransformerの心臓部
残差接続(Residual Connection)
Attention結果と元の情報を合わせて次に渡します。
これで「情報の消えすぎ・壊れすぎ」を防ぎます(学習が安定)。
フィードフォワード層(Feed Forward)
Attentionの出力を少し加工して整理します。
「Attention=関係性」「Feed Forward=情報整形」と思ってください。
最終出力
ここまで処理された結果が、最終的な文の意味ベクトルになります。
このあとにDecoderや次の層で翻訳・生成・分類などに活用されます。
⑤ GPT登場:生成特化型AIの誕生
GPTはTransformerのデコーダ部分だけを活用した巨大生成モデルです。
| Transformer | GPT |
|---|---|
| エンコーダ+デコーダ | デコーダのみ |
| 翻訳・分類・要約 | 文章生成特化 |
| 入力+出力両方参照 | 過去の履歴のみ参照 |
GPTの生成例
- 「私は」 → 「りんごを」
- 「私はりんごを」 → 「食べる」
- 「私はりんごを食べる」 → 「。」
👉 自己回帰生成(Autoregressive)
👉 Masked Self-Attention で未来を遮断
⑥ Prompt Engineering:AIの使い方が重要に
プロンプトの良し悪しで性能が変わる
具体例
- ❌:「記事を書いて」
- ✅:「Transformerの仕組みを中学生向けに図解付きで2000文字以内に解説して」
👉 質問の仕方がスキルになる時代へ
⑦ AIエージェント:次世代の自律行動AIへ
AIエージェントとは?
単なる「入力→出力」から進化し、
- 目標を理解し
- 自ら計画を立て
- 必要なら外部ツールを使い
- 状況に応じて行動を修正
という自律行動型AIが登場しています。
具体例①:OpenAI Operator
- ブラウザ操作をAIが自律実行
- 例:商品購入、会員登録、予約作成などをAIが勝手に進行
具体例②:Manus (Monica社)
- 複数のWebサイトを横断して情報収集
- 株式分析やレポート作成を自動化
⑧ 全進化まとめ表
| 時代 | 技術 | キーワード |
|---|---|---|
| 2014 | Seq2Seq | ボトルネック |
| 2015 | Attention | Query / Key / Value |
| 2017 | Transformer | 並列計算・高速学習 |
| 2018〜 | GPT | 自己回帰生成 |
| 2023〜 | Prompt Engineering | 質問設計 |
| 2024〜 | AIエージェント | 自律行動・計画実行 |
まとめ
私は最初、AIの中身は魔法のように感じました。
でも実際には、単純な行列計算と足し算・掛け算の積み重ねというだけが分かりました。AI黎明期であるこのタイミングで大枠を理解しておくことは今後の世界で生き抜くために必要かと思います。
少しでも役に立てれば幸いです。