目的と方法
- OpenStackのCeilometerの仕組みがよくわからなかったのでメモ。
- 基本的には以下のドキュメント(CCライセンス)の和訳。
- 以下の記述は、OpenStack Mitakaリリースでの説明。
英→日対応表
| original | transltated |
|---|---|
| metering | 計測 |
| rating | 評価 |
| billing | 課金 |
| meter | メトリック |
| sample | サンプル |
| event | イベント |
| notification | 通知 |
| consumer | メッセージをキューから受信する機能 |
| producer | メッセージをキューに送信する機能 |
| publish | 発行 |
Ceilometerインストール
- インストールマニュアルはこちらを参照。
- ceilometerをcontrollerノードと別サーバ上で起動させる場合には、マニュアル通りのインストールに加え、ceilometerノード上で以下のコマンドを入力する。
# yum install python-memcached
OpenStack Ceilometerとは?
- OpenStack Telemetryサービスの一つ。
Telemetry
- クラウドの世界においても、プロバイダはユーザが使用するクラウドリソースの使用状況を計測、評価、課金することでサービスを提供している。
- プロバイダ要件は各々異なるので、評価と課金に関しては全てを網羅するような共通のモジュール設計は困難だが、ユーザがクラウドサービスの使用状況を把握できることは重要である。
- 以上の背景のもと、Telemetryサービスは元来は課金システムをサポートするために設計され、課金に必要な計測のみをカバーしている。
- 本サービスはシステムに関する情報を収集し、課金に必要となるデータをサンプルという形でを保存する。
- システムの計測に加え、本サービスはOpenStackシステムの様々なアクションの実行結果により発せられるイベント通知を収集し、イベントデータとして計測データと共に格納される。
- 計測できるメトリックリストは更新されつづけており、収集されたデータは課金以外の目的にも使用できる。
- 例えば、オーケストレーションサービス(Heat)によるオートスケーリングは本サービスのアラームを契機に実行される。
システム構成
-
Telemetryサービスはエージェント型のアーキテクチャを採用している。
-
以下に示すモジュールが相互に連携することで、データの収集、データベースへの格納、APIによるリクエストの処理を実現する。
- ceilometer-api
- 計測データを課金システムや解析ツールに送信するAPIを提供。
- ceilometer-polling(
polling agent)- 異なる名前空間内で動作するポーリングプラグイン(pollsters)により計測されたデータを統合的に取得。
- ceilometer-agent-central(
central agent)-
centralという名前空間内のpollstersが、NovaやGlanceを含むOpenStackサービスのPublic APIを呼ぶことでリソースの存在を確認。
-
- ceilometer-agent-compute(
compute agent)-
computeという名前空間内のpollstersが、インスタンスのパフォーマンスをハイパーバイザやlibvirtデーモンから取得し、AMQPメッセージとして出力。
-
- ceilometer-agent-ipmi(
ipmi agent)-
ipmiという名前空間内のpollstersが、IPMIセンサやIntel Node Managerのデータを取得。
-
- ceilometer-agent-notification(
notification agent)- 他のOpenStackサービスから発せられるAMQPメッセージを取得。
- ceilometer-collector(
collector)- ceilometerのagentからのAMQP通知を取得し、データを適切な形で保存する。
- ceilometer-alarm-evaluator
- 統計的トレンドや閾値定義をもとにアラーム発呼するかどうかを評価。
- ceilometer-alarm-notifier
- アラームを制御。
- ceilometer-api
-
ceilometer-pollingはKiloリリースから利用可能となり、ceilometer-agent-central、ceilometer-agent-compute、ceilometer-agent-ipmiの一部機能に取って代わっている。
-
ceilometer-agent-computeとceilometer-agent-ipmi以外のモジュールはコントローラノードに配置される。
-
TelemetryサービスアーキテクチャはOpenStackサービスからの通知情報取得や内部通信においてAMQPプロトコルを用いているため、AMQPサービス(例えばRabbitMQ)に大きく依存している。
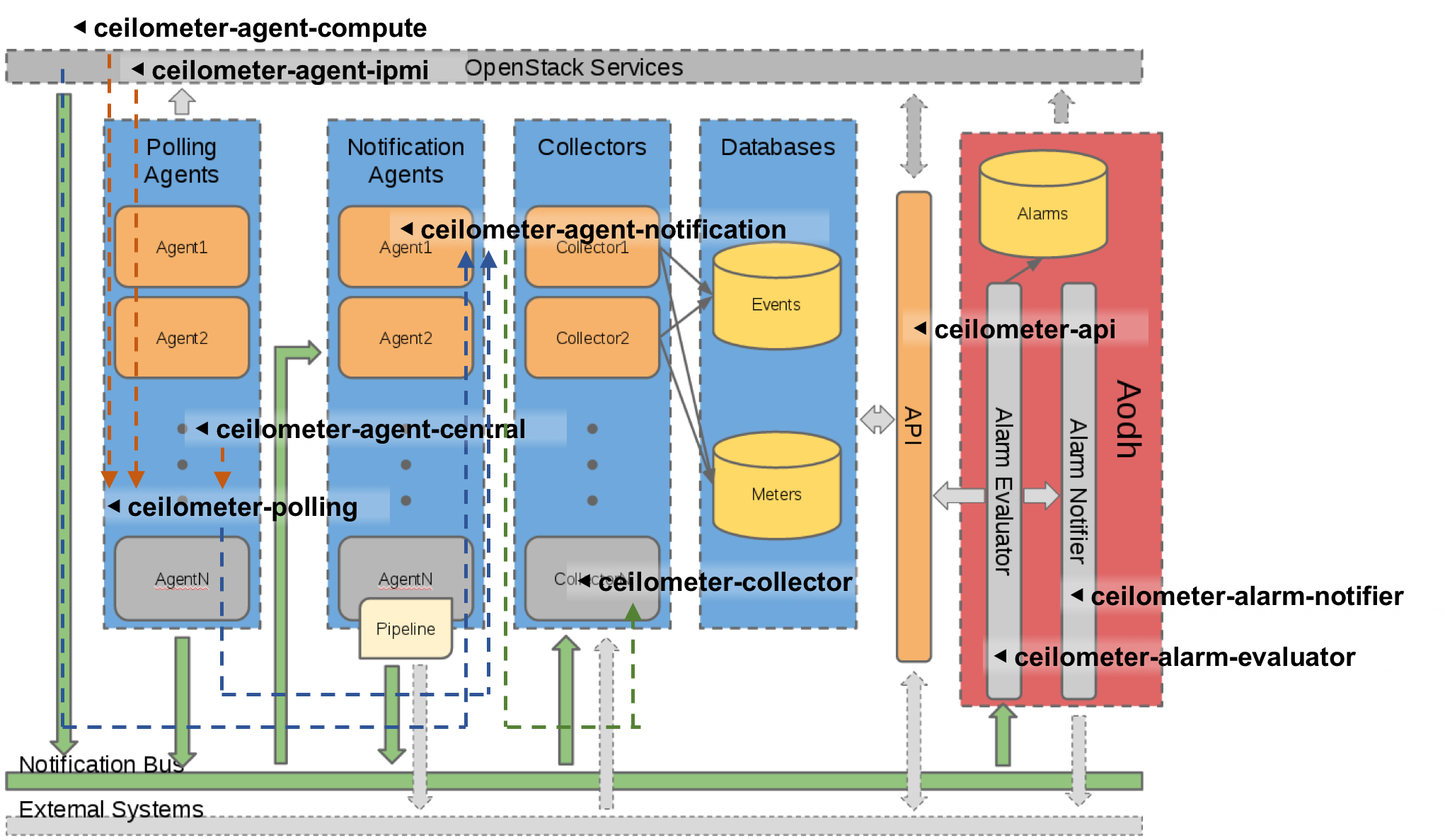
Ceilometer構成図
引用:http://docs.openstack.org/developer/ceilometer/architecture.html
対応しているデータベース
- Telemetryサービスにおいても、イベント、サンプル、アラーム定義、アラームを格納するデータベースはキーコンポーネントである。(いくつかのデータベースをそれぞれに適用することも可能)
- サポートしているデータベースは以下の通り。
- ElasticSearch(event only):ドキュメント指向データベース
- MongoDB:ドキュメント指向データベース
- MySQL:リレーショナルデータベース
- PostgreSQL:リレーショナルデータベース
- HBase:列指向分散データベース
対応しているハイパーバイザ
- Telemetryサービスは仮想マシンの情報を収集するため、収集対象となるハイパーバイザとは密接な関係がある。
- サポートしているハイパーバイザは以下の通り。
- KVM(Kernel-based Virtual machine) via libvirt
- QEMU(Quick Emulator) via libvirt
- LXC Linux Containers) via libvirt
- UML(User-mode Linux) via libvirt
- Hyper-V
- XEN
- VMware vSphere
対応しているネットワーキングサービス
- サポートしているネットワーキングサービスは以下の通り。
- OpenStack Networking:
- Basic network meters
- Firewall-as-a-Service meters
- Load-Balancer-as-a-Service(LBaaS) meters
- VPN-as-a-Service(VPNaaS) meters
- SDN controllr meters:
- OpenDaylight
- OpenCOntrail
- OpenStack Networking:
ユーザ、ロール、テナントの扱い
- 本サービスは認証と承認にKeystoneサービスを活用するため、適切な設定を実施する必要がある。
- OpenStackは
adminとnon-adminロールを使い分ける。各APIリクエストを処理する前には承認が必要。返却値の量はリクエスト実行したロールに依存する。 - アラーム定義はアクションを定義したユーザのロールに高い依存性がある。詳細はこちらを参照。
データの収集
- Telemetryサービスの目的は、課金システムや解析ツールによって使用されるシステム情報(メトリック)を収集することにある。
- データ収集における当初の目的は課金であったが、そのスコープは広がり続けている。
- 収集データはサンプルやイベントといった形でデータベースに格納される。
- サンプルには設定や要件に関する多様な条件への対応が求められるため、複数のデータ取得方法が必要であり、本サービスのデータ収集方法には以下の3種類が存在する。
- Notifications(通知)
- メッセージキューからメッセージを受信することで、他のOpenStackサービスに関する通知を処理。
- Polling(ポーリング)
- SNMPや他OpenStackサービスのAPIを介して、ハイパーバイザやホストマシンから直接データを取得。
- RESTful API
- RESTful APIを介してサンプルを送受信。
- Notifications(通知)
Notifications(通知)
- OpenStackの各サービスは、サービスの動作状況やシステム状態に関する通知を送り、いくつかの通知はVMのCPU時間などの情報を含む。
- Telemetryサービスでは、_
notification agent_と呼ばれるエージェントがメッセージバスから通知を受信し、イベントや計測サンプルに変換する処理を担う。 - Libertyリリースの初期からは、_
notification agentは変換やプッシュといったデータ処理の全てを担っている。処理後、AMQPを用いてcollector_や外部サービスを介してデータベースに保存される。 - 他OpenStackサービスは、通常動作においてもシステムに起きた様々な種類のイベント通知を送信する。
- 全ての通知はTelemetryサービスによって処理されるというわけではなく、課金に関するイベントや監視に関する通知のみが処理される。つまり、イベントの種類によってフィルタリングする。
- 以下のテーブルには、Telemetryによって処理されるイベント一覧を示す。各サービスにおいて設定変更が必要となる場合もある。
| OpenStack service | Event types |
|---|---|
| OpenStack Compute (Nova) |
scheduler.run_instance.scheduled scheduler.select_destinations compute.instance.* |
| Bare metal service (Ironic) |
hardware.ipmi.* |
| OpenStack Image service (Glance) |
image.update image.upload image.delete image.send |
| OpenStack Networking (Neutron) |
floatingip.create.end floatingip.update.* floatingip.exists network.create.end network.update.* network.exists port.create.end port.update.* port.exists router.create.end router.update.* router.exists subnet.create.end subnet.update.* subnet.exists l3.meter |
| Orchestration service (Heat) |
orchestration.stack.create.end orchestration.stack.update.end orchestration.stack.delete.end orchestration.stack.resume.end orchestration.stack.suspend.end |
| OpenStack Block Storage (Cinder) |
volume.exists volume.create.* volume.delete.* volume.update.* volume.resize.* volume.attach.* volume.detach.* snapshot.exists snapshot.create.* snapshot.delete.* snapshot.update.* volume.backup.create.* volume.backup.delete.* volume.backup.restore.* |
- Computeサービスからの特定の通知は管理者やユーザにとって重要で、
nova.conf内のnova_notificationsを適切に設定することでイベントに対する即応性を高めることができる。 - 通知の設定方法に関するガイドはTelemetryインストールガイドを参照されたい。
- Kiloより前のリリースにおいて
ceilometer.conf内のstore_eventsがTrueに設定されている場合には、_notification agent_はデータベースに直接アクセス可能である必要がある点に注意。
OpenStack Object Storageに関するミドルウェア(Swift)
- オブジェクトストレージサービス(Swift)の統計値を取得するためには追加でミドルウェアを導入する必要がある。
- このミドルウェアはデータフローに基づくメータ(storage.objects.(incoming|outgoing).bytes values)を通知する。
- インストール方法はインストールガイドに記述してある。
Telemetrサービスに関するミドルウェア
- TelemetryプロジェクトはOpenStackのAPIエンドポイントに対するHTTPリクエストやレスポンスをカウント(audit.http.request、audit.http.response、http.request、http.response)することができる。
- これらの通知は、過負荷を避け、値に対する適切なインデックスを保持すべきであるため、サンプルよりもイベントとして処理されることが望ましい、
ポーリング
-
Telemetryサービスは直接的なインフラ情報や各OpenStackサービスから発呼される通知から得られる情報だけではなく、より意味のある情報を得ることを目的としており、例えばインスタンスが使用するリソース使用率などがそれに当たる。
-
他OpenStackサービスのAPIやハイバーバイザなどからインフラ情報をポーリングすることによってデータを取得する。
-
これを実現するためには、他のサービスとの相互接続性の確保が必要で、エージェント型のアーキテクチャを採用している理由でもある。
-
ポーリングは3種類のエージェントによりサポートされる。
-
compute agent(コンピュートノード内で動作) -
central agent(コントローラノード内で動作) -
ipmi agent(コンピュートノード内で動作)
-
-
異なる名前空間からそれぞれの
pollstersを起動するが、全てのエージェントはceilometer-pollingエージェントとして、つまり以下のように動作する。#ceilometer-agent-compute $ ceilometer-polling --polling-namespaces compute #ceilometer-agent-central $ ceilometer-polling --polling-namespaces central #ceilometer-agent-ipmi $ ceilometer-polling --polling-namespaces ipmi -
さらに、polling-listオプションを用いることで、特定のポーリングプラグインをロードすることもできる。ただし、HAには未対応である。
$ ceilometer-polling --polling-namespaces central --pollster-list image image.size storage.* -
ceilometer-pollingはKiloリリースより使用可能である。
Central agent
- 本エージェントは、public REST APIを介して、通知からは取得できないOpenStackやハードウェアのリソースに関する情報を取得する。
- 本エージェントのポーリング対象:
- OpenStack Networking(Neutron)
- OpenStack Object Strage(Swift)
- OpenStack Block Storage(Cinder)
- Hardware resources(SNMP)
- Energy consumption meters(Kwapi framework)
- インストールの方法はこちらを参照。
- 本エージェントは直接データベース接続する必要はなく、収集されたサンプルはAMQPを介して_
notification agent_に送信され、処理される。 - Liberty以前のリリースでは各エージェント内で処理されていた。
Compute agent
- 本エージェントはVMインスタンスやコンピュートノードのリソース使用状況を取得する。
- 本エージェントはハイパーバイザとの密接なインタラクションが求められるため、関連メトリックを収集する個々のエージェントとしてホストマシン内でローカルに動作するため、各コンピュートノードにインストールする必要がある。インストール方法はこちらを参照。
- _
central agentと同様に、収集されたサンプルはAMQPを介してnotification agent_に送信される。 - 対応しているハイパーバイザは上述の通りであり、ハイパーバイザの種類によって収集可能なメトリックも異なり、ハイパーバイザとそれに対応するメトリックはこちらを参照。
IPMI agent
- このエージェントはIPMIセンサとIntel Node Managerのデータを各コンピュートノード上で収集する。
-
ipmitool utilityのインストールが必要で、ベアメタルサービスによって管理されるノード以外の各コンピュートノードにインストールされる。 - 仮にIPMIやIntel Node Managerをコンピュートノードがサポートしていなくても、エージェント内で妥当性を確認する機構を備えているため問題ないが、パフォーマンスの観点から、IPMIをサポートしないコンピュートノードにはインストールしない方がいい。
- _
central agentと同様に、収集されたサンプルはAMQPを介してnotification agent_に送信される。 - サポートしているメトリックはこちらを参照。
- _
ipmi agent_とベアメタルサービス(Ironic)を同じコンピュートノード上に導入してはならない。conductor.send_sensor_dataが設定されていた場合、IPMIセンササンプルの競合が起きる。
HAの実現方法
- _
polling agentとnotification agent_はHA構成、つまり機能をいくつかのエージェントインスタンスを並行動作せることで負荷分散させることができる。 -
Toozは、インスタンスグループを制御し、分散的に動作するサービスバックエンド上にAPIを提供するライブラリであり、HAのために以下のような多様なドライバをサポートしている。- Zookeeper
- Redis
- Memached
- HA動作のためにはこれらドライバに適切な設定をする必要があり、基本的には
ceilometer.confのオプションにに変更を加える。詳細はこちらを参照。
Notification agentのHA構成
- Kiloリリースにおいて、_
notification agentの負荷分散機能が追加され、特にnotification agent_にパイプライン処理させる場合に有効である。 -
ceilometer.conf内のbackend_urlを設定し、Notification sectionセクション内のworkload_partitioningを有効にする必要がある。 - Libertyでは、_
notification agent_は全エージェントに対して複数のキューを作成するが、キューの数はceilometer.conf内のpipeline_processing_queuesにて制御可能である。数が多いほど並列処理性能は向上するが、メモリを多く消費し、タスク起動にも時間がかかる。起動しているエージェントに対し約3倍のキューを用意することが推奨されている。
Polling agentのHA構成
-
backend_urlオプションが設定されていなければ、_central agentとcompute agent_は各々単一インスタンスとしてのみ正しく動作する。 - _
polling agent_のインスタンスの可用性確認はheartbeatメッセージ交換により実現される。つまり、インスタンスに対するコネクションがロストしたなら、処理は残りのインスタンスに再割当てされる。 - Memcachedもタイムアウト値を用いるため、これはheartbeat値より大きい必要がある。
- 後方互換性のため、_
central agent_の設定はグループ毎に異なる設定方法もサポートしており、有効化のためには、Central section内のpartitioning_group_prefixに値を設定する必要がある。 -
compute agentにおいて負荷分散させる場合には、ceilometer.conf内のCompute sectionにおいて、work_partitioningをTrueに設定する必要がある。
Telemetryへのサンプルの送信
-
データ収集の大部分は自動で実行されるが、ユーザが定義した収集項目をTelemetryサービスにRestAPIを介して送信することもできる。
-
これはコードや設定ファイルの修正なしに実現でき、送信するデータは実際に存在するメトリックか否かに限らず、ユーザが定義するメトリックをPOSTリクエストに記述する。
-
ユーザ定義メトリックが既存のメトリックと競合するのであれば、属性フィールドとメトリック名は同じでなければならない。
-
ユーザ定義メトリックをコマンドラインにて送信する場合には以下の属性フィールドを明示する必要がある。
- ID(--resource-id)
- メトリック名(--meter-name)
- メトリック種別(--meter-type)
- Gauge
- Delta
- Cumulative
- 単位(--meter-unit)
- 値(--sample-volume)
コマンドラインによるサンプルの送信$ ceilometer sample-create -r 37128ad6-daaa-4d22-9509-b7e1c6b08697 \ -m memory.usage --meter-type gauge --meter-unit MB --sample-volume 48 +-------------------+--------------------------------------------+ | Property | Value | +-------------------+--------------------------------------------+ | message_id | 6118820c-2137-11e4-a429-08002715c7fb | | name | memory.usage | | project_id | e34eaa91d52a4402b4cb8bc9bbd308c1 | | resource_id | 37128ad6-daaa-4d22-9509-b7e1c6b08697 | | resource_metadata | {} | | source | e34eaa91d52a4402b4cb8bc9bbd308c1:openstack | | timestamp | 2014-08-11T09:10:46.358926 | | type | gauge | | unit | MB | | user_id | 679b0499e7a34ccb9d90b64208401f8e | | volume | 48.0 | +-------------------+--------------------------------------------+
データ収集と加工処理
- パイプラインを用いたデータ収集と加工処理に関して説明する。
- パイプラインとは、データソース(サンプルやイベント)と対応する_
シンク_を紐付けて、変換や出力処理を一括して実施することである。 - データソースの設定には名前一致やポーリング間隔、関連リソース一覧、出力方法との対応付け等が含まれている。
- 収集されたデータは様々な用途に使用され、用途に応じてその更新頻度は大きく変わる。例えば、あるメトリックにおいては、課金のためには30分毎、パフォーマンス監視のためには1分毎に出力されるような場合もある。
- 短い時間間隔でのポーリング処理、例えば10秒毎のような短い時間間隔での処理は、大量のデータが生じ、Telemetryや他のバックエンドサービスにも処理影響を及ぼすため避けるべきである。
- _
シンク_では取得したデータの変換や出力のロジックを提供し、実際には、ハンドラのチェインを指す。 - チェインは0以上の変換でスタートし、1以上の発行で終了する。チェインの最初の変換では、該当するソースに対して、変化率計算、単位変換、集約処理などいくつかのアクションがなされる。
パイプラインの設定
- パイプライン処理設定はデフォルトでは
pipeline.yamlやevent_pipepline.yamlといったceilometer.confとは異なる設定ファイルに記述されている。 - 上記パイプライン処理設定ファイルパスは'ceilometer.conf'内の
pipeline_cfg_fileとevent_pipeline_cfg_fileにて指定する。 - メトリックのパイプライン定義は以下の通りである。
---
sources:
- name: 'source name'
interval: 'how often should the samples be injected into the pipeline'
meters:
- 'meter filter'
resources:
- 'list of resource URLs'
sinks
- 'sink name'
sinks:
- name: 'sink name'
transformers: 'definition of transformers'
publishers:
- 'list of publishers'
- sourcesセクションにおけるintervalの単位は秒で定義され、パイプラインに挿入するサンプルのポーリング間隔を決定する。
- パイプラインに使用するメトリックリストを定義する方法は以下のようにいくつか存在し、リストに登録可能なメトリック一覧はこちらを参照。
- すべてのメトリックを含む場合は、'*'ワイルドカードシンボルを用いる。負荷を考慮するなら、使用するメトリックを明示した方がいい。
- メトリックを含める場合は
meter_nameシンタックスを、含めない場合は!meter_nameシンタックスを活用する。
- 重複チェックはしていないので、同じメトリック定義が複数存在すれば、同アクションが複数実行される。
- 整理すると、メトリック定義は以下の組み合わせが存在する。
- ワイルドカードシンブルのみを利用。
- 含めるメトリックをリストに明示。
- 含めないメトリックをリストに明示。
- 含めないメトリックとワイルドカードを利用。
- 少なくとも1つ以上のメトリック定義が
metersセクションに含まれなければならず、meter_nameと!meter_nameは共存してはならない。また、ワイルドカードシンボルとmeter_nameは共存できない。 - オプションである
resourcesセクションはポーリングのためのリソースURLを静的に記述できる。 -
transformersセクションは変換定義を記述し、変換方法には以下のような種類がある。
| Name of transformer | Reference name for configuration |
|---|---|
| Accumulator | accumulator |
| Aggregator | aggregator |
| Arithmetic | arithmetic |
| Rate of change | rate_of_change |
| Unit conversion | unit_conversion |
| Delta | delta |
-
publishersセクションは変換後の出力先対象リストを示す。 - 同様にイベントパイプラインも以下のように記述できる。
---
sources:
- name: 'source name'
events:
- 'event filter'
sinks
- 'sink name'
sinks:
- name: 'sink name'
publishers:
- 'list of publishers'
Transformers
-
transformersの定義方法について説明する。基本的なパラメータは以下である。- name: 変換方法の定義名
- parameters: 変換方法に関するパラメータ
-
parametersセクションはsourceやtargetとこれに紐づくサブフィールドなど、変換に必要なフィールドを含む。
Rate of Change transformer
- 使用率を計算する。
transformers:
- name: "rate_of_change"
parameters:
target:
name: "cpu_util"
unit: "%"
type: "gauge"
# スケールファクターを定義しており、複数CPU対応やナノ秒対応を実施。
scale: "100.0 / (10**9 * (resource_metadata.cpu_number or 1))"
transformers:
- name: "rate_of_change"
parameters:
source:
map_from:
name: "disk\\.(read|write)\\.(bytes|requests)"
unit: "(B|request)"
target:
map_to:
name: "disk.\\1.\\2.rate"
unit: "\\1/s"
type: "gauge"
Unit Conversion transformer
- 単位変換する。
transformers:
- name: "unit_conversion"
parameters:
target:
name: "disk.kilobytes"
unit: "KB"
scale: "volume * 1.0 / 1024.0"
transformers:
- name: "unit_conversion"
parameters:
source:
map_from:
name: "disk\\.(read|write)\\.bytes"
target:
map_to:
name: "disk.\\1.kilobytes"
scale: "volume * 1.0 / 1024.0"
unit: "KB"
Aggregator変換
- サンプルを、数あるいは時間によって集約する。
-
sizeオプションにより集約させるサンプル数を定義し、retention_timeオプションにて集約するタイムアウト時間を定義する。。 - サンプルは
project_id、user_id、resource_metadataの属性に応じて集約される。指定した属性で集約するためには、設定ファイルで定義する必要がある。- first: 最初を保持
- last: 最後を保持
- drop: 破棄
```yaml:resource_metadataにより60秒毎に集約。最後の取得したサンプルの`resource_metadata`を保持
transformers:
- name: "aggregator"
parameters:
retention_time: 60
resource_metadata: last
```yaml:`user_id`と`resource_metadata`によって15サンプル毎に集約。最初に取得したサンプルの`user_id`を保持し、`resource_metadata`は破棄する。
transformers:
- name: "aggregator"
parameters:
size: 15
user_id: first
resource_metadata: drop
Accumulator変換
- サンプルをキャッシュしてパイプラインに一括して流す。
transformers:
- name: "accumulator"
parameters:
size: 15
Multi Meter Arithmetic変換
- 複数のメトリックに対する計算を実現。
- 変換の設定ファイルにおける
targetセクションに記述。 - NaNデータの場合は計算結果は出力されず、ログにwarningが出力される。
# memory_util = 100 * memory.usage / memory
transformers:
- name: "arithmetic"
parameters:
target:
name: "memory_util"
unit: "%"
type: "gauge"
expr: "100 * $(memory.usage) / $(memory)"
transformers:
- name: "arithmetic"
parameters:
target:
name: "avg_cpu_per_core"
unit: "ns"
type: "cumulative"
expr: "$(cpu) / ($(cpu).resource_metadata.cpu_number or 1)"
Delta変換
- サンプルの時間的差分を計算。
transformers:
- name: "delta"
parameters:
target:
name: "cpu.delta"
growth_only: True
Meter definitions
- TelemetryサービスはOpenStackサービスの通知をフィルタリングすることで、いくつかのメトリックを収集する。
- Libertyリリースからは、メトリック定義は
ceilometer/meter/data/meter.yamlに記述されている。 - 注意点:
- 既存の
meter.yamlファイルを削除してはならない。 - 収集されるメトリックは参照するOpenStack設定ドキュメントによって異なる場合がある。
- 既存の
---
metric:
- name: 'meter name'
event_type: 'event name'
type: 'type of meter eg: gauge, cumulative or delta'
unit: 'name of unit eg: MB'
volume: 'path to a measurable value eg: $.payload.size'
resource_id: 'path to resource id eg: $.payload.id'
project_id: 'path to project id eg: $.payload.owner'
- 上記定義は
name、event_type、type、unit、volumeフィールドを用いて記述しており、対応するイベントが存在すれば、メトリックからサンプルが生成される。 -
meter.yamlファイルには、通知から取得する全メトリックのサンプルの定義が記述されている。 - 通知メッセージからの値を見つけるため、各フィールドはJSONパスで記述されており、フィールド定義のためには処理される通知のフォーマットを知る必要がある。
- 探索されるJSONパスのは
$.で始まり、例えばペイロードからsizeの情報を取得する場合には、$.payload.sizeを定義する必要がある。 - 通知メッセージが複数のメトリックを含む場合は、
*を活用することで対応できる
---
metric:
- name: $.payload.measurements.[*].metric.[*].name
event_type: 'event_name.*'
type: 'delta'
unit: $.payload.measurements.[*].metric.[*].unit
volume: payload.measurements.[*].result
resource_id: $.payload.target
user_id: $.payload.initiator.id
project_id: $.payload.initiator.project_id
- 上記例では、
nameフィールドは通知メッセージ内の多くのメトリック名に一致するJSONパスとなる。 - より複雑な設定記述も可能で、以下の例では
volumeとresource_idフィールドに対して、算術や文字連結を適用している。
---
metric:
- name: 'compute.node.cpu.idle.percent'
event_type: 'compute.metrics.update'
type: 'gauge'
unit: 'percent'
volume: payload.metrics[?(@.name='cpu.idle.percent')].value * 100
resource_id: $.payload.host + "_" + $.payload.nodename
-
timedeltaプラグインを用いることで1つの通知から2つの日時フィールドの差分を計算することもできる。
---
metric:
- name: 'compute.instance.booting.time'
event_type: 'compute.instance.create.end'
type: 'gauge'
unit: 'sec'
volume:
fields: [$.payload.created_at, $.payload.launched_at]
plugin: 'timedelta'
project_id: $.payload.tenant_id
resource_id: $.payload.instance_id
- 下記に示すような、
meter.yamlファイル下部に記述してある既存メトリックのいくつかはvolumeを1と定義しているが、将来的に削除される可能性がある。
---
metric:
- name: 'meter name'
type: 'delta'
unit: 'volume'
volume: 1
event_type:
- 'event type'
resource_id: $.payload.volume_id
user_id: $.payload.user_id
project_id: $.payload.tenant_id
- これらのメトリックはデフォルトではロードされない。
- ロードするためには
ceilometer.confのdisable_non_metric_metersをfalseにする必要がある。
Block Storage audit script setup to get notification
pass
Storing samples
- Telemetryサービスは、pollersや通知から取得したデータの一貫性を担保する別のサービスを保持している。
- データはファイルや上述のデータベースに格納され、外部システムにHTTP dispatcherを介して送信される。
-
ceiloeter-collectorサービスはAMQのメッセージバスからデータを受信し、そのデータポイントをターゲットに送信する。 - 本サービスは設定されたdispatcherにアクセスできるサーバ上で動作させる必要がある。
- 同時に複数のdispatcherを動作することもできる。
-
ceilometer.conf内のcollector_workersオプションの設定を変更することで、複数のceiloeter-collectorプロセスを同時に動作させることも、プロセス当たりに複数のワーカスレッドを動作させることもできる。詳細は[こちら](http://docs.openstack.org/mitaka/config-reference/telemetry/telemetry_service_config_opts.htmlを参照。
Database dispatcher
- Database dispatcherがデータストアとして設定するなら、
time_to_live(ttl)オプションを設定する必要がある。 - デフォルトでは
-1に設定されているが、これは∞であることを意味している。 - 本オプションは秒単位である。
- 各サンプルはタイムスタンプを保持しており、
ttlはサンプルがデータベースから、そのサンプルがアクセスされてから何秒後に削除されるかを定義している。 - 例えば、600に設定されていれば、600秒前の全てのサンプルはデータベースから削除される。
- いくつかのデータベースはデータベースそのものがttlを保持している場合もあるが、サポートしていないデータベースはコマンドラインスクリプト
ceilometer_expirerをクーロンとして活用することで解決を図っている。
| Database | TTL value support | Note |
|---|---|---|
| MongoDB | Yes | データベースのTTL機能を活用 |
| SQL-based back ends | Yes | ceilometer-expirerで対応 |
| HBase | No | 未対応 |
| DB2 NoSQL | No | 未対応 |
HTTP dispatcher
- Telemetryサービスは外部のHTTPターゲットにサンプルを送信することもできる。
-
ceilometer.confのdispatcherオプションをhttpに変更する必要がある。詳細はこちらを参照。
File dispatcher
・同上。詳細はこちらを参照。
Gnocchi dispatcher
・同上。詳細はこちらを参照。
データの回収
- Telemetryサービスは格納したデータへのアクセス方法を提供している。
Telemetry v2 API
- TelemetryサービスはRESTful APIを介して収集したサンプルやメトリック一覧やアラーム定義等の情報等を提供する。
- Telemetry API URLはOpenStack Identityサービスのサービスカタログから確認でき、アクセスには適切なトークンや権限が必要である。
- 詳細はこちらを参照。
Query
- APIはクエリ等の拡張機能を有している。
- サンプルやアラームのAPIエンドポイントに対して、単純または複雑なクエリ記述が可能である一方で、他のエンドポイントには単純なクエリ記述のみ対応している。
単純なクエリ
- 多くのAPIエンドポイントは以下の記述に対応している。
fieldopvaluetype
- サンプルタイプは指定する必要がある。
- フィールドによっては、例えば以下のフィールドは実際よりも短い名前も許容する場合があり、内部的に変換処理がなされる。
-
project_id-> プロジェクト名 -
resource_id-> リソース名 -
user_id-> ユーザ名
-
-
ANDの使用可能。
複雑なクエリ
- 以下の表現は
Sample、Alarm、AlarmChangeに対して適用可能。詳細はこちらを参照。+!=<<=>>=andor-
not(DBによって異なる動きをする点に注意)
- 以下のようなSQLライクな表現も可能。
orderbylimitfilter
統計
- 基本的な統計的計算方法も提供している。
avgcardinalitycountmaxminstddevsum
コマンドラインクライアント
- Telemetryサービスはコマンドラインのクライアントを提供しており、クライアントは上記APIを参照することで実行結果を返す。
-
ceilometerコマンドを使用するためには、python-ceilometerclientパッケージをインストールする必要がある。 - OpenStack Identityサービスの認証を活用するので、適切な認証設定と
--auth-urlパラメータをオプションにて指定する必要がある。
Pythonを利用
- コマンドラインクライアントライブラリはpython bindingsも提供。詳細はこちらを参照。
import ceilometerclient.client
# クライアントインスタンスの作成
cclient = ceilometerclient.client.get_client(
VERSION,
username=USERNAME,
password=PASSWORD,
tenant_name=PROJECT_NAME,
auth_url=AUTH_URL)
# ceilometer meter-list
cclient.meters.list()
# ceilometer sample-list
cclient.samples.list()
Publishers
- Telemetryサービスは収集したデータを
ceilometer-collectorや外部システムに転送する仕組みを有している。 - _
publisherはメッセージバスを介してデータをストレージに保存する、あるいは複数の外部システムに送信する。1つのチェインには複数のpublisher_を含む。 - 複数の要件を満たすため(課金システムのように安定性を重視するか、監視システムのように即時性を重視するか)、各データポイントに対して、複数の_
publisher_を適用可能である。 - _
publisher_の - 設定は
pipeline.yamlファイルのpublishersセクションにて定義される。 - 以下の_
publisher_のタイプを定義可能である。-
notifier: AMQPを利用。 -
rpc: lossy AMQPを利用。同期をとるためパフォーマンスに課題あり。Libertyから非推奨。 -
udp: UDPを利用。 -
file: ファイルに記述。
-
-
notifierとrpcではkafka publisherで活用する以下のオプションを定義可能。- per_meter_topic
- polich
- topic
- max_bytes
- backup_count
アラーム
pass
測定
pass
イベント
pass
トラブルシューティング
pass
ベストプラクティス
pass