Show and Tell で述べられていたNIC model について調べる機会があったときのメモ
画像から説明文を生成するタスクをpythonでお手軽に実行してみたい人は以前書いた
こちら参考にしてみてください
参考
元論文:Show and Tell: A Neural Image Caption Generator
※図は元論文からの引用
Show and Tell: A Neural Image Caption Generatorを読んだ
Show and Tell: A Neural Image Caption Generatorの紹介
ざっくりな流れ
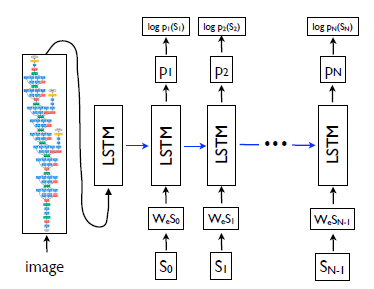
図1 NIC model
( ① 事前学習によりモデルを作成する )
② CNNによって入力画像の特徴ベクトルを中間層から出力
③ 最初のLSTMに特徴ベクトルを入力し、LSTMの出力$m_0$を2番目のLSTMに入力する
④ 2番目のLSTMにおいて、$m_0$と単語$S_0$をベクトル化した$W_eS_0$から、$S_0$に続く単語$S_1$を予測($log_{p_1}(S_1)$)
⑤ 2番目の出力$m_1$($p_1$は$m_1$をSoftmaxしたもの)を3番目のLSTMに入力
⑥ 3番目のLSTMにおいて、$m_1$と単語$S_1$をベクトル化した$W_eS_1$から、$S_1$に続く単語$S_2$を予測($log_{p_2}(S_2)$)
⑦ ストップワード$S_N$が予測されるまで、⑤と⑥のように単語予測をしていく
⑧ $S_0$から$S_N$が入力画像の説明文(キャプション)になる
以下、画像から説明文を出力するまでのちょっと詳しい流れです
※さらっと読んだだけなので間違いがあるかもしれません
事前学習
事前学習では単語の意味や文法と画像の特徴をまとめたベクトル空間を作ります
そのベクトル空間から次に述べるLSTMが、入力された画像の説明文を予測します
まず、事前学習ではMSCOCOやFlicker-8kなどのトレーニングデータセットによって単語予測のための条件付き確率式を作ります
log_p(S|I) = \sum_{t=0}^{N} log_pp(S_t|I, S_0, ... , S_{t-1}) \\\
t番目の単語$S_t\ $の確率は画像$I\ $とt個の単語列$S_0\ $, ..., $S_{t−1}\ $の条件付き確率、らしい
単語$S_0$の次に来る単語は$S_1$の確立が高い、みたいな式ですたぶん
次に、画像の特徴をCNNを使用して取得します
Batch normalizationを使用したとか書いてありますが、
学習時間の短縮や過学習の抑制のためなので割愛!
(CNN)(Batch normalizationについて)
CNNによって取得した画像の特徴と単語予測の条件付き確率式$log_p(S|I)$を word embeddingします
(word embeddingは単語の意味や文法を保持したままベクトル空間に写像する手法・・・らしい)
画像の特徴と単語予測の確率式を同ベクトル空間にすることにより、画像の特徴から単語を推測することができます
元論文的な言い方をすると「画像を単語に翻訳する!」
文の生成
文作成には、図2のLSTMが使われます
LSTM内のパラメータは事前学習によって決められたものを使用し、すべてのLSTMは同じパラメータを共有しているそうな~
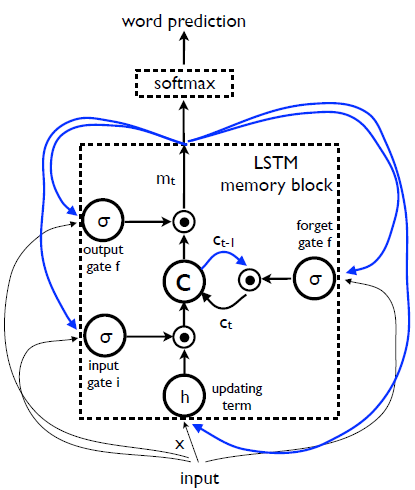
図2 LSTM-based Sentence Generater
図1 NIC model(再掲)
最初にCNNを使って入力画像(image)から画像の特徴をベクトルとして抽出します(中間層の出力を使う)
抽出された特徴ベクトルを最初のLSTMに入力します
この入力からは単語予測を行わず、出力$m_0$を次のLSTMに渡します
※図2の青線と図1の青線は対応しているので、図を見た方がイメージしやすいかも
次に、スタートワード$S_0$をword embeddingによってベクトル化した$W_eS_0\ $をLSTMに入力します
前の出力である$m_0$と入力$W_eS_0\ $から単語を予測します
予測には事前学習で作った、単語と画像特徴のベクトル空間を使用します
出力$m_1$をSoftmaxにかけて確率に変換した$p_1$と事前学習で作ったベクトル空間から、$S_0$に続く単語$S_1$を予測($log_{p_1}(S_1)$)
このように前のLSTMの出力$m_{N-1}$を使いながら、ストップワード$S_N$が予測されるまで処理を続けます
※文の始まりと終わりを認識するために$S_0$はスタートワードで$S_N$はストップワードという特別に設定したものです
元論文には、事前学習データセット別の結果とかも載っていますが、今回は割愛!
以上!