1 最初に
「#2 データ収集」で画像とラベルのデータセットを作成し「#3 無念 学習モデルの構築」で実際に自作したデータセットを学習したが精度が良くなかったのでこの記事ではmediapieで取得した座標でデータセットの作成に取り掛かる
参考資料・お借りしたプログラム
1.https://qiita.com/akira2768922/items/c660129cc45cce384e90
2.https://github.com/Kazuhito00/mediapipe-python-sample
2 データ収集器
このコードはカメラの目の前に手を写すとmediapipeで手の各座標をCSVに書き出します。
コードを実行するとクラス番号の入力を要求されるので入力します。
(Finishはプログラム終了すると表示されます。)

mediapipeは21箇所のランドマークを取得し各ランドマークはx,y,zの3要素持っているので一度に計63個のデータを取得することができます。CSVには、クラス番号と63個のデータ計64個のデータを書き出します。以下の画像は幅が広くなるのでクラス番号と63個中の7個のデータのみになっています。

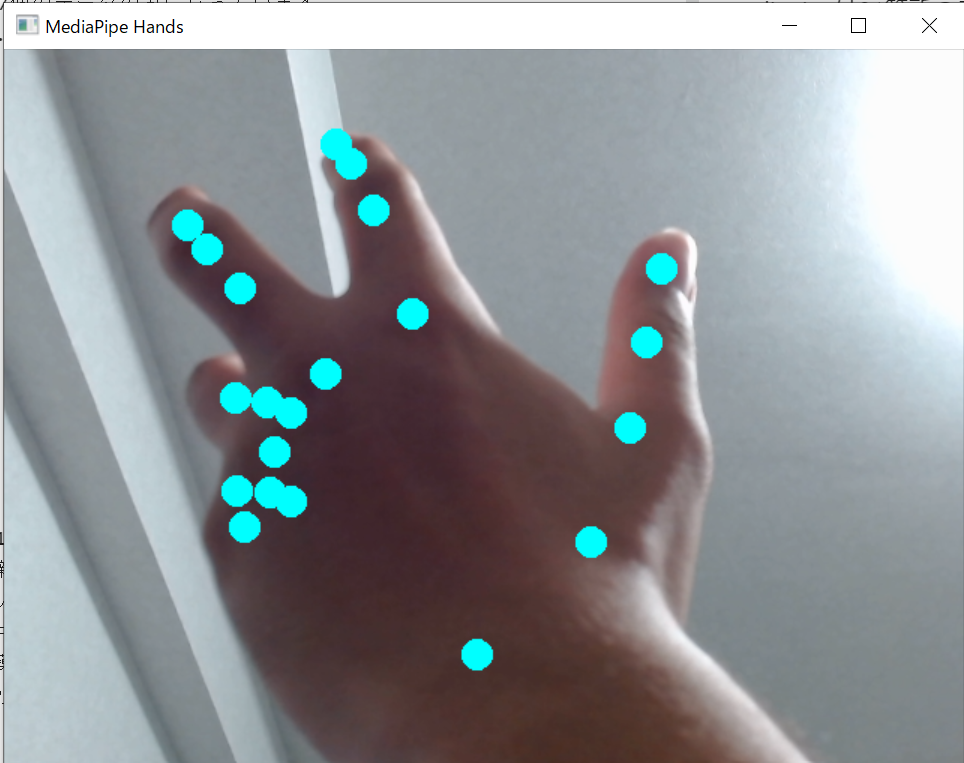
カメラの前に手をかざした際の画像です。
mediapipeで取得したランドマークの場所に明るめの青の丸印で描画しています。この丸印が描画しているときは座標がCSVに書き込まれているので画角内で同じポーズで動かしてデータを収集します。別のポーズで収集する際は一度プログラムを終了して再び起動してクラス番号を入力して収集します。
import cv2
import numpy as np
import mediapipe as mp
import csv
import os
import copy
import itertools
# landmarkの繋がり表示用
landmark_line_ids = [
(0, 1), (1, 5), (5, 9), (9, 13), (13, 17), (17, 0), # 掌
(1, 2), (2, 3), (3, 4), # 親指
(5, 6), (6, 7), (7, 8), # 人差し指
(9, 10), (10, 11), (11, 12), # 中指
(13, 14), (14, 15), (15, 16), # 薬指
(17, 18), (18, 19), (19, 20), # 小指
]
mp_hands = mp.solutions.hands
hands = mp_hands.Hands(
max_num_hands=2, # 最大検出数
min_detection_confidence=0.7, # 検出信頼度
min_tracking_confidence=0.7 # 追跡信頼度
)
def circle_landmarks(img, hand_landmarks, img_h, img_w):
z_list = [lm.z for lm in hand_landmarks.landmark]
z_min = min(z_list)
z_max = max(z_list)
for lm in hand_landmarks.landmark:
lm_pos = (int(lm.x * img_w), int(lm.y * img_h))
lm_z = int((lm.z - z_min) / (z_max - z_min) * 255)
cv2.circle(img,
center=lm_pos,
radius=10,
color=(0, 255, 255),
thickness=-1,
lineType=cv2.LINE_4,
shift=0)
def calc_landmark_list(image, landmarks):
image_width, image_height = image.shape[1], image.shape[0]
landmark_point = []
for _, landmark in enumerate(landmarks.landmark):
tmp_x = round(landmark.x,4)
tmp_y = round(landmark.y,4)
tmp_z = round(landmark.z,4)
landmark_point.append([tmp_x, tmp_y, tmp_z])
return landmark_point
def save_landmark(INPUT_CLASS,landmark_list):
tmp_list = []
for i in landmark_list:
tmp_list.append(i[0])
tmp_list.append(i[1])
tmp_list.append(i[2])
file_path = 'landmark.csv'
with open(file_path, 'a', newline="") as f:
writer = csv.writer(f)
writer.writerow([INPUT_CLASS, *tmp_list])
def main():
cap = cv2.VideoCapture(1)
#分類のクラスとして使用する
input_class = int(input('Input only integer : '))
while True:
success,img = cap.read()
if not success:
break
#左右反転
img = cv2.flip(img,1)
debug_img = copy.deepcopy(img)
#サイズの取得
img_h, img_w, _ = img.shape
#BGR=>RGB変換
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
#手の検出
results = hands.process(img)
if results.multi_hand_landmarks:
for h_id, hand_landmarks in enumerate(results.multi_hand_landmarks):
#landmarkをcircleで表示
circle_landmarks(img,hand_landmarks, img_h, img_w)
#landmarkをlandmark.csvへ保存する
landmark_list = calc_landmark_list(debug_img, hand_landmarks)
save_landmark(input_class,landmark_list)
#RGB=>BGR
img = cv2.cvtColor(img, cv2.COLOR_RGB2BGR)
#画像の表示
cv2.imshow("MediaPipe Hands", img)
#escキーの入力に対しての操作
key = cv2.waitKey(10)
if key == 27: # ESC
break
cap.release()
print('Finish')
if __name__ == '__main__':
main()
3 次回
次の回では作成したデータセットをもとに学習させて学習済みモデルをロードしカメラ画像から学習させたハンドジェスチャーを推定するまでをしたいと考えています。