はじめに
RAG (Retrieval-Augmented Generation) システムの構築において、多くの開発者が直面するのが 「日本語特有の検索精度の壁」 です。
Dense Vector(意味検索)は文脈理解に優れていますが、特定の型番、条文番号、あるいは固有名詞(例:「金商法第37条」)の完全一致検索には弱点があります。一方で、従来の全文検索(Keyword Search / BM25)は、表記ゆれ(例:「サーバー」と「サーバ」)や同義語に対応できません。
本記事では、Milvus AmbassadorのEisuke Izawa (Beginnersguide138)が、この課題を解決するために、高度な日本語正規化を行う「Sudachi」 と、マネージドベクトルDB「Zilliz Cloud (Milvus)」の最新機能を組み合わせた、実用的なハイブリッド検索システムの構築手法を提案・解説します。
アーキテクチャの概要

本システムは以下の技術スタックで構成されます。
-
Tokenizer (形態素解析): SudachiPy
- 単なる分かち書きではなく、
normalized_form()を利用して表記ゆれを強力に吸収します。
- 単なる分かち書きではなく、
-
Vector Database: Zilliz Cloud (Milvus)
- 意味検索(dense vector)や全文検索(sparse vector)で、ベクトル検索を担います。
- v2.4以降の機能である
Functionを利用し、DB側でBM25用のSparse Vectorを自動生成させます。
-
Embedding Model: AWS Bedrock (Titan Embedding v2)
- 多言語対応に定評のあるモデルを使用します。
-
Reranking: Reciprocal Rank Fusion (RRF)
- DenseとSparseのスコアを公平に統合します。
初心者向けハイブリッド検索チュートリアル!
ここからは、上のアーキテクチャのハンズオンを行っていきましょう。
ほとんどの資材は準備済みなので、簡単なセットアップだけで、ベクトル検索や全文検索、ハイブリッド検索を学習できます。料金もBedrockのみで、ほとんどかかりません。
セットアップ
GitHubから環境を移植
まずは、上のリポジトリをcloneしましょう。
git clone https://github.com/Beginnersguide138/rag-with-sudachi.git
クローンできたら、リポジトリの内部に移動し、Pythonの環境を準備します。
cd rag-with-sudachi
uv sync(uvを使用してPythonのライブラリをインストールします)
cp .env.example .env (環境変数を設定するファイルをテンプレートから作成します)
Zilliz Cloudを無料で使う
ベクトル検索や全文検索には、専用のデータベースが必要です。Zillizは、OSSのMilvusをマネージドサービスにしたプロダクトで、AWSでも使用できます。

特に、PoCのような極小のプロジェクトから、エンタープライズレベルまで、ほとんど同じコードで開発を続けられる点がお気に入りです。Milvus/Zillizであれば、「PoCはうまく行ったけど、会社全体に広げると高コストや性能不足で展開できない、、、」というのがなくなります。 Azure AI Searchのような高コストなPaaSと比較すると明らかですが、サービスの競争力をあげるのには、ぜひもってこいのサービスです。
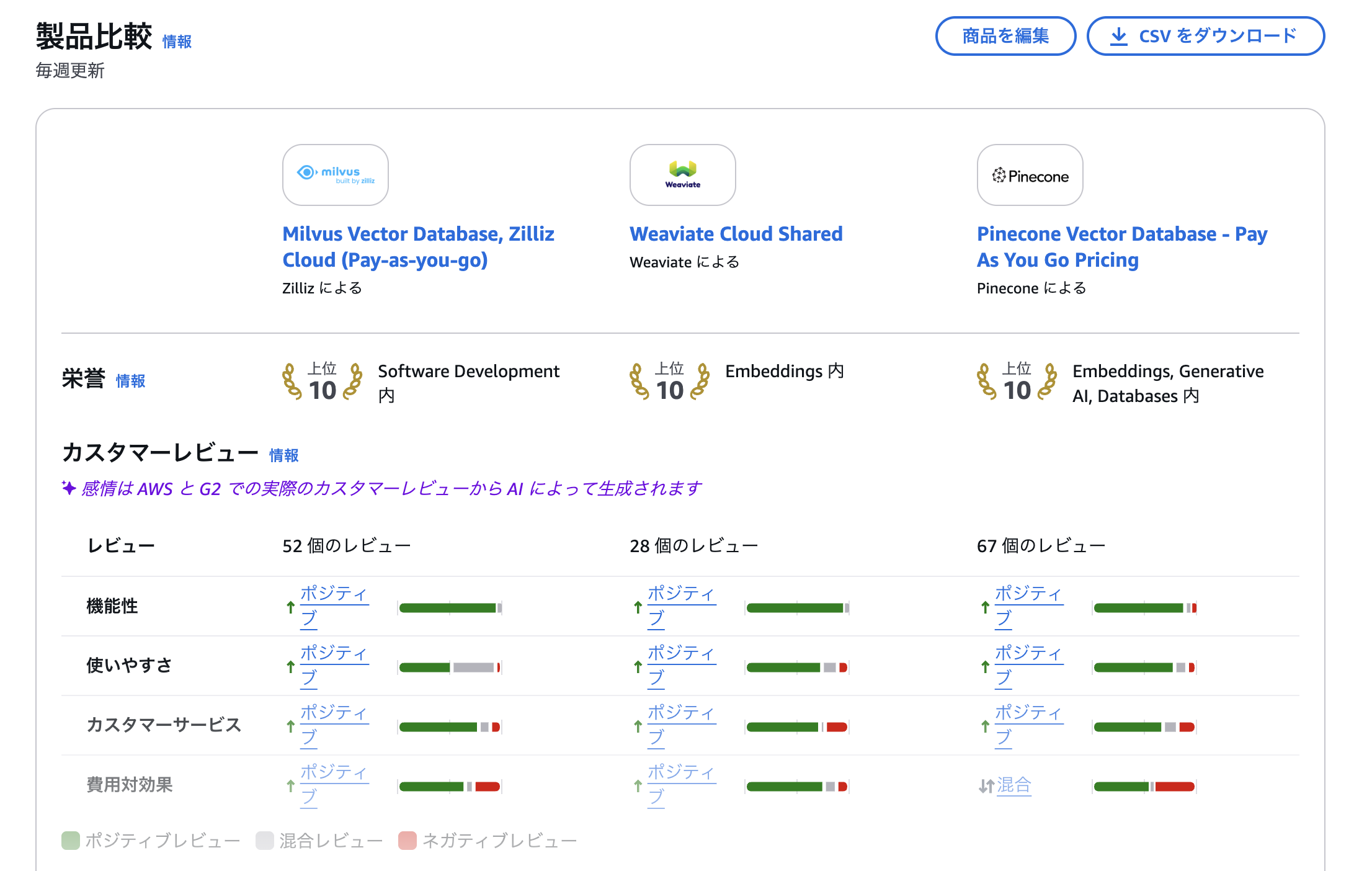 |
|---|
| 他のVectorDBと比較しても、機能性、費用対効果が評価されています。 |
さて、AWS Marketplaceに飛んだら、「無料で試す」を押します。これで、Milvusを無料枠で使うことができます。

トライアルは無料枠になっており、自動で有料に移行することはありません。
※ その代わり、無料トライアルは、一部監視機能などが利用できません。
トライアルを開始して、Zillizのコンソールに入ると、Organizationsを作成して、以下の画面になるはずです。
 |
|---|
| 無料のクラスターが作成されています。 |
最後に、クラスターのエンドポイントやAPI Keyをコピーすれば、完了です。
 |
|---|
| Geminiってマスキングできるんですね(雑談) |
コピーしたエンドポイントとAPI Keyは、以下に貼り付けてください。
- ZILLIZ_CLOUD_URI
- ZILLIZ_CLOUD_API_KEY
(作成した.envに上書きしましょう)
Bedrock API Keyの生成
オレゴンリージョンでBedrock APIキー(短期キー)を生成し、AWS_BEARER_TOKEN_BEDROCKに上書きしてください。
 |
|---|
| APIキー便利ですね。12時間で失効しますが、安全です。 |
ハンズオン開始
セットアップできたら、リポジトリをVSCodeで開いてみましょう。
notebooksフォルダのhybrid_search_with_bm25.ipynbがチュートリアルです。
- JupyerNotebookではなく、通常のPythonスクリプトで実行したい場合、
run_hybrid_search.pyをそのまま実行できます。


技術について
1. 日本語処理の要:Sudachiによる「正規化」
RAGの精度は、インデックス作成時のテキスト前処理で8割が決まると言っても過言ではありません。特に日本語においては、PDFから抽出したテキストに含まれるノイズや表記ゆれが検索漏れ(Recall低下)の主因となります。
本実装では、Sudachiの 正規化機能 を活用します。
実装コード
class SudachiAnalyzer:
def __init__(self):
self.tokenizer = dictionary.Dictionary(dict="core").create()
self.mode = tokenizer.Tokenizer.SplitMode.C
def analyze(self, text: str) -> str:
if not text:
return ""
tokens = self.tokenizer.tokenize(text, self.mode)
# スペース区切りの文字列として返す
return " ".join([t.normalized_form() for t in tokens if t.surface().strip()])
analyzer = SudachiAnalyzer()
なぜ正規化が必要なのか
normalized_form() を使用することで、以下のような揺らぎが統一されます。
- カタカナ語: 「サーバー」 ⇔ 「サーバ」
- 数字・記号: 「第1条」 ⇔ 「第一条」
- PDFノイズ: 「第 一 条」(不自然なスペース) ⇔ 「第一条」
これにより、ユーザーがどのような表記で検索しても、ドキュメント側の表記とマッチする可能性が飛躍的に高まります。
2. Milvus (Zilliz) のスキーマ設計など
Milvus (Zilliz Cloud) の強力な機能である Function を利用します。これにより、クライアント側で複雑なBM25計算を行う必要がなくなり、テキストを投げるだけで内部的にSparse Vectorが生成されます。
スキーマ定義
# スキーマ作成 (今回は埋め込みデータにIDをつけているため、Auto ID False)
schema = MilvusClient.create_schema(auto_id=False, enable_dynamic_field=True)
# フィールド定義
schema.add_field(field_name="id", datatype=DataType.INT64, is_primary=True)
schema.add_field(
field_name="text",
datatype=DataType.VARCHAR,
max_length=65535,
enable_analyzer=True,
analyzer_params={
"tokenizer": "whitespace"
}, # Sudachiで分かち書き済みのためwhitespaceを指定
)
schema.add_field(
field_name="dense_vector", datatype=DataType.FLOAT_VECTOR, dim=1024
) # 1024はTitanで指定
schema.add_field(field_name="sparse_vector", datatype=DataType.SPARSE_FLOAT_VECTOR)
# Function定義
# textフィールドからsparse_vectorを自動生成するBM25関数
bm25_function = Function(
name="text_bm25_emb",
input_field_names=["text"], # schema.add_field()で指定したfield_name
output_field_names=["sparse_vector"], # schema.add_field()で指定したfield_name
function_type=FunctionType.BM25,
)
schema.add_function(bm25_function)
この設計により、データ挿入時に sparse_vector を明示的に計算して渡す必要がなくなります。運用コストを大きく下げる重要なポイントです。
インデックス設計と最適化戦略
検索パフォーマンスと精度のバランスを最適化するために、各ベクトルフィールドに対して適切なインデックスアルゴリズムを設定します。
# インデックス定義
index_params = client.prepare_index_params()
index_params.add_index(
field_name="dense_vector", index_type="HNSW", metric_type="COSINE"
)
index_params.add_index(
field_name="sparse_vector",
index_type="SPARSE_INVERTED_INDEX",
metric_type="BM25",
params={"inverted_index_algo": "DAAT_MAXSCORE"},
)
Dense Vector: HNSW (Hierarchical Navigable Small World)
意味検索を担う dense_vector には、HNSW を採用しています。これはグラフベースの近似最近傍探索 (ANN) アルゴリズムであり、現在多くのベクトル検索エンジンでデファクトスタンダードとなっている手法です。 大規模なデータセットに対しても、高速かつ高精度な検索が可能であり、コサイン類似度 (COSINE) を用いて意味的な近さを判定します。
HNSW関連
Sparse Vector: 転置インデックスと高速化アルゴリズム
キーワード検索を担う sparse_vector には、全文検索エンジンで伝統的に使われる 転置インデックス (Inverted Index) をベースとした SPARSE_INVERTED_INDEX を使用します。
ここで特筆すべきは inverted_index_algo に設定している DAAT_MAXSCORE です。
-
DAAT (Document-at-a-Time): ドキュメントID順にポスティングリストを走査する戦略。
-
MaxScore: 検索クエリに含まれる用語の最大スコア(上限値)を事前に見積もり、最終的にトップkに入らないと判断されるドキュメントの計算を動的にスキップ(Pruning)するアルゴリズム。
この設定により、精度を落とすことなく、不要なスコア計算を削減し、BM25検索のレイテンシを大幅に短縮しています。
3. ハイブリッド検索の実装 (RRF)
検索時には、Dense Search(意味)と Sparse Search(キーワード)の結果を統合する必要があります。ここでは、スコアの尺度が異なる両者を適切にランク付けできる Reciprocal Rank Fusion (RRF) を使用します。
from pymilvus import AnnSearchRequest, RRFRanker
def search_hybrid(client, collection_name, query_text, query_vector, top_k=5):
# クエリテキストもSudachiで正規化・分かち書きする
query_processed = analyzer.analyze(query_text)
# 1. Dense Search Request
req_dense = AnnSearchRequest(
data=[query_vector],
anns_field="dense_vector",
param={"metric_type": "COSINE"},
limit=top_k * 2,
)
# 2. Sparse Search Request (BM25)
req_sparse = AnnSearchRequest(
data=[query_processed],
anns_field="sparse_vector",
param={"metric_type": "BM25"},
limit=top_k * 2,
)
# 3. Hybrid Search (RRF)
res = client.hybrid_search(
collection_name=collection_name,
reqs=[req_dense, req_sparse],
ranker=RRFRanker(), # RRFで順位を統合
limit=top_k,
output_fields=["text", "original_text"],
)
return res[0]
4. 実際の検索結果比較
このチュートリアルでは、金融庁の公開資料(金融商品取引業者等向けの総合的な監督指針)を用いた検証結果を紹介しています。
また、ノートブックでは、
- 意味検索(dense vector)
- 全文検索(sparse vector)
- ハイブリッド検索
- のそれぞれに最適なクエリを行って比較できるようにしています。
# --- 5. 比較実行 ---
query_types = ["ベクトル検索", "全文検索", "ハイブリッド検索"]
queries = [
["別紙様式Ⅱ-11", "チャイニーズウォール", "金商法第37条"],
[
"システム障害が発生した際の金融庁への報告期限と方法",
"非対面取引における本人確認の手続き",
"顧客の最善の利益を確保するための誠実公正義務について",
],
[
"指定ADR機関が存在しない場合の苦情処理措置",
"登録金融機関に対する行政処分の留意点",
"反社会的勢力への対応方針と遮断のための体制整備",
],
]
TOP_K = 5
ケーススタディ:キーワード性が高いクエリ
Query: 「指定ADR機関が存在しない場合の苦情処理措置」
| 検索手法 | 結果の特徴 |
|---|---|
| Dense Vector (意味検索) | 「金融ADR制度の概要」「苦情処理態勢」など、意味が近い一般的な文書が上位に来てしまい、ピンポイントな条項が埋もれる傾向がありました。 |
| Sparse Vector (BM25) | 「指定ADR機関」「苦情処理措置」という単語を正確に捉え、対象の文書を1位にランクインさせました。 |
| Hybrid Search | Sparseの結果が補完し、正確な文書を上位に表示しつつ、Dense由来の関連文書も候補に含めることができました。 |
この結果から、「ユーザーが専門用語や特定の名称で検索した場合、Denseだけでは取りこぼすリスクがある」 ことがわかります。ハイブリッド検索は、ビジネス文書検索において必須のアプローチと言えます。
5. まとめと応用
本記事では、Sudachiによる日本語正規化とZilliz Cloud (Milvus) を組み合わせたハイブリッド検索の実装方法を解説しました。
本構成のメリット
- 表記ゆれに強い: Sudachiの正規化により、ユーザーの入力揺らぎを吸収。
- 運用が楽: MilvusのFunction機能により、BM25の管理・計算コストをオフロード。
- 高精度: RRFにより、意味検索とキーワード検索の「いいとこ取り」を実現。
想定ユースケース
- 社内規定・マニュアル検索: 「第◯条」などの厳密な指定と、「〜について知りたい」という曖昧な質問の両立。
- ECサイト内検索: 正確な型番検索と、特徴による類似商品検索の両立。
- カスタマーサポート: 専門用語(エラーコード)と自然言語(「動かない」)の組み合わせ対応。
本記事の完全なソースコードおよびJupyter Notebookは、以下のリポジトリで公開されています。少額・簡単なので、ぜひ一通り試してみることをおすすめします。
(Bedrockで検索ベクトル作成費用しか掛かりません。。。)
ぜひ、実際のプロジェクトでこのハイブリッド検索の効果を体感してください。
この記事が皆様に役立てればと思います。
最後までお読みいただき、ありがとうございました!