はじめに
こんにちは、anyのプロダクトチーム所属@310kaです。
この記事は any Product Team Advent Calendar2025 18日目の記事になります。
今回は、GMKtecのEVO-X2とLemonadeServer 9.1.0を使ってローカルLLM環境を構築してみました。最近のMiniPCの性能向上で、ローカルでの大規模言語モデル(LLM)運用が手軽になってきています。特にEVO-X2は128GBのLPDDR5Xを搭載しており、96GBのVRAM割り当てが可能なため、大規模モデルでも余裕を持って運用できます。
普段JetBrainsのIDEを利用しており、All Products Packを契約しているのでAIクレジットがある程度使えるんですが、本格的な開発に使い続けるには厳しいときも多いのでローカルでなんとかできないか試してみます。
環境構成
EVO-X2(Ryzen AI Max+ 395搭載、128GB LPDDR5X)
LemonadeServer 9.1.0(LLM推論サーバ)
JetBrains IntelliJ IDEA(Continueプラグイン経由でローカルLLM連携)
性能と利点
EVO-X2はユニファイドメモリでBIOSにて96GBまでVRAMに割り当てが可能で gpt-oss-120bなどの大規模モデルもロードできます。
モデルのロードは多少時間がかかりますが、メモリに空きがあれば同時に複数のモデルをロードできるため、それぞれのタスクに適したモデルを使った開発がしやすいと思います。
実行手順
LemonadeServerの起動
Lemonadeは、Windows上でLLMのロードと推論を行うサーバです。
Windows環境なのでこちらからlemonade.msiをダウンロードしてインストールします。
インストール後にショートカットから起動できますが、デフォルトでは外部からアクセスができません。
今回はLAN内のMacから接続するためにhostオプションをして起動します。
lemonade start --host 0.0.0.0 --port 8080 --ctx-size 131072 --max-loaded-models 2 1 1 1
-
--host 0.0.0.0とすることで、LAN内の別の端末からもアクセス可能になります -
max-loaded-modelsは同時ロードできるモデル数を指定できます。これにより、モデルロード待ち時間が削減されるはずです。ただし、NPUを使うモデルは同時に1つしかロードできないので注意
詳しくは https://lemonade-server.ai/docs/server/lemonade-server-cli/ を確認してください。
起動するとタスクトレイに追加され、Open appでアプリを表示できます。
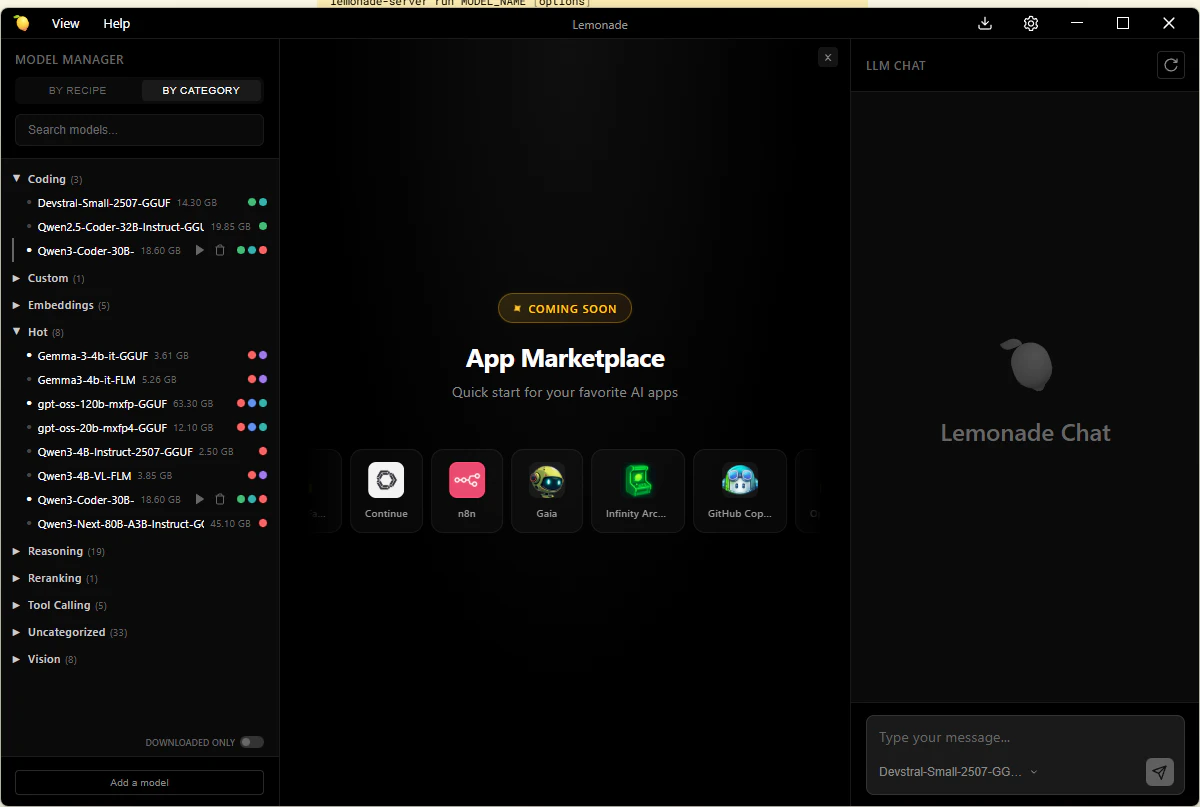
Lemonade 9.1.0から WebUIが廃止されてアプリになりました。
必要なモデルをダウンロードしておきます。
Continueプラグインの設定
JetBrains IDEにContinueプラグインを導入し、LemonadeServerのAPIエンドポイントに接続することで、コード補完やエラー修正などのアシスタント機能をローカルで実行できます。
AI AssistantでもOpenAI互換やLMStudioなどのローカルLLMを利用できますが、単純にモデルに投げることしかできないようなので開発には不十分かと思うのでContinueを利用してみます。
Continueプラグインでエラーが出る場合は ヘルプ | カスタムVMオプションの編集 で以下を追加してください。
-Dide.browser.jcef.out-of-process.enabled=false
Lemonadeへの接続設定が必要になるのでContinueのconfig.yamlに以下を追加します。
models:
- name: Lemonade
provider: openai
model: AUTODETECT
apiBase: http://192.168.***.***:8000/api/v1/
apiKey: none
- name: Lemonade Autocomplete
provider: openai
model: AUTODETECT
apiBase: http://192.168.***.***:8000/api/v1/
apiKey: none
roles:
- autocomplete
AUTODETECTを指定しているとLemonadeでダウンロードしているモデルがリストアップされるようになります。
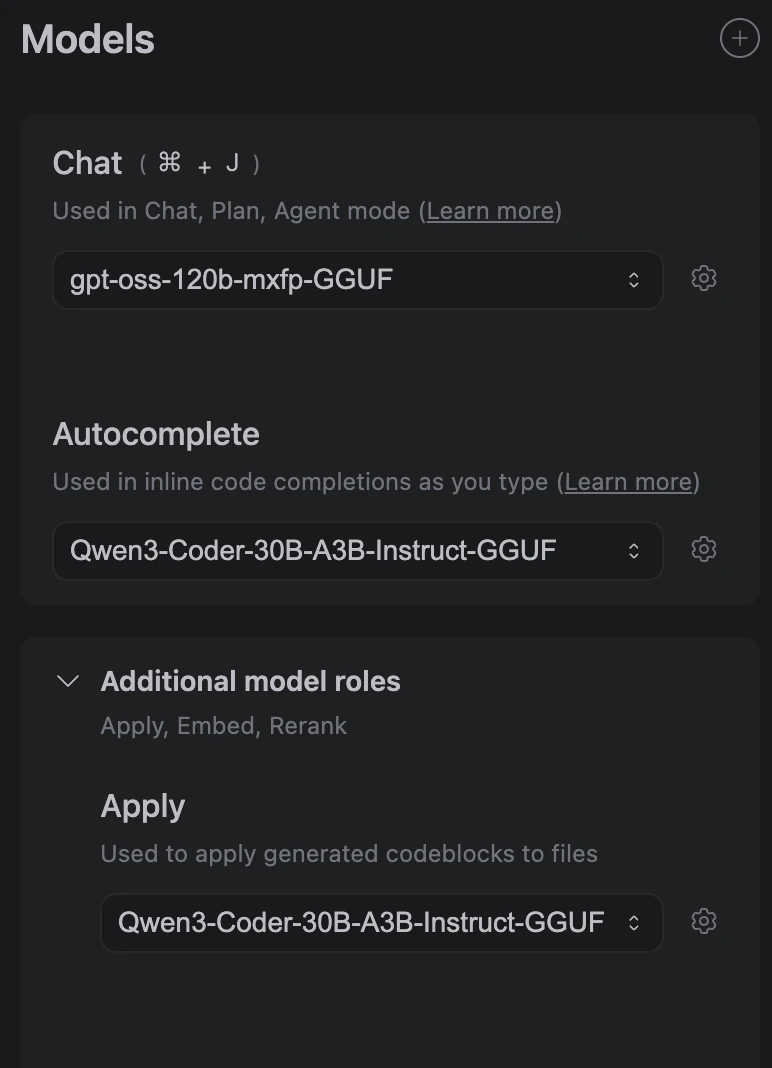
Continueプラグインの設定画面でデフォルトのモデルを指定します。
チャットのデフォルト選択にgpt-oss-120bとAutocompleteとApply(作成されたコードを反映する処理)にQwen3 Coder(30B)を指定してみました。
いざ実行
応答速度を見るために、Reactを利用したサンプル環境にて適当に以下のリクエストを出してみました。
Twitchのスクリーンショットを取得するためにTwitchのVideo要素の取得と動画タイトルを取得するための機能をもつ useTwitch hookを作って
使用モデルはQwen3-Coder-30B-A3B-Instruct-GGUFです
[Server] POST /api/v1/chat/completions - Streaming
srv params_from_: Chat format: Qwen3 Coder
slot get_availabl: id 1 | task -1 | selected slot by LCP similarity, sim_best = 0.974 (> 0.100 thold), f_keep = 0.566
slot launch_slot_: id 1 | task -1 | sampler chain: logits -> logit-bias -> penalties -> dry -> top-n-sigma -> top-k -> typical -> top-p -> min-p -> xtc -> temp-ext -> dist
slot launch_slot_: id 1 | task 5223 | processing task
slot update_slots: id 1 | task 5223 | new prompt, n_ctx_slot = 131072, n_keep = 16, task.n_tokens = 1640
slot update_slots: id 1 | task 5223 | n_tokens = 1598, memory_seq_rm [1598, end)
slot update_slots: id 1 | task 5223 | prompt processing progress, n_tokens = 1640, batch.n_tokens = 42, progress = 1.000000
slot update_slots: id 1 | task 5223 | prompt done, n_tokens = 1640, batch.n_tokens = 42
slot print_timing: id 1 | task 5223 |
prompt eval time = 198.18 ms / 42 tokens ( 4.72 ms per token, 211.93 tokens per second)
eval time = 7615.78 ms / 510 tokens ( 14.93 ms per token, 66.97 tokens per second)
total time = 7813.96 ms / 552 tokens
slot release: id 1 | task 5223 | stop processing: n_tokens = 2149, truncated = 0
srv update_slots: all slots are idle
srv log_server_r: request: POST /v1/chat/completions 127.0.0.1 200
[Server] Streaming completed - 200 OK
=== Telemetry ===
Input tokens: 42
Output tokens: 510
TTFT (s): 0.198
TPS: 66.97
=================
生成速度(TPS)は約67トークン/秒で結構早めです。
実行の様子は以下です。
若干待ちますが使えなくもないという感じですね。

autocompleteの方は入力中に稀にいい感じの補完をしてくれますが、個人的にはいらないかなぁという印象でした。
続いてgpt-oss-120bでも試してみます。

何度か応答を繰り返したのちに出力されていきますが、途中で長考しています。
トータルで1分30秒ほどで最後まで出力しました。
個人的にはちょっと待つのがきつい時間です。
おわりに
なるべくサブスク料金を減らせないかと思ってましたが、ローカルLLMではまだまだ敵わないという結果でした。
ちなみに、今回使用したEVO-X2はセールで約21万円ほどでした。
月2,500円のサブスク代わりとすると、元を取るには7年かかる計算になります。
当然ながらオンラインの方は進化も早いわけで・・・
これだけで元を取るのは厳しいですが、ただ、まあ、ローカルで動くのは楽しいです!
なんとかして有効活用していきます!