はじめに
最近流行り?のWebスクレイピングってやつをやってみたくなったので、GASで自作してみました。
js,GAS共に軽く触ったことがある程度の初心者なので、効率的でないやり方や誤った内容が含まれているかもしれません。
今回の要件は以下3つ。
- 検知先Webページ・抽出条件などは Googleスプレッドシートで管理 (気軽に検知対象を増減させたい)
- 更新検知は 1日数回 とし、何時何分にチェックさせるかもシートで管理させる
- 検知したら Webhook を投げる (今回はDiscordのテキストチャンネルに投稿)
スクレイピング頻度について
軽く調べたのですがどの程度なら問題ないのかよくわからなかったんですよね。
チェック先のHPに過度な負荷をかけるのは本意では無いですし、自分の使用用途的に毎日決まった時間だけチェックすれば十分だったので
今回は 1日数回 程度チェックさせるようなプログラムとしました。
GASの最低起動間隔は 1分に1回 ですが、その程度なら問題無いといった記事も見かけたので過度な心配なのかもしれません。
作ってみる
下準備 : DiscordのWebhook作成
サーバー設定 > アプリ > 連携サービス から、Webhookを発行しておきます。
ここで記載する名前やアイコンは実際に使うことは無いのでわかればOKです。

スプレッドシート
今回は以下のような列を用意しました。
last_checked以降はGASで使用する列なので自分では入れません。
| 列名 | 用途 |
|---|---|
| name | 記事名・Discordに投稿するbotのユーザー名 |
| avatar_url | Discordに投稿するbotのアイコン |
| article_url | 記事の取得先URL |
| check_time | 毎日何時何分に更新チェックを行うか (例)12:00,12:01,12:02,12:30 |
| extract_from | 記事全体をどこから抽出するか |
| extract_to | 記事全体をどこまで抽出するか |
| article_from | 各記事をどこから抽出するか |
| article_to | 各記事をどこまで抽出するか |
| title_from | 記事タイトルをどこから抽出するか |
| title_to | 記事タイトルをどこまで抽出するか |
| link_from | 記事リンクをどこから抽出するか |
| link_to | 記事リンクをどこまで抽出するか |
| last_checked | 最終チェック日時 |
| last_updated | 最終記事更新日時 |
| last_title | 最新記事タイトル |
| last_link | 最新記事リンク |
Apps Script作成
以下3ファイルに分けて作成しました。
- checkWebUpdate.gs : メイン処理
- 処理内容は基本的にコメントに記載している通りです。
- 実行時間が
check_time列でカンマ区切りで指定された時分と一致する記事のみ更新チェックするような処理にしています。 - シートの情報取得・書き込みについては、列番号を直接指定したくなかったので列名キーの連想配列として処理しています。
- シートの情報取得はこちらの記事を参考にさせていただきましたが、今回のプログラム作成の中で一番の知見でした。スマートですごい。
/**
* Webページの更新チェック
*/
function checkWebUpdate() {
// スクリプト実行日時を取得
const now = new Date();
const currentDateTime = now.toLocaleString("ja-JP");
// 実行時間確認用に実行時間を取得(分は0埋め)
const padZero = (value, length) => (Array(length).join('0') + value).slice(-length);
const currentTime = `${now.getHours()}:${padZero(now.getMinutes(), 2)}`;
// シート記載内容取り込み
const sheet = SpreadsheetApp.getActiveSheet();
const sheetValues = sheet.getDataRange().getDisplayValues();
// 1行目をheaders(配列)に、2行目以降をrecords(2次元配列)に代入
const [headers, ...records] = sheetValues;
// records(2次元配列)をtargets(連想配列の配列)に代入し直す
const targets = records.map(
record => Object.fromEntries(
record.map((value, i) => [headers[i], value])
)
);
// 1行(URL先1件)ずつ処理
for (const target of targets) {
// 実行時間確認
const checkTimes = String(target.check_time).split(",");
// 今が実行対象時間でなければこのURL先の記事チェックは行わない
if (!checkTimes.find(time => time === currentTime)) {
continue;
}
// 記事チェック
const newArticles = getArticles(target);
// 最新チェック日を記録
target.last_checked = currentDateTime;
// 新しい記事があった場合
if (newArticles.length) {
// 最新更新日時・最新記事タイトル・リンクを記録(最新記事が上にある前提)
target.last_updated = currentDateTime;
target.last_title = newArticles[0].title;
target.last_link = newArticles[0].link;
// 記事1件ずつDiscordに投稿(古い記事から投稿するために逆順)
for (const article of newArticles.reverse()) {
let message = article.title + "\n" + article.link;
postDiscord(target.name, target.avatar_url, message);
}
}
}
// シート書き出し用にシートの行番号・列番号の連想配列を作成
const rowNumbers = Object.fromEntries(targets.map((target, i) => [target.name, i]));
const columnNumbers = Object.fromEntries(headers.map((value, i) => [value, i]));
// records配列に最新チェック日・最新更新内容などを更新
for (const target of targets) {
records[rowNumbers[target.name]][columnNumbers["last_checked"]] = target.last_checked;
records[rowNumbers[target.name]][columnNumbers["last_updated"]] = target.last_updated;
records[rowNumbers[target.name]][columnNumbers["last_title"]] = target.last_title;
records[rowNumbers[target.name]][columnNumbers["last_link"]] = target.last_link;
}
// records配列をシートに書き出す
sheet.getRange(2, 1, records.length, headers.length).setValues(records);
}
- getArticles.gs : シートの記載内容を元に、記事の各情報を取得
- シートの記載内容を
targetに詰めて呼び出します。 - データ抽出にはGASで使用できる
Parserライブラリを使用しているため、ライブラリの参照設定が必要です。 - XMLを取得した後の処理は以下のような流れとしています。
- 取得したXMLから
extract_fromからextract_toの間のみを残す -
article_fromからarticle_toの間を1記事として、XMLを分割する -
title_fromからtitle_toの間を記事名、link_fromからlink_toの間をリンクとして取得 - 記事名と
last_title・リンクとlast_linkを比較し、両方一致していたら処理終了
- 取得したXMLから
- シートの記載内容を
/**
* Webページから記事を取得する
*/
function getArticles(target) {
// URL先XMLを取得
const response = UrlFetchApp.fetch(target.article_url);
if (response.getResponseCode() !== 200) {
throw new Error(`${target.name}: Webページの取得に失敗しました。ResponseCode: ${response.getResponseCode()}`);
}
let xml = response.getContentText();
// 取得先がRSSの場合、抽出条件をソースで指定
if (target.article_url.slice(-3) === "rss" || target.article_url.slice(-3) === "xml") {
target = setRssExtractCondition(target);
}
// 絞り込み指定がされていたら絞り込む
if (target.extract_from !== "" && target.extract_to !== "") {
xml = Parser.data(xml).from(target.extract_from).to(target.extract_to).build();
}
// 各記事を取得(最新記事が上にある前提)
const articles = Parser.data(xml).from(target.article_from).to(target.article_to).iterate();
const newArticles = [];
for (const article of articles) {
// 記事名とリンクを取得
const title = Parser.data(article).from(target.title_from).to(target.title_to).build().trim();
const link = Parser.data(article).from(target.link_from).to(target.link_to).build().trim();
// 前回実行時の最新記事と同じ場合、以降は最新記事ではないため処理終了
if (title === target.last_title && link === target.last_link) {
break;
};
// アップデート内容を格納
newArticles.push({title: title, link: link});
}
return newArticles;
}
/**
* RSSの抽出条件指定
*/
function setRssExtractCondition(target) {
target.extract_from = "<channel>"
target.extract_to = "</channel>"
target.article_from = "<item>"
target.article_to = "</item>"
target.title_from = "<title>"
target.title_to = "</title>"
target.link_from = "<link>"
target.link_to = "</link>"
return target;
}
ParserライブラリのTips
-
iterate()で該当する範囲を全て抽出、build()で該当する条件のうち最初1件のみを抽出します。 -
from()、to()の中身はHTMLタグでなくともOKです。
ただし、ここで指定したものは抽出結果に残りません 。
また、to()の抽出はfrom()の指定内容より後で 初めて引っかかった部分 までです。
例えば以下のようなHTMLに対し、
<div>
<div>
test
</div>
</div>
以下のように抽出したとします。
Parser.data(foo)from("<div>").to("/<div>").iterate();
すると、抽出結果は以下のようになります。
<div>
test
つまり「XMLを上から見た時に最初の<div>から最初の</div>までが抽出される」+「from・toで指定したdivタグは残っていない」ということです。
そのあたりを踏まえ、なるべく一意に抽出できるように条件設定しましょう。
- postDiscord.gs : Discordに投稿する
- DiscordのWebhookでは、メッセージごとに名前・アイコンが変更出来ます。
-
nameがDiscord上のbotの名前、avatar_urlがbotのアイコンのURL、messageが投稿内容になります。
/**
* Discordに投稿
*/
function postDiscord(name, avatar_url, message) {
// DiscordのWebhookURL
const webhookURL = "※ここに発行したWebhookのURLを記載";
// jsonをPOST
const param = {
"method": "POST",
"headers": { 'Content-Type': "application/json" },
"payload": JSON.stringify({
"username": name,
"avatar_url": avatar_url,
"content": message
})
};
UrlFetchApp.fetch(webhookURL, param);
}
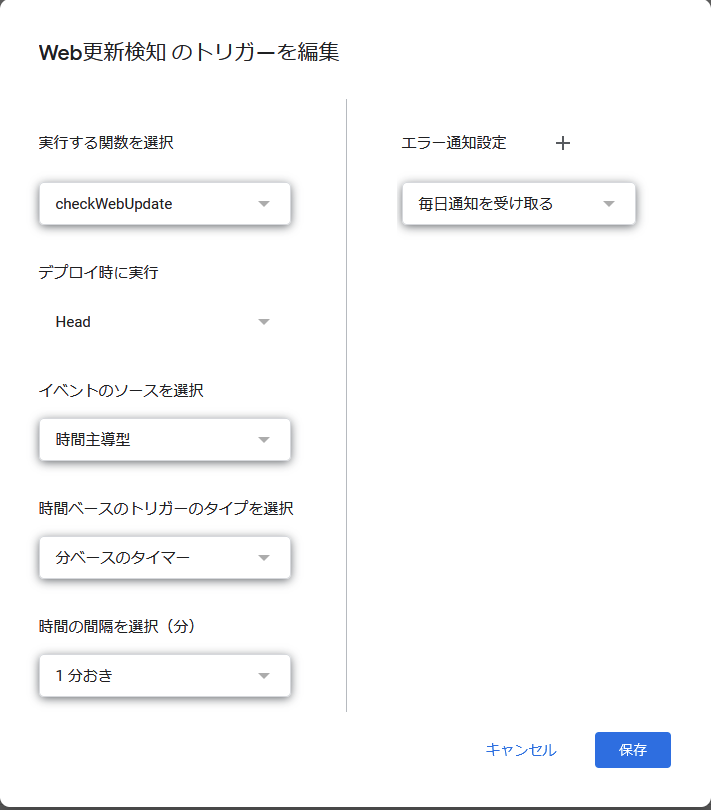
トリガー設定
Apps ScriptからcheckWebUpdateを1分おきに呼び出すようトリガー設定します。
動作確認
こんな感じでDiscordに投稿されます。
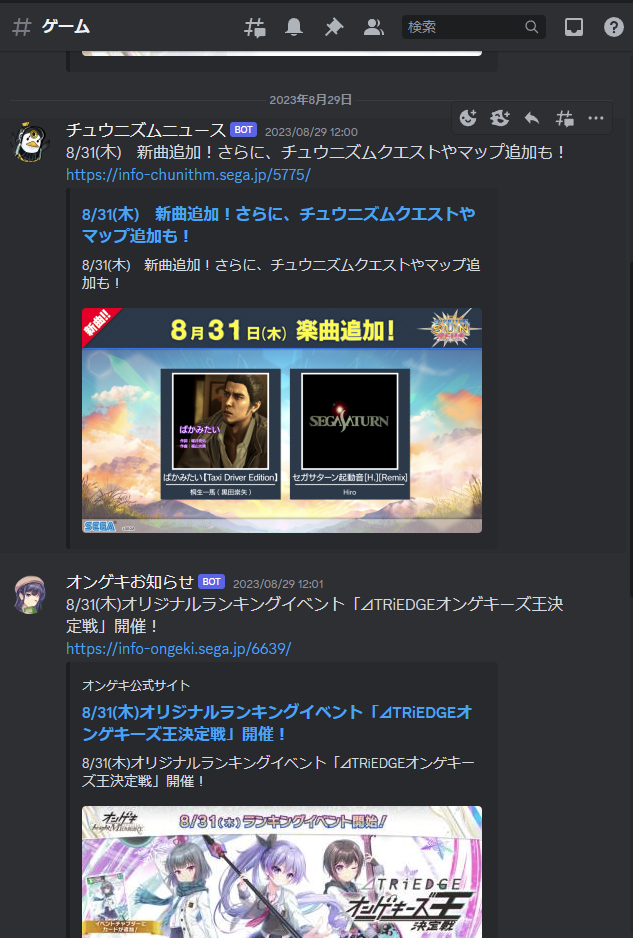
DiscordだとURLを投稿しただけで記事内容を埋め込んでくれるので便利ですね。
おわりに
GASとParserライブラリのパワーのおかげで大して苦労せずに作れました。
エラーハンドリングを充実させたり、WebhookはDiscordのチャンネルごとに分かれているのでシート側で指定できるようにしたり、改良の余地はまだまだありそうですね。
これで某SNSに頼らずに効率的に情報収集できそうです。