表と裏
思い起こせば去年も「【Power BI】表でやるか、裏でやるか」というタイトルでMicrosoft Power BI Advent Calendar 2018に記事を投稿させて頂きました。
記念すべきQiita初ポスト!ウェーイ。
表というのはわたし用語でレポート作成画面のこと。裏はPower Queryの編集画面のことです。
記事の内容は、Power BIでレポート作成中に、項目が足りなくて表で作ったり、裏に戻ったりしちゃうんだけど、ちゃんと最初から設計して、どっちかに寄せた方がいいと思っている、というお話。
でも、この記事で書いたレポートは、データは2万行弱くらいでパフォーマンス的に言うとどっちでやっても多分さほど違いはない。
ただし、2019冬のレポートは違います。
2019冬 3000万行データのレポートを最適化せよ!
こんなレポートを作ったと仮定します。
- フレーバーが200種類あるアイスクリーム屋さんの販売実績データ。
- 販売日付、顧客ID、販売フレーバー名のリスト。3000万行。
- 顧客IDはレジで一意に付番される。1顧客あたり平均で8フレーバーほど購入するので、400万IDくらい。
- このリストから、弊社のおススメ16フレーバーセットを購入した顧客ID数をカウント。
- おススメフレーバーセットは全部で7種類!
これをどうやって集計しようか考えて・・・
1)表で、各販売フレーバーがおススメセットに該当するかどうかのフラグを立てる列を作成。(IF文)
2)顧客IDごとに1)のフラグを合計して16になる顧客ID数をカウント。
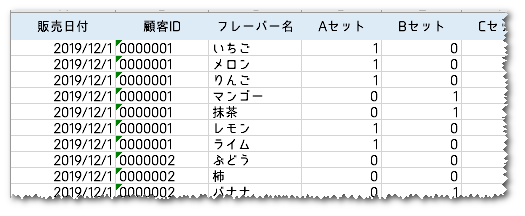
データはこんな感じになります。
ちなみに、1)のIF文はこんな感じ。
Aセット = if (
'販売データ[フレーバー名]="いちご" || '販売データ[フレーバー名]="メロン" ||
'販売データ[フレーバー名]="りんご" || '販売データ[フレーバー名]="レモン" ||
'販売データ[フレーバー名]="ライム" || '販売データ[フレーバー名]="オレンジ" ||
'販売データ[フレーバー名]="みかん" || '販売データ[フレーバー名]="ゆず" ||
'販売データ[フレーバー名]="すいか" || '販売データ[フレーバー名]="もも" ||
'販売データ[フレーバー名]="なし" || '販売データ[フレーバー名]="キウイ" ||
'販売データ[フレーバー名]="パイン" || '販売データ[フレーバー名]="ライチ" ||
'販売データ[フレーバー名]="ブルーベリー" || '販売データ[フレーバー名]="ラズベリー",1,0)
で、こんな風に7種類のセットについて月別の販売セット数をマトリクスと折れ線グラフにだしたら、
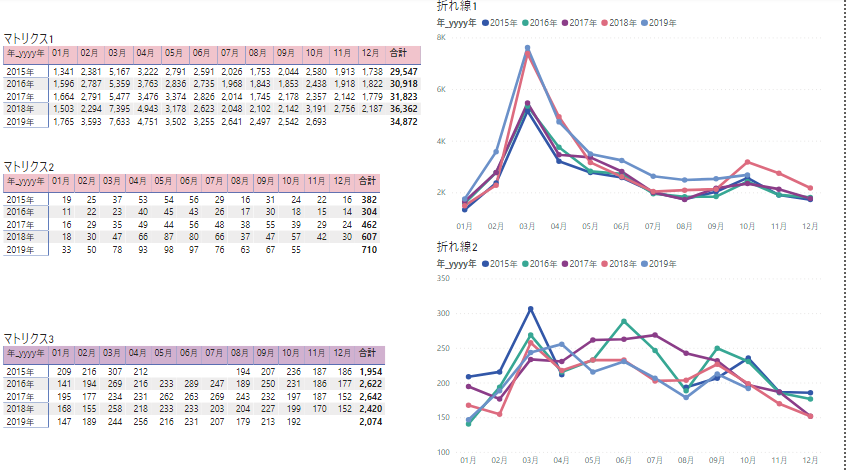
重い!!!
表示が遅くて、結構ぐるぐるが回っています・・・・。
というわけで、これをどうにかしてちょっとでも早くできないか、と、拙いスキルで色々やってみた、というお話です。
①表でIF文列
②裏でIF文列
③裏でセットマスタ
④表でセットマスタ
この4種類を試して、パフォーマンスアナライザーで表示までの時間を計測してみました。
・条件をなるべく同じにするために、エクスプローラー以外の他のアプリを全て終了。
・pbixファイルを開いた時に空白ページが表示されるように保存。
・ファイルが開いたらすぐに 表示→パフォーマンスアナライザー→記録の開始 で、前述の折れ線×2、マトリクス×3のページへ遷移
・その後、ビジュアルの更新を2回試す。
①表でIF文
前述の通りに表で長ったらしいIF文列を追加して、メジャーでカウントしたレポートです。
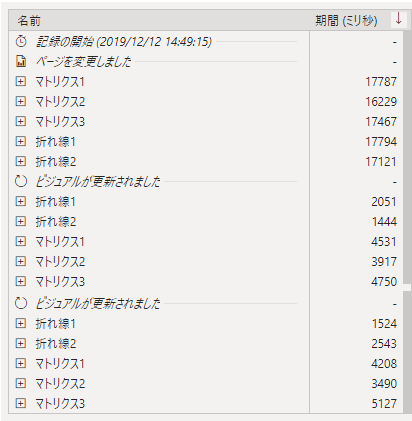
表示されるのは折れ線が早いのですが、時間はどちらも同じくらいなのが意外でした。
②裏でIF文
①の長ったらしいIF文列を、表ではなく裏で追加しました。
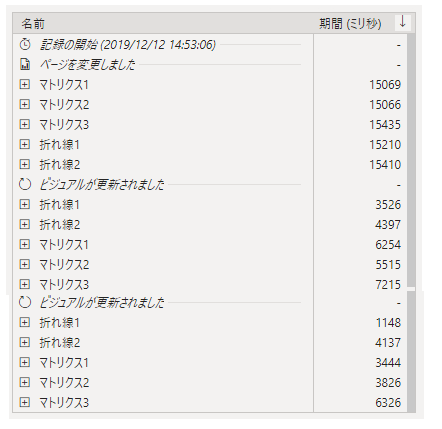
①より2秒ほど早いくらい。めっちゃ最適化!というわけでもなく。
そして、2回目、3回目の更新が、①より全体的に遅くなってるのが気になります。
③裏でセットマスタ
1)↓のようなセットマスタを作成して、各セットごとにフレーバー名にマージしてフレーバー名を展開。
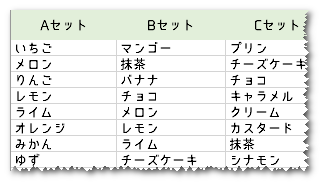
つまり、セットマスタのAセットの列とトランザクションデータのフレーバー名、セットマスタのBセットの列とトランザクションデータのフレーバー名・・・・とGセットまでそれぞれ7回マージして、それぞれのセットの列を展開。
2)それから、各セットの列がnullだったら0、nullじゃなかったら1というフラグを立てる条件列をそれぞれ作成。
3)そのフラグを表のメジャーで顧客IDごとに合計して16になる顧客ID数を集計
結果。
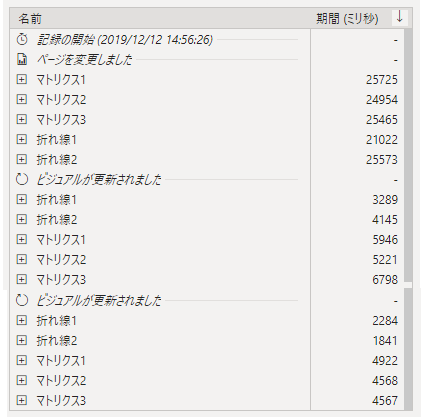
うーん、遅い・・・
裏でしこたまマージしたのが原因でしょうか?
④表でセットマスタ
1)↑のセットマスタから、SUMMARIZE関数で各セットごとのテーブルを作成、リレーション。
2)LOOKUPVALUE関数で、トランザクションデータのテーブルに各セットのフラグ列を作成。
こんな感じです。
AセットF =
IF (
ISBLANK ( LOOKUPVALUE ( 'Aセット'[Aフレーバー名], 'Aセット'[Aフレーバー名], '販売データ'[フレーバー名] ) ),
0,
1
)
3)そのフラグをメジャーで顧客IDごとに合計して16になる顧客ID数を集計
結果。
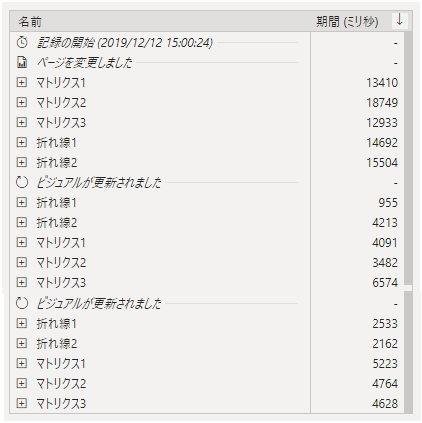
今までで一番マシな②より微妙に早かったり遅かったり・・・・。
とりあえずの結果
③以外はどれも五十歩百歩というところでした。めっちゃ最適化できた!というオチがなくすみません・・・。わたしもがっかりです・・・。
ただし、この4種類のレポートを作成しながら、原因はこのモーレツIF文列だけではなく、他にもあるなと思ったので、この記事はVol.2に続けたいと思います。
...to be continued