はじめに
RAGシステムに関する仕事に関わることが多く、たまたまQdrantを使う機会があったので基本的な概念~操作を勉強してみました。
非エンジニアなので初歩の初歩だけさらう感じでまとめています。超概要をお求めの方向けです。
Qdrantとは?
オープンソースで提供されているベクトルデータベース
特徴
- 高精度な類似検索(Cosine、Euclid、Dotなど多彩な距離計算に対応)
- ローカル、オンプレ、クラウド環境で利用可能
- ベクトルに加えて、Payload(メタデータのようなもの。詳細は後述)での絞り込み検索も可能
用語の説明
- Collection
- RDBにおけるテーブル
- Pointをまとめたもの
- Point
- RDBにおけるレコード
- ID,Vector,Payloadで構成される
- Id
- Pointの一意の識別子
- Vector
- 検索に使用されるベクトル値
- Payload
- Pointに付与できる情報
- メタデータのように使用可能で、JSON形式で追加可能
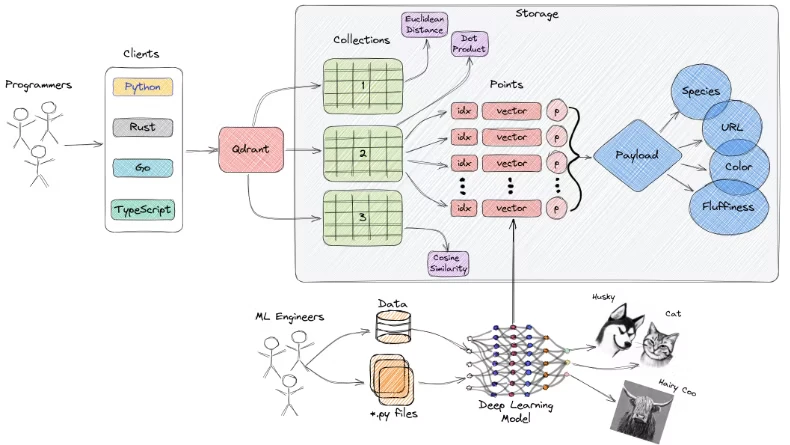
全体像
公式サイトから引用(出典)
基本操作
Collectionの作成
今回は"study_collection"を作成していきます。
ベクトルの次元数は4次元、類似度測定方法はCosine類似度を使用します。
client.recreate_collection(
collection_name="study_collection",
vectors_config={"size": 4, "distance": "Cosine"}
)
Pointの登録
コレクションができたら、Pointを登録していきます。
- 今回は日本の都市をお試しで登録します。ベクトル値は適当です
- Payloadとして、都市の名前と人口の情報を付与してみます
- pointを追加する際は、clientオブジェクトの"upsert"メソッドを使用します
points = [
{
"id": 1,
"vector": [1.0, 1.0, 0.7, 0.8],
"payload": {"name": "Tokyo",
"Population":9600000},
},
{
"id": 2,
"vector": [0.9, 0.9, 0.6, 0.8],
"payload": {"name": "Osaka",
"Population":2700000},
},
{
"id": 3,
"vector": [0.6, 0.5, 0.9, 1.0],
"payload":{"name": "Kyoto",
"Population":1450000}
}
]
client.upsert(collection_name="study_collection", points=points)
追加できたら、コレクション内のPoint数と各Pointのデータを確認してみましょう。
response = client.scroll(
collection_name="study_collection",
limit=10, # 必要に応じて増やす
with_vectors=True
)
for point in response[0]:
print(f"ID: {point.id}, ベクトル: {point.vector}, ペイロード: {point.payload}")
3つの都市の情報がPointとして登録されていることが確認できました。
ID: 1, ベクトル: [0.5652334, 0.5652334, 0.39566338, 0.45218673], ペイロード: {'name': 'Tokyo', 'Population': 9600000}
ID: 2, ベクトル: [0.55602187, 0.55602187, 0.37068126, 0.49424165], ペイロード: {'name': 'Osaka', 'Population': 2700000}
ID: 3, ベクトル: [0.38569462, 0.32141218, 0.5785419, 0.64282435], ペイロード: {'name': 'Kyoto', 'Population': 1450000}
新しいPointの登録(差分登録)
あとから追加したいPointが増えた場合も、upsertを使って登録できます。
new_points = [
{
"id": 4,
"vector": [0.8, 0.75, 0.7, 0.7],
"payload":{"name": "Fukuoka",
"Population": 1640000
}
}
]
Pointの検索(ベクトル検索)
Pointの追加方法がわかったところで、検索を行ってみましょう。
今回は、「neo_Tokyo」のベクトルを入力し、検索結果の最上位に正しくneo_Tokyoがヒットするかを確認します。
search_vector = [1.0, 1.0, 0.7, 0.8]
result = client.search(
collection_name="study_collection",
query_vector=search_vector,
limit=1 # 何件のPointを取得するかを設定
)
for hit in result:
print(f"ID: {hit.id}, スコア: {hit.score}, データ: {hit.payload}")
想定通りneo_Tokyoが最上位としてヒットしました。
ID: 1, スコア: 0.99999994, データ: {'name': 'neo_Tokyo', 'Population': 9600000}
スコアが1.0になっていないことが気になったのですが、その他の都市のベクトルで検索した場合はきちんと1.0が出力されました。
ID: 4, スコア: 1.0, データ: {'name': 'Fukuoka', 'Population': 1640000}
ChatGPTによると内部での正規化処理の影響なのでは?とのこと。neo_Tokyoだけで発生する理由までは確認できませんでしたので、もう少し勉強したいと思います。
Payloadを使ったフィルタリング
次にQdrantの特徴でもある、Payloadを使ったフィルタリングを行ってみます。
Payloadをいわゆるメタデータのように利用して検索できるので、業務利用を検討する場合需要が高そうです。
- 今回は「Population(人口)が200万人以下の都市」を検索してみます
- Filterクラスを使用してフィルタリングを行うことができます
from qdrant_client.http.models import Filter, FieldCondition, Range
# Populationが2000000以下のPointを検索
filter_condition = Filter(
must=[
FieldCondition(
key="Population",
range=Range(lt=2000001) # lt: より小さい(<) ※2000000以下
)
]
)
# 該当Pointを取得
points, _ = client.scroll(
collection_name="study_collection",
scroll_filter=filter_condition,
limit=10
)
for pt in points:
print(f"ID: {pt.id}, Population: {pt.payload.get('Population')}, 名前: {pt.payload.get('name')}")
結果はこちらです。200万人以下の「Kyoto」と「Fukuoka」がヒットしています。
ID: 3, Population: 1450000, 名前: Kyoto
ID: 4, Population: 1640000, 名前: Fukuoka
Pointの削除
次に、Pointの削除方法を確認します。
- pointを削除する際は、clientオブジェクトの"delete"メソッドを使用します
- 今回はID=4を指定して、途中で追加した"Fukuoka"を削除してみます
client.delete(
collection_name = "study_collection",
points_selector = [4]
)
# 以下は確認用コード
response = client.scroll(
collection_name="study_collection",
limit=10, # 必要に応じて増やす
with_vectors=True
)
for point in response[0]:
print(f"ID: {point.id}, ベクトル: {point.vector}, ペイロード: {point.payload}")
結果はこちら。きちんとFukuokaは削除できています。
ID: 1, ベクトル: [0.5652334, 0.5652334, 0.39566338, 0.45218673], ペイロード: {'name': 'neo_Tokyo', 'Population': 9600000}
ID: 2, ベクトル: [0.55602187, 0.55602187, 0.37068126, 0.49424165], ペイロード: {'name': 'Osaka', 'Population': 2700000}
ID: 3, ベクトル: [0.38569462, 0.32141218, 0.5785419, 0.64282435], ペイロード: {'name': 'Kyoto', 'Population': 1450000}
Collectionの削除
使う機会はあまり少ないかもしれませんが、コレクションの削除方法も確認します。
- "client.delete_collection(collection_name="___")"で削除することができます
client.delete_collection(collection_name="study_collection")
結果は以下の通り、きちんと削除できました。
True
まとめ
Qdrantの初歩的な操作を確認しました。
実践を考えると以下の点については深堀して勉強する必要がありそうです。
今後の課題としてあらためて勉強してみたいと思います。
- 類似検索方法による違い(どの検索方法が、どんなデータ/処理に向いているのか?)
- 密ベクトル/疎ベクトルの違い
- なぜ"neo_Tokyo"の検索スコアが1.0にならなかったのか
- Embeddingモデルを使った実装方法