概要
- FolkとElectronicのジャンルで各500曲を用意
- メル周波数ケプストラム係数 (MFCC) を使って学習モデルを作成
- Kerasを使って学習・判定
- 交差検証を行い、二値分類で精度は約85%程度
データの準備
フリーで音楽データを利用可能なFMA (Free Music Archive) というサービスがあります。
このFMAからさらに、8ジャンル x 1000曲を抽出したfma_smallというデータセットがあります。
このfma_smallから、違いが分かりやすいと思われる2ジャンル Folk と Electronic の楽曲をそれぞれ500曲選択し実験に使いました。
1曲の長さは全て30秒となっています。
モデルの作成
モデルにはメル周波数ケプストラム係数 (MFCC) を用います。
MFCCについてはこちらが詳しく書かれています。
MFCCへの変換にはlibrosaを用いました。
特徴的なFolkとElectronicの曲のMFCCを可視化すると下図のようになります。
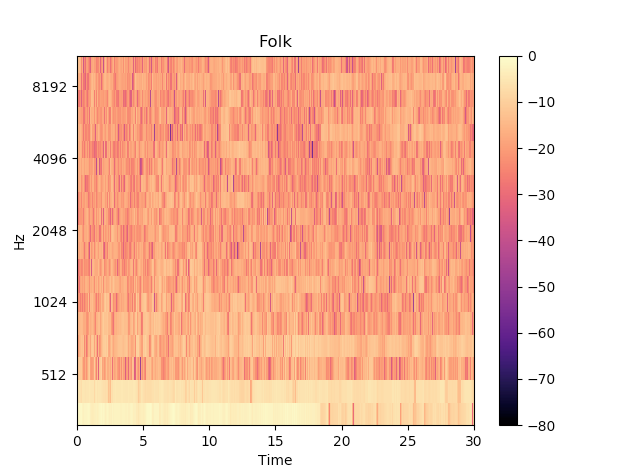
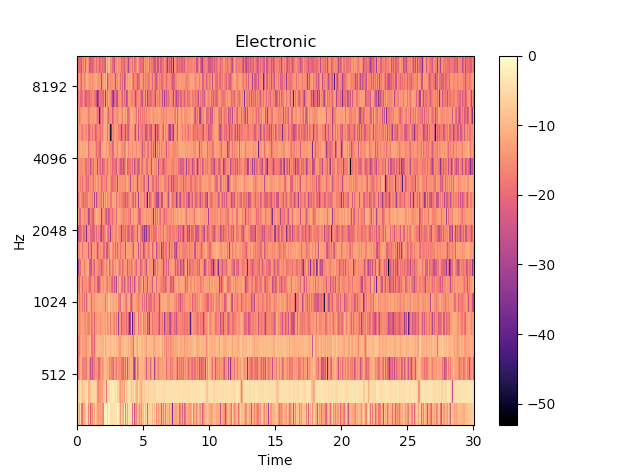
なんとなく違いがあるように思えます。
このままモデルとしても今回の実験ではうまくいかなかったため、縦軸の音の高さ毎に平均を取り1次元の配列にし、それをモデルとしました。
なので、今回のモデルには時間軸の要素はないことになります。
具体的には以下のプログラムでモデルを作成しました。
import os
import librosa
import numpy as np
def load(dir_path, label):
n_mfcc = 20
genre_x = np.zeros((0, n_mfcc))
genre_y = np.zeros((0, 1), dtype='int')
files = os.listdir(dir_path)
for i, file in enumerate(files):
file_path = dir_path + file
y, sr = librosa.load(file_path)
mfcc = librosa.feature.mfcc(y=y, sr=sr, n_mfcc=n_mfcc)
mean = np.mean(mfcc, axis = 1)
genre_x = np.vstack((genre_x, mean))
genre_y = np.vstack((genre_y, label))
print(f'{i+1}/{len(files)} loaded: {file_path}')
return genre_x, genre_y
if __name__ == '__main__':
folk_x, folk_y = load('Folkのディレクトリパス', 0)
electronic_x, electronic_y = load('Electronicのディレクトリパス', 1)
X = np.r_[folk_x, electronic_x]
Y = np.r_[folk_y, electronic_y]
np.save('x.npy', X)
np.save('y.npy', Y)
結果をx.npyとy.npyとしてそれぞれファイル保存しています。
学習と評価
前節で作成したモデルを用いて交差検証を行います。
import numpy as np
from keras.models import Sequential
from keras.layers import Dense, Dropout
from sklearn.model_selection import train_test_split
x = np.load('x.npy')
y = np.load('y.npy')
x_train, x_test, y_train, y_test = train_test_split(x, y, train_size=0.8)
model = Sequential()
model.add(Dense(256, activation='relu', input_shape=(20,)))
model.add(Dropout(0.25))
model.add(Dense(256, activation='relu'))
model.add(Dropout(0.25))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=500, batch_size=128)
score = model.evaluate(x_test, y_test, batch_size=128)
print(f'loss: {score[0]}, accuracy: {score[1]}')
librosaのMFCC変換時の係数の次元がデフォルトで20だったので、入力の次元も20となっています。
結果
学習結果
Epoch 1/500
800/800 [==============================] - 0s 358us/step - loss: 5.3203 - acc: 0.5800
Epoch 2/500
800/800 [==============================] - 0s 35us/step - loss: 3.2174 - acc: 0.6875
...
Epoch 499/500
800/800 [==============================] - 0s 29us/step - loss: 0.0370 - acc: 0.9900
Epoch 500/500
800/800 [==============================] - 0s 30us/step - loss: 0.0067 - acc: 0.9975
学習がうまくいったことが分かります。
評価結果
200/200 [==============================] - 0s 106us/step
loss: 0.8637916135787964, accuracy: 0.8850000071525573
何回か試してみましたが、今回の実験では概ね85%前後となりました。
まとめ
FMAの音楽データを使ってジャンル分類をしました。
結果は二値分類で85%となりましたが、MFCC変換の調整や学習のさせ方次第で、もっと精度が出るような気がします。
今回は2ジャンルでの実験だったので、もっとジャンルを増やしてやってみたいですね。