1 最初に
「#4(再)データ収集」で作成したデータセットを使用してモデルを作成し、学習済みモデルをロードしリアルタイムでハンドジェスチャーを推定するプログラムを作っていきます。
2 モデルの作成
ライブの読み込み
import tensorflow as tf
import keras
from tensorflow import keras, config
from tensorflow.keras.layers import Dense, Flatten, Conv2D
from tensorflow.keras import Model
from keras.utils import np_utils
import csv
import random
import os
import cv2
import numpy as np
from __future__ import absolute_import, division, print_function, unicode_literals
データセット読み込みをするコード
指定したCSVファイルを読み込んだ後、訓練データとテストデータに8:2の比率で分割します。
CSVファイルに保存されている全てのデータを読み込んだ後、リスト型のconten内のデータをランダムに並べ替えます。スライスで訓練データとテストデータに分割します。その後に学習データと正解ラベルに分割します。正解ラベルの入ったリストは学習用に変換します。
def remake_data(data_list,X,Y):
for i in data_list:
tmp = [float(j) for j in i]
X.append(tmp[1:])
Y.append(tmp[0])
X = np.array(X)
Y = np.array(Y)
return X,Y
file_path = 'landmark.csv'
NUM_CLASS = 6
model_save_path ='test.hd5'
content = []
with open(file_path, encoding='utf8', newline='') as f:
csvreader = csv.reader(f)
content = [row for row in csvreader]
random.shuffle(content)
data_num = len(content)
ratio = 0.8
train = content[:int(data_num*ratio)]
test = content[int(data_num*ratio):]
train_x = []
train_y = []
train_x, train_y = remake_data(train,train_x,train_y)
train_y = np_utils.to_categorical(train_y,(NUM_CLASS))
test_x = []
test_y = []
test_x, test_y = remake_data(test,test_x,test_y)
test_y = np_utils.to_categorical(test_y,(NUM_CLASS))
モデルの構築・学習・検証・保存
以下のプログラムでモデルを構築しデータセットを学習させます。その後、検証しモデルのパラメータを保存します。
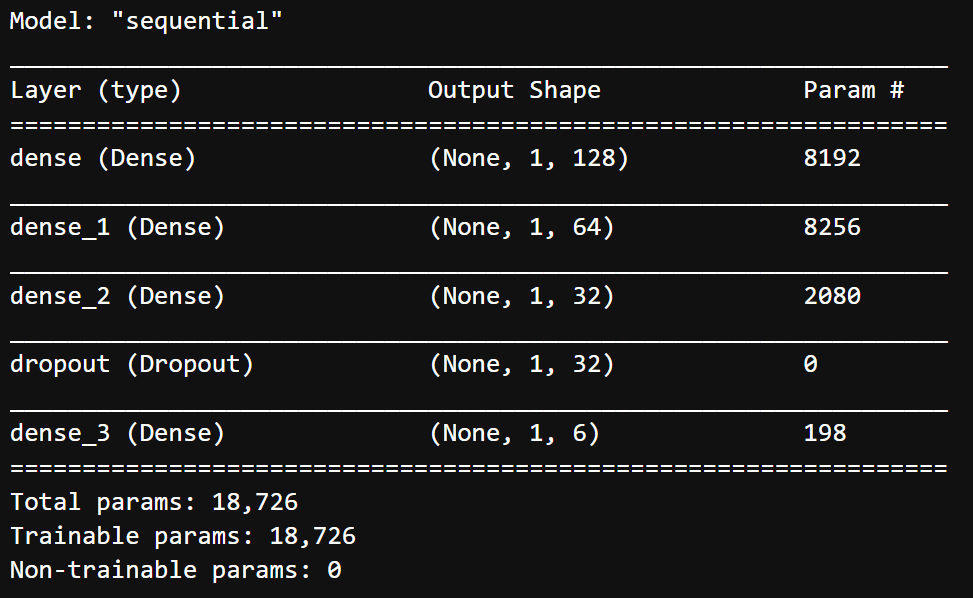
dims = (1,63)
model = tf.keras.Sequential()
model.add(tf.keras.layers.InputLayer(input_shape=dims))
model.add(tf.keras.layers.Dense(128, activation='relu'))
model.add(tf.keras.layers.Dense(64, activation='relu'))
model.add(tf.keras.layers.Dense(32, activation='relu'))
model.add(tf.keras.layers.Dropout(0.5))
model.add(tf.keras.layers.Dense(NUM_CLASS,activation="softmax"))
model.summary()
model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
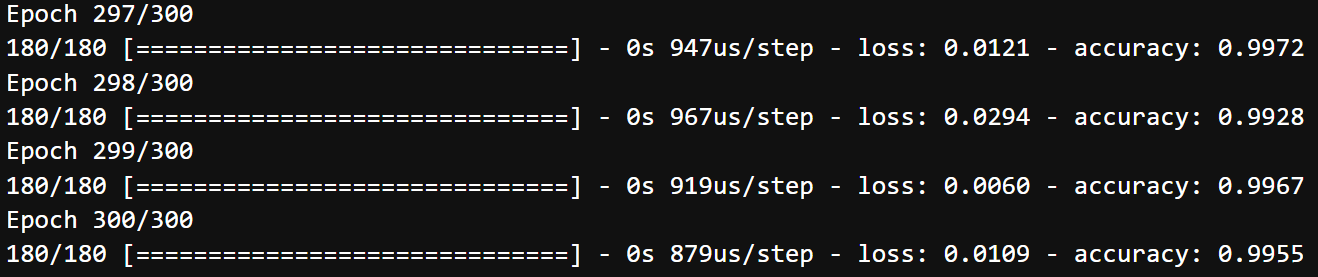
model.fit(train_x, train_y, batch_size=10, epochs=300)
score = model.evaluate(test_x,test_y, verbose=0)
print("Test loss:", score[0])
print("Test accuracy:", score[1])
model.save('test.h5')

3 学習済みモデルの利用
ライブラリの読み込み
import os
import cv2
import numpy as np
import tensorflow as tf
import mediapipe as mp
import copy
import itertools
from __future__ import absolute_import, division, print_function, unicode_literals
from tensorflow import keras, config
from tensorflow.keras.layers import Dense, Flatten, Conv2D
from tensorflow.keras import Model
from keras.utils import np_utils
モデル読み込み
NUM_CLASS = 6
dims = (1,63)
model = tf.keras.Sequential()
model.add(tf.keras.layers.InputLayer(input_shape=dims))
model.add(tf.keras.layers.Dense(128, activation='relu'))
model.add(tf.keras.layers.Dense(64, activation='relu'))
model.add(tf.keras.layers.Dense(32, activation='relu'))
model.add(tf.keras.layers.Dropout(0.5))
model.add(tf.keras.layers.Dense(NUM_CLASS,activation="softmax"))
model.summary()
model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
model.load_weights('./test.h5')
カメラに手のひらを写しmediapipeで取得した座標を元に学習したハンドジェスチャに分類するプログラムです。分類は、操作するドローンのコマンドに合わして学習させています。
以下が分類ラベルとジェスチャー
0:FRONT =>手のひら
1:BACK =>手の甲
2:RIGHT =>親指だけ立てて親指を右に向ける
3:LEFT =>親指だけ立てて親指を左に向ける
4:UP =>人差し指だけを立てて人差し指を上に向ける
5:DOWN =>人差し指だけを立てて人差し指を下に向ける
操作性を考えるともう少しジェスチャーの数を増やした方がいいような気もします...

# landmarkの繋がり表示用
landmark_line_ids = [
(0, 1), (1, 5), (5, 9), (9, 13), (13, 17), (17, 0), # 掌
(1, 2), (2, 3), (3, 4), # 親指
(5, 6), (6, 7), (7, 8), # 人差し指
(9, 10), (10, 11), (11, 12), # 中指
(13, 14), (14, 15), (15, 16), # 薬指
(17, 18), (18, 19), (19, 20), # 小指
]
mp_hands = mp.solutions.hands
hands = mp_hands.Hands(
max_num_hands=2, # 最大検出数
min_detection_confidence=0.7, # 検出信頼度
min_tracking_confidence=0.7 # 追跡信頼度
)
label =['FRONT','BACK','RIGHT','LEFT','UP','DOWN']
def circle_landmarks(img, hand_landmarks, img_h, img_w):
z_list = [lm.z for lm in hand_landmarks.landmark]
z_min = min(z_list)
z_max = max(z_list)
for lm in hand_landmarks.landmark:
lm_pos = (int(lm.x * img_w), int(lm.y * img_h))
lm_z = int((lm.z - z_min) / (z_max - z_min) * 255)
cv2.circle(img,
center=lm_pos,
radius=10,
color=(0, 255, 255),
thickness=-1,
lineType=cv2.LINE_4,
shift=0)
def calc_landmark_list(image, landmarks):
image_width, image_height = image.shape[1], image.shape[0]
landmark_point = []
# キーポイント
for _, landmark in enumerate(landmarks.landmark):
tmp_x = round(landmark.x,8)
tmp_y = round(landmark.y,8)
tmp_z = round(landmark.z,8)
landmark_point.append([tmp_x, tmp_y, tmp_z])
return landmark_point
def model_result(landmark_list):
tmp_list = []
for i in landmark_list:
tmp_list.append(round(i[0],4))
tmp_list.append(round(i[1],4))
tmp_list.append(round(i[2],4))
tmp_list_np = np.array(tmp_list)
list_reshape = tmp_list_np.reshape(1,63)
result=model.predict(list_reshape)
max_index = np.argmax(result)
return max_index
def main():
cap = cv2.VideoCapture(1)
while True:
success,img = cap.read()
if not success:
break
#左右反転
img = cv2.flip(img,1)
debug_img = copy.deepcopy(img)
#サイズの取得
img_h, img_w, _ = img.shape
#BGR=>RGB変換
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
#手の検出
results = hands.process(img)
if results.multi_hand_landmarks:
for h_id, hand_landmarks in enumerate(results.multi_hand_landmarks):
#landmarkをcircleで表示
circle_landmarks(img,hand_landmarks, img_h, img_w)
#landmarkをモデルに渡す
landmark_list = calc_landmark_list(debug_img, hand_landmarks)
ml_result = model_result(landmark_list)
cv2.putText(img,label[ml_result],(0,100),cv2.FONT_HERSHEY_COMPLEX,3.5,color=(0, 255, 0))
#RGB=>BGR
img = cv2.cvtColor(img, cv2.COLOR_RGB2BGR)
#画像の表示
cv2.imshow("MediaPipe Hands", img)
#escキーの入力に対しての操作
key = cv2.waitKey(10)
if key == 27: # ESC
break
cap.release()
print('Finish')
if __name__ == '__main__':
main()
ジェスチャーの切り替えの時に推定してしまうので同じジェスチャーが5回判定されたらドローンを操作するなどの工夫は必要かもしれません。
4 次回
次回は、このプログラムとドローン(DJI Tello)を操作するコードを組み合わせてみようと思います。