準備:Transformer Based AutoEncoder (TBA)
先日、VRChatML集会という場でTransformerを利用したAutoencoderの実装について話す機会がありました。
以下はその時のスライドです。
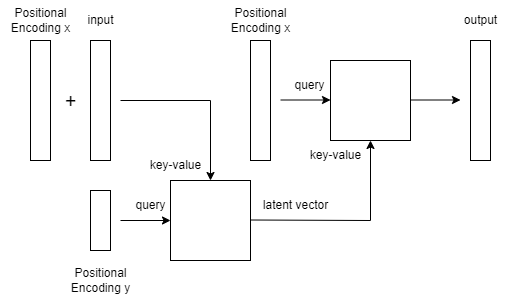
紹介したモデルは2つのTransformerDecoder(それぞれEncoder、Decoderとします)を用いたAutoEncoderとなっています。
EncoderのKey-Value側に圧縮したいデータをPositionalEncoding xと共に突っ込み、Query側にはPositionalEncoding yのみを突っ込みます。xの長さよりyの長さを短くすることで系列長さ方向の圧縮ができ、例えば長さ1024の系列を長さ512に圧縮するということができます。
DecoderではKey-Value側に圧縮した潜在ベクトル系列を突っ込み、Query側ではPositionalEncoding xを突っ込むことでデータの復元を行います。
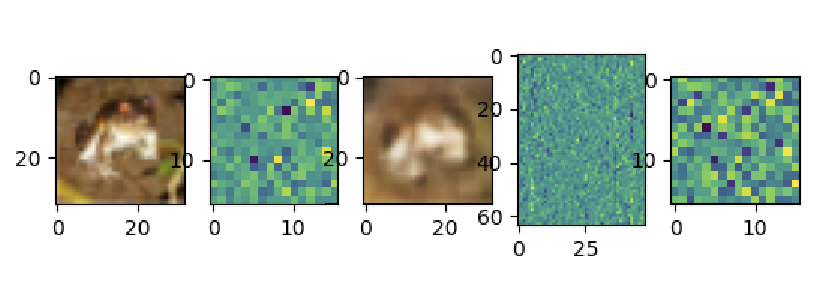
CIFAR10の画像を用いた実験では圧縮した潜在ベクトル系列から元の画像の特徴を持った画像が復元されるのが確認できました。
下の画像は左から元画像、圧縮した潜在ベクトル系列、復元画像、画像用のPositionalEncoding、潜在ベクトル用のPositionalEncodingとなっています。
使用したコードはGistにおいてあります。
https://gist.github.com/myxyy/0e06c430652b35cda4d56aaf21eb7fa9
Transformer U-Net (TUNet)
TBAでEncoderのKey-Valueに突っ込むデータとDecoderのQueryに突っ込むデータは同じ形をしているので、Decoderに圧縮前のデータを突っ込んでみたくなります。
やってみましょう。
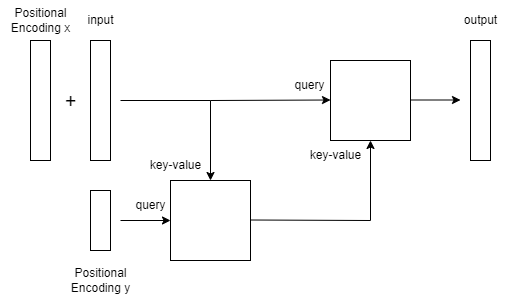
この図では上の段の圧縮前データと下の段の圧縮後データの2つのデータの流れがあり、それぞれに対してSelfAttention等の処理を行うことで局所的な情報と大域的な情報を並列に処理できそうだという気持ちがあります。
またこのモデルは段数を増やして下図のような再帰的な構造にすることができます。
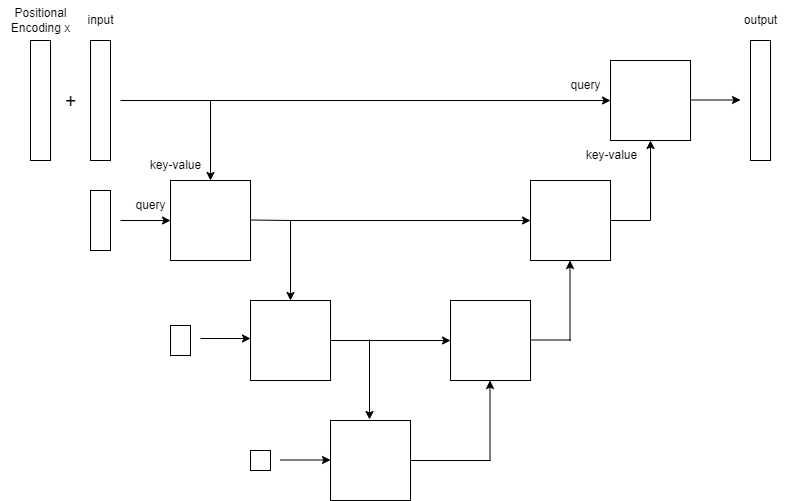
U-Netに構造が似ているため安直にこのモデルを Transformer U-Net (TUNet) と呼ぶことにします。
TUNetによる時系列データ予測
TUNetを用いて言語モデル等の時系列データ予測を行う際に問題となるのが未来方向へのマスキングです。
GPT等のSelfAttentionのみを用いたモデルでは現在の次のインデックスの情報を予測する際、未来方向の情報が混ざるのを防ぐためにQueryとKeyを乗算した行列にたいして下図のような三角行列のマスクを掛けます(実装上はSoftmaxを適用する前に要素が0と-∞で構成されるマスクを加算します)、
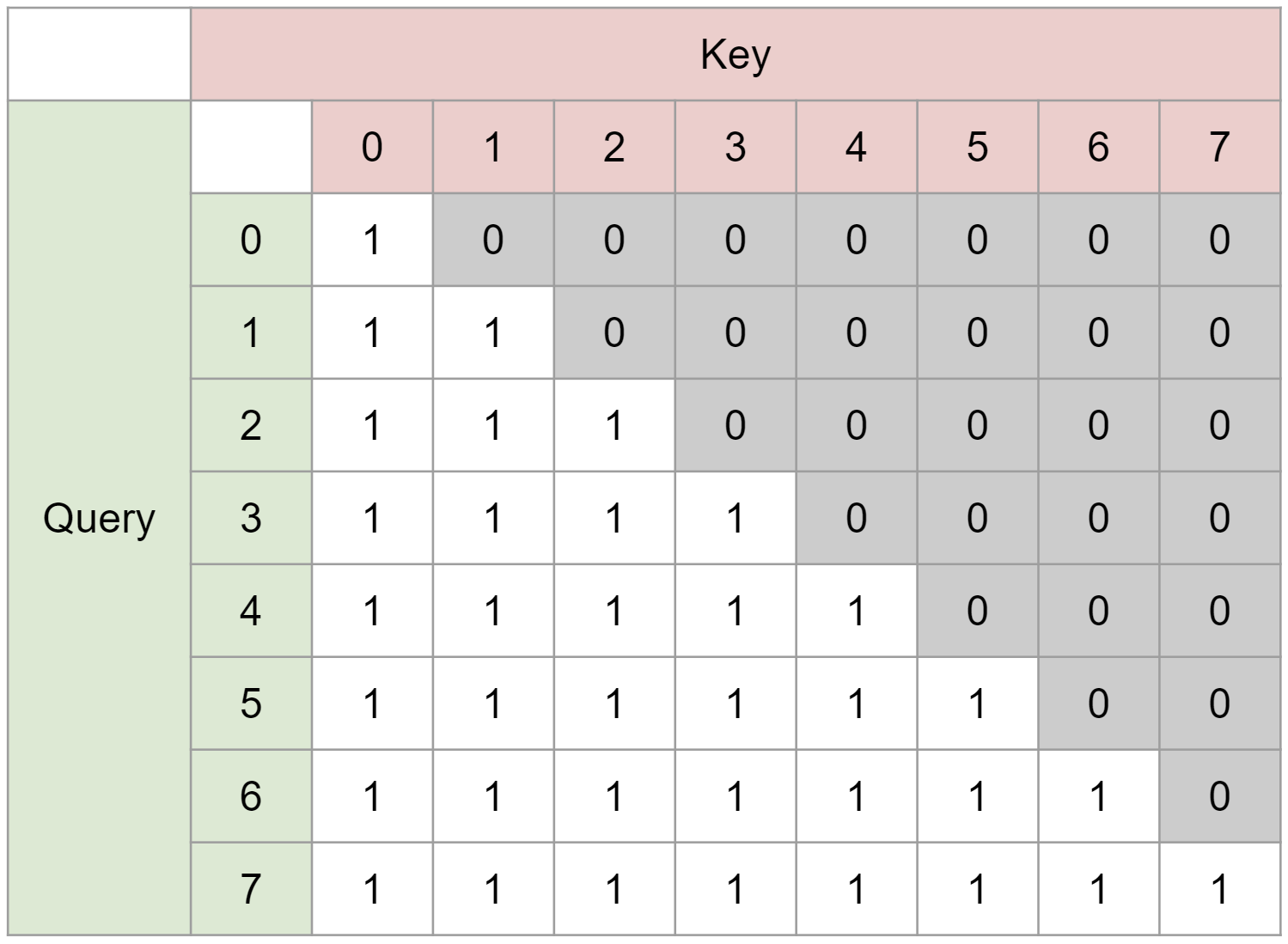
TUNetではCrossAttetionを用いており、CrossAttention部分で未来の情報が混ざらないような工夫が新たに必要となります。
そこで、Encoder側とDecoder側に対してそれぞれ、
- Encoderで圧縮した情報はある時点以前の情報しか見えない
- Decoderで復元する情報はある時点以降の推論にしか影響しない
ようなマスクを適用します。
具体例として長さ8の系列を長さ4に圧縮する場合のEncoder、Decoderのマスクを示します:
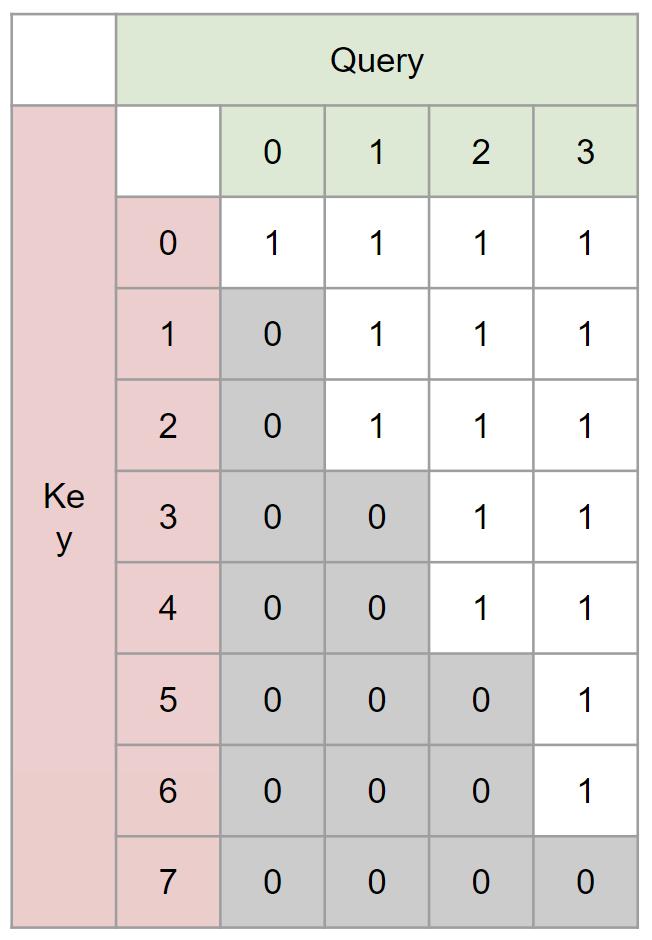
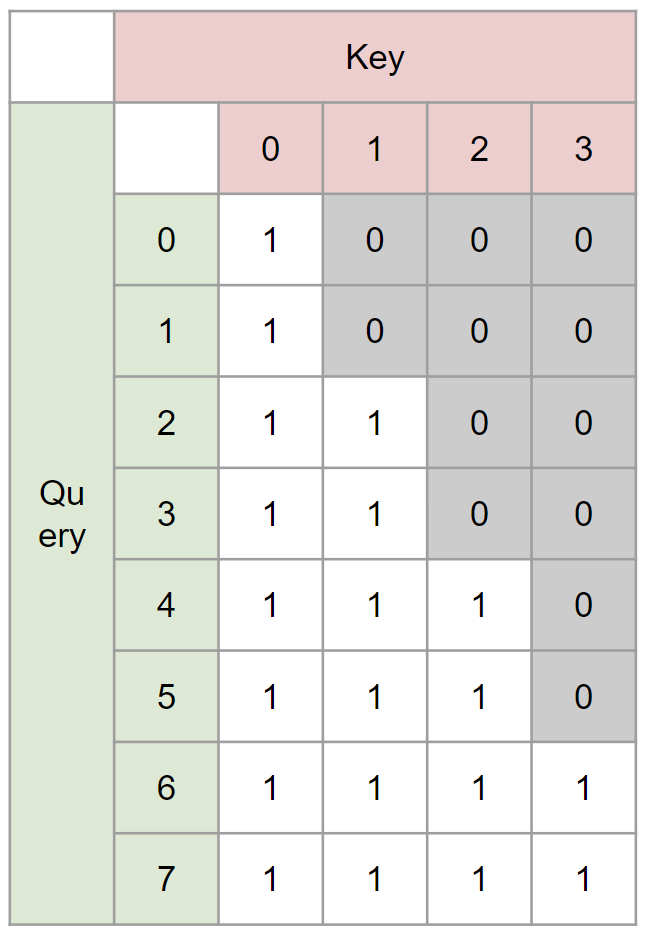
例えば圧縮後インデックス2のデータには圧縮前インデックス4以前の情報しか入ってこない一方で、圧縮後インデックス2のデータから復元した情報は圧縮前インデックス4以降の情報にしか影響を及ぼさないという時間に対して一方向のデータの流れがあります。
実験:TUNetによる言語モデル
モデル
実験時のコミットはGitHubにあります:
https://github.com/myxyy/TransformerUNet/tree/c8694609b10860d7e1a3172213a321b3b46f0233
2023-03-31追記:少し修正して実験しました:
https://github.com/myxyy/TransformerUNet/tree/5f4aaff90bce6c04a13326152ed6e2a37d0930c6
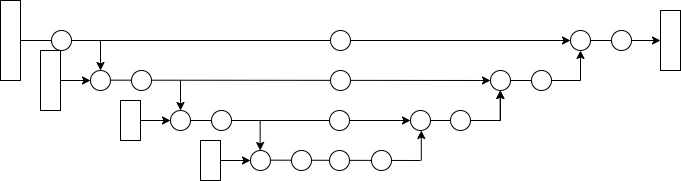
通常のTransformerDecoderはCrossAttentionとSelfAttentionの両方を使った構造となっていますが、TUNetの実験を行うにあたってCrossAttentionとSelfAttentionの効果を分離した気持ちがあったので以下のようなSelf/Cross Multi-Head Attention+FFNの構造を採用しています。またなんとなくLayerNormalizationは前段に入れています。
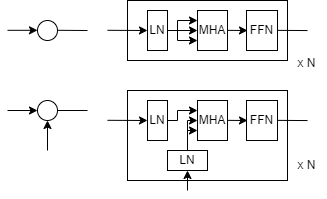
矢印が1本入ってくる丸でSelfAttentionを、矢印が2本入ってくる丸でCrossAttentionを表します。実験ではN=2としました。
実験で使用したモデルでは各段の
- 圧縮前データがEncoderに入る前(分岐前)
- 圧縮前データがEncoderに入った後(分岐後)
- 圧縮前データと圧縮後データがDecoderで処理された後(合流後)
の3カ所でSelfAttentionを行います。
文章だと分かりづらいですが図だとこんな感じになります:
実験では初期系列長は1024とし、段が下がる毎に512, 256, ..., 1と系列長が0.5倍されるようにしました。また段が下がる毎に次元数が1.2倍されるようになっていて、初期次元数は256としました。
データセットはこちらの夏目漱石の文章を利用させていただきました。トークナイズやBytePairEncoding等の処理は行わずバイト列として処理します。テキストのバイト列を1Byteずつすらしながら1024Byteずつ切り出したものをデータセットとしています。
実験結果
学習が終わったら書きます。
予備実験では以下のような出力が得られています。
0.3くらいのときの様子 pic.twitter.com/U1gc877khf
— みきしぃ (@3405691582) February 14, 2023
2023-03-31追記
4epochほど回した結果training lossが0.4程度となりました。
以下がプロンプトに対する1024バイト分の出力例となります。
支離滅裂な文章ですが日本語文法はそれなりに学習できているようです。
終端の�はUTF-8のバイト列が中途半端なところで出力が終わっているために出力されたエラー文字です。
今回学習では簡単のためEOS等の特殊トークンは用いませんでした。
prompt:吾輩は猫である
吾輩は猫である事を忘れている。
そうして、これが一番心配権利である。
この一番心配権以外には何となく生のあるのもあるから、まず二百代子の家へ来てこの女は寝ていたのだ。
この女はいまだかつても気に入らぬというよりも、まず一歩寝ていた。
当時に今来の秘密などを苦にして、証拠の初めたか、これから人が難有いと思っていたのも、もし当世のものと誤解がなくなったのとは無論察したら、昔し此象徴の方が小過失だって自家の事より考えるところで、全く陥るのと同じ事であるが、そう書いてあるというのではない。
我臭に入ろうとしたところで、秘の家を忘れた、事実はある人が頭々と通っている間、諧謔したあとで、その様子が他の始めてある一というようなものが山の手に這入るかも知れない。
最後にこの違ったところがようやくそ�
prompt:私はその人を常に先生と呼んでいた
私はその人を常に先生と呼んでいた時、彼はその時の私にはいってくれた。
しかし先生の態度ではなかった。
自分の親切に対する言葉の意味は、どうしても先生の掛念を持ち出した。
私はそれほどの人なら、ただいまだいっこう想像していたのではなかろうかといった。
私は再び書物の上にしてくれた。
こうして根本的な建築を支配した。
そうして私はまた当分の返事を少しこの所置になるというので、引き受ける見込はあるまいと思った。
私は喧嘩をする事にした。
そうして大自分の存在を繰り返して行った。
前申した義理は、毫も私をいうのでないと私は自分一人にしていて、述べ立てたものを、やはり雑談し得た。
この場合に今時と先生から意味ができているから、私には無理の意味が解らなかった。
私は答を争つけてやる女の手を出した。
そ�
実験セッティングを手元の環境で回したところRTX3090で4epoch回すのに13日程度かかりました。
学習曲線は以下のようになっています。学習が飽和するまで回すつもりでしたがまだ損失が下がりそうな気配はあります。
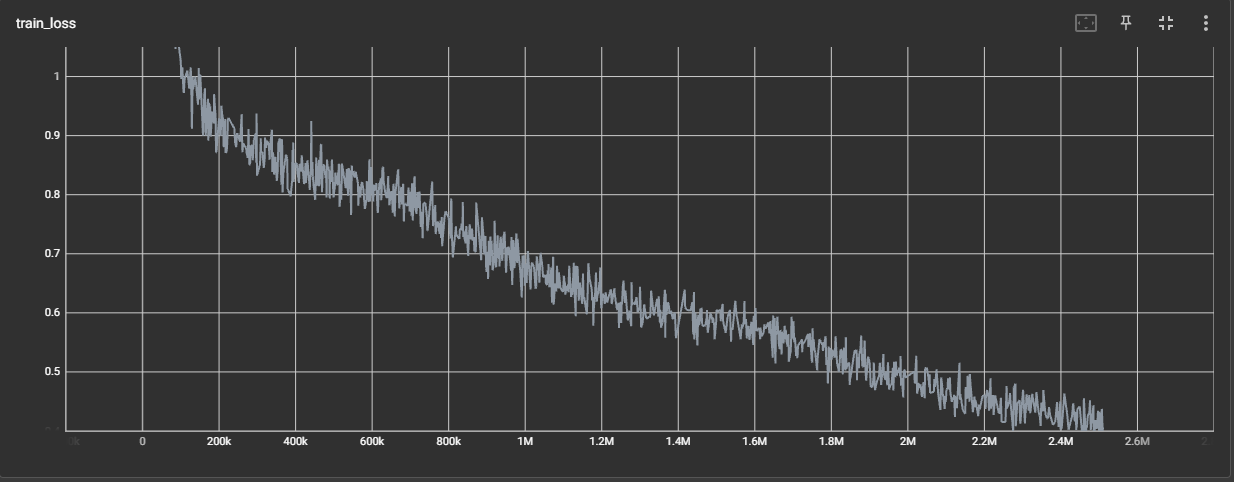
これは予備実験でも見られた現象なのですが、損失がある程度飽和した状態から急にまた下がり始めるという挙動が観察されました。
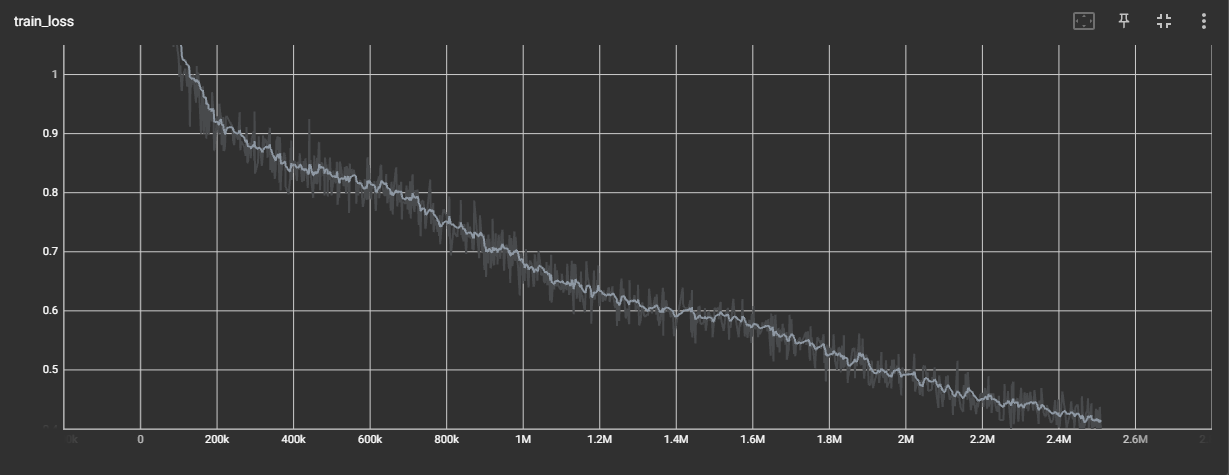
上記のグラフを平滑化してみるとわかりやすいです:
その他
同一パラメータ数の通常の直列Transformerとの比較もやってみたかったのですが学習がVRAMに乗りませんでした。
また、今回の実験で用いたデータセットは10MB程度の比較的小さいものなので、計算資源が足りればWikipediaコーパス等の大規模なもので実験してみたいです。