初めに
Draw.ioで作成した図形にはいくつか保存形式があり、pngファイルはその一つである。
そして、Draw.ioはpngファイルから図形を復元することができる。自分はよく作った図形をpngファイルで共有している為、この発見は嬉しいものだった。なぜなら、Draw.ioでしか開けない.drawio形式は不便だし、共有用の.png形式との二重管理になっては管理が面倒だからだ。他の.svgや.htmlについてはなんとなく何をやってるか想像が付くが、.png形式だけはよく分からなかったのでどう情報を保持してるかを検証していく。
pngファイルの形式について
PNG バイナリは、先頭に PNG であることを示す8バイトの識別子があり、その後はチャンクと呼ばれるデータのまとまりが最後まで連なる構造になっています。各チャンクは、長さ・種別・データ・CRC という共通の構造から成り、チャンクの種別によってデータの内容が変わります。
ふむふむ。読んでると、「補助チャンク」というモノがあるらしく、そこが描画に寄与しないのであれば、そこの適当な情報をぶち込めばいいと予想。
画像を用意
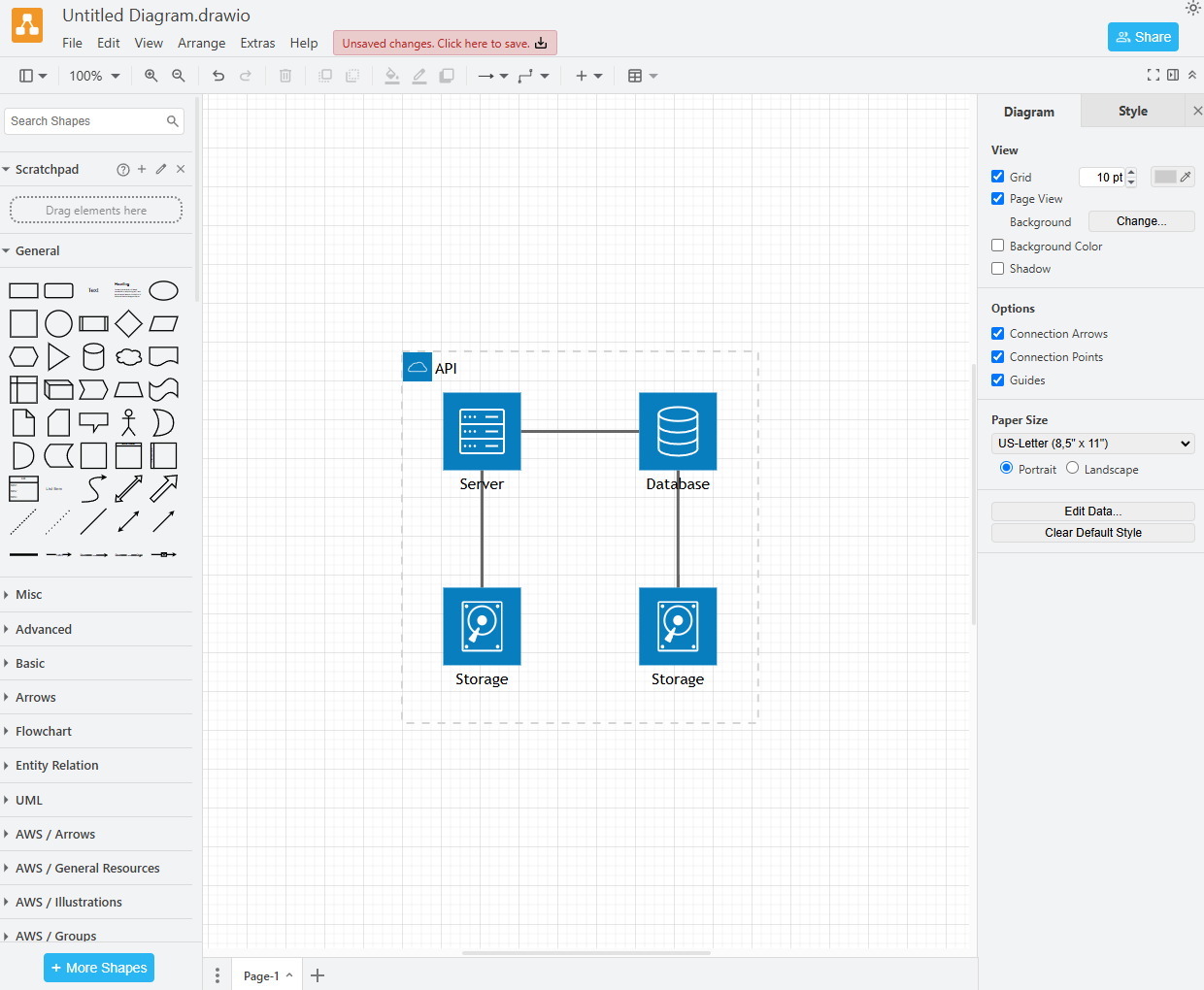
Draw.ioで適当に図を作って.png形式で保存。

比較対象として、この前飲んで美味かったラム酒の写真を使う。iPhoneで撮影したものを.png形式で保存。
では、これらのバイナリを見ていく
pngバイナリを解析
適当にチャンク毎に分割するコードを作る。
def parse_png(file_path):
with open(file_path, "rb") as f:
# シグニチャ確認
signature = f.read(8)
expected_signature = b'\x89PNG\r\n\x1a\n'
if signature != expected_signature:
print("これはPNGファイルではありません。")
return
print("PNGシグニチャを検出しました。")
# チャンクの読み込みループ
while True:
length_bytes = f.read(4)
if len(length_bytes) < 4:
print("ファイル末尾に達しました。")
break
length = int.from_bytes(length_bytes, "big")
chunk_type_bytes = f.read(4)
chunk_type = chunk_type_bytes.decode("ascii")
chunk_data = f.read(length)
crc = f.read(4)
print(f"チャンクタイプ: {chunk_type}, サイズ: {length}")
# もしIHDRなら画像の基本情報を取り出す例
if chunk_type == "IHDR":
width = int.from_bytes(chunk_data[0:4], "big")
height = int.from_bytes(chunk_data[4:8], "big")
bit_depth = chunk_data[8]
color_type = chunk_data[9]
print(f" 幅: {width}, 高さ: {height}, ビット深度: {bit_depth}, カラータイプ: {color_type}")
# IENDなら解析を終える
if chunk_type == "IEND":
print("IENDチャンクを検出しました。解析を終了します。")
break
print("======= Analyzing drawio.png =======")
parse_png("./drawio.png")
print("======= Analyzing rum.png =======")
parse_png("./rum.png")
### 実行結果
======= Analyzing drawio.png =======
PNGシグニチャを検出しました。
チャンクタイプ: IHDR, サイズ: 13
幅: 447, 高さ: 463, ビット深度: 8, カラータイプ: 6
チャンクタイプ: sRGB, サイズ: 1
チャンクタイプ: tEXt, サイズ: 17809
チャンクタイプ: IDAT, サイズ: 8192
チャンクタイプ: IDAT, サイズ: 8192
チャンクタイプ: IDAT, サイズ: 1487
チャンクタイプ: IEND, サイズ: 0
IENDチャンクを検出しました。解析を終了します。
======= Analyzing rum.png =======
PNGシグニチャを検出しました。
チャンクタイプ: IHDR, サイズ: 13
幅: 2934, 高さ: 3912, ビット深度: 8, カラータイプ: 2
チャンクタイプ: iCCP, サイズ: 2457
チャンクタイプ: cHRM, サイズ: 32
チャンクタイプ: bKGD, サイズ: 6
チャンクタイプ: tIME, サイズ: 7
チャンクタイプ: tEXt, サイズ: 119
チャンクタイプ: zTXt, サイズ: 3552
チャンクタイプ: orNT, サイズ: 1
チャンクタイプ: IDAT, サイズ: 32768
チャンクタイプ: IDAT, サイズ: 32768
チャンクタイプ: IDAT, サイズ: 32768
チャンクタイプ: IDAT, サイズ: 32768
チャンクタイプ: IDAT, サイズ: 32768
チャンクタイプ: IDAT, サイズ: 32768
チャンクタイプ: IDAT, サイズ: 32768
チャンクタイプ: IDAT, サイズ: 32768
チャンクタイプ: IDAT, サイズ: 32768
~~
大量のIDATチャンク
~~
チャンクタイプ: IDAT, サイズ: 32768
チャンクタイプ: IDAT, サイズ: 32768
チャンクタイプ: IDAT, サイズ: 32768
チャンクタイプ: IDAT, サイズ: 32768
チャンクタイプ: IDAT, サイズ: 32768
チャンクタイプ: IDAT, サイズ: 32768
チャンクタイプ: IDAT, サイズ: 32129
チャンクタイプ: eXIf, サイズ: 26
チャンクタイプ: tEXt, サイズ: 37
チャンクタイプ: tEXt, サイズ: 37
チャンクタイプ: tEXt, サイズ: 40
チャンクタイプ: tEXt, サイズ: 40
チャンクタイプ: tEXt, サイズ: 26
チャンクタイプ: IEND, サイズ: 0
IENDチャンクを検出しました。解析を終了します。
drawio.png の特徴
- sRGB チャンク: サイズ 1
- tEXt チャンク: サイズ 17809 ← ここが妙に大きい
- IDAT チャンク: 8192, 8192, 1487 バイト
- IEND チャンク
rum.png の特徴
- iCCP, cHRM, bKGD, tIME, tEXt, zTXt, orNT …などの複数のメタデータ系チャンクがある
- IDAT チャンク: たくさん(基本 32768 バイト)
- eXIf チャンク: 26 バイト
- tEXt チャンク: 37, 37, 40, 40, 26 バイトなど比較的小さめ
- IEND チャンク
それぞれどのようなチャンクをまとめた。
| チャンク名 | 説明 |
|---|---|
| iCCP | 画像の正確な色再現を行うために使用される International Color Consortium (ICC) プロファイル |
| cHRM | 画像の色度 (Chromaticity) 情報を格納するための標準チャンク |
| bKGD | 背景色 (Background Color) を指定するための標準チャンク |
| tIME | 画像ファイルの最終更新時刻 (Last-Modified time) を表す標準チャンク |
| tEXt | テキストデータを格納する標準チャンク |
| zTXt | テキストデータを zlib で圧縮して格納する標準チャンク |
| orNT | 不明(標準外のカスタムチャンク)。orientation(向き情報)に関連する可能性あり |
| IDAT | 画像データ本体 (ピクセル情報) を zlib 形式で圧縮して格納するチャンク |
まず、tEXtとzTXtは表示に直に関わらず、情報を保存できるので最も怪しい。そして、drawio.pngにはそのうちtEXtしかない為、ここに図形情報が埋め込まれてるとみてまず間違いない。
ここから、tEXtの中身を見ていく
def extract_text_chunks(png_path):
with open(png_path, "rb") as f:
# シグニチャ確認
signature = f.read(8)
if signature != b'\x89PNG\r\n\x1a\n':
raise ValueError("Not a valid PNG file.")
text_chunks = []
# チャンクの読み込みループ
while True:
length_data = f.read(4)
if len(length_data) < 4:
break
length = int.from_bytes(length_data, byteorder="big")
chunk_type = f.read(4)
if len(chunk_type) < 4:
break
chunk_type_str = chunk_type.decode("ascii", errors="replace")
chunk_data = f.read(length)
f.read(4)
# tEXt チャンクの場合
if chunk_type_str == "tEXt":
null_pos = chunk_data.find(b'\x00')
if null_pos != -1:
key = chunk_data[:null_pos].decode("utf-8", errors="replace")
value = chunk_data[null_pos+1:].decode("utf-8", errors="replace")
text_chunks.append((key, value))
if chunk_type_str == "IEND":
break
return text_chunks
if __name__ == "__main__":
text_data_list = extract_text_chunks("./drawio.png")
for key, value in text_data_list:
print(f"Key: {key}")
print(f"Value: {value}")
print("-----")
実行結果

なんとなくURLエンコードっぽい?
デコードしてみる
import urllib.parse
raw_value = """
%3Cmxfile%20host%3D%22app.diagrams.net%22%20...
"""
decoded_str = urllib.parse.unquote(raw_value)
print("======= decoded_str =======")
print(decoded_str)
実行結果
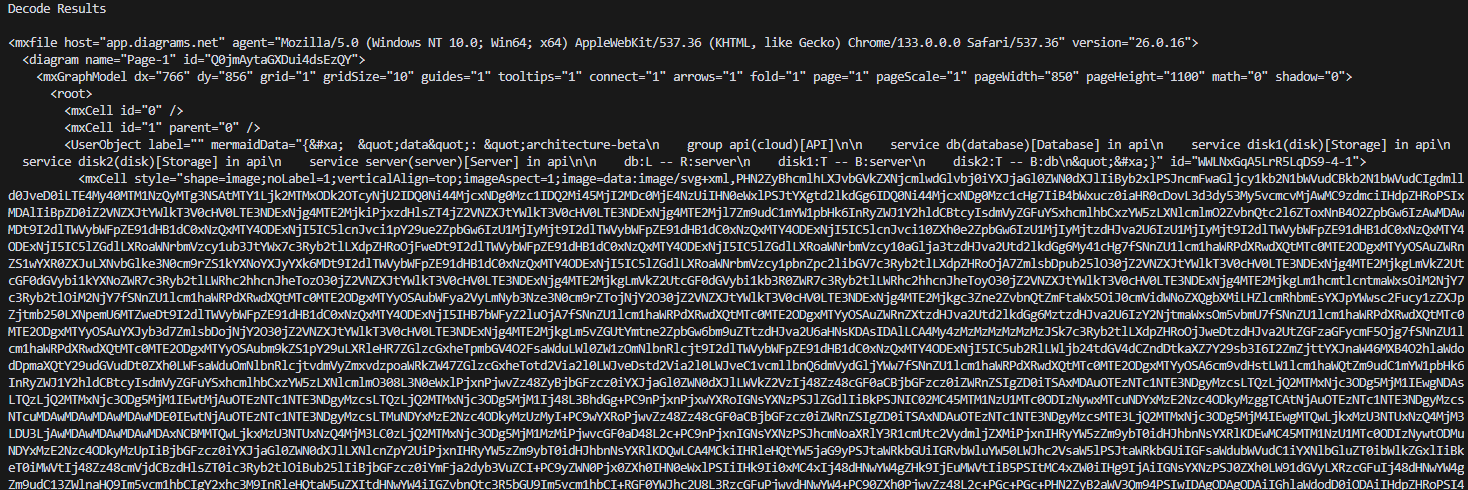
XMLだ。Draw.ioの図形は実はMermaidで作ったから、それらしき属性も見える。UserObjectの中ももう少し見れるかな?
import urllib.parse
import html
raw_xml = r'''
# write your xml here
'''
import xml.etree.ElementTree as ET
root = ET.fromstring(raw_xml)
userobject_elem = root.find('.//UserObject')
if userobject_elem is not None:
mermaid_data_str = userobject_elem.attrib.get('mermaidData', '')
decoded_mermaid = html.unescape(mermaid_data_str)
print("=== HTML Unescaped mermaidData ===")
print(decoded_mermaid)
実行結果
=== HTML Unescaped mermaidData ===
{
"data": "architecture-beta\n group api(cloud)[API]\n\n service db(database)[Database] in api\n service disk1(disk)[Storage] in api\n service disk2(disk)[Storage] in api\n service server(server)[Server] in api\n\n db:L -- R:server\n disk1:T -- B:server\n disk2:T -- B:db\n"
}
最終的に元画像で使ってたアイコン名が乗ったjsonファイルまで辿ることができた。
移植実験
Draw.ioの出力するpngファイルがどういう構造になったか分かったので、最後にXML形式のレシピをrum.pngに移植して、Draw.ioで読み込ませた時に図形が復元できるか実験して終わろうと思う。
多分、Draw.ioでは.png形式をインポートしたとき、最初のチャンクがsRGB->tEXtの順番じゃないと読み込んでくれない予感があるので、rum.pngに元からある不要なチャンクは消して調整していく。
def extract_chunk_by_type(file_path, target_types):
with open(file_path, "rb") as f:
signature = f.read(8)
if signature != b'\x89PNG\r\n\x1a\n':
raise ValueError("Not a PNG file.")
chunks = []
while True:
length_bytes = f.read(4)
if len(length_bytes) < 4:
break
length = int.from_bytes(length_bytes, "big")
chunk_type_bytes = f.read(4)
chunk_type_str = chunk_type_bytes.decode("ascii", errors="replace")
chunk_data = f.read(length)
crc = f.read(4)
if chunk_type_str in target_types:
chunks.append((chunk_type_str, chunk_data, crc))
if chunk_type_str == "IEND":
break
return chunks
def build_minimal_drawio_png(src_png_for_idat, src_png_for_srgb_text, out_png):
keep_types = {"IHDR", "IDAT", "IEND"}
rum_chunks = extract_chunk_by_type(src_png_for_idat, keep_types)
insert_types = {"sRGB", "tEXt"}
drawio_chunks = extract_chunk_by_type(src_png_for_srgb_text, insert_types)
ihdr_chunks = [(t, d, c) for (t, d, c) in rum_chunks if t == "IHDR"]
idat_chunks = [(t, d, c) for (t, d, c) in rum_chunks if t == "IDAT"]
iend_chunk = [(t, d, c) for (t, d, c) in rum_chunks if t == "IEND"]
srgb_chunks = [(t, d, c) for (t, d, c) in drawio_chunks if t == "sRGB"]
text_chunks = [(t, d, c) for (t, d, c) in drawio_chunks if t == "tEXt"]
# もしIHDRやIENDが見つからなかったら失敗
if not ihdr_chunks:
raise ValueError("No IHDR found in rum.png!")
if not iend_chunk:
raise ValueError("No IEND found in rum.png!")
# 抽出したチャンクからpngファイルを作成
with open(out_png, "wb") as f_out:
f_out.write(b'\x89PNG\r\n\x1a\n')
for (t, d, c) in ihdr_chunks:
length_bytes = len(d).to_bytes(4, "big")
f_out.write(length_bytes)
f_out.write(t.encode("ascii"))
f_out.write(d)
f_out.write(c)
for (t, d, c) in srgb_chunks:
length_bytes = len(d).to_bytes(4, "big")
f_out.write(length_bytes)
f_out.write(t.encode("ascii"))
f_out.write(d)
f_out.write(c)
for (t, d, c) in text_chunks:
length_bytes = len(d).to_bytes(4, "big")
f_out.write(length_bytes)
f_out.write(t.encode("ascii"))
f_out.write(d)
f_out.write(c)
for (t, d, c) in idat_chunks:
length_bytes = len(d).to_bytes(4, "big")
f_out.write(length_bytes)
f_out.write(t.encode("ascii"))
f_out.write(d)
f_out.write(c)
(t, d, c) = iend_chunk[0]
length_bytes = len(d).to_bytes(4, "big")
f_out.write(length_bytes)
f_out.write(t.encode("ascii"))
f_out.write(d)
f_out.write(c)
print(f"Result: {out_png}")
if __name__ == "__main__":
build_minimal_drawio_png(
src_png_for_idat="rum.png",
src_png_for_srgb_text="drawio.png",
out_png="result.png"
)
さて、出来上がったこのresult.pngをDraw.ioに読み込ませてみる。

↓ File>Open from>Device>result.png
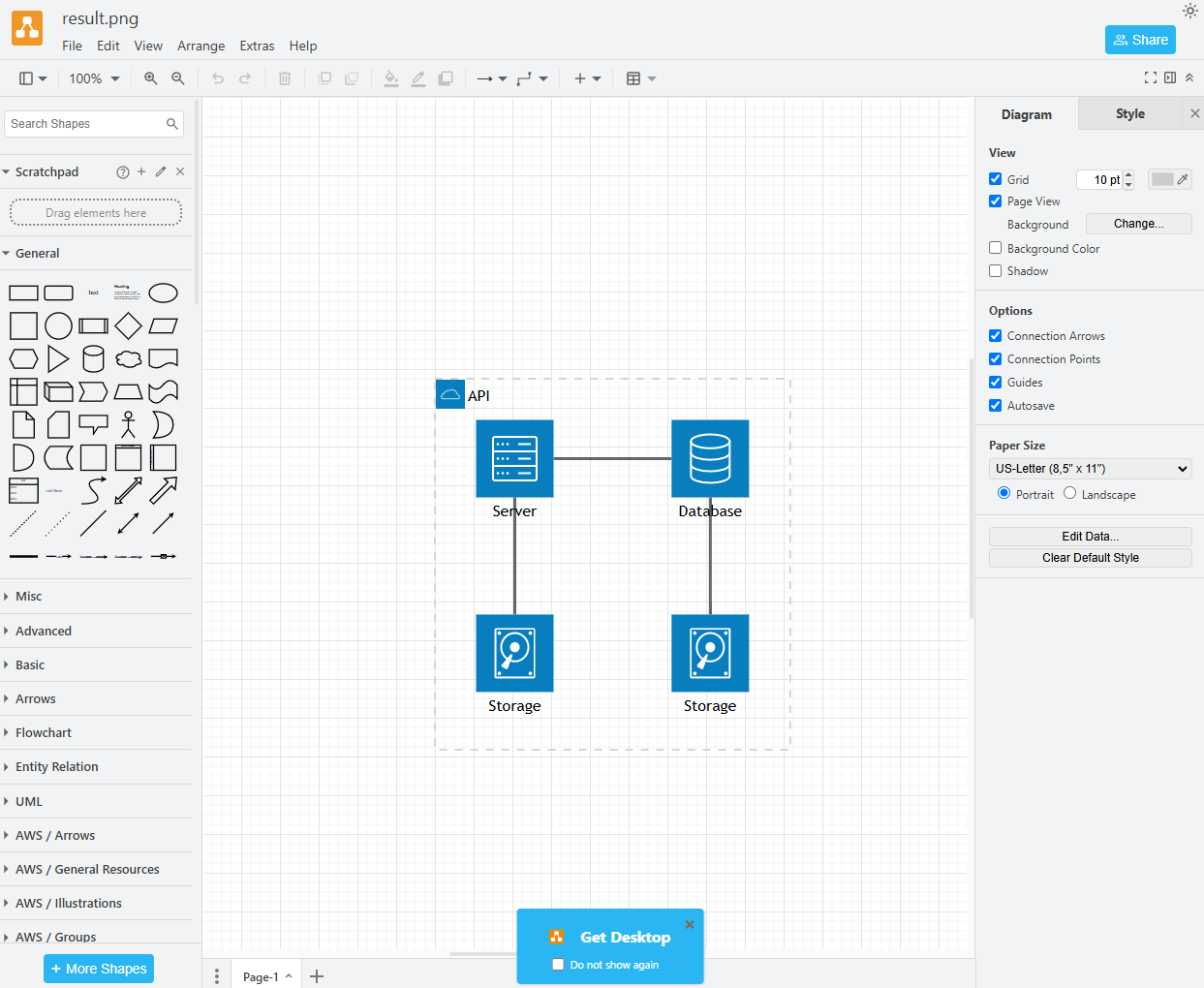
出来た。
おまけ
最後にTwitterへDraw.ioで保存した.pngファイルをアップロードし、再ダウンロードすることで、描画に不要なチャンクが抜け落ちるか確認してみる。ちなみに、3年ぐらい前にjpgファイルで実行ファイルを仕込む実験をしていたが、この時は実行ファイル分のチャンクは消し飛んでた。
result.pngと再ダウンロードした物の比較
======= Analyzing result.png =======
PNGシグニチャを検出しました。
チャンクタイプ: IHDR, サイズ: 13
幅: 2934, 高さ: 3912, ビット深度: 8, カラータイプ: 2
チャンクタイプ: sRGB, サイズ: 1
チャンクタイプ: tEXt, サイズ: 17809
チャンクタイプ: IDAT, サイズ: 32768
チャンクタイプ: IDAT, サイズ: 32768
~~
大量のIDATチャンク
~~
チャンクタイプ: IDAT, サイズ: 32768
チャンクタイプ: IDAT, サイズ: 32768
チャンクタイプ: IDAT, サイズ: 32768
チャンクタイプ: IDAT, サイズ: 32129
チャンクタイプ: IEND, サイズ: 0
IENDチャンクを検出しました。解析を終了します。
======= Analyzing png that was uploaded to twitter =======
PNGシグニチャを検出しました。
チャンクタイプ: IHDR, サイズ: 13
幅: 2934, 高さ: 3912, ビット深度: 8, カラータイプ: 2
チャンクタイプ: pHYs, サイズ: 9
チャンクタイプ: tEXt, サイズ: 17
チャンクタイプ: tEXt, サイズ: 19
チャンクタイプ: zTXt, サイズ: 45
チャンクタイプ: IDAT, サイズ: 9356332
チャンクタイプ: IEND, サイズ: 0
IENDチャンクを検出しました。解析を終了します。
tEXtの内容は消し飛び、Draw.ioで開くことはできなかった。
おわり