DirectX11でGPUスキニングを行いたい!と試行錯誤をしている中での一つの形を共有していきたいと思います。
未だ学習途中のため間違っている点や不足している点がありましたら申し訳ありません。
その1: これ
その2: モデル読込編
使用PC
・プロセッサ: Intel(R) Core(TM) i7-11800H @ 2.30GHz (16 CPUs), ~2.3GHz
・GPU: NVDIA GEForce RTX 3050 Laptop GPU
対象
- DirectX11において基礎的な3Dモデルのボーンアニメーションが出来る方
目標とする動作
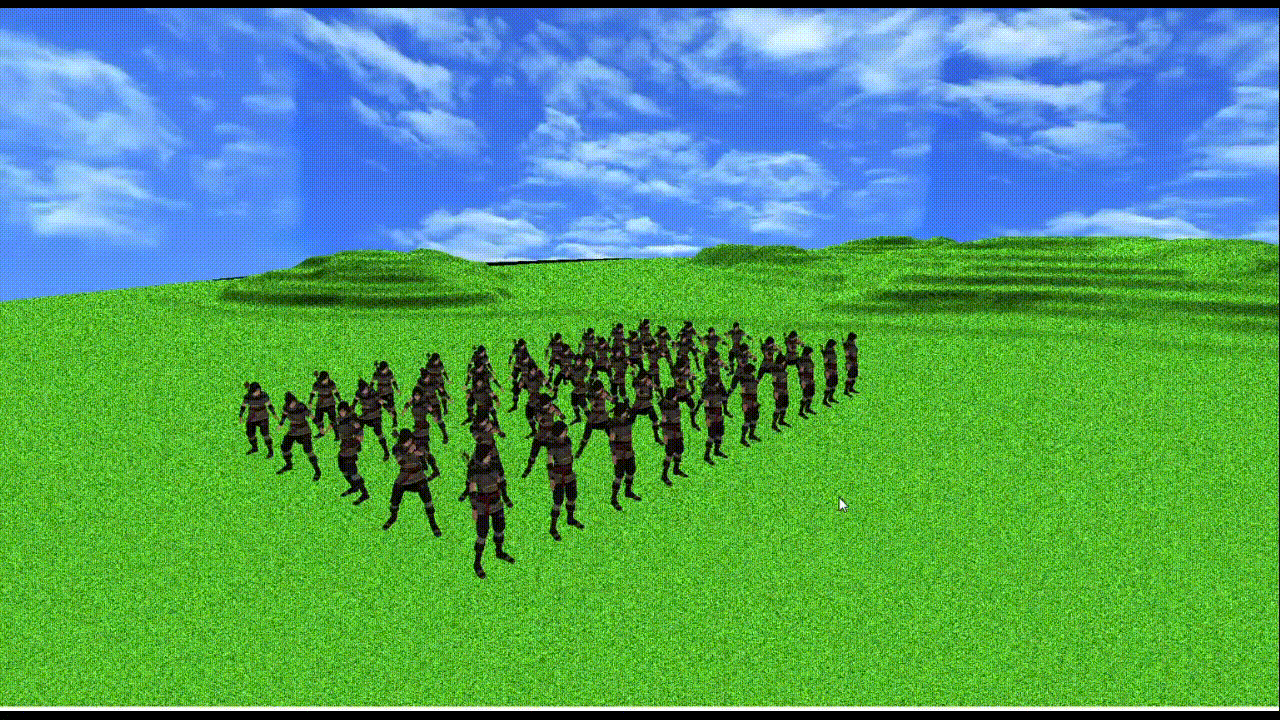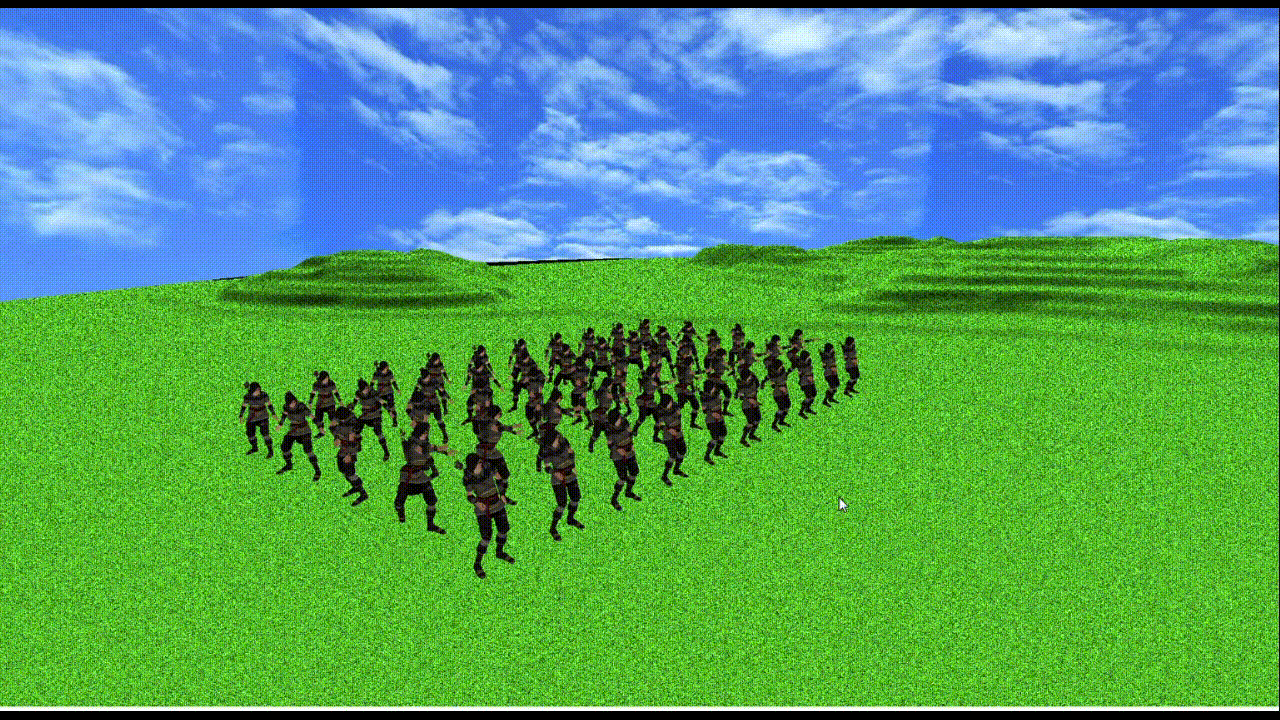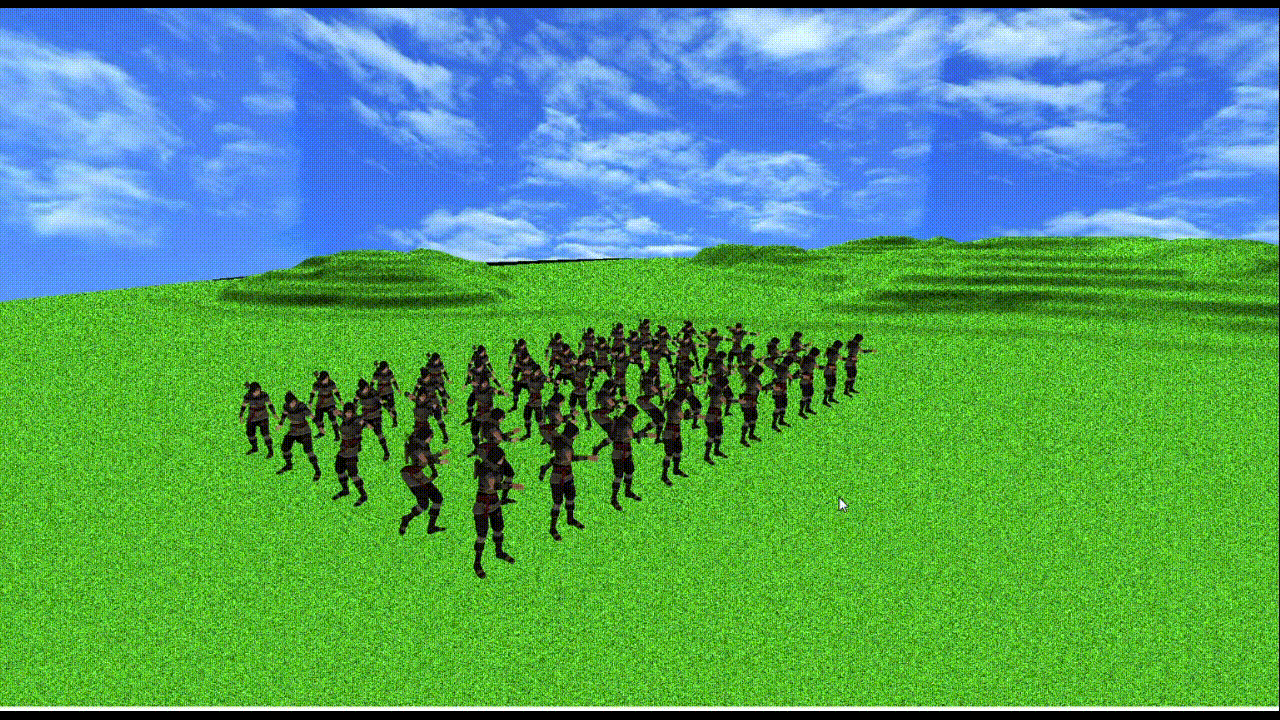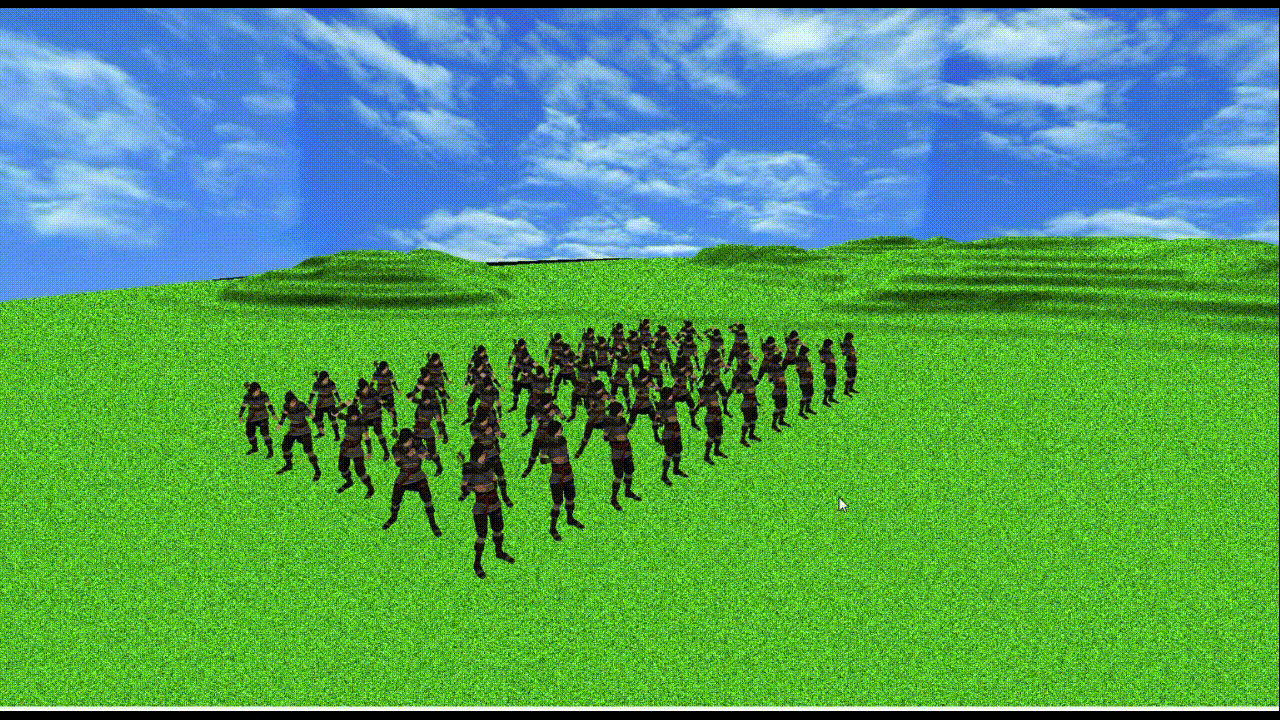
上記使用PCで
メッシュ数3つ、頂点数約1万2千、ボーン数155のモデルが50体でも60fpsになるくらいの処理速度(上記gifだとカクついちゃってるけど...)
なぜCPUじゃなくてGPUでスキニングを行うのか
結論、速いから!
スキニングの計算処理自体は
各ボーンの変換行列 * 各ボーンの重みの合計にさらに頂点位置を掛け合わせるという非常に単純な計算です。
しかしながら、最近のゲームのほとんどはアニメーションを行うモデルであっても頂点数が膨大な数になることはザラです。また、画面上に表示されるモデルの数自体も多くCPUの直列処理ではその計算量に耐えられません。
したがって、並列処理を得意とするGPUにスキニングの計算を肩代わりしてもらおうという算段です。
全体の処理の流れ
- モデルの読込 (頂点とボーン情報の取得)
- 変換前の頂点とボーンの情報、結果を格納する用のバッファをコンピュートシェーダーに送る
- コンピュートシェーダーでスキニング処理を行う [今回解説]
- CPUにスキニングを施した頂点データを返す
- スキニングが施された頂点データを頂点シェーダーに送って描画コールを行う
- 渡された頂点を用いて処理を行う [今回解説]
となります。
一回目となる今回は最初のモデル読込ではなくシェーダーから解説を行います。
個人的にシェーダー内の計算よりも厄介なのがデータの送信方法をどうするか。という点なので先にシェーダーを理解しなにをしなければならないかから始めていきましょう!
コンピュートシェーダー
DirectX11から追加されたシェーダーです。
本来、描画に関わる頂点の計算、ピクセルごとの色計算などを行うために稼働しているGPUを描画に関わらないような個所でも使用して並列処理の恩恵を受けよう。というシェーダーです。
今回はこのコンピュートシェーダーを用いてGPUにスキニングの計算を肩代わりしてもらいます。
コンピュートシェーダー
struct AnimationVertex
{
float4 pos; // 位置座標
float4 normal; // 法線
float4 diffuse; // 頂点色
float2 uv; // TextureのUV値
// ボーンに関わるステータス
// 最大4つまでとする
int4 boneIndex;
float4 boneWeight;
};
cbuffer AnimationBuffer : register(b0)
{
uint maxVertexCount; // モデルの最大頂点数
float4x4 boneMatrix[256]; // 各ボーンの変換行列
};
StructuredBuffer<AnimationVertex> inputVertexBuffer : register(t0); // 変換前の頂点バッファ
RWStructuredBuffer<VS_IN> outPutVertexBuffer : register(u0); // 変換された頂点を格納するバッファ
[numthreads(256, 1, 1)]
void main( uint3 DTid : SV_DispatchThreadID )
{
uint index = DTid.x; // スレッドidを頂点idとする
if (index >= maxVertexCount)return;
AnimationVertex inputVertex = inputVertexBuffer[index];
// スキニング計算処理
float4x4 skinMatrix;
skinMatrix = mul(boneMatrix[inputVertex.boneIndex.x], inputVertex.boneWeight.x);
skinMatrix += mul(boneMatrix[inputVertex.boneIndex.y], inputVertex.boneWeight.y);
skinMatrix += mul(boneMatrix[inputVertex.boneIndex.z], inputVertex.boneWeight.z);
skinMatrix += mul(boneMatrix[inputVertex.boneIndex.w], inputVertex.boneWeight.w);
// 出力
VS_IN outputVertex;
outputVertex.Position = mul(inputVertex.pos, skinMatrix);
// 法線用に移動を消す
skinMatrix[0][3] = 0.0f;
skinMatrix[1][3] = 0.0f;
skinMatrix[2][3] = 0.0f;
skinMatrix = transpose(inverse(skinMatrix));
outputVertex.Normal = mul(inputVertex.normal, skinMatrix);
outputVertex.Diffuse = inputVertex.diffuse;
outputVertex.TexCoord = inputVertex.uv;
// 格納用バッファに入れていく
outPutVertexBuffer[index] = outputVertex;
}
外部から渡されるデータ
AnimationVertex構造体
int4 boneIndex;
float4 boneWeight;
スキニングを行う際の頂点一つに必要な情報のまとまりです。
特筆すべきは下二つ
boneIndexは頂点に対してどのボーンの影響を受けているか、が格納されます。
boneWeightは影響を受けるボーンそれぞれどれだけ影響を受けるかという重みが格納されます。
どちらもint4とfloat4というようにメンバが4つ存在し、影響を受けられる個数が4つと制限されている形です。
AnimationBuffer 定数バッファ
cbuffer AnimationBuffer : register(b0)
{
uint maxVertexCount; // モデルの最大頂点数
float4x4 boneMatrix[256]; // 各ボーンの変換行列
};
モデル単位で必要となる情報を格納するバッファです。
maxVertexCountにはモデルの最大頂点数が格納されます。詳しくは後述ですがコンピュートシェーダーを扱う際には最大計算回数を定めないとバグの温床となるため必要です。
boneMatrixはボーンの変換行列が格納されます。最大数を定数の256と定めているのは可変にする方法が考え付かず固定にしたためです。したがって制作するゲームによっては無駄が生じる。あるいはボーン数が足りないという状況になるので適宜変更しましょう。
inputVertexBuffer 構造体バッファ
StructuredBuffer<AnimationVertex> inputVertexBuffer : register(t0); // 変換前の頂点バッファ
CPU側から変形前の計算に用いられる頂点バッファを受け取り格納されます。
StructuredBufferは定数バッファとは異なりCPU側で格納サイズを決められるため頂点情報のようなモデルごとに異なるものを格納するのに適しています。また、後述のRWStructuredBufferとは異なり読み取り専用です。
outPutVertexBuffer RW(ReadWrite)構造体バッファ
RWStructuredBuffer<VS_IN> outPutVertexBuffer : register(u0); // 変換された頂点を格納するバッファ
CPU側から変換された頂点を格納するバッファを受け取り格納されます。
結果が書き込まれCPUに渡された後このデータは頂点シェーダーで扱われます。
基本はStructuredBufferと同じですがこちらは読み書き両方ができます。計算結果をCPUに渡したいときに活用できますね。
ちなみにVS_INは頂点シェーダーで頂点を用いる際の頂点用構造体です。ボーン情報はいらないので分けています。
コンピュートシェーダーによる計算
スレッドグループとスレッド数
[numthreads(256, 1, 1)]
コンピュートシェーダーに馴染みのない人にとっては全く意味が分からない個所だと思いますのでわかりやすく解説します。
コンピュートシェーダの実行はmain関数の中がGPU内で並列に処理されます。
並列に処理されるにあたってGPUは
一回のコンピュートシェーダーによる実行の中でいくつ並列に処理すればいいかというスレッド数を設定しなければなりません。
そしてこのスレッドのまとまりをスレッドグループといいます。
そこで登場するのが[numthreads(x,y,z)]です。
引数のx, y, zはそれぞれの次元のスレッド数を指します。ではそれぞれの次元のスレッド数とはというと、実際の処理のされ方を考えていきましょう。
[numthreads(256,1,1)]
void main( uint3 DTid : SV_DispatchThreadID )
{
// DTidが取る数値は (1,1,1),(2,1,1),(3,1,1)....と増えて(256,1,1)が並列に処理
// 一回の実行でスレッド数は256
// 二回目の実行だとDTidは(257,1,1)...から増加する
}
[numthreads(256,256,1)]
void main( uint3 DTid : SV_DispatchThreadID )
{
// DTidが取る数値は
//(1,1,1),(2,1,1),(3,1,1)....(256,1,1)
//(1,2,1),(2,2,1),(2,3,1)....(256,2,1)
//....
//(1,256,1),(2,256,1),(3,256,1)...(256,256,1)の二次元配列のように並列に処理
// 一回の実行でスレッド数は256*256=65536
// 二回目の実行だとDTidは(257,257,1)...から増加する
}
のように実行されます。
つまり、今回の頂点バッファなどの一次元配列のようなものはxのみを増加させ指定する方が効率的(二次元で扱わなくてもいい)なので[numthreads(256,1,1)]としています。
よって、コンピュートシェーダーを一度呼び出すと256のidまで並列処理が実行されます。
今回は導入として簡単に解説をしていますがより正確で詳細な解説は公式リファレンスを確認いただければと思います。
実行回数の制限
uint index = DTid.x; // スレッドidを頂点idとする
if (index >= maxVertexCount)return;
スレッドidを頂点idとして最大頂点数よりも大きければ処理をしません。
スレッドグループごとの呼び出しとなるためDTidは最大頂点数を超える可能性があります。
スキニング計算
// スキニング計算処理
float4x4 skinMatrix;
skinMatrix = mul(boneMatrix[inputVertex.boneIndex.x], inputVertex.boneWeight.x);
skinMatrix += mul(boneMatrix[inputVertex.boneIndex.y], inputVertex.boneWeight.y);
skinMatrix += mul(boneMatrix[inputVertex.boneIndex.z], inputVertex.boneWeight.z);
skinMatrix += mul(boneMatrix[inputVertex.boneIndex.w], inputVertex.boneWeight.w);
// 出力
VS_IN outputVertex;
outputVertex.Position = mul(inputVertex.pos, skinMatrix);
最初に解説した式と変わりありません。
結果の格納
// 格納用バッファに入れていく
outPutVertexBuffer[index] = outputVertex;
RWStructuredBufferのoutPutVertexBufferに格納していきます。
書き込みが可能なので配列のようにindexを指定して直接中に格納します。
以上です。意外にコンピュートシェーダーの中は簡単だったのではないでしょうか。
頂点シェーダー
StructuredBuffer<VS_IN> vertexBuffer : register(t0); // スキニング処理が施された頂点バッファ
struct CSVS_IN
{
uint vertexID : SV_VertexID; // ユニークな頂点idが自動に格納される
};
void main(in CSVS_IN In, out PS_IN Out)
{
VS_IN vtx = vertexBuffer[In.vertexID];
// なにか頂点に色々処理する
}
通常のSetVertexBufferを用いずCPUから送信される構造体バッファを用いて頂点情報をピクセルシェーダーに送信するのが重要です。
外部から渡されるデータ
vertexBuffer 構造体バッファ
StructuredBuffer<VS_IN> vertexBuffer : register(t0); // スキニング処理が施された頂点バッファ
CPUから渡されるコンピュートシェーダーで計算が施された頂点バッファが格納されます。
このデータに対し書き込みは行わないのでStructuredBufferで取り扱います。
CSVS_IN構造体
struct CSVS_IN
{
uint vertexID : SV_VertexID; // ユニークな頂点idが自動に格納される
};
コメントの通りですがGPUで処理される際自動でどの頂点番号に処理するべきかのidが格納されます。
頂点シェーダーによる計算
頂点情報の取得
VS_IN vtx = vertexBuffer[In.vertexID];
コンピュートシェーダーのときと取得方法は同じです。
以降はこのデータを用いて各々好きなように頂点計算を行えます。
CPU内の処理に向けて
シェーダーの説明を終えたところで改めて全体の流れを見ていきます。
- モデルの読込 (頂点とボーン情報の取得)
- 変換前の頂点とボーンの情報、結果を格納する用のバッファをコンピュートシェーダーに送る
- コンピュートシェーダーでスキニング処理を行う [今回解説]
- CPUにスキニングを施した頂点データを返す
- スキニングが施された頂点データを頂点シェーダーに送って描画コールを行う
- 渡された頂点を用いて処理を行う [今回解説]
となります。
次回は残りの読込と特に重要などうやってシェーダーにデータを渡すのかを説明したいと考えています。