5-14 特徴量選択[モデル作成タブ]

1.ノードの目的
予測に有効なフィールド(列)を自動選別する。
2.解説動画(拡張ノード共通)
3.クイックスタート
[Statisticsファイル]ノードを配置して[テーブル]を接続します。

[Statisticsファイル]ノードを編集します。インポートファイルの[...]ボタンを押して入力パスを指定します。
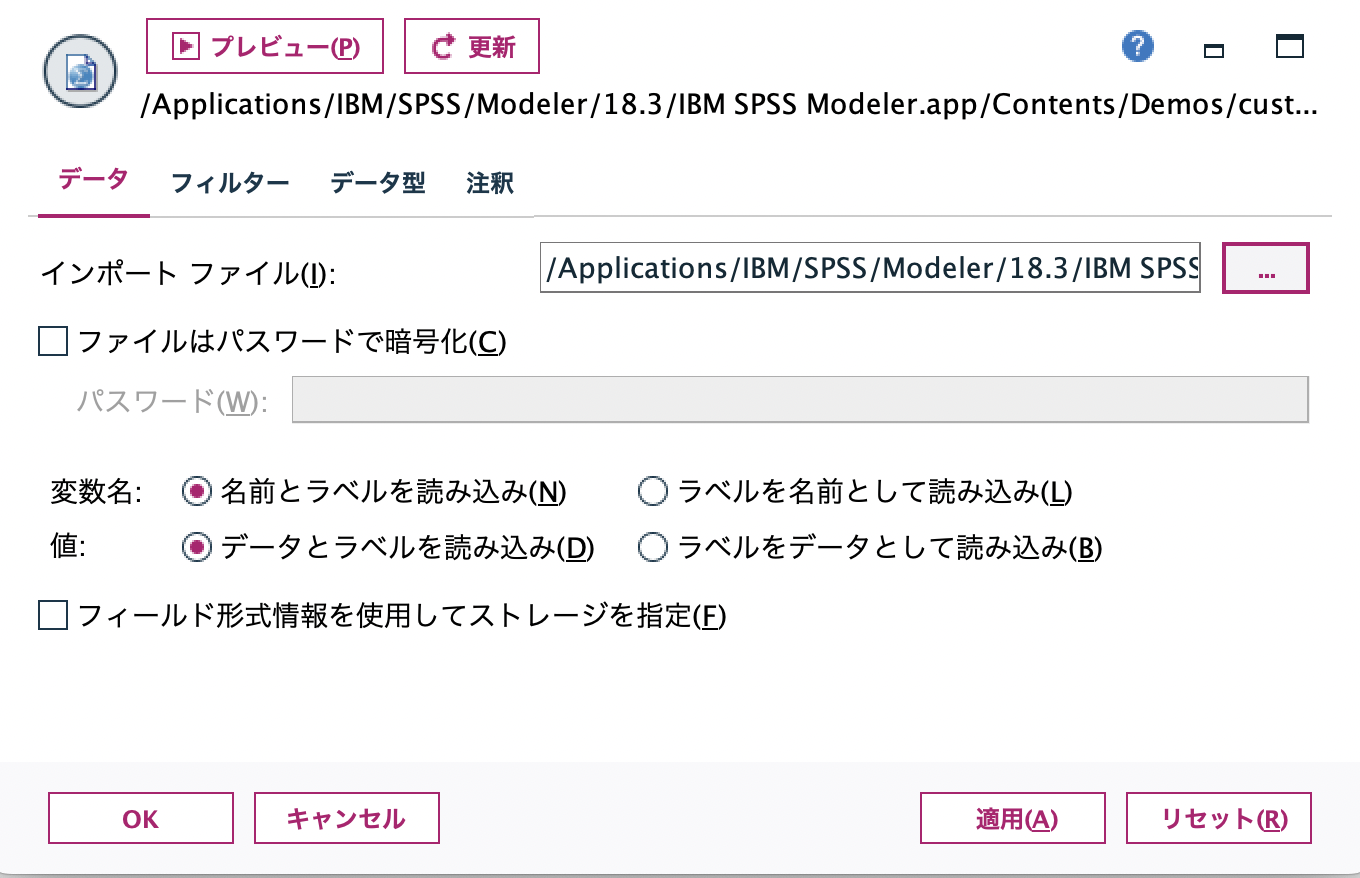
赤い枠のボタンを押してDemosフォルダを指定します。今回利用するファイルはSPSS Modelerインストール時に同梱されているデモデータ[customer_dbase.sav]です。
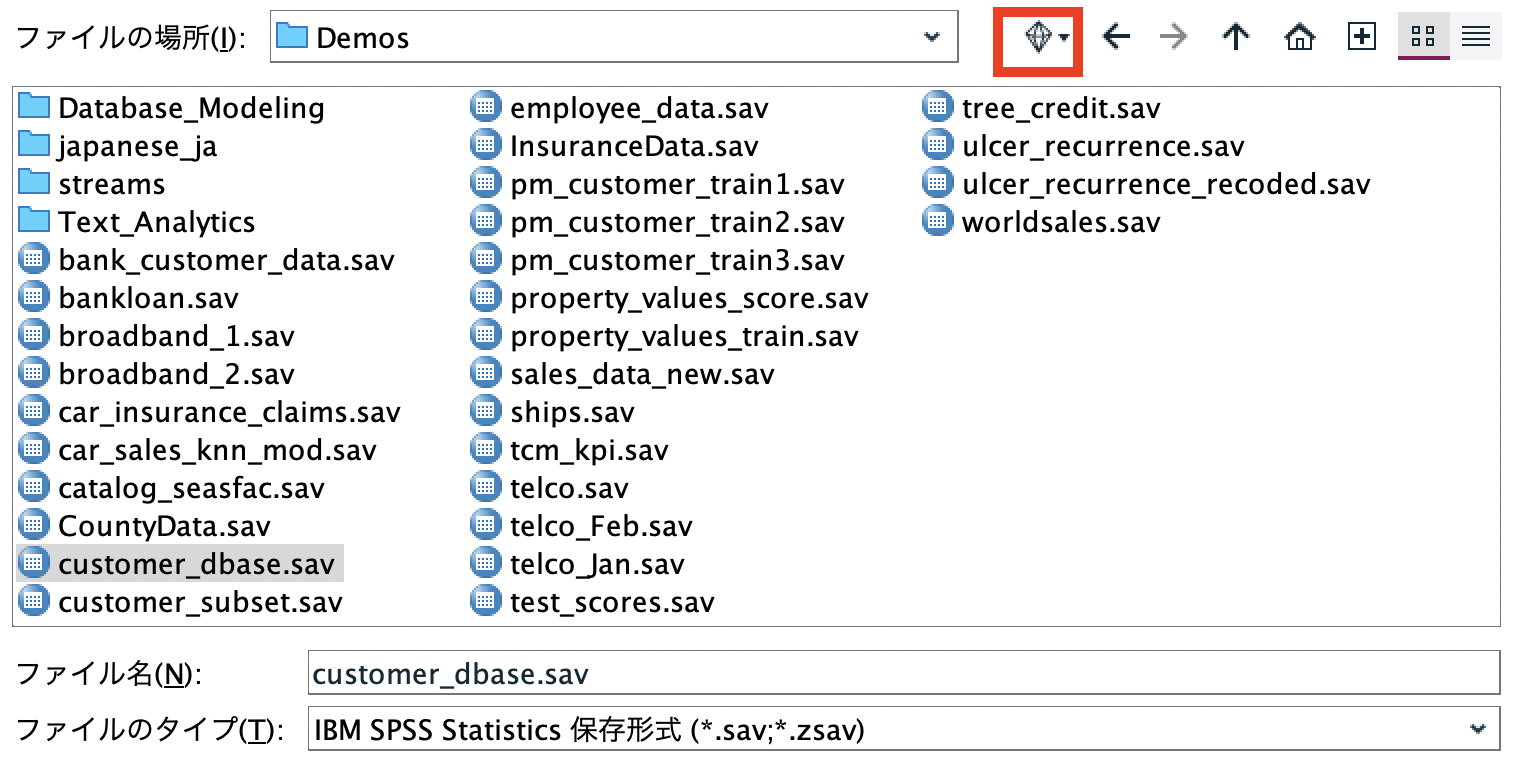
[データ型]タブを確認すると[response_01]フィールドが予測対象に事前にセットされています。

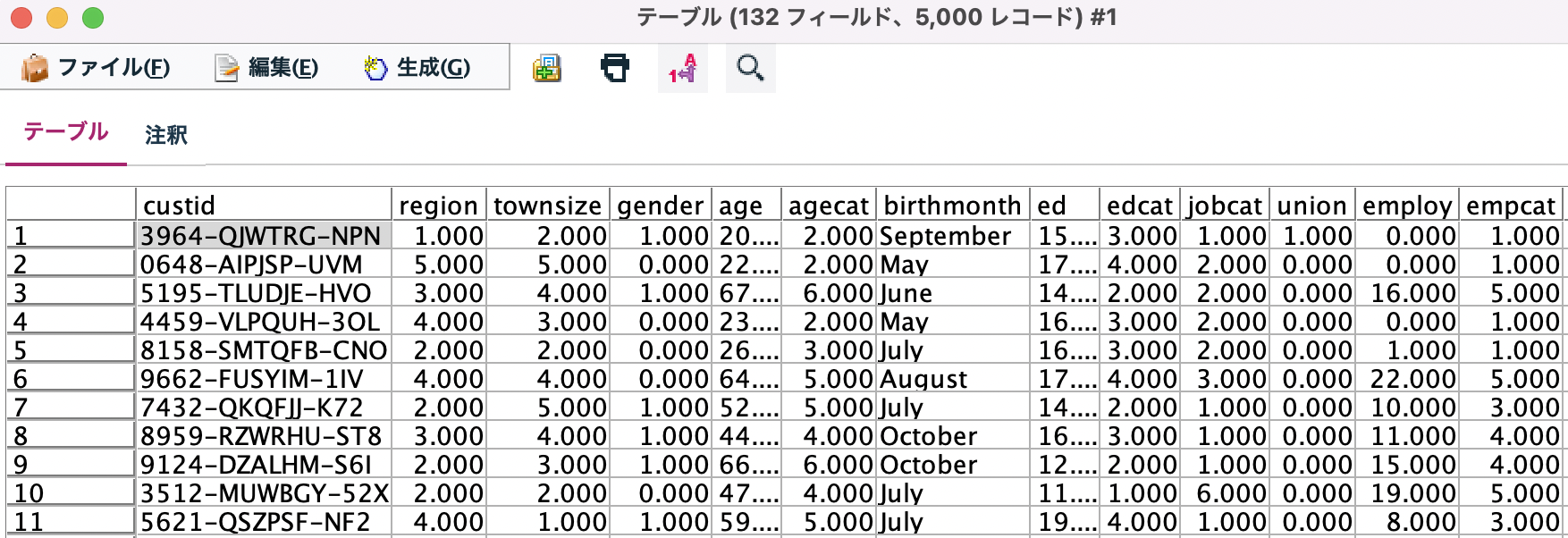
[テーブル]を実行します。ヘッダーに132フィールドとありますので、132列だと判ります。
[Statisticsファイル]ノードに[特徴量選択]ノードを接続します。
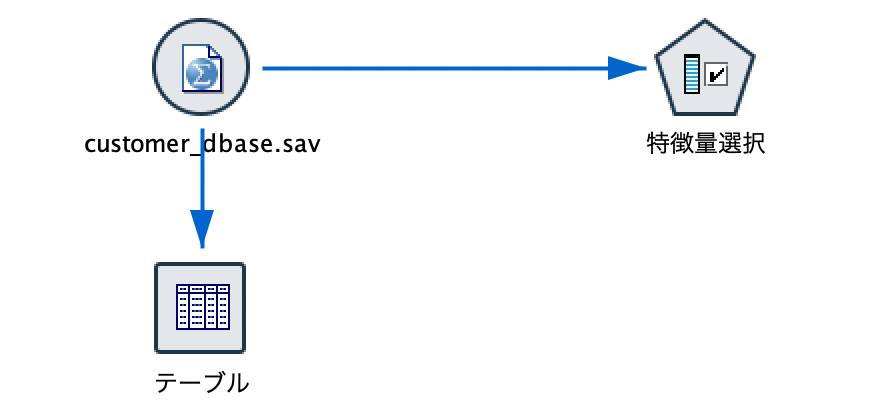
[特徴量選択]ノードを初期設定のまま実行します。

モデルナゲットに[テーブル]を接続し直します。
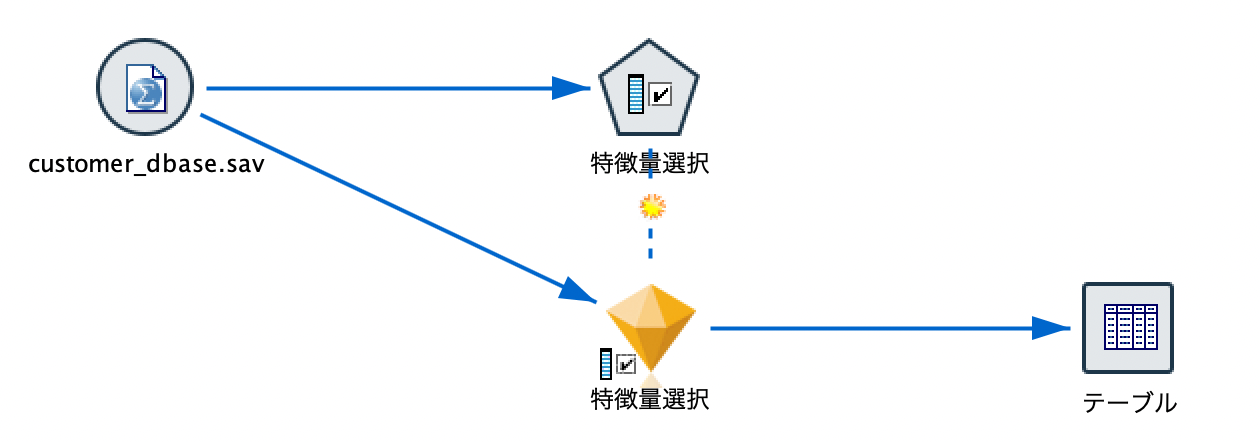
[テーブル]を実行するとフィールド数が38まで絞り込まれています。モデルナゲットはフィルターノードの役割をしています。
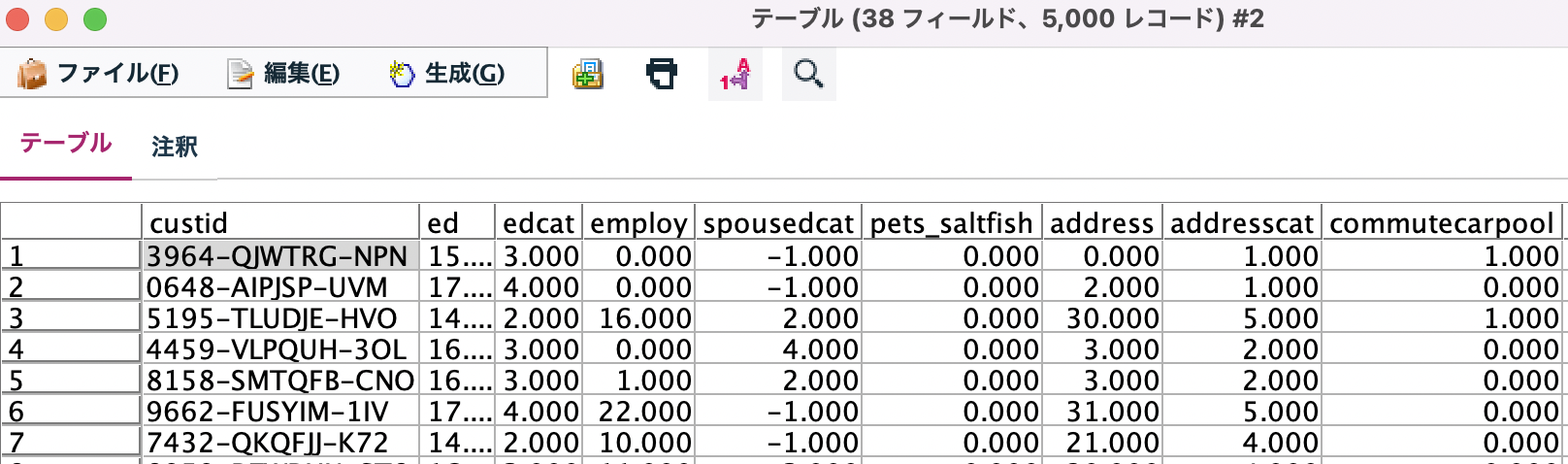
モデルナゲットを編集します。34フィールドが[response_01]を予測するのに有効だと判断されています。
また明らかに品質、説明変数として役に立たないものが9フィールドスクリーニングされています。
4.Tips
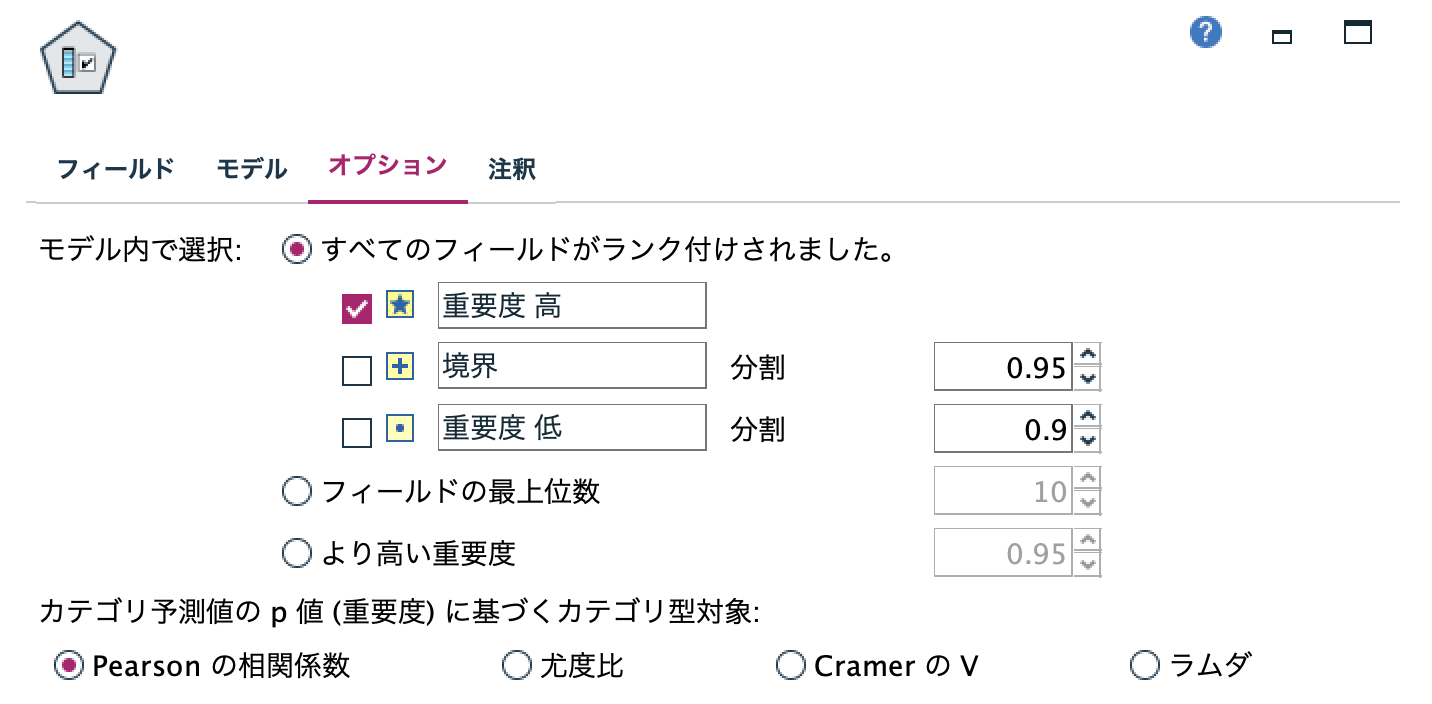
フィールドの有効性を判定する基準の変更
特徴量選択を解説したブログ記事
特徴量選択が登場するノードリファレンス記事
5.参考情報
ノードのヘルプ
SPSS Modeler 逆引きストリーム集(データ加工)
SPSS Modeler ノードリファレンス目次