前回に引き続きDirectX11でGPUスキニングに関わる解説を行っていきたいと思います。
その1: シェーダー編
その2: これ
内容としては今回の方が厄介だと感じているので前回を見てない方は是非第一回を見ていただければと思います。
目標とする動作
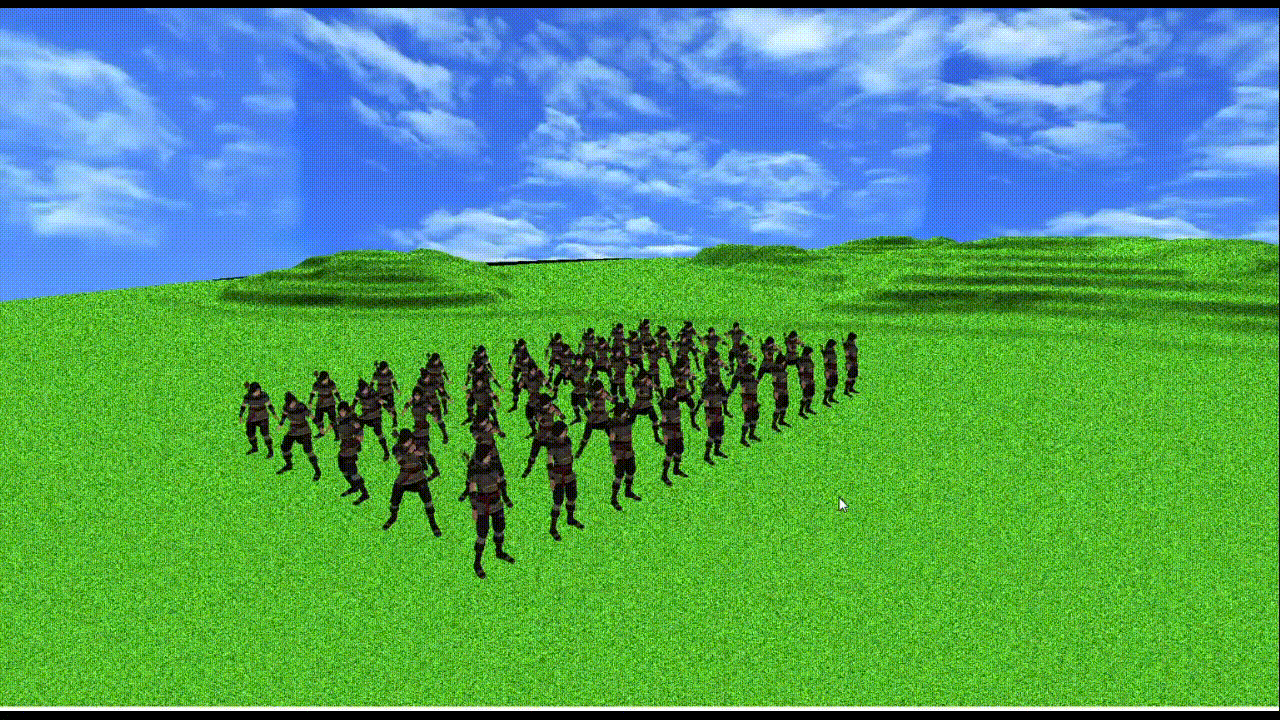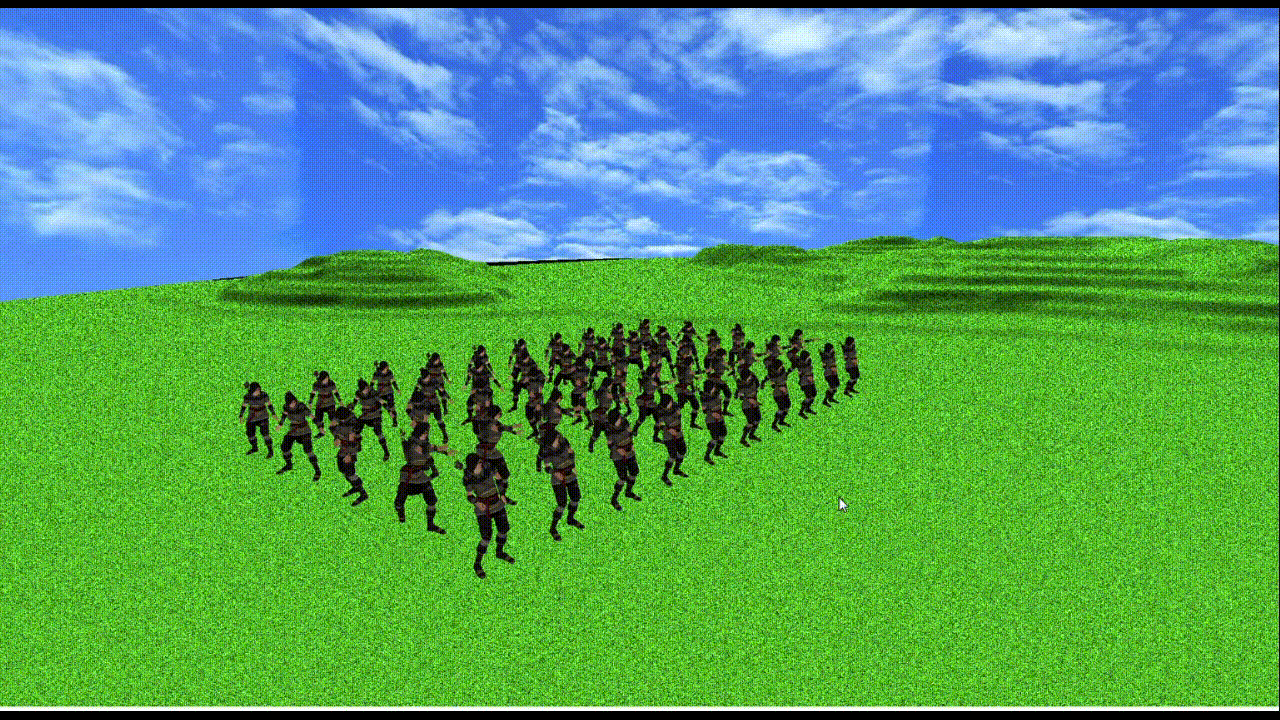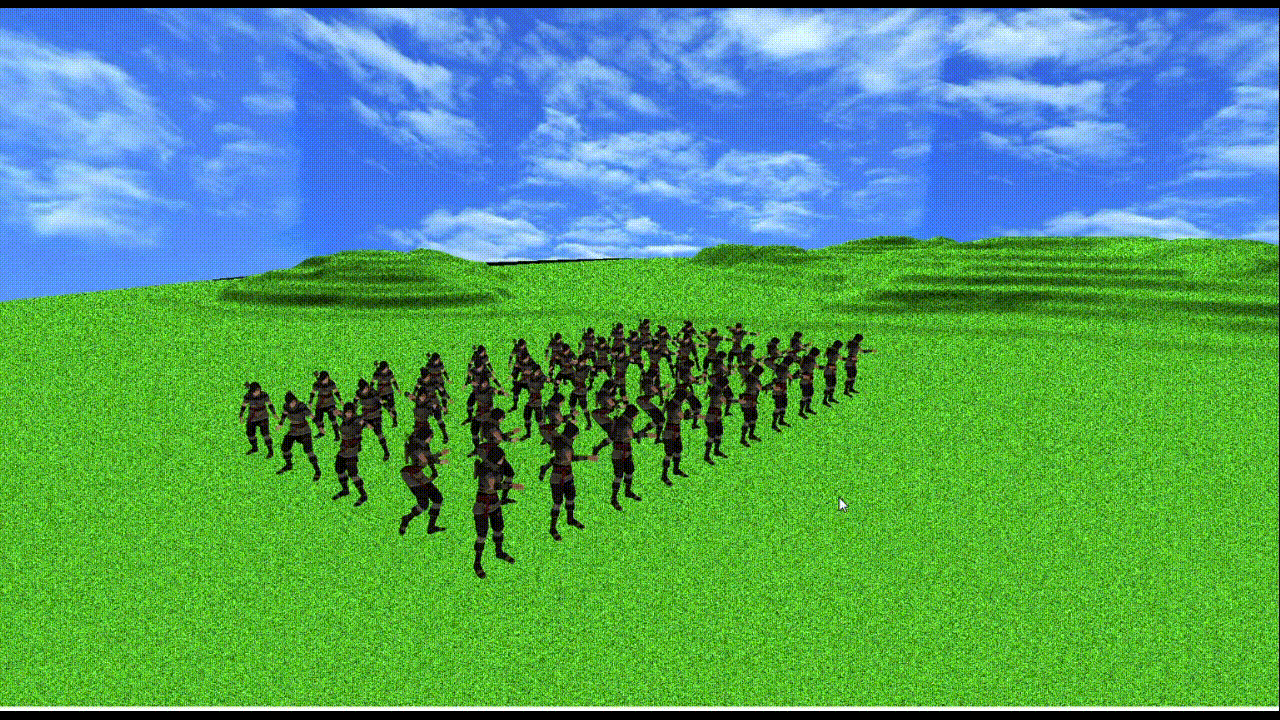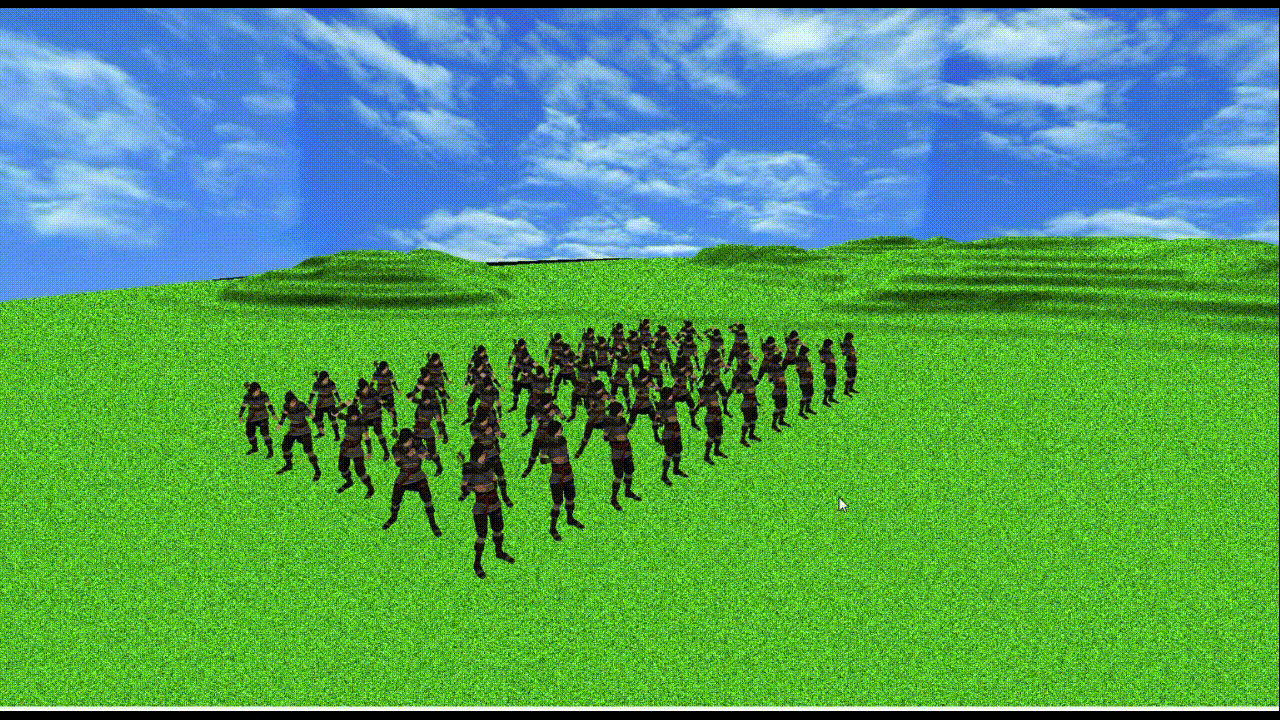
上記使用PCで
メッシュ数3つ、頂点数約1万2千、ボーン数155のモデルが50体で60fpsになる(上記gifだとカクついちゃってるけど...)
全体の流れのおさらい
- モデルの読込 (頂点とボーン情報の取得) [今回解説]
- 変換前の頂点とボーンの情報、結果を格納する用のバッファをコンピュートシェーダーに送る [今回解説]
- コンピュートシェーダーでスキニング処理を行う
- CPUに計算結果を返す
- 計算結果を頂点シェーダーに送って描画コールを行う [今回解説]
- 渡された頂点を用いて処理を行
ということで今回は読込からデータの送受信をしていきましょう。
モデルの読込
具体的な読込方法は色々あるため割愛しますが何が必要かは説明していきます。
| 型 | 名前 | 解説 |
|---|---|---|
| float4 | Position | 位置 |
| float4 | Normal | 法線 |
| float4 | Diffuse | 頂点色 |
| float2 | UV | テクスチャ座標 |
| int[n] | BoneIndex | 対応するボーンのインデックス |
| float[n] | BoneWeight | それぞれのボーンの重み |
一つの頂点が影響を受けるボーンの個数n=4として説明していきます。
コンピュートシェーダーで記述されていたAnimationVertex構造体と同じです。
ただし前述の通りボーンに関わるデータは頂点シェーダーにはいらないデータなので渡さないように型を分けるなどをしていくと効率的かと思います。
また、モデルの頂点数と対応するインデックスバッファも必要ですので確保してください。
| 型 | 名前 | 解説 |
|---|---|---|
| Matrix4x4 | OffsetMatrix | オフセットボーン行列 |
| Matrix4x4 | BoneMatrix | ボーン行列 |
ボーン行列はアニメーションの特定フレーム時の位置や回転情報が格納される行列です。
オフセット行列はアニメーションの初期状態(基本はTポーズ)の時のボーンの位置や回転情報が格納される行列です。これらと頂点位置を掛け合わせてスキニング計算を行います。
データをCPUからGPUに渡すための準備 <超重要>
スキニング計算のためにシェーダーへデータを渡すにはViewと定数バッファを扱います。
Viewにはいくつかの種類がありますが今回は送信に扱う代表的な二種を説明します。
ShaderResourceView (SRV)
CPUで作られたID3D11Bufferを元にして作成し、該当バッファの中身をGPU内において 読み取り専用 で扱えるよう渡します。
後述するViewより制限があるもののコストが軽いため、読み取りで事が足りるならSRVを使用したほうが良いでしょう。
UnorderedAccessView (UAV)
CPUで作られたID3D11Bufferをもとにして作成し、該当バッファの中身をGPU内において 読み書き両方 で扱えるよう渡します。
SRVよりもコストが高いですが計算結果をコンピュートシェーダーから頂点シェーダーに渡すような場合はこちらを使用することになるでしょう。
CPUでの操作
ここまでで今回していく操作の流れをざっと図で表すと
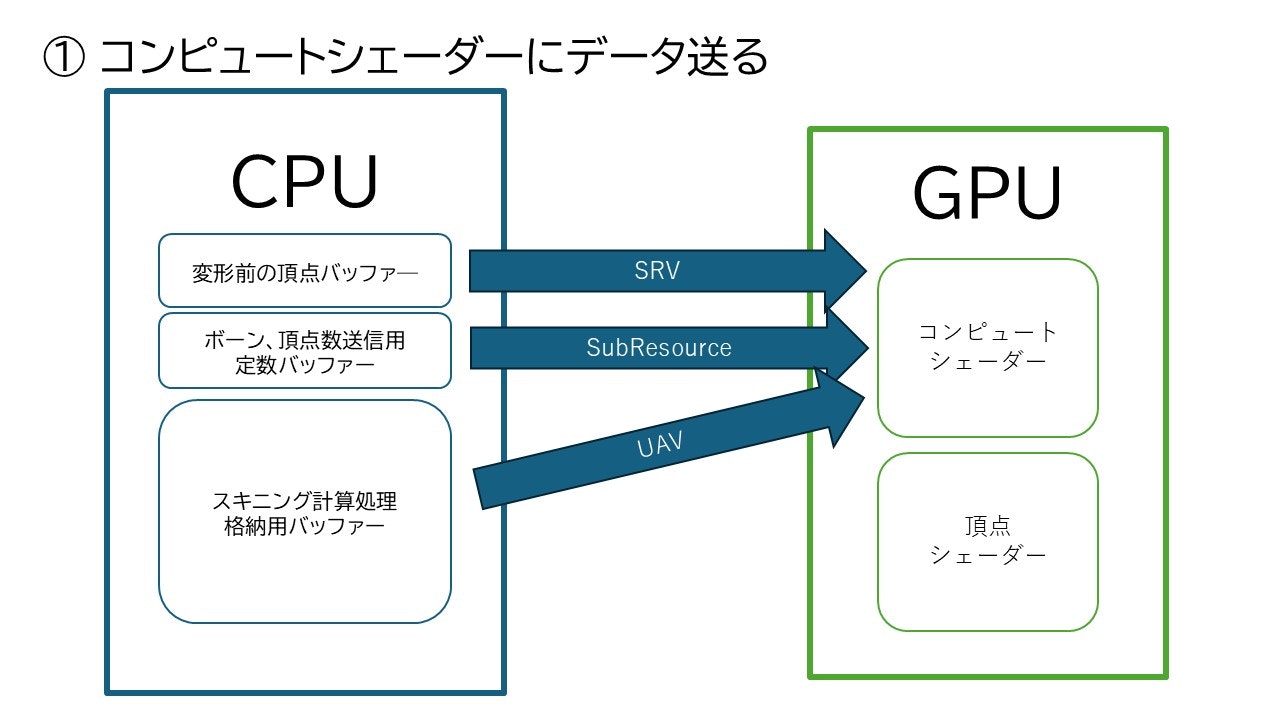
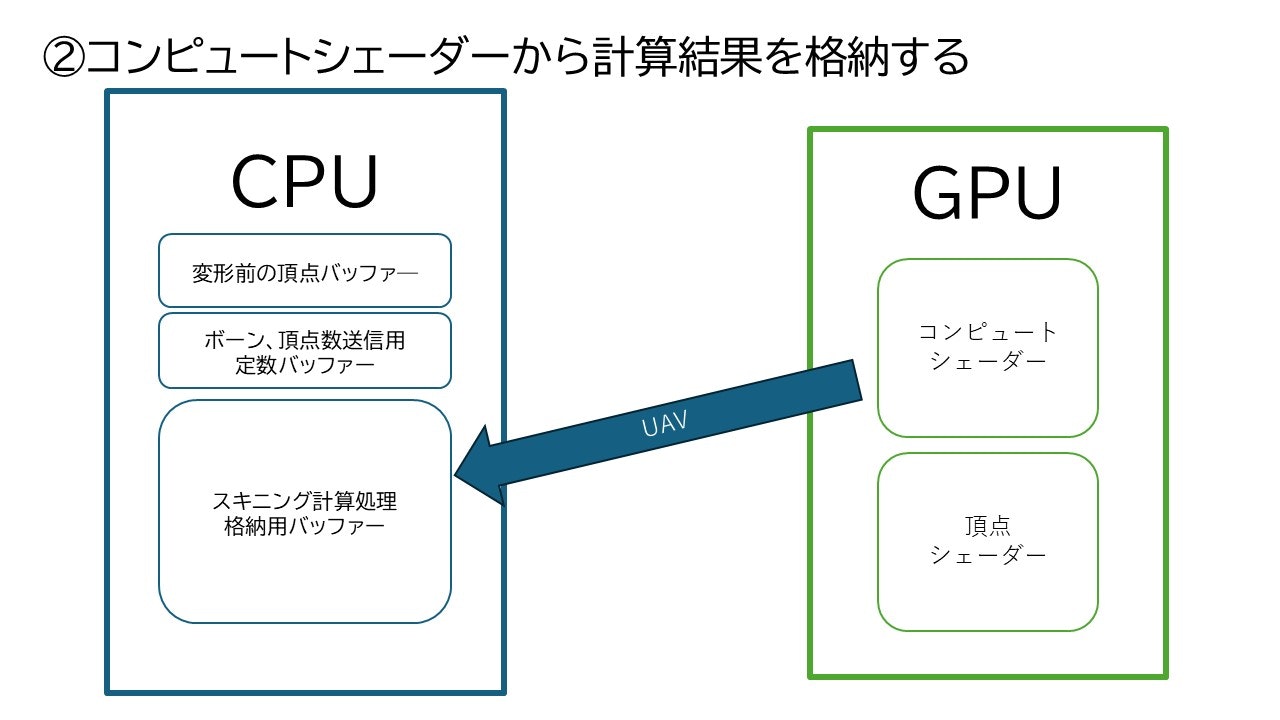
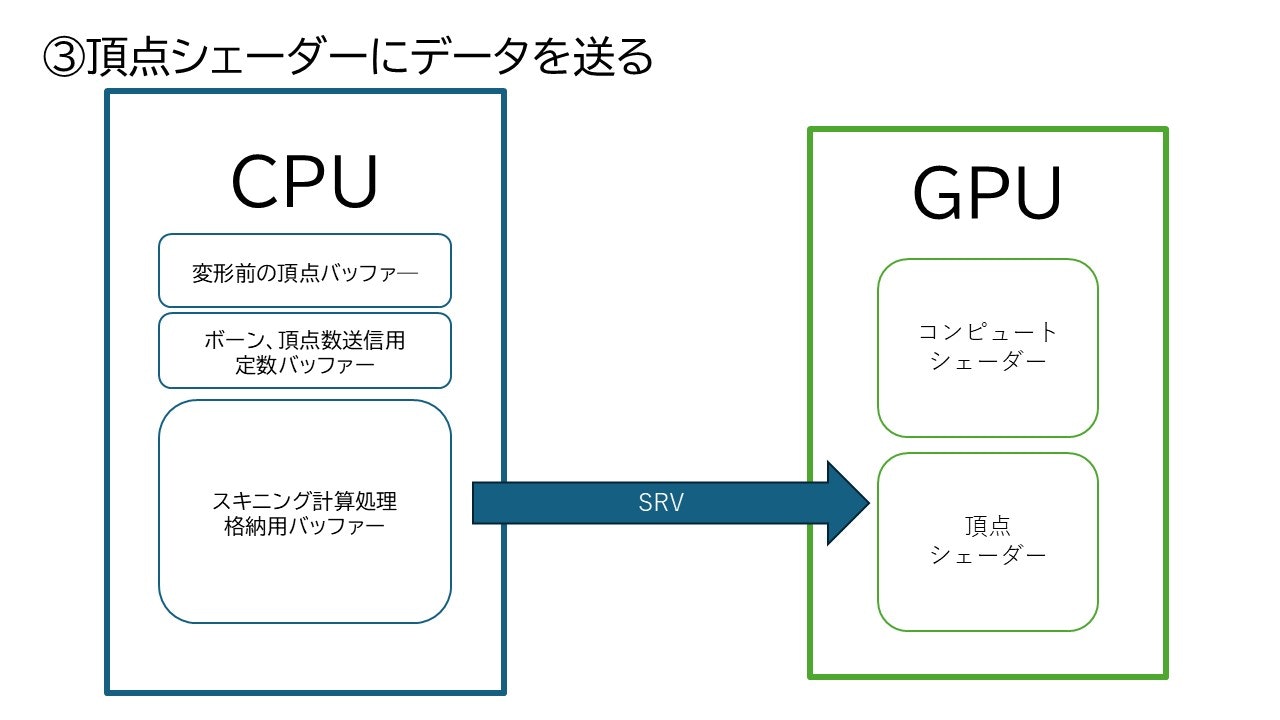
となります。
重要なのは一つのバッファーに対し二つのViewが作成されるということと、頂点シェーダーに対してスキニングが施された頂点のデータは頂点バッファとしてでなく、SRVを用いて通常のリソースとして渡すということです。
送信するためのコード
変形前の頂点情報格納バッファの作成
まずはコンピュートシェーダーに送る変形前の計算に用いられる頂点バッファを作りましょう。
中身はボーン情報も含めた頂点情報です。
/*
頂点読込したあと
*/
// バッファ作成
D3D11_BUFFER_DESC bd;
ZeroMemory(&bd, sizeof(bd));
bd.Usage = D3D11_USAGE_DEFAULT;
bd.ByteWidth = sizeof(/*頂点要素の型*/) * /*メッシュの頂点数*/;
bd.BindFlags = D3D11_BIND_SHADER_RESOURCE;
bd.CPUAccessFlags = 0;
bd.MiscFlags = D3D11_RESOURCE_MISC_BUFFER_STRUCTURED;
bd.StructureByteStride = sizeof(/*頂点要素の型*/) ; // 各要素のサイズを設定
D3D11_SUBRESOURCE_DATA sd;
ZeroMemory(&sd, sizeof(sd));
sd.pSysMem = notDeformVertex;
Renderer::GetInstance()->GetDevice()->CreateBuffer(&bd, &sd, ¬DeformVertexBuffer);
いつも通りの頂点バッファの作成と流れは変わりありませんが一部違う点があると思うので解説します。
bd.BindFlags = D3D11_BIND_SHADER_RESOURCE;
今回は頂点バッファ(VERTEX_BUFFER)として扱わず単純なリソースの一部として扱うので D3D11_BIND_SHADER_RESOURCE を設定します。
bd.CPUAccessFlags = 0;
頂点バッファの作成だとCPUでデータを弄る用にここを1とかにしてるかもしれませんが今回はGPUのみで計算しますのでCPUのアクセスは拒否するものとして0とします。
bd.MiscFlags = D3D11_RESOURCE_MISC_BUFFER_STRUCTURED;
bd.StructureByteStride = sizeof(/*頂点要素の型*/) ; // 各要素のサイズを設定
送信するデータが構造体の場合MiscFlagsはD3D11_RESOURCE_MISC_BUFFER_STRUCTUREDになります。
またこの場合一つの要素のサイズを入れる必要があります。
ここまででバッファの作成は完了しました。
次にこのバッファを用いてViewを作成します。
変形前頂点情報のView作成
// csで使われるsrvの作成
D3D11_SHADER_RESOURCE_VIEW_DESC notDeformSRVDesc;
ZeroMemory(¬DeformSRVDesc, sizeof(D3D11_SHADER_RESOURCE_VIEW_DESC));
notDeformSRVDesc.ViewDimension = D3D11_SRV_DIMENSION_BUFFER;
notDeformSRVDesc.Buffer.NumElements = /*頂点数*/;
notDeformSRVDesc.Buffer.FirstElement = 0;
notDeformSRVDesc.Format = DXGI_FORMAT_UNKNOWN;
ID3D11ShaderResourceView* notDeformVertexSRV;
Renderer::GetInstance()->GetDevice()->CreateShaderResourceView(notDeformVertexBuffer, ¬DeformSRVDesc, ¬DeformVertexSRV);
こちらも分けて解説していきます。
notDeformSRVDesc.ViewDimension = D3D11_SRV_DIMENSION_BUFFER;
リソースの種類を表すフラグです。構造体の場合はD3D11_SRV_DIMENSION_BUFFERを扱います。
notDeformSRVDesc.Buffer.NumElements = /*頂点数*/;
notDeformSRVDesc.Buffer.FirstElement = 0;
NumElementsはその名の通り要素数です。今回は頂点を送るので頂点数が入ります。また、FirstElementは配列のどこを始点とするかですが特殊な処理をしていないのであれば通常は0でよいと考えます。
notDeformSRVDesc.Format = DXGI_FORMAT_UNKNOWN;
リソースのデータの格納の種類を表すフラグです。テクスチャのようなRGBAがある一般で広く決まっているようなデータは用意されているフラグが使えますが自作の構造体の場合は当然違うのでUNKNOWNを指定します。
以降このnotDeformVertexSRVを用いてコンピュートシェーダーにデータを送信していきます。
計算後の頂点格納用バッファの作成
コンピュートシェーダー、頂点シェーダー共に使用していく計算後の頂点を格納していくバッファを作っていきます。
中身はボーン情報を含めない頂点情報です。
// バッファ作成
D3D11_BUFFER_DESC bd;
ZeroMemory(&bd, sizeof(bd));
bd.Usage = D3D11_USAGE_DEFAULT;
bd.ByteWidth = sizeof(/*頂点の要素の型*/) * mesh->mNumVertices;
bd.BindFlags = D3D11_BIND_UNORDERED_ACCESS | D3D11_BIND_SHADER_RESOURCE;
bd.CPUAccessFlags = 0;
bd.MiscFlags = D3D11_RESOURCE_MISC_BUFFER_STRUCTURED;
bd.StructureByteStride = sizeof(/*頂点要素の型*/); // 各要素のサイズを設定
D3D11_SUBRESOURCE_DATA sd;
ZeroMemory(&sd, sizeof(sd));
sd.pSysMem = vertex;
Renderer::GetInstance()->GetDevice()->CreateBuffer(&bd, &sd, &vertexBuffer);
先ほどの作成とさほど変わりがないですが特筆すべき点を解説します。
bd.BindFlags = D3D11_BIND_UNORDERED_ACCESS | D3D11_BIND_SHADER_RESOURCE;
バッファがどのように用いられるかを指定するフラグは『|』(OR)を用いて多数同時に指定することができます。今回の場合は計算を格納するので D3D11_BIND_UNORDERED_ACCESS (UAVで使用)と計算した値を頂点シェーダーで読み取るので D3D11_BIND_SHADER_RESOURCE (SRVで使用)の二つのフラグを指定します。
スキニング処理格納用UAVの作成
// csで書き出される用のUAV
D3D11_UNORDERED_ACCESS_VIEW_DESC uavDesc = {};
uavDesc.ViewDimension = D3D11_UAV_DIMENSION_BUFFER;
uavDesc.Format = DXGI_FORMAT_UNKNOWN;
uavDesc.Buffer.FirstElement = 0;
uavDesc.Buffer.NumElements = /*頂点数*/;
ID3D11UnorderedAccessView* vertexUAV;
HRESULT hr = Renderer::GetInstance()->GetDevice()->CreateUnorderedAccessView(vertexBuffer, &uavDesc, &vertexUAV);
descと本体の型が変わっただけで基本的にSRVと同じです。
以降はvertexUAVを用いてコンピュートシェーダからバッファーにスキニング処理の結果を書き込んでもらいます。
スキニング処理送信用SRVの作成
// vsで読み込まれるスキニング処理後を送るSRV
D3D11_SHADER_RESOURCE_VIEW_DESC updatedSrvDesc = {};
updatedSrvDesc.ViewDimension = D3D11_SRV_DIMENSION_BUFFER;
updatedSrvDesc.Buffer.FirstElement = 0;
updatedSrvDesc.Buffer.NumElements = mesh->mNumVertices;
updatedSrvDesc.Format = DXGI_FORMAT_UNKNOWN;
ID3D11ShaderResourceView* updatedSRV;
Renderer::GetInstance()->GetDevice()->CreateShaderResourceView(vertexBuffer, &updatedSrvDesc, &updatedSRV);
以降はupdatedSRVを用いてコンピュートシェーダから書き込まれた計算結果を頂点シェーダーに送ります。
ボーンデータ、頂点数 送信用定数バッファの作成
コンピュートシェーダー側ではAnimationBufferとして扱われる定数バッファを作成します。
// CSに渡す定数バッファの作成
D3D11_BUFFER_DESC bufferDesc = {};
bufferDesc.Usage = D3D11_USAGE_DEFAULT;
bufferDesc.BindFlags = D3D11_BIND_CONSTANT_BUFFER;
bufferDesc.CPUAccessFlags = 0;
bufferDesc.ByteWidth = sizeof(/*ボーンの情報と頂点数が格納できる構造体の型*/);
bufferDesc.StructureByteStride = 0;
bufferDesc.MiscFlags = 0;
Renderer::GetInstance()->GetDevice()->CreateBuffer(&bufferDesc, nullptr, &constantBuffer);
今までのバッファ作成とさほど変わりがないですね。
フラグの指定が定数用なっている点を気を付けるぐらいです。
以降はconstantBufferを用いてコンピュートシェーダーにボーンデータを送信します。
コンピュートシェーダーの実行
モデルの読込からバッファーの作成までは完了しましたので後は実際に計算をするだけです。
/*
ボーンアニメーションのマトリクス更新などが終わった後
/*
// GPUスキニングを行う (ComputeShaderに処理を委譲している)
Renderer::GetInstance()->GetDeviceContext()->CSSetShader(_skinCS, nullptr, 0);
// ComputeShaderへのデータ送信
Renderer::GetInstance()->GetDeviceContext()->CSSetConstantBuffers(0, 1, &constantBuffer);
Renderer::GetInstance()->GetDeviceContext()->CSSetShaderResources(0, 1, ¬DeformVertexSRV);
Renderer::GetInstance()->GetDeviceContext()->CSSetUnorderedAccessViews(0, 1, &vertexUAV, nullptr);
UINT numThreadGroup = (/*頂点数*/ + 255) / 256; // 256スレッドの何グループ必要か計算
Renderer::GetInstance()->GetDeviceContext()->Dispatch(numThreadGroup, 1, 1); // csの実行
// uavの再設定によるリソースバリア
ID3D11UnorderedAccessView* nulluav = nullptr;
Renderer::GetInstance()->GetDeviceContext()->CSSetUnorderedAccessViews(0, 1, &nulluav, nullptr);
まず、コンピュートシェーダーの設定からです。
Renderer::GetInstance()->GetDeviceContext()->CSSetShader(_skinCS, nullptr, 0);
頂点シェーダーやピクセルシェーダーと同じくCSSetShaderというセッターが用意されているためこれを使います。
// ComputeShaderへのデータ送信
Renderer::GetInstance()->GetDeviceContext()->CSSetConstantBuffers(0, 1, &constantBuffer);
Renderer::GetInstance()->GetDeviceContext()->CSSetShaderResources(0, 1, ¬DeformVertexSRV);
Renderer::GetInstance()->GetDeviceContext()->CSSetUnorderedAccessViews(0, 1, &vertexUAV, nullptr);
それぞれにデータが格納されているか(とくにconstantBuffer)を確認して設定していきます。ここもいつもと同じですね。VSやPSがCS(ComputeShader)になっているだけです。
UINT numThreadGroup = (/*頂点数*/ + 255) / 256; // 256スレッドの何グループ必要か計算
Renderer::GetInstance()->GetDeviceContext()->Dispatch(numThreadGroup, 1, 1); // csの実行
見慣れない記述が出てきました。これは前回のコンピュートシェーダーのスレッド数とスレッドグループの項で説明した点が関連します。
DeviceContextからDispatch関数を呼び出していますがこれはコンピュートシェーダーの実行を行う関数です。しかしnumThreadGroupという変数は一体なにを格納しているでしょうか。
コンピュートシェーダー上ではスレッドグループのスレッド数は
[numthreads(256, 1, 1)]
となっていました。
つまり、xに256回、yに1回、zに1回の256 * 1 * 1 = 256個でひとつのスレッドグループとなります。CPUではこのスレッドグループを何個呼び出すかを指定しなければなりません。
頂点数が仮に800としたとき、ひとつ256個のスレッドを持つスレッドグループは800 / 256で3.125個必要です。しかし、3.125個という値はスレッドグループの個数としては相応しくない値です。スレッドグループは整数で指定することしかできないため切り上げる必要がでてきます。
そのため元の頂点数800に対し1スレッドグループのスレッド数-1を足してやって計算すると
800 + 255 / 256となり4.1210...個となりUINTとして評価されるため4という計算結果となります。
ここで「あれ?スレッドグループ4つ分動かすと800頂点以上の処理が走ってコンピュートシェーダーが変な動きをするんじゃないか?」と疑問に思う方もいると思いますが一度コンピュートシェーダーを見てみるとこんな記述をしていたはずです。
if (index >= maxVertexCount)return;
頂点番号が範囲外を指したときに何もしないようif文を設けているためスレッドグループは切り上げでも問題ないですね。
上記コードでは頂点数は省いてますが皆さんのモデルに合わせた頂点数を入れ込んで実行してください。
さて、Dispatch関数の呼び出しで実行できたのであとは描画だけか、というと残念ながらもう一つ問題があります。それはGPUの計算が終わったかどうかの同期をとらなければならないという点です。
// uavの再設定によるリソースバリア
ID3D11UnorderedAccessView* nulluav = nullptr;
Renderer::GetInstance()->GetDeviceContext()->CSSetUnorderedAccessViews(0, 1, &nulluav, nullptr);
この個所は一見すると単なるnullのセットにしか見えないコードですがここで同期をとっているのです。
CPUが別のUAVを再設定しようとすると指定されたスロットをGPUがまだ計算に扱っている際処理がストップするという仕様を活かし同期をとっています。ここが非常に大事で実行環境によってはこれを書かなくても何も問題ない場合がありますが、他の実行環境ではなぜかエラーになってしまう。という非常にわかりづらいエラーを出してきます。(当然ですがエラー個所は全然違うところでなおわかりにくい!!)
描画
/*頂点シェーダーとピクセルシェーダーの設定ができているものとする*/
// ComputeShaderでのスキニング処理後の頂点設定
Renderer::GetInstance()->GetDeviceContext()->VSSetShaderResources(0, 1,&updatedSRV);
// 頂点バッファの設定
//Renderer::GetInstance()->GetDeviceContext()->IASetVertexBuffers(0, 1, nullptr, &stride, &offset); これは今回いらない...はず
// インデックスバッファ設定
Renderer::GetInstance()->GetDeviceContext()->IASetIndexBuffer(/*モデルに対応するインデックスバッファ*/, DXGI_FORMAT_R32_UINT, 0);
// ポリゴン描画
Renderer::GetInstance()->GetDeviceContext()->DrawIndexed(/*インデックスバッファの総数*/, 0, 0);
特筆すべきは
// ComputeShaderでのスキニング処理後の頂点設定
Renderer::GetInstance()->GetDeviceContext()->VSSetShaderResources(0, 1,&updatedSRV);
// 頂点バッファの設定
//Renderer::GetInstance()->GetDeviceContext()->IASetVertexBuffers(0, 1, nullptr, &stride, &offset); これは今回いらない...はず
この部分でしょう。
SetShaderResources関数でSRVを設定しています。コメントの通りupdatedSRVはコンピュートシェーダーで計算されたスキニングを施された頂点が入っているはず(同期も取れてる)ですので頂点シェーダーはこれを用いて描画を行います。
SRVを用いて描画を行うということは頂点バッファでの描画は行わないため頂点バッファの設定は今回いらないはずなのでコメントアウトしています。(確証を得られていないので間違っていたら申し訳ありませんが教えていただけると幸いです)
頂点情報の設定が済んだのであとはいつも通りインデックスバッファを設定し描画コールを呼ぶだけ。
おわり
この記事が誰かの手助けになれば幸いです。