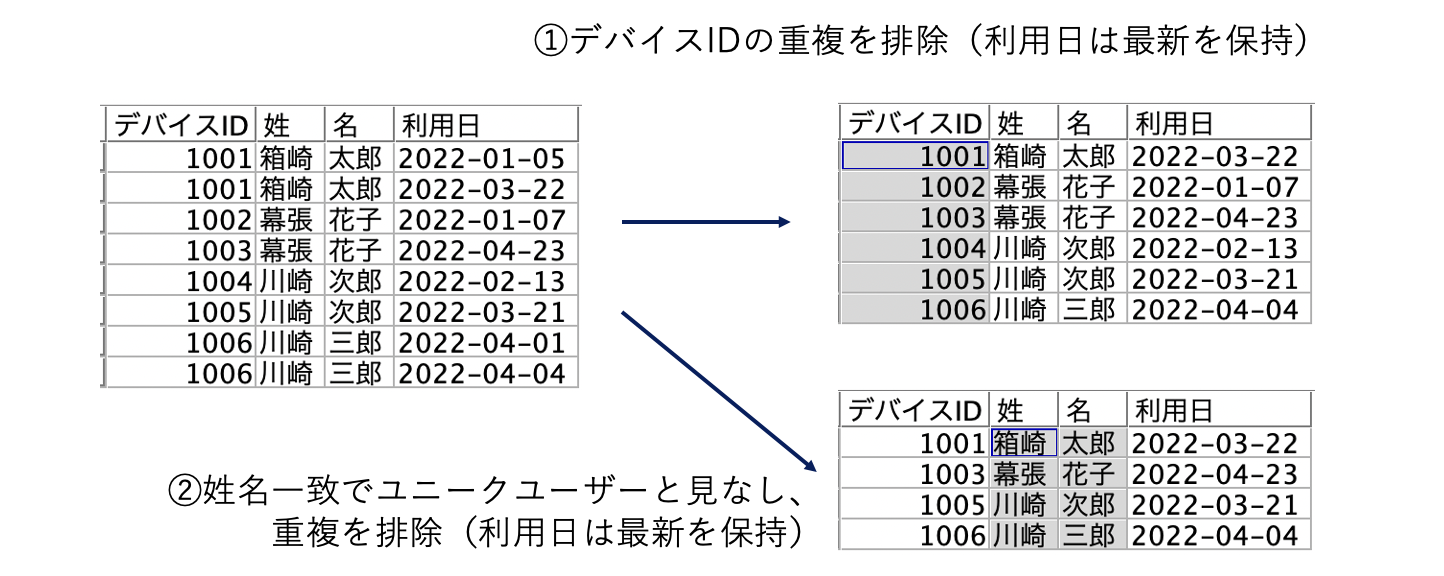
重複する不要なレコード(行)を削除(distinct)
1.想定される利用目的
・トランザクションやログからリストやマスタテーブルの作成
・新規テーブル作成のための前処理
2.サンプルストリームのダウンロード
3.サンプルストリームの説明
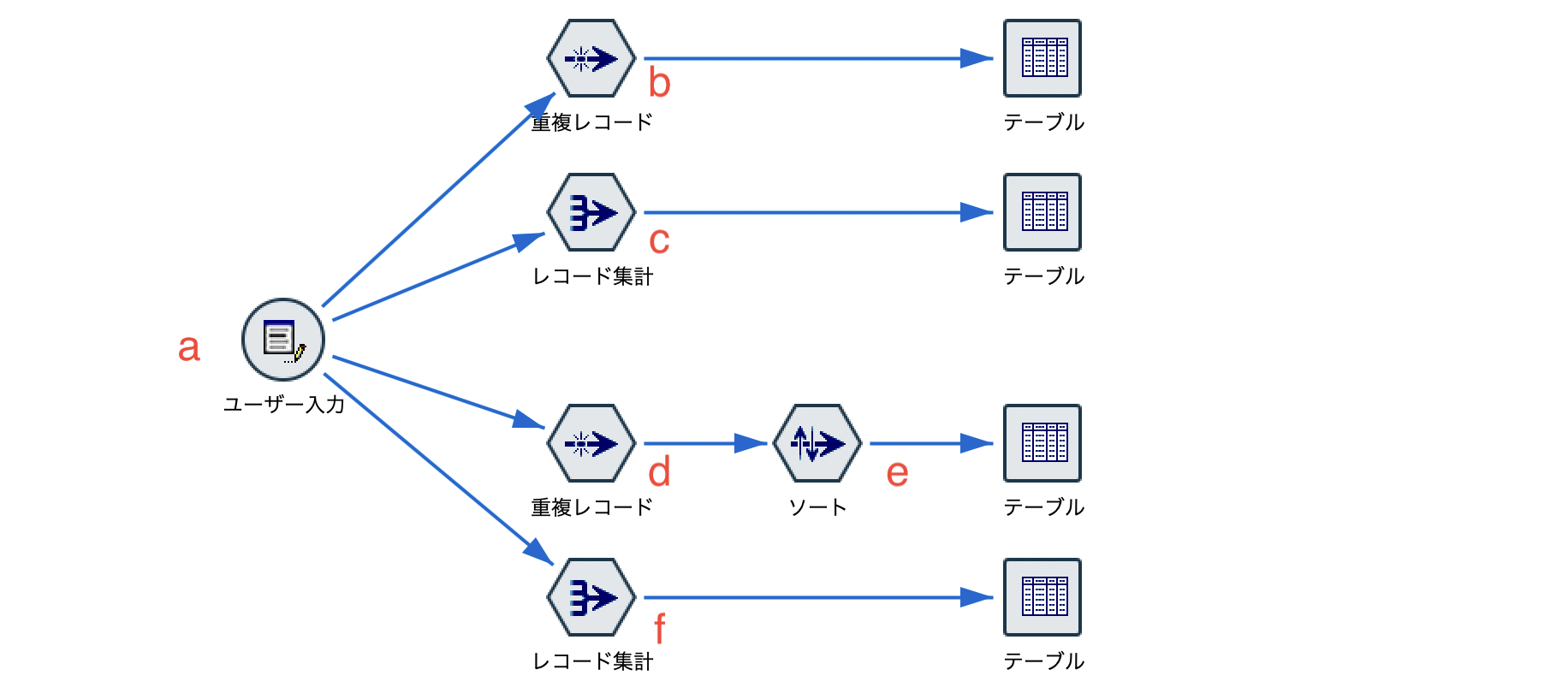
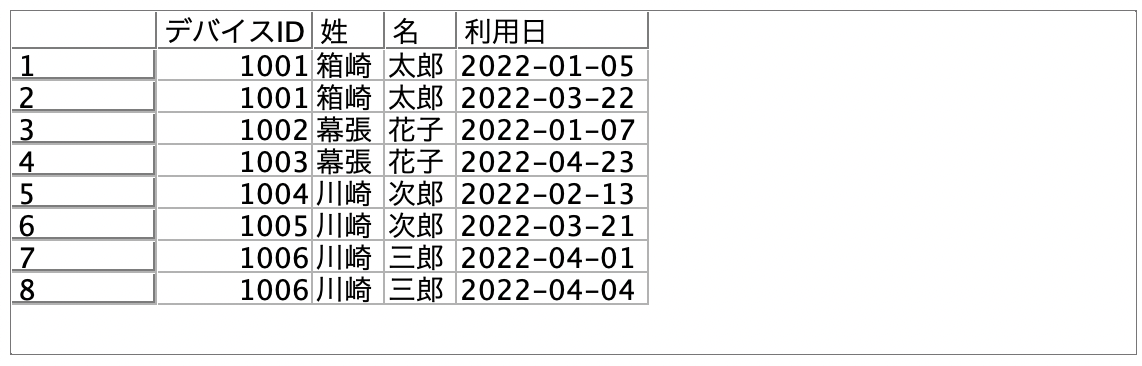
a.入力するデータは以下の通りです。
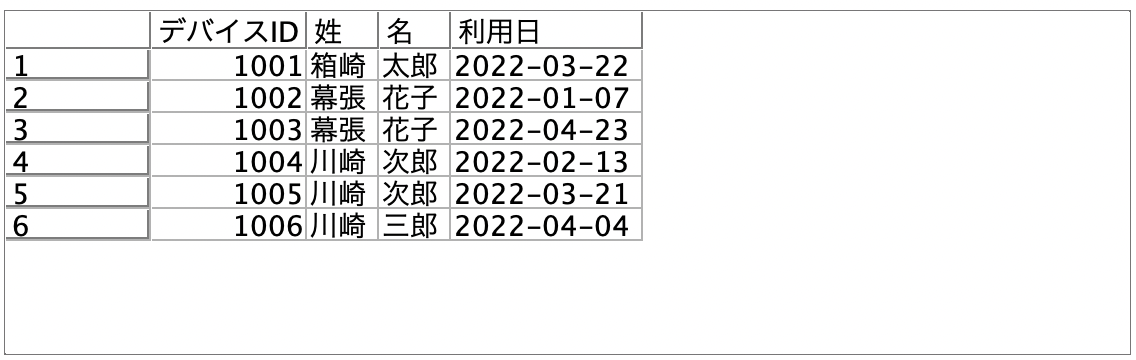
IDをキーにして重複を排除する
b.[重複レコード]ノードを編集します。[利用日]を降順ソートしてデバイスIDの最初のレコードを保持する設定です。
[テーブル]を実行します。IDでユニークなレコード(行)になりました。
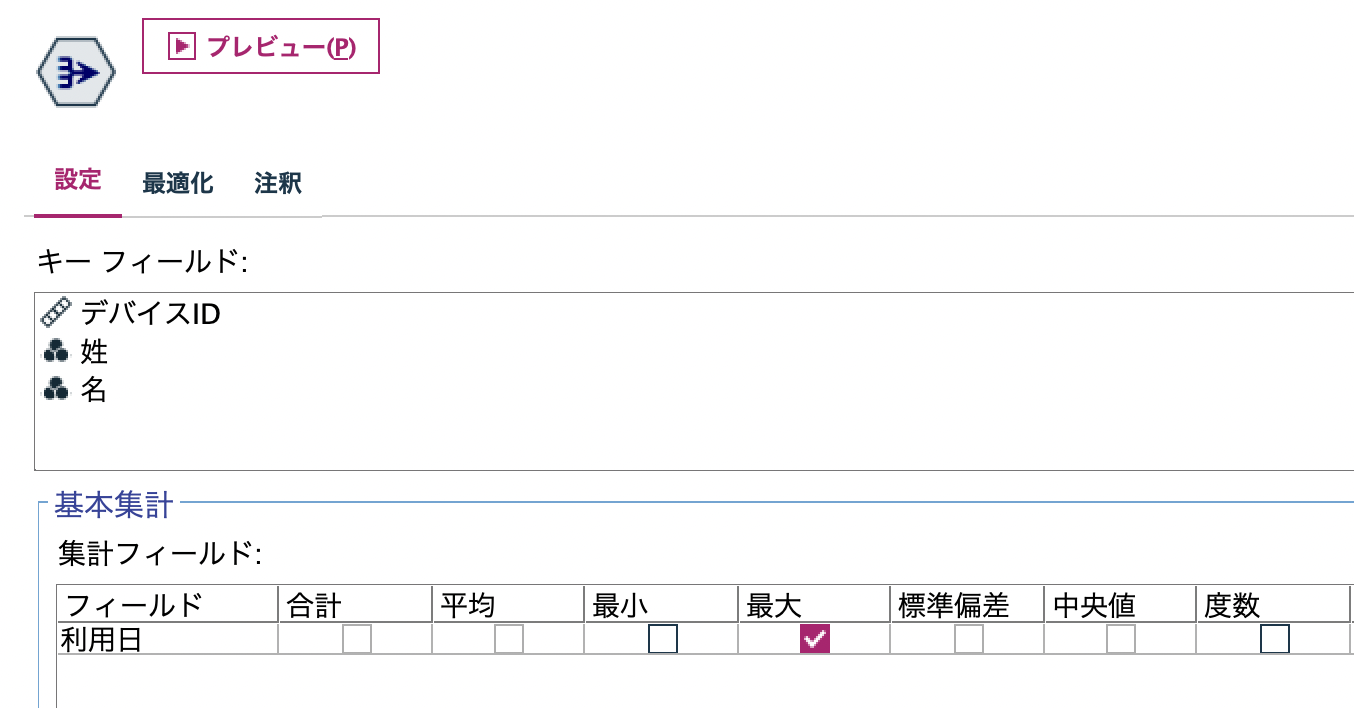
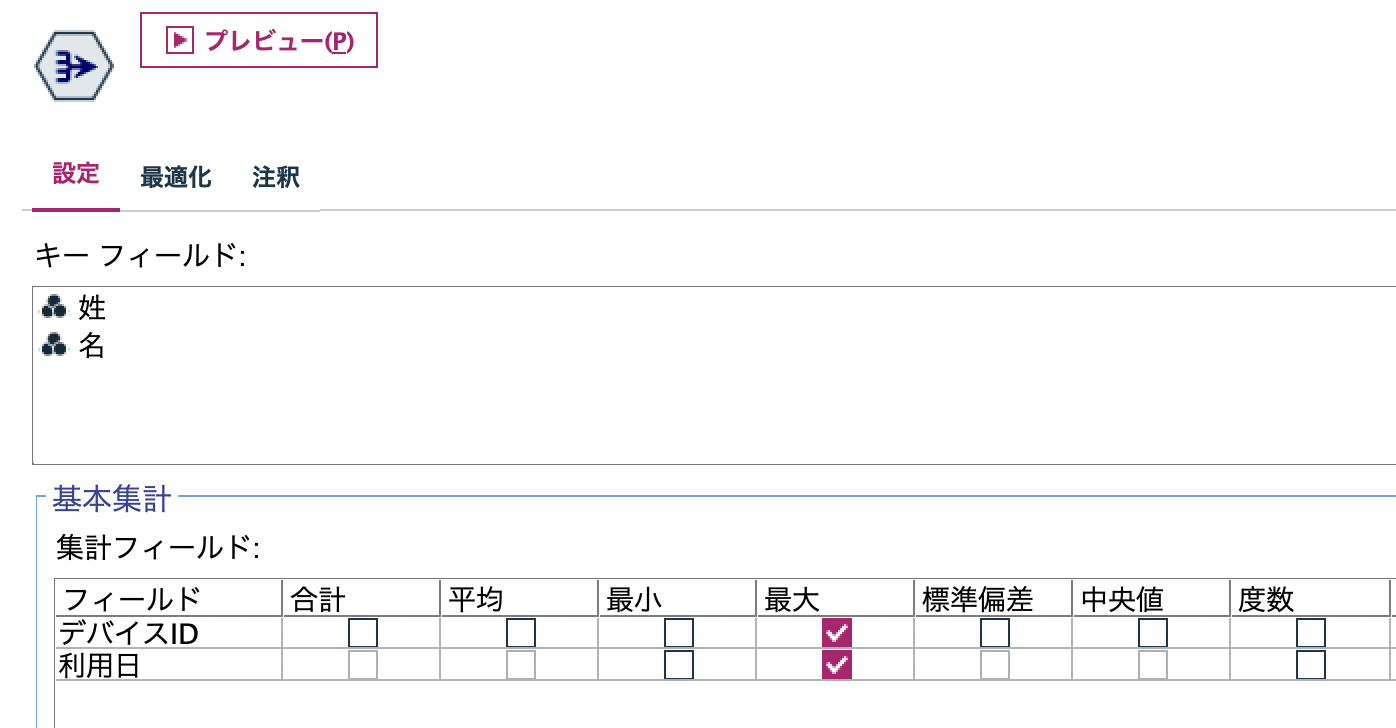
c.[レコード集計]ノードでも同じ処理が可能です。
姓と名が一致したらユニークと見なして重複を排除する
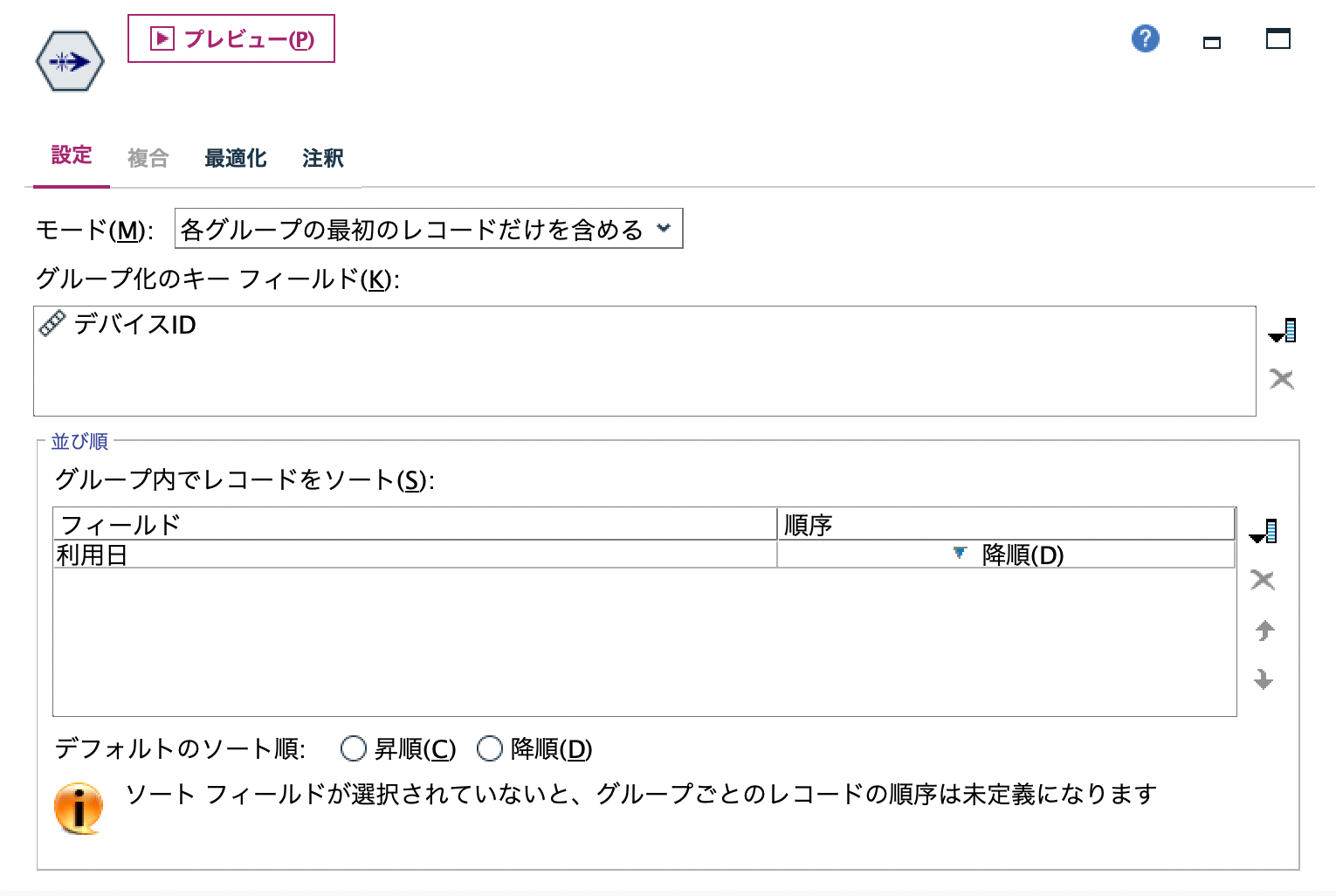
d.[重複レコード]ノードを編集します。[デバイスID]と[利用日]を降順ソートして姓名一致の最初のレコードを保持する設定です。

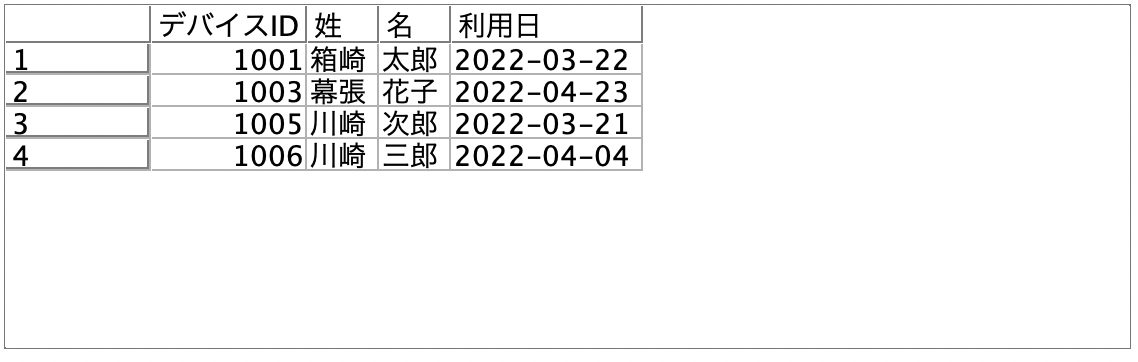
[プレビュー]します。正しくできていますが並び順が姓名でソートされました。

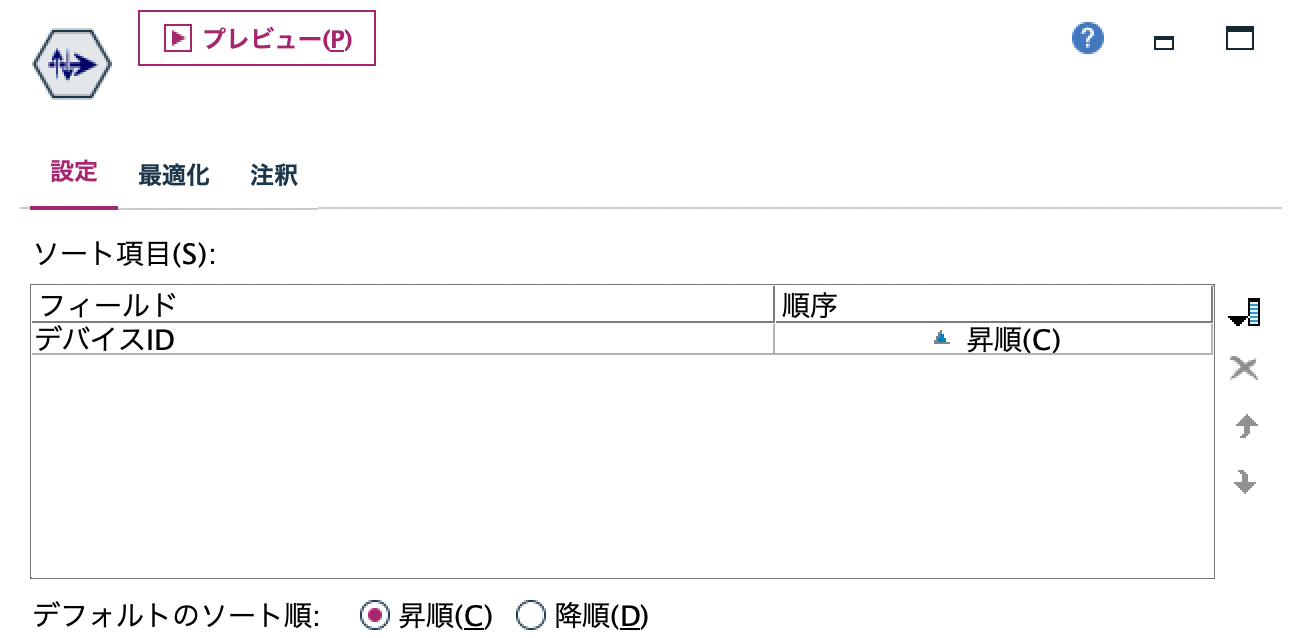
e.[ソート]ノードを編集します。
[テーブル]を実行します。
f.[レコード集計]ノードでも同じ処理が可能です。
注意事項
[デバイスID]を整数型で扱っていたため[レコード集計]ノードで最大値として利用できました。IDが文字型の場合には[置換]ノードで関数[to_integer(フィールド)]を利用して変換します。
4.参考情報
重複処理について解説した記事
SPSS Modeler ノードリファレンス目次
SPSS Modeler 逆引きストリーム集(データ加工)