複数ファイルを加工して結合する(Modelerスクリプトによるループ処理)
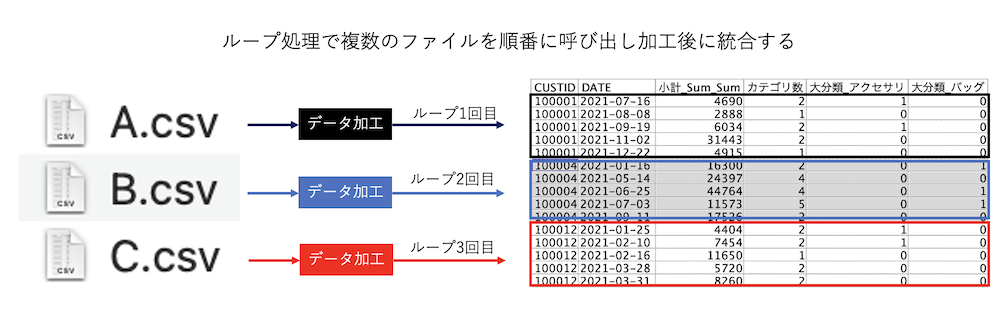
1.想定される利用目的
・同じような処理を効率的に実施するためPythonスクリプトを利用してループさせる
・IoTセンサーデータのような日毎ファイルから特徴量を抽出して分析用テーブルを作成する
2.サンプルストリームのダウンロード
サンプルデータ1(右クリックでダウンロード)
https://raw.githubusercontent.com/yoichiro0903n/blue/main/1.csv
サンプルデータ2
https://raw.githubusercontent.com/yoichiro0903n/blue/main/2.csv
サンプルデータ3
https://raw.githubusercontent.com/yoichiro0903n/blue/main/3.csv
3.サンプルストリームの説明
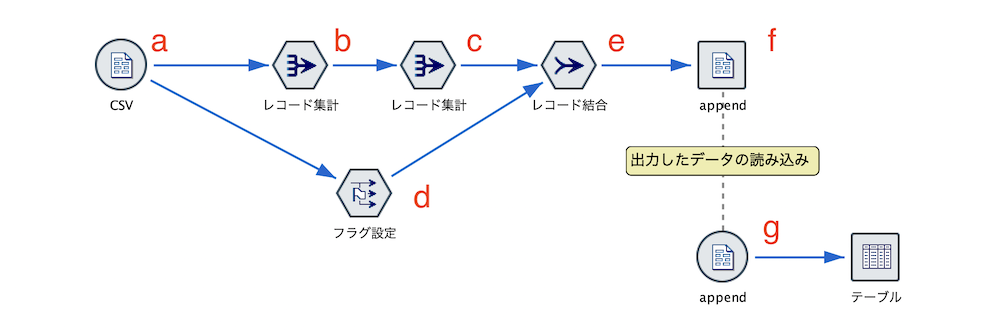
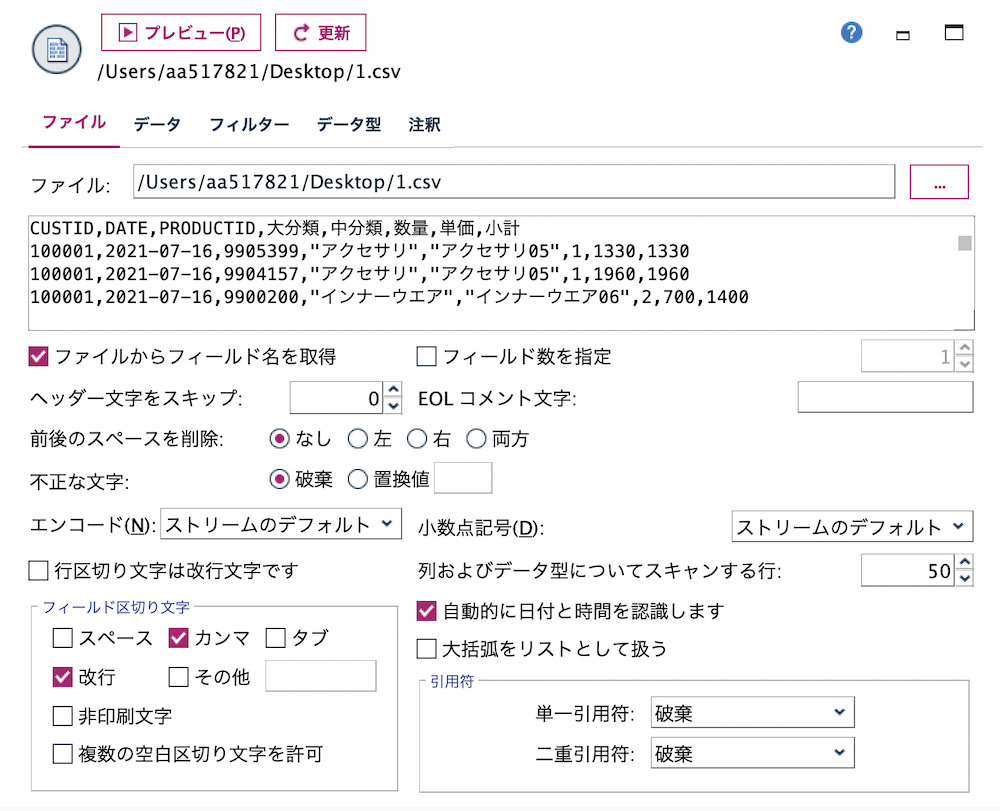
a.[可変長ファイル]ノードを編集します。サンプルの3つのうち、ストリーム設計には[1.csv]を利用します。
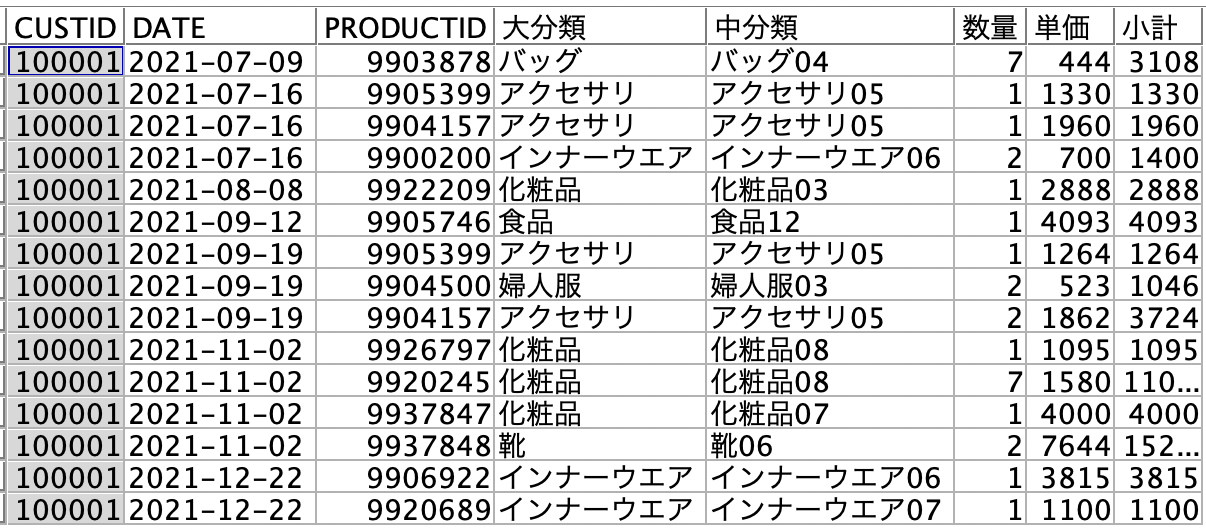
データは以下の通りです。顧客の取引明細データです。
[データ型]タブで[値の確定]ボタンを押しておきます。後続dで大分類のメンバーを認識させるためです。
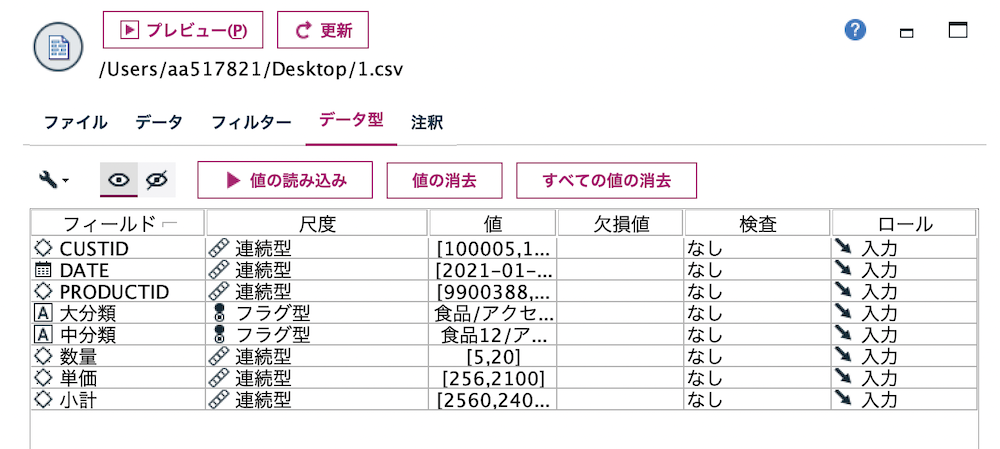
顧客の日毎の情報に要約する(特徴量を生成する)
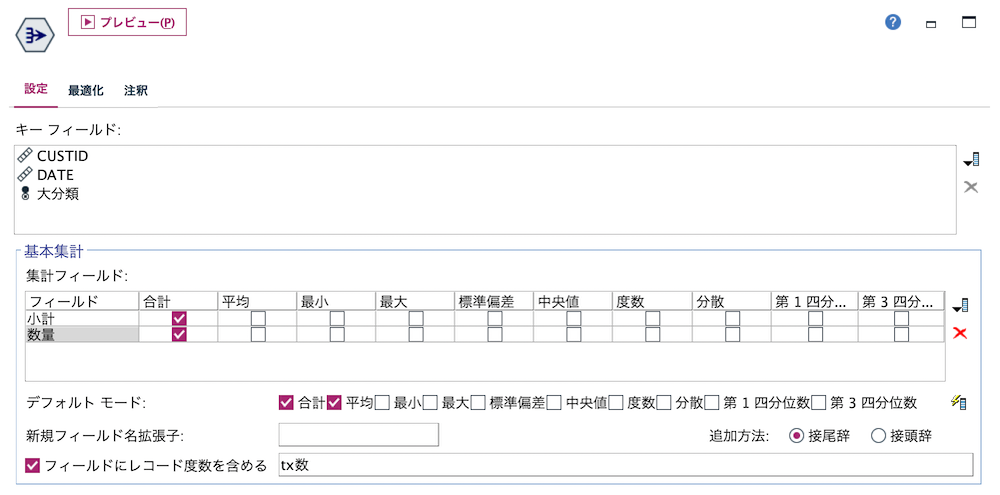
b.[レコード]ノードを編集します。
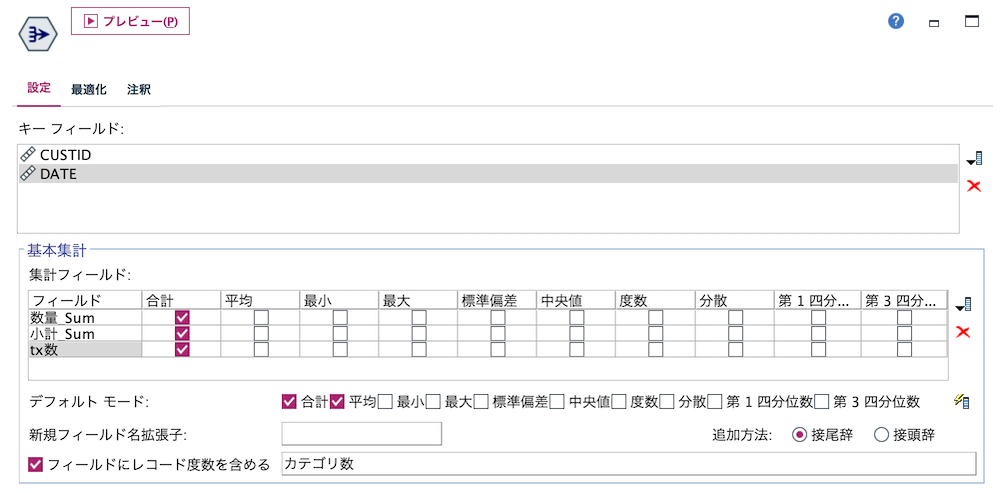
c.[レコード]ノードを編集します。この2段階集計でカテゴリ数(大分類数)をカウントできます。
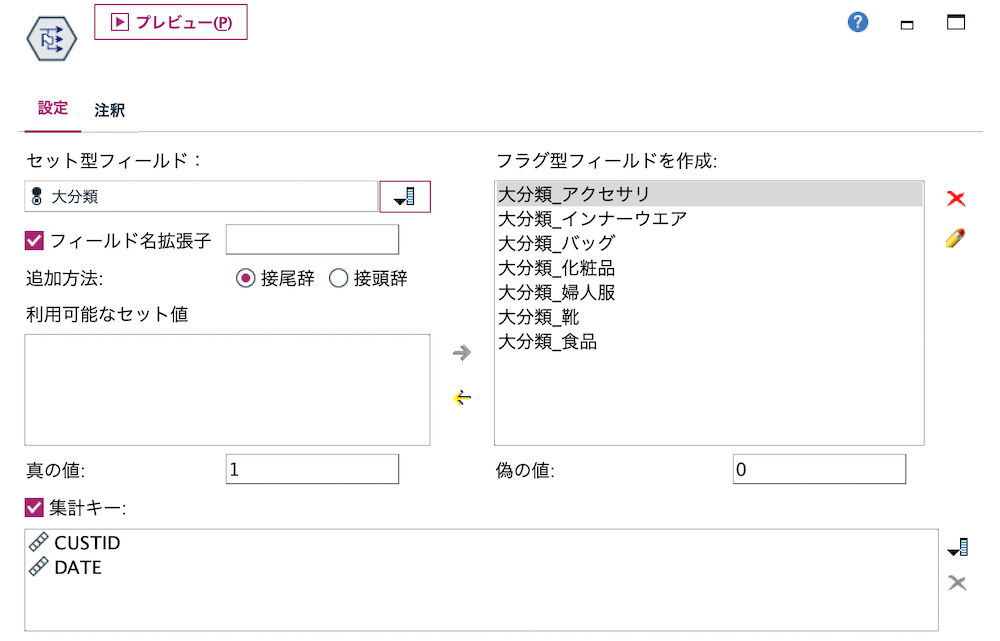
d.[フラグ設定]ノードを編集します。
e.[レコード結合]ノードを編集します。
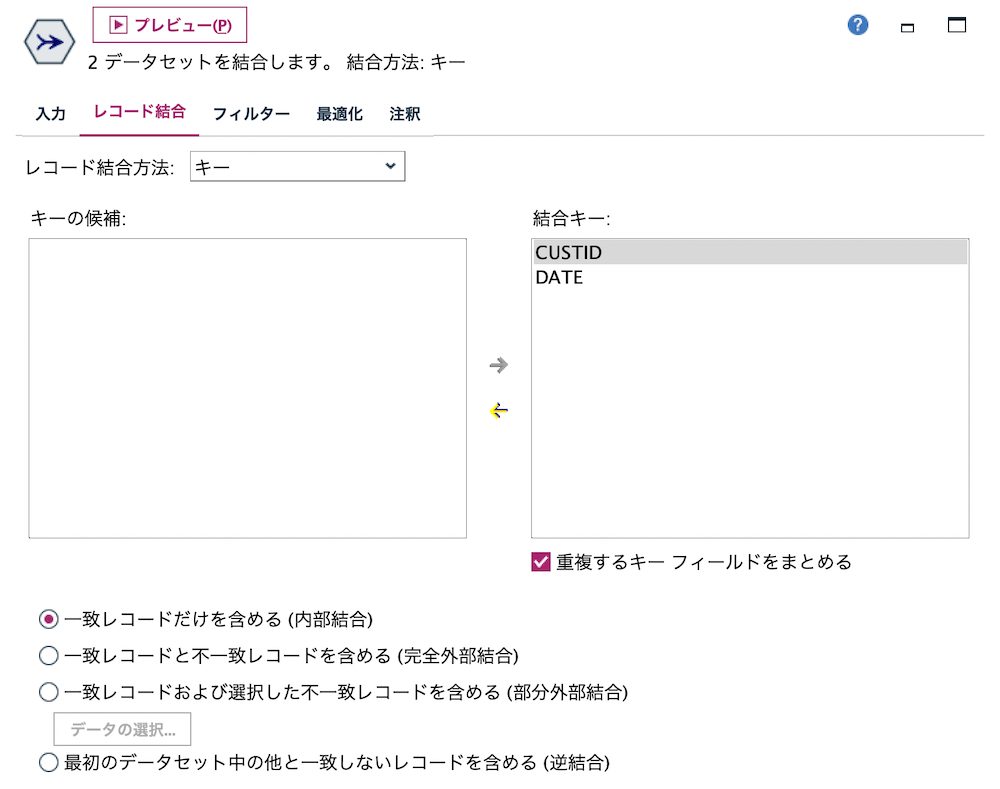
[プレビュー]します。ループの1回目で記録されるデータです。

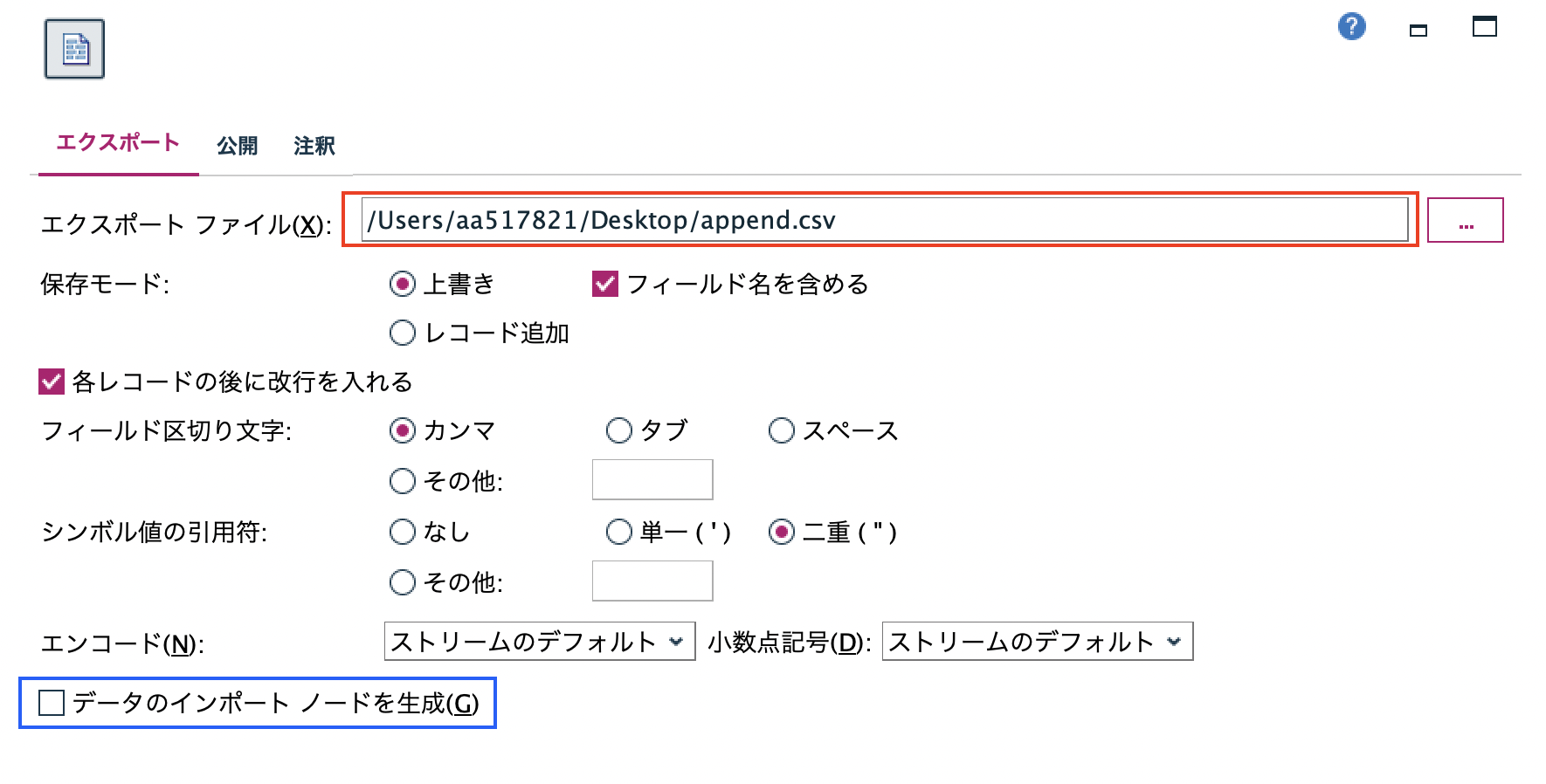
f.[フラットファイル]ノードを編集します。赤枠のように出力するテキストファイル名称とパスを記述します。青枠はチェックを入れて実行するとノードgが自動生成されます。ノードが生成されたら青枠チェックを外しておきます。
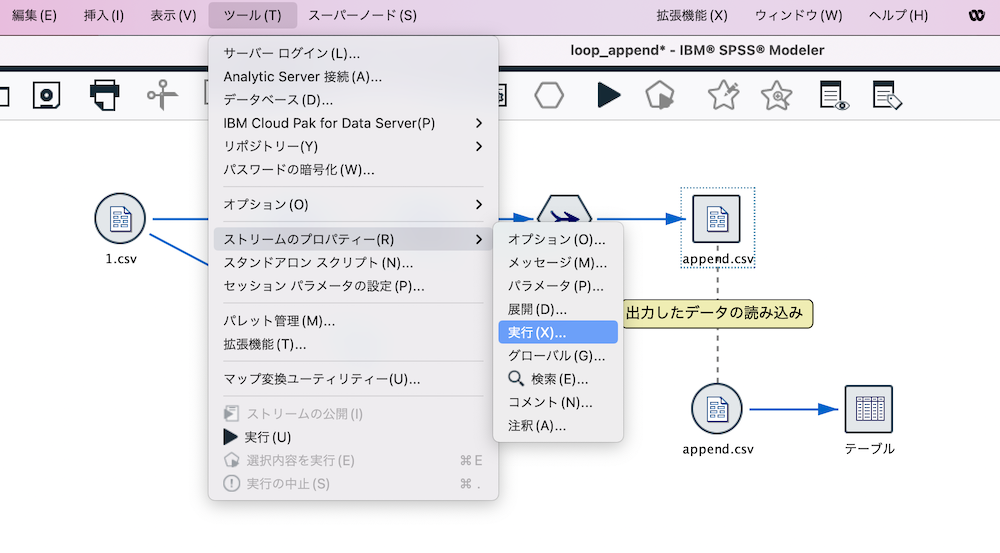
Modelerスクリプトでループを設定する
以下のメニューからスクリプト画面を開きます。
Pythonモードで以下のようにスクリプトを記述します。[このスクリプトを実行]を選択します。
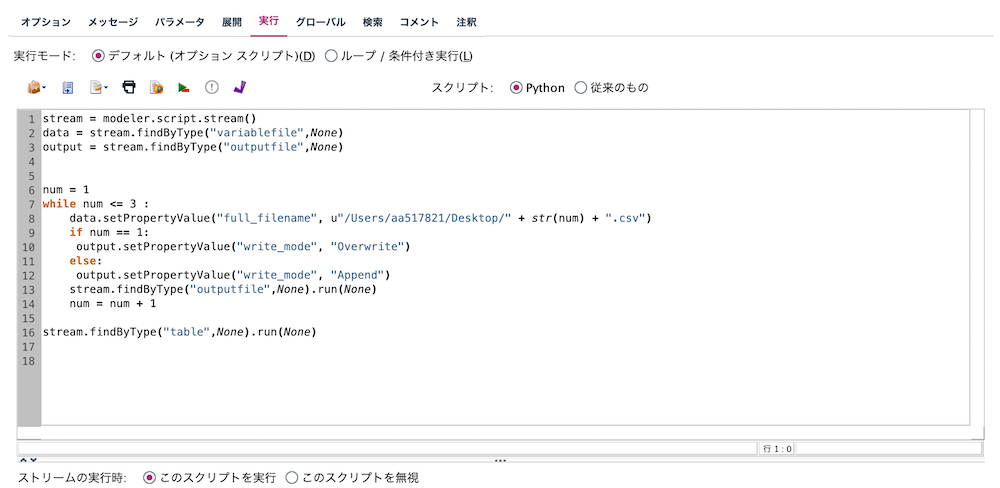
stream = modeler.script.stream()
data = stream.findByType("variablefile",None)
output = stream.findByType("outputfile",None)
num = 1
while num <= 3 :
data.setPropertyValue("full_filename", u"/Users/aa517821/Desktop/" + str(num) + ".csv")
if num == 1:
output.setPropertyValue("write_mode", "Overwrite")
else:
output.setPropertyValue("write_mode", "Append")
stream.findByType("outputfile",None).run(None)
num = num + 1
stream.findByType("table",None).run(None)
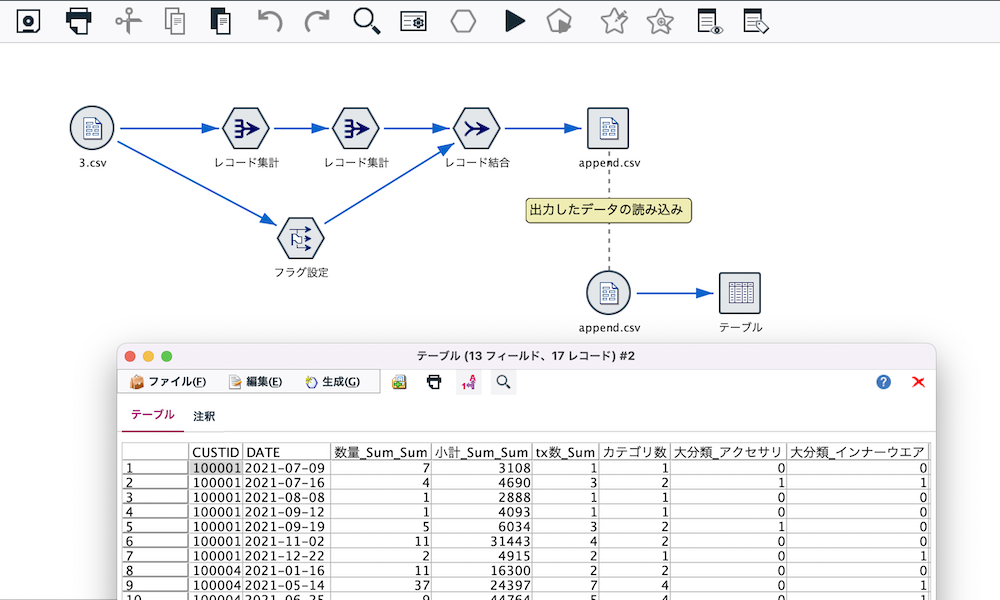
ループ処理を実行する
画面の▶︎ボタンを押すと3つのファイルが順番に加工処理され同じテーブルに統合して表示されます。
注意事項
ModelerでPythonスクリプトを用いるとき、日本語Shift-JISのノードラベルや文字列を指定する場合はご注意下さい。「u”レコード集計”」のように「u」を先頭につける必要があります。
今回はファイル名を番号にしてループしやすくしています。OSコマンドで複数のファイルをリネームすると事前の準備が楽になります。
4.参考情報
Modelerスクリプトについて解説した記事
SPSS Modeler ノードリファレンス目次
SPSS Modeler 逆引きストリーム集(データ加工)