1-1 可変長ファイルノード[入力タブ]

1.ノードの目的
CSVやタブ区切りなどのテキストファイル形式のデータを読み込みます。
2.解説動画(60秒)
3.クイックスタート
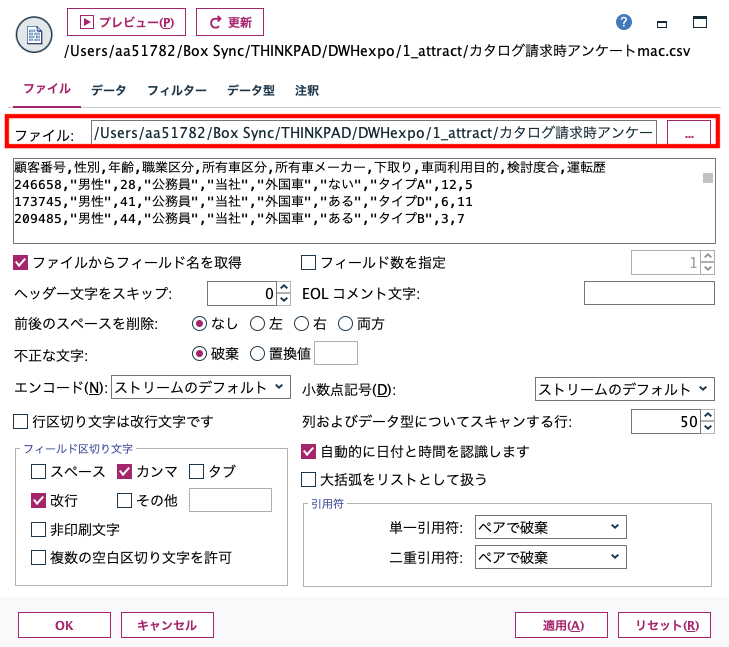
①ファイルタブの[ファイル:]の[...]ボタンから読み込むファイルパスを指定します。
(またはエクスプローラからCSVファイルをストリーム領域にドロップ)
*サンプルのCSVデータは[5.参考情報]からダウンロードできます。
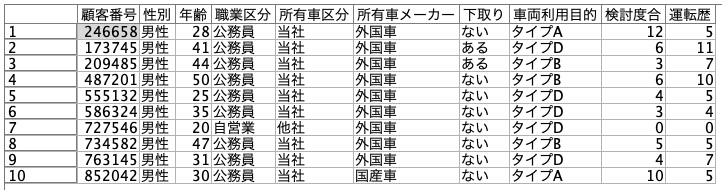
② [OK]ボタンで完了です。画面上のプレビューでデータが表示されます。
うまく読めない場合のヒント
Mac版ではデータの文字コードがUTF-8である必要があります。Shift-JISでは文字化けします。予めテキストエディタで変換しておいてください。

先頭レコード(先頭行)がフィールド名でない場合には以下のチェックを外します。
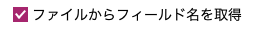
桁ずれしている場合には区切り文字や引用符を確認して適宜設定します。
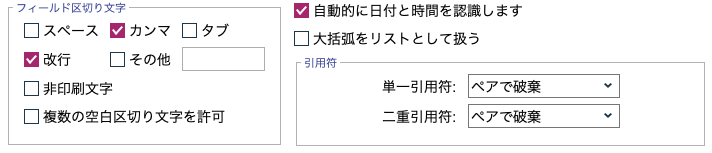
*金額に含まれるカンマは桁ずれの原因になりますので、予め処理するかタブ区切りなどを使います。
[商品名]などの文字列の前後に空白が入っていて、後続処理(結合)などでトラブルになることを防ぐため以下の設定が重宝します。業務的な特殊(不正)文字の処理も役に立ちます。

4.Tips
文字列や日付などのデータタイプの確定
例えば顧客番号や商品番号を文字列で扱うか整数で扱うかを曖昧にすると後続のテーブル結合で思いがけない不一致が起きます。[データタブ]で読み込み時点で強制的に文字列に上書きすることをお勧めします。その際前後の空白文字の有無にも注意してください。
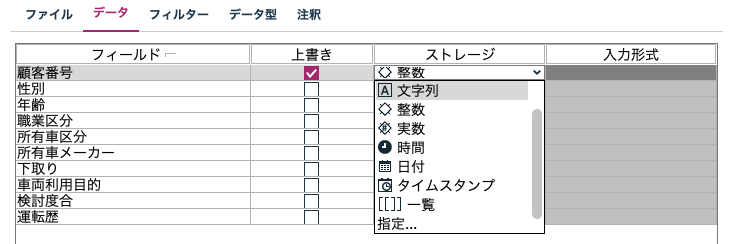
商品コードや電話番号は文字列に
[03********]のようなゼロから始まるコードや番号は整数で読み込むと先頭のゼロが欠落するために[文字列]として扱います。
不要なフィールドの除外
不要なフィールドは[フィルタ-タブ]で除外することが可能です。
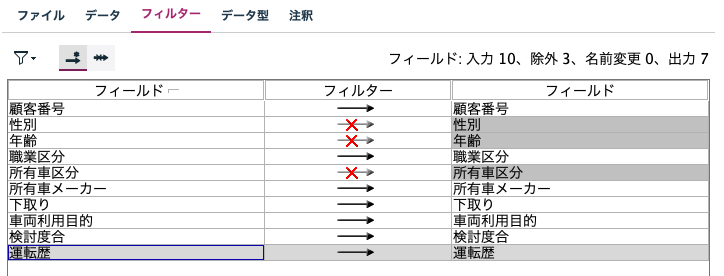
値の読み込み
[データ型タブ]で[値の読み込み]ボタンを押して値を確定をしておくと、後続の[再構成]や[行列変換]、[データの分類]の直前に[データ型ノード]を配置する必要がなくなります。
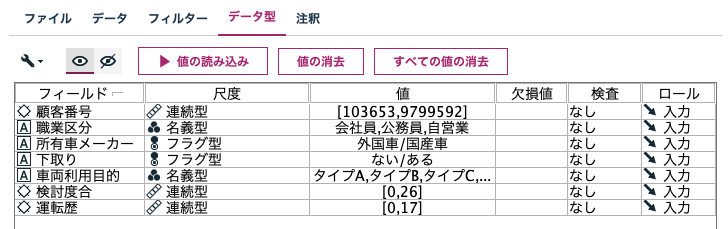
5.参考情報
利用データ
右クリックでリンク先を保存してください。
ノードのヘルプ
SPSS Modeler 逆引きストリーム集(データ加工)
SPSS Modeler ノードリファレンス目次