この記事はKafka Advent Calendar 2021の3日目の記事です。
Kafka Streams でステートフルなアプリケーションを開発する際、Kafka 外のデータストアを使ってしまうと Kafka Streams が持つフォールトトレランスや処理の保証などの機能を活かし切れず、競合状態やリトライなど注意点が多く発生します。Kafka 自体をデータストアとすることで、Kafka Streams の利点を活かせるアプリケーションのパターンを紹介します。
Kafka Streams
Kafka Streams とは Kafka のクライアントとコンシューマを利用し、Kafka トピック上を流れるデータに対するトポロジー(結合、変換など)を定義し、ストリーム処理が出来るライブラリです。
あるトピックにメッセージが配信されたらそのメッセージを処理し、結果を別のトピックに配信する、というようなアプリケーションを開発出来ます。
KStream と KTable
Kafka トピック上を流れるデータはキーと値の組み合わせですが、それには二つの意味付けが可能です。キーをあるエンティティの ID とすると、
- Changelog stream ... 値はそのエンティティ自体の最新値
- Record stream ... 値はエンティティに対する何らかのイベント
そして Kafka Streams でこれらを抽象化したものがそれぞれ Changelog stream -> KTable と Record stream -> KStream です。Kafka Stream では KTable と KStream をトポロジーの入力として使うことが出来ます。ストリーム処理は一つ以上の KStream から始まります。KTable はストリーム処理の始点にはなりませんが KStream に結合することでトポロジー内でエンティティのスナップショットを提供します。
KTable による状態管理
上述の通り Kafka Streams で状態を扱う一番基本的な方法は KTable です。トポロジー内で KTable からエンティティのスナップショットを取得し、計算した新状態を KTable のトピックに再び配信することでそのエンティティを更新していくことが出来ます。
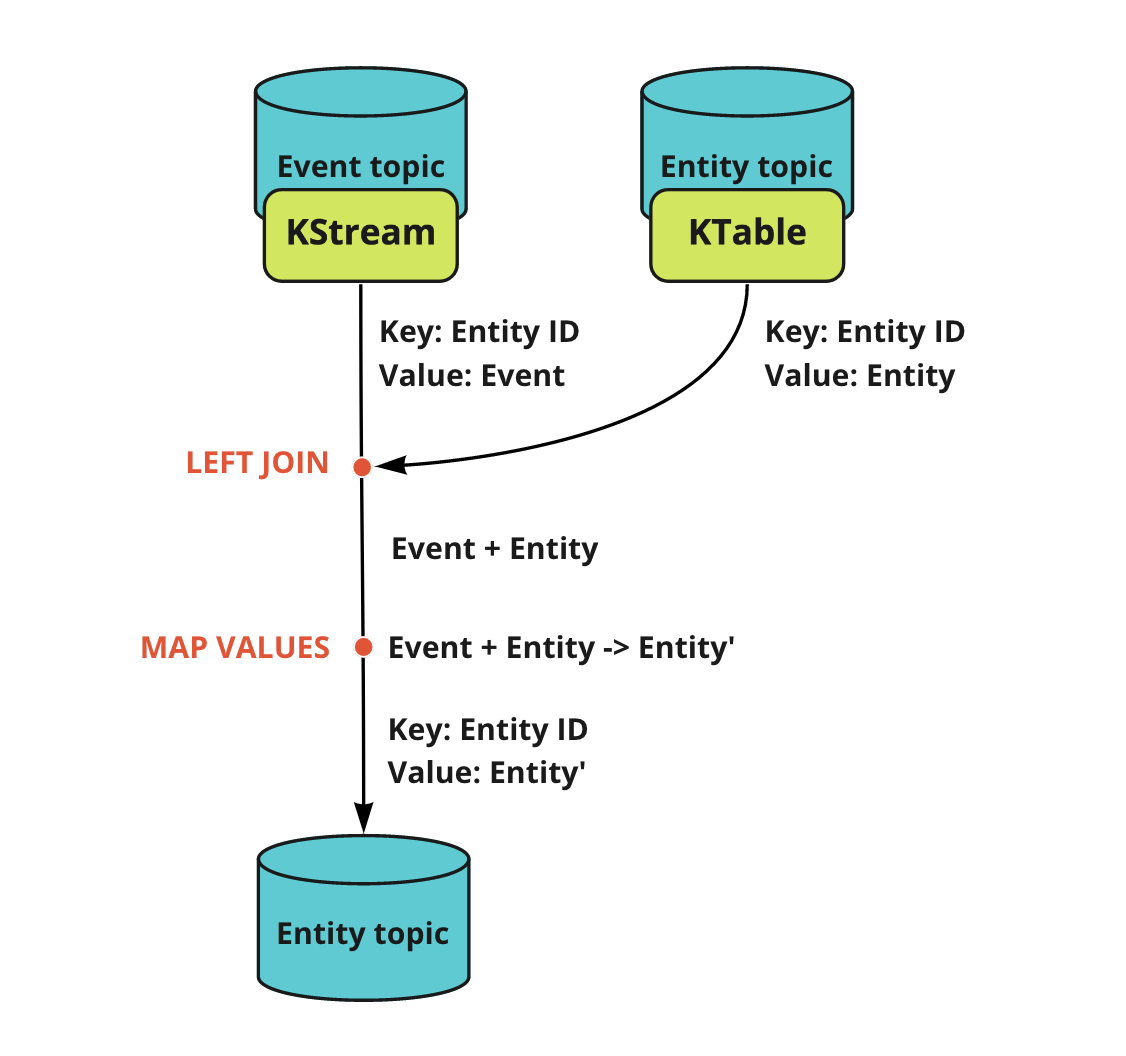
- Event topic ... Record stream のソーストピック。エンティティに対するイベントメッセージが配信される。
- Entity topic ... changelog stream のソーストピック。エンティティのスナップショットを配信する。
- Event topic にエンティティの更新を伴うイベントメッセージが配信される。ここでメッセージのキーは Entity ID。
- Event topic をソースとする KStream からストリーム処理を開始。
- Entity topic をソースとする KTable を LEFT JOIN し、Entity topic 上の同一キーを持つ最新(厳密には少し違う※後述)のスナップショットを結合する。
- エンティティの値とイベントを基に新しいエンティティに変換(MAP VALUES)
- 最新のエンティティを Entity トピックに配信
このパターンなら状態更新のトランザクション管理を Kafka Streams に委ねることが出来、リトライやデータ復旧なども簡単に行うことが出来ます。
KTable による状態管理の問題
しかし上記のトポロジーには一つ問題があります。問題は Event トピック上で同一エンティティに対するイベントが複数同時に入力された場合に、上記ステップ3で起こります。Kafka Streams の LEFT JOIN の挙動として最新のスナップショットが結合されると述べましたが、厳密には LEFT JOIN はインプットメッセージのレコードタイムスタンプに基づき行われます。つまり、KTable から結合されるのは Event トピックメッセージのタイムスタンプから見て最近過去のスナップショットです。Kafka Streams は同一キーメッセージに対しては順次処理を行いますが、レコードタイムスタンプはあくまでそのメッセージが配信された時間となります。そのため Event トピックに一つ目のイベントが配信され、Kafka Streams がその処理を終える前に次のイベントが配信されてしまうと、二つ目のイベントのレコードタイムスタンプが最新スナップショットより過去になってしまうため、一つ前のスナップショットが結合されてしまうのです。そのため二つ目のイベントの処理時に LEFT JOIN で一つ古いスナップショットが結合されてしまい、競合状態を引き起こします。
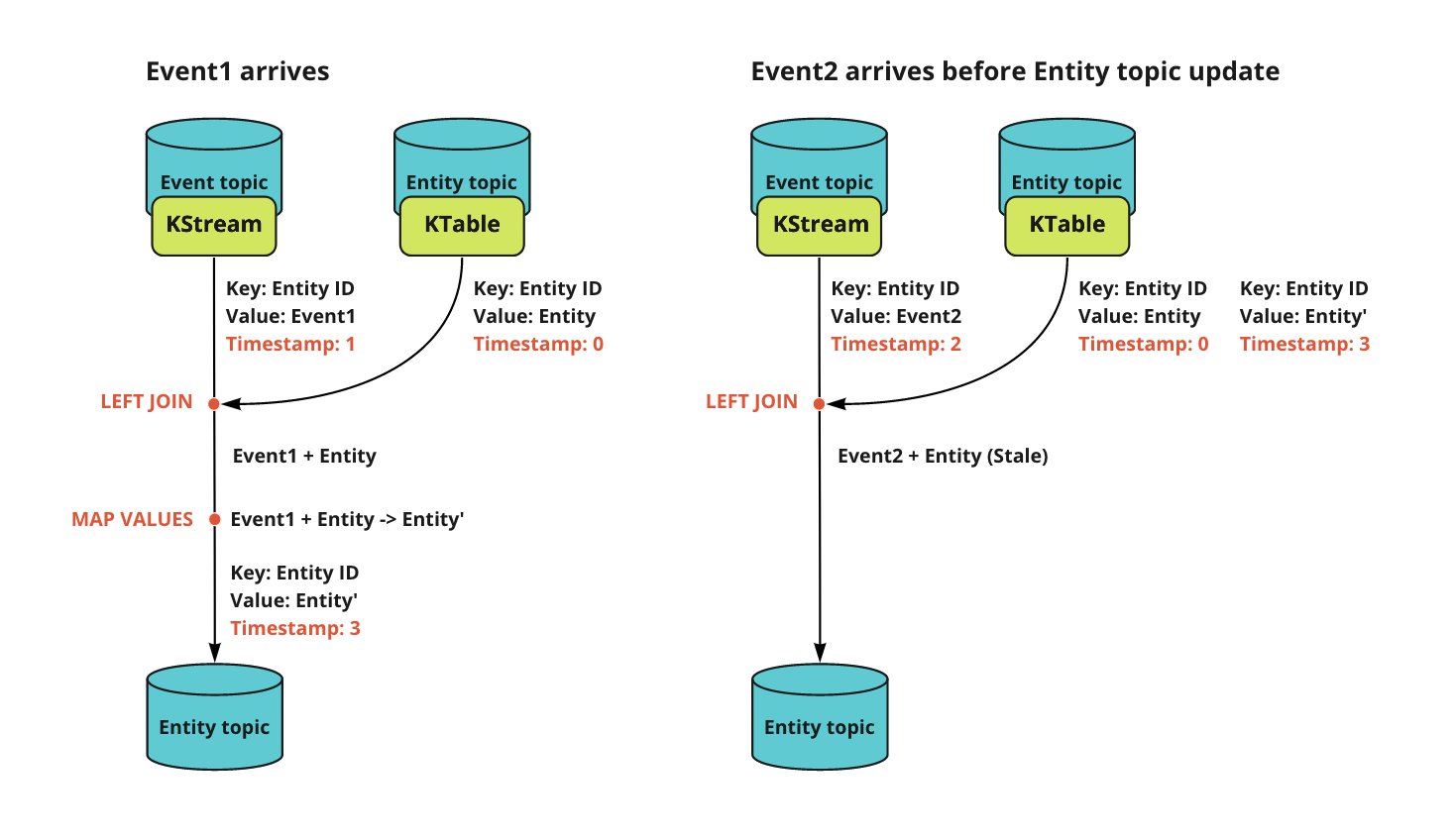
この LEFT JOIN の挙動はリトライ時の処理を決定論的にするため正しいものですが、KTable で状態管理するための障害となります。
解決策としては Kafka Streams にてレコードタイムスタンプを決定する関数(timestamp.extractor)を常に最新のタイムスタンプを返すように差し替えることも出来ますが、影響が大きいためあまりやりたくありません。
https://docs.confluent.io/platform/current/streams/developer-guide/config-streams.html#streams-developer-guide-timestamp-extractor
そこで Kafka(Kafka Streams) 内で完結する解決方法として、StateStore を利用します。
KTable, StateStore による状態管理
StateStore は Kafka Streams の実プロセスである Stream Processor におけるストレージエンジンです。いくつか実装がありますが、最も単純にキーバリューストア(KeyValueStore)を利用すれば、値の即時読み書きが可能なので、問題の競合状態に対する回避策として利用できます。仮に二つ目のイベントがストリーム処理が完了する前に発生しても、同一キーに対するストリーム処理は順次行われるため、二つ目のイベントの処理開始時には既に StateStore に最新スナップショットが存在するため、それを使えば競合状態を回避出来ます。
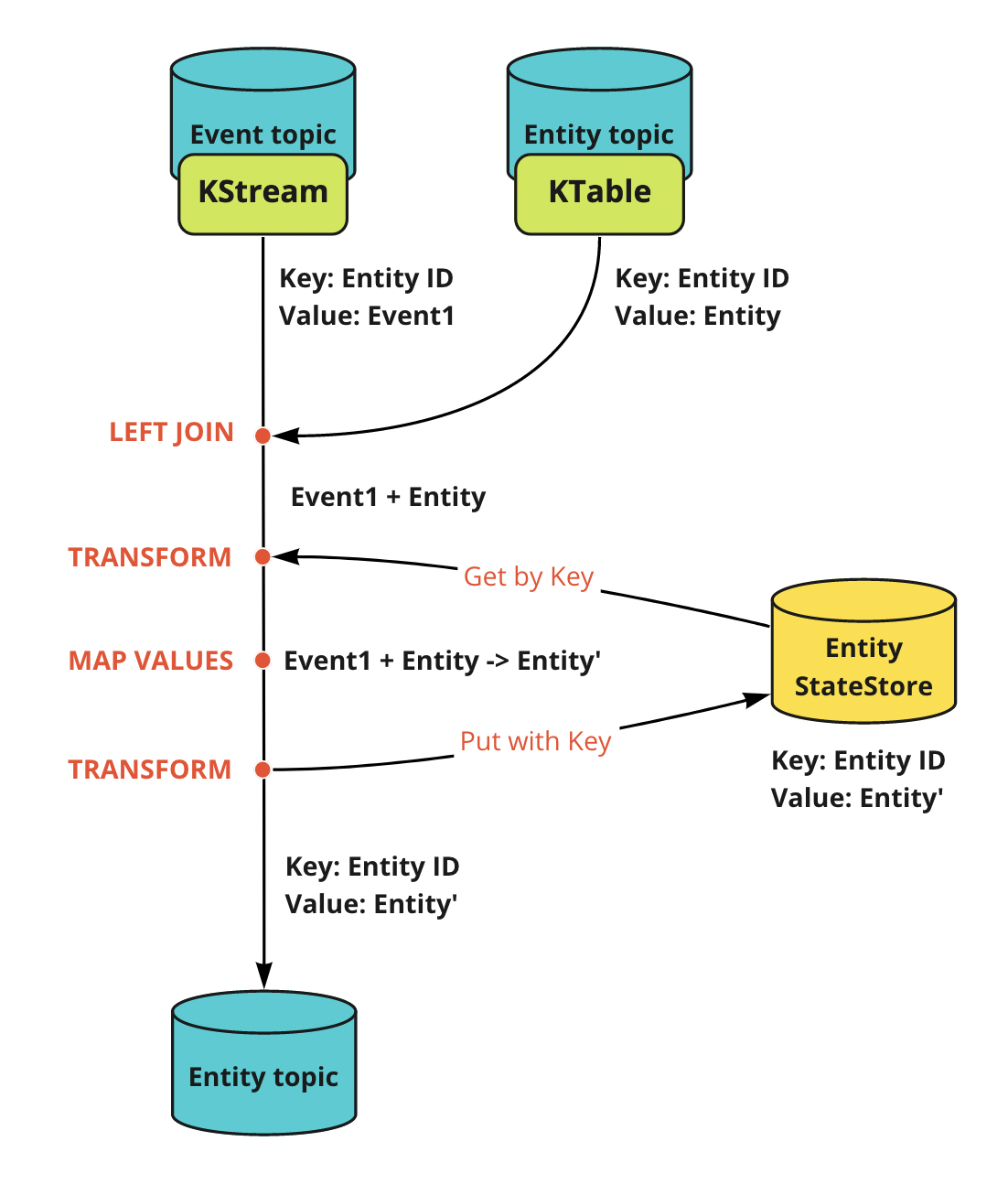
この場合、KTable は必要なのかという疑問がありますが、StateStore は各 Stream Processor の内部ストレージであるため、別のトポロジーからの読み出しが出来ません。そのため StateStore はあくまでも競合状態を回避するためだけの一時状態のためだけに使い、実際のストレージは KTable のソーストピックと考えましょう。
ただし、StateStore 自体も Stream Processor が内部トピックを作成してデータを Changelog stream として配信することでバックアップされており、Stream Processor の再起動時には自動でデータが復元されます。
Clojure で書いてみる
別記事に書きます。
まとめ
Kafka Streams で状態を持つアプリケーションを作るパターンと起こり得る競合状態、その解決方法について書きました。特段珍しいユースケースではないとは思うのですが、なかなか問題とその解決方法が面倒だったので、よりよい解決方法があれば教えて下さい。