Githubでコードを公開しました!(2018.05.01 追記) https://github.com/29Takuya/EyeSight
0. 背景
こんにちは、@29Takuyaです。(プロフィールページ)
この記事は、僕が学部3年(2016年後半)に授業の一環として行った活動をまとめたものです。
Pythonや機械学習の知識を身につけることが主な目的であったため、新規性などは特にありません。(暖かい目でご覧頂けると嬉しいです)
1. 目的
顔が写った一枚の画像を入力として、その人の視線がカメラを向いているかそうでないかを判定するします。(二値分類)
僕の研究室では、対話ロボットの研究を行っているのですが、視線を検知することでよりスムーズな対話が実現できるのではというのがモチベーションです。

2. 関連技術(OpenFace)
顔が写った画像と言っても、顔のサイズや位置などは様々です。
そのため今回は、OpenFaceというAPIで顔を検出した後に、視線判定を行うことにしました。
OpenFanceには色々な機能があるのですが、今回利用したのは主に二つです。
- ランドマークの座標取得(下の画像で黒い点がついている部分)
- 顔領域の切り出し
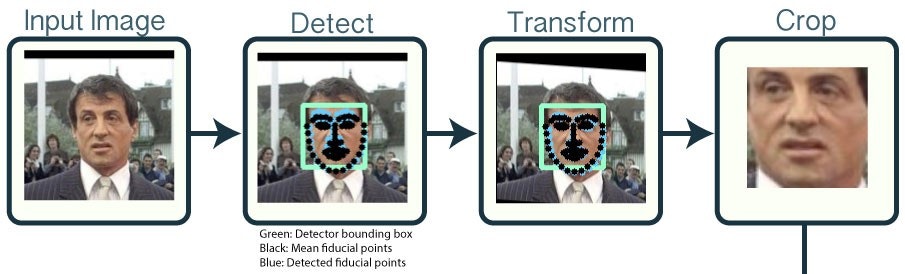
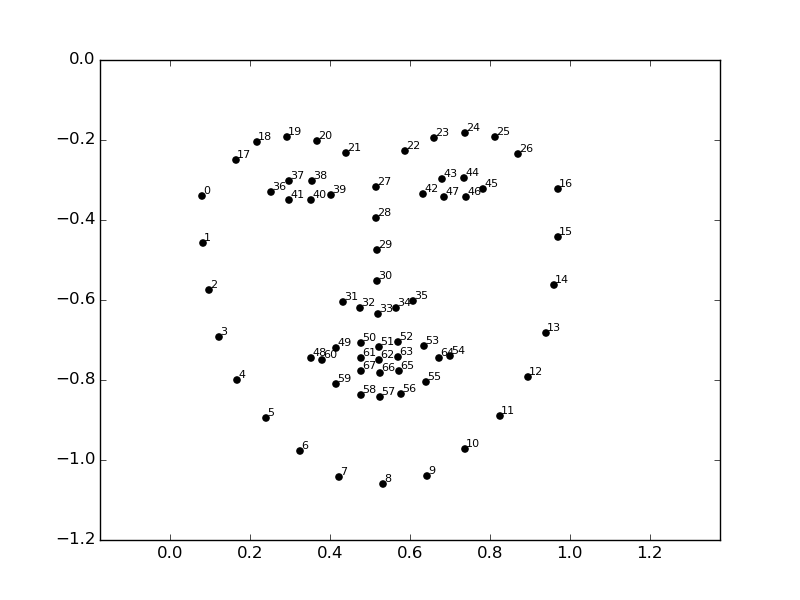
顔のランドマークは下の画像のような感じで、計64個検出されます。
切り出しは特定のランドマークを基準に行われます(確か目の位置?)。
また、各ランドマークの座標も取得することができます。
3. モデルの作成
今回試した視線検出モデルは以下の3つです。
- 画像(画素値)をそのまま入力としてSVMを学習
- SIFT特徴量を入力としてSVMを学習
- 画像を入力としてCNNを学習
それぞれのアルゴリズムを以下で説明します。
1. 画像(画素値)をそのまま入力としてSVMを学習
OpenFaceで切り出した顔画像(96×96)にヒストグラム平坦化をしたものの上1/3部分の画素値を入力とします(3072次元のベクトル)。
図を使うとこんな感じ。

ちなみに、モノクロ化と1/3のみの切り出しは、次元削減を目的としていて、ヒストグラム平坦化についてはコントラストの違いに頑健にすることが目的です。
このようにしてベクトル化したものを入力として、SVMを学習させました(ハイパーパラメータはグリッドサーチで決めました)。
2. SIFT特徴量を入力としてSVMを学習
画像特徴量としてよく用いられているものがSIFT特徴量です。
今回は、OpenFaceのおかげで目の周りのランドマークの座標が分かっているので、その12点におけるSIFT特徴量を利用しました。
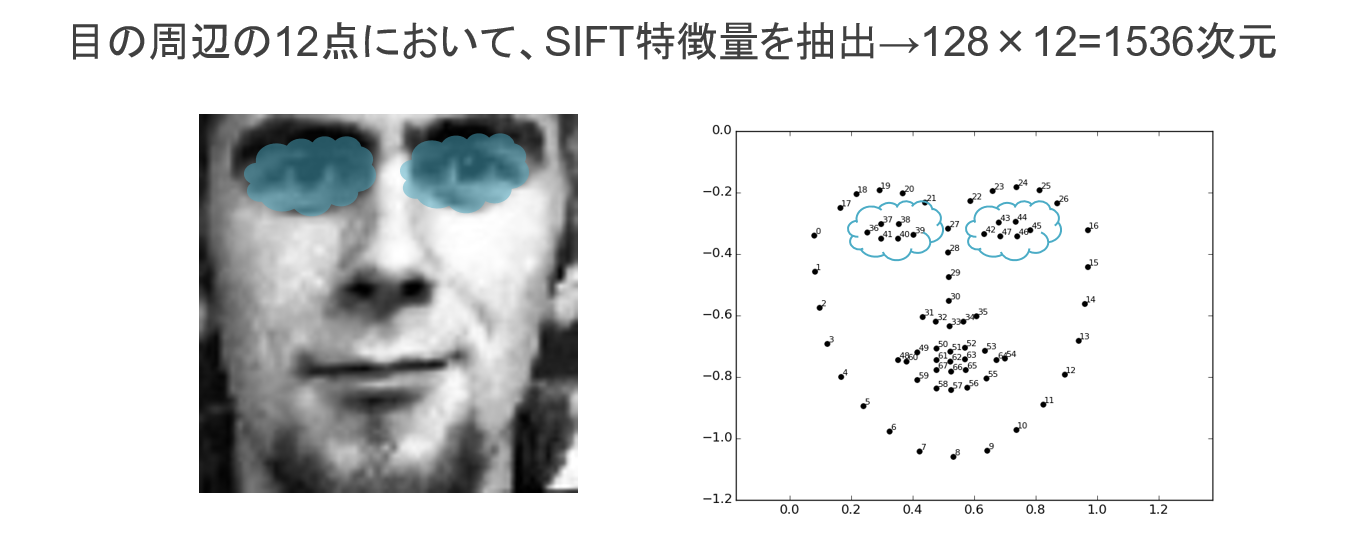
この方法で得られた1536次元の特徴量を入力として、SVMを学習させます。
SIFT特徴量については中部大の藤吉先生の資料が非常にわかりやすかったです。
(スライド)画像局所特徴量と特定物体認識- SIFTと最近のアプローチ -
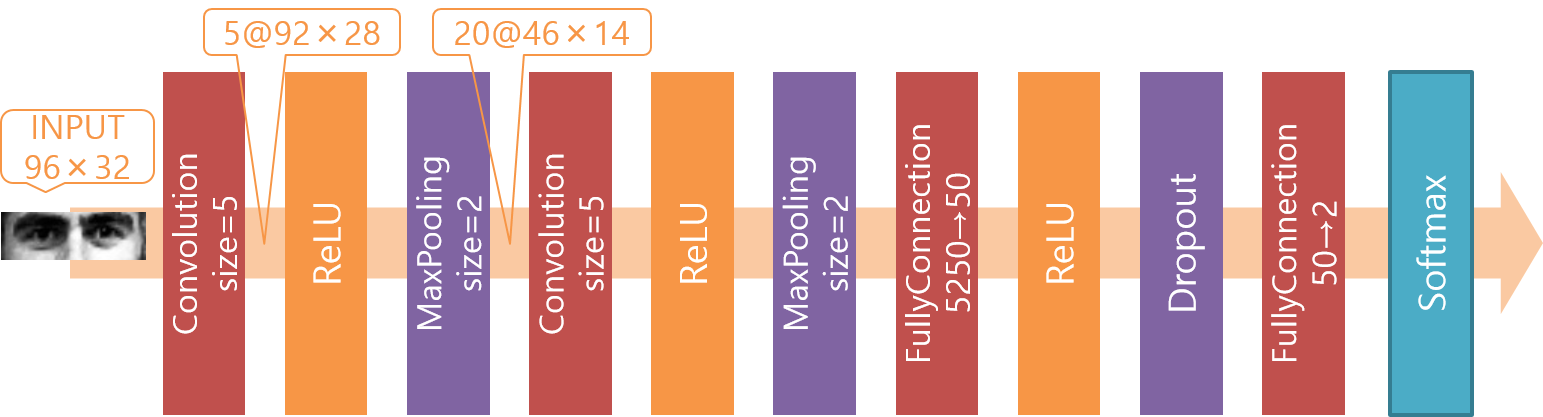
3. 画像を入力としてCNNを学習
入力は1.と同じく前処理をした顔画像の上1/3です。
モデルは畳み込み2層と全結合2層のシンプルなネットワークにしました。
4. 評価実験
データセット
今回用意したデータは、正例(カメラを見ている)画像1300枚と、負例(カメラを見ていない)画像600枚です。
学習データと訓練データを9:1に分け、ホールドアウト検証を行いました。

実験結果
| Model | Accuracy [%] |
|---|---|
| 1. SVM(Input: Raw pixel) | 81.3 |
| 2. SVM(Input: SIFT Features) | 82.3 |
| 3. CNN | 88.7 |
結論(感想)
ニューラルネットすごい
5. おまけ
Webカメラで撮影した映像に対して、フレーム単位で識別結果を表示してみました。
青がカメラを見ている、赤がカメラを見ていないという予測です。
1. SVM(Input: Raw Pixel)の場合

2. CNNの場合

うーん、なんとなくCNNの方が安定している気がしているような…
やはり顔自体がカメラを向いていない時には予測が難しいようです。データセットにそのような画像が足りていないのが原因かもしれません。
加えて、もし動画に適用することが前提であればスムージングや時系列モデルを用いることで、より精度が安定するのではと思いました。
ソースコードはこちらで公開しています。
ここまで読んで頂いてありがとうございました!