家のデスクトップパソコンでディープラーニングとかしてみようと思ったので備忘録として残します。
Qiitaド初心者ですので何か問題などあれば遠慮なく教えてください
環境
・OS : Windows11(64bit)
・GPU: GeForce GTX 1650
・Visual Studio 2022 Enterprise
windows10だとWSL上でGUIが使えないそうなのでwindows11は必須な気がします
WSL2のインストール
これによってWindows上でLinuxを動かせるそうです、今までVMwareとかは使ったことはあったのですが今はWSL2が主流のようですね。
https://docs.microsoft.com/ja-jp/windows/wsl/install-manual#step-4---download-the-linux-kernel-update-package
ほかのページも少し試したのですが、結局公式のドキュメント通りに進めないとエラーが出てしまいました。
PowerShellを管理者権限で起動して以下のコマンドを実行です
dism.exe /online /enable-feature /featurename:Microsoft-Windows-Subsystem-Linux /all /norestart
dism.exe /online /enable-feature /featurename:VirtualMachinePlatform /all /norestart
wsl --set-default-version 2
続いてどのLinuxを入れるかどうかです。自分は今までubuntu 18.04 LTSをよく使っていたのですが調べていた感じ20.04の方が多いようなのでそちらをインストール
https://www.microsoft.com/store/productId/9MTTCL66CPXJ
起動したら最初に上のツールバーを右クリックしてプロパティを開き、オプションにある[Ctrl+Shift+C/Vをコピー/貼り付けとして使用する]にチェックをしましょう。コピペができるようになります。
ubuntuインストール後
まずはお決まりのアップグレード
sudo apt-get update
sudo apt-get upgrade
cuda tool kitをインストール
https://zenn.dev/ylabo0717/articles/48796b7f3470c7
確認したところcuda11.7が入っているようなので対応したcuDNNをインストールします。
先ほどのサイトを参考にwindows側のブラウザ上でubuntu用のインストーラをダウンロードし、ubuntu側でインストールします。
tensorflowのインストール
sudo apt update
sudo apt install python3-dev python3-pip python3-venv
pip3 install --upgrade tensorflow
pythonを起動してみたところ無事にimportできたので問題なさそう。
openCVのインストール
続いてリアルタイム物体認識を実装してみたいので必要なopencvをインストール
sudo apt update
sudo apt install libopencv-dev python3-opencv
tensorflowの物体認識APIをインストール
あとは公式のページにあったこちらの通り進めていきます。
※dockerのほうがうまくいかなかったのでpipで入れるほうを進めました
https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/tf2.md
git clone https://github.com/tensorflow/models.git
cd models/research
# Compile protos.
protoc object_detection/protos/*.proto --python_out=.
# Install TensorFlow Object Detection API.
cp object_detection/packages/tf2/setup.py .
ページでは以下のコマンドを実行するとなっていますがそのまま実行するとエラーが出てしまいました。
以下のサイトを参考にpipをアップグレード
https://stackoverflow.com/questions/63687113/no-such-option-use-feature-while-installing-tensorflow-object-detection-api
python3 -m pip install --upgrade pip
python3 -m pip install --use-feature=2020-resolver .
# Test the installation.
python3 object_detection/builders/model_builder_tf2_test.py
pipをアップグレードしたらうまくいきました、テストも完了です。
いよいよ実行!と思ったらWSLにカメラが認識されておりません…
WSL2でカメラを認識させるために
認識させるために必要な「usbipd」コマンドを実行しましたがインストールされていないようなので「usbipd」のインストールをします。
https://docs.microsoft.com/ja-jp/windows/wsl/connect-usb
こちらのサイトを参考にPowershellを管理者モードで開いて以下のコマンドを実行
winget install --interactive --exact dorssel.usbipd-win
終わったらいったんパソコンを再起動させます。
WSLのUbuntuも起動させておきましょう。
以下のサイトを参考にUbuntuにUSBIPツールを入れます
https://docs.microsoft.com/ja-jp/windows/wsl/connect-usb
sudo apt install linux-tools-5.4.0-77-generic hwdata
sudo update-alternatives --install /usr/local/bin/usbip usbip /usr/lib/linux-tools/5.4.0-77-generic/usbip 20
完了したらUbuntuを再起動
再度Powershellを管理者モードで開いてカメラをWSLでアクセスできるようにします。
参考にしたサイトはこちら
https://scratchpad.jp/wsl2-usb-camera-1/
usbipd wsl list
usbipd wsl attach --busid 5-6 #IDはlistを参考に使いたいカメラのIDを選んでください
ここまでようやく到達したわけですがまだWSLはカメラを認識してくれません。「/dev/video」としては認識されていない様子…
こちらのサイトを参考にカーネルを更新します
https://zenn.dev/fate_shelled/articles/06d109bd10b702
基本的に上記のサイトのやり方でうまくいくとは思うのですが自分の場合以下の方が質問してるようなエラーが出てしまいました。
[ WARN:0@10.310] global /io/opencv/modules/videoio/src/cap_v4l.cpp (1000) tryIoctl VIDEOIO(V4L2:/dev/video0): select() timeout.
カメラが原因かなと思い下のようなカメラを購入
www.amazon.co.jp/dp/B07MBQ1PT3
しかしエラーは消えません…
ですのでカーネルのバージョンをインストール時点で最新の5.10.102.1にして再度挑戦
import cv2
i=0
cap = cv2.VideoCapture(7)
#cap.set(cv2.CAP_PROP_FRAME_WIDTH, 160)
#cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 120)
cap.set(cv2.CAP_PROP_FOURCC,cv2.VideoWriter_fourcc('M','J','P','G'))
#cap.set(cv2.CAP_PROP_FPS, 10)
print(cap.get(cv2.CAP_PROP_FPS))
print(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
print(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
print(cap.get(cv2.CAP_PROP_FOURCC))
if cap.isOpened():
while True:
_, img = cap.read()
if _:
print("OK")
Height, Width = img.shape[:2] # sizeを取得
img=cv2.resize(img, (int(Width), int(Height)))
#img=img.reshape([img.shape[0],img.reshape[1],3])
cv2.imshow("", img)
key = cv2.waitKey(1)
if key == ord('q'):
break
else:
print("yet")
cap.release()
cv2.destroyAllWindows()
menuconfigをいじったときに関係ありそうなものは片っ端からチェックを付けたのでそれもきっかけかもしれませんが成功!
(カメラ1つしか接続していないのになぜか/dev/video7で認識されてますが…)
解像度を下げたり、FPSを下げると成功するという記事もあったのですが自分はコーデックをMJPGにすると問題なく動くようになりました。
ようやく物体認識できます!
tensorflowのサンプルプログラムにトライ
それではサンプルコードを動かしてみましょう。
自分のカメラでリアルタイムの物体認識をさせてみたかったのでチュートリアルからサンプルコードをダウンロード
https://tensorflow-object-detection-api-tutorial.readthedocs.io/en/latest/auto_examples/object_detection_camera.html#sphx-glr-auto-examples-object-detection-camera-py
サンプルコードにカメラ番号の変更とコーデックのコードだけ追加します
cap = cv2.VideoCapture(7) #ここのカメラ番号の変更を忘れず!
cap.set(cv2.CAP_PROP_FOURCC,cv2.VideoWriter_fourcc('M','J','P','G')) #コーデックの変更も同じく
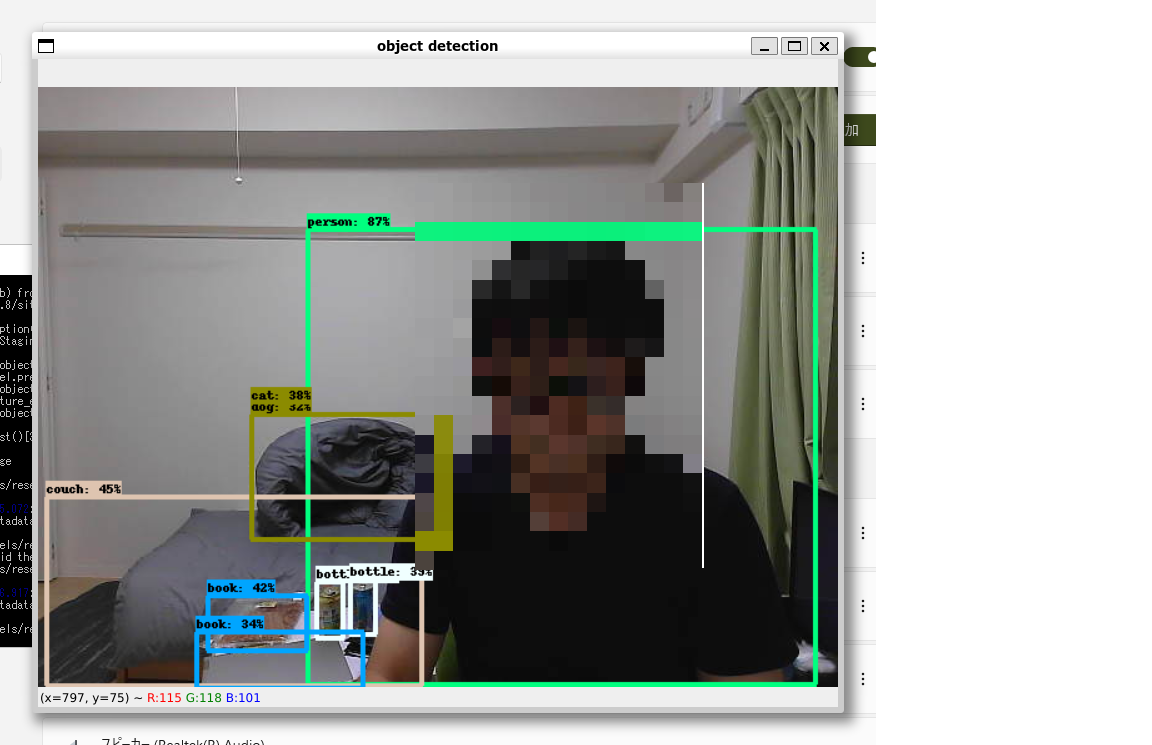
うまく認識されてそうですね!ようやくスタートラインに立てたという感じなのでここからいろいろ遊んでみたいと思います。