これはなに
NoSQLとPaaSでナレッジベース+WebAPIを構築した際のノウハウのまとめです。
文字列タグ指向無向グラフ型ナレッジベース というアーキテクチャを実装する場合に、
Heroku + Redis + FastAPI で構築した例と、
AWS(DynamoDB + Lambda + API Gateway) で構築した例を紹介します。
コード部分は全て Python3.8.0 を使用しています。
※ 現在AWS編が未完成です。ごめんなさい。
ナレッジベースとは?
ナレッジベースには様々な定義がありますが、この記事では
「知識をコンピュータが読み取り可能な形式で格納したデータベース」を指します。
知識ベース ナレッジデータベース KB などの呼ばれ方もあります。
参考リンク(クリックで開く)
文字列タグ指向無向グラフ型ナレッジベース
今回例として構築するナレッジベースです。
名前だけでは分かりにくいと思うので、イメージ図を用意しました。
(可視化は未実装のためマインドマップツール coggle で作成)

このナレッジベースの役割
「2つの文字列を格納する」という単純な操作の繰り返しだけで、
辞書的な知識体系(集合知)を形成することです。
そして爆速で育て上げるためにWebAPIが必要になります。
「文字列タグ指向」について
このナレッジベースでは文字列(とその集合)データのみを扱い、
全ての文字列をタグとして扱います。
上の図の例では、
Webサービス名 アカウントID URL 記事タイトル 概念 プログラミング言語
などの各文字列を1つのタグとして扱っています。
仕様上、文字列には空白や改行文字などは含まないものとします。
「無向グラフ型」について
このナレッジベースでは、関係のあるタグを結び付けるようにします。
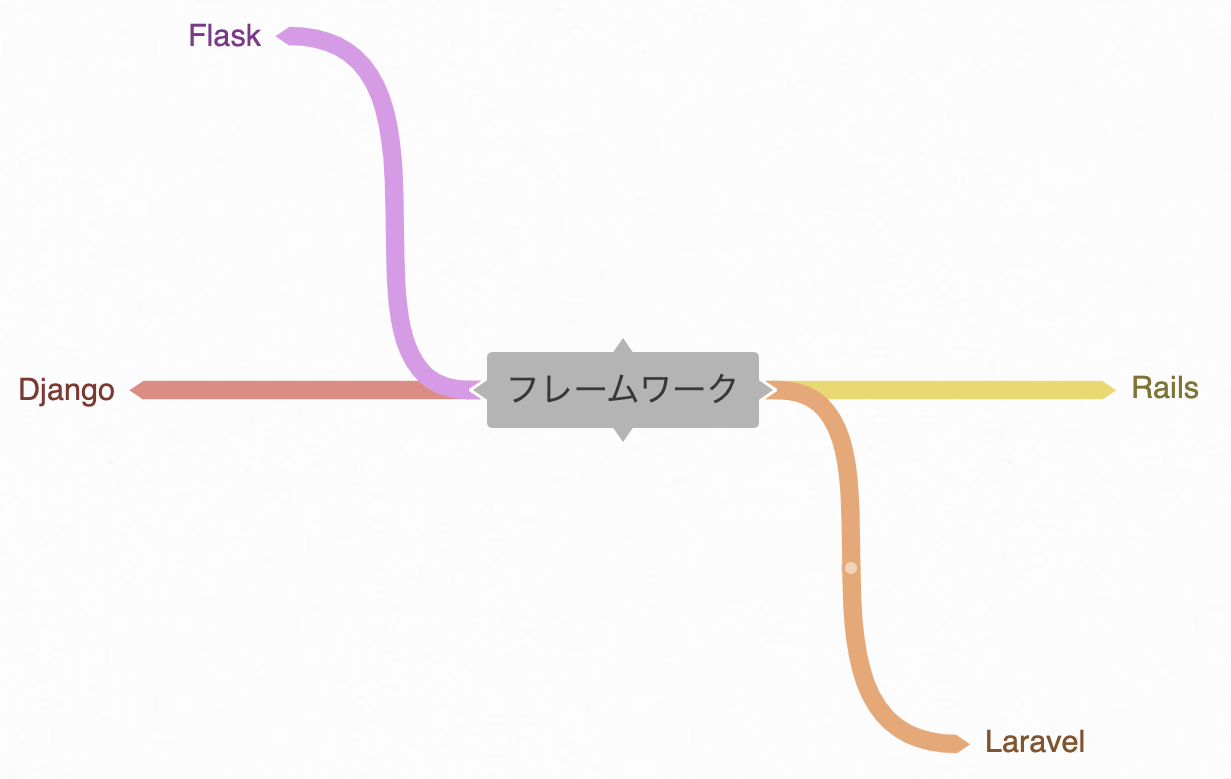
例えば フレームワーク というタグには
Rails Laravel Django Flask
というタグが紐付いているというデータが取得可能で、
例えば Qiita と Python のどちらのタグも紐付いているのは
https://qiita.com/1ntegrale9/items/94ec4437f763aa623965
というタグ(QiitaのPythonに関する記事URL)、のようにデータを取得できます。

上の図では頂点(文字列)がタグ、辺が関係を表しています。
そして無向なので双方参照が可能です。
また包含関係などは考慮しないので、重み付けはありません。
参考記事:グラフ理論の基礎 - Qiita
補足事項
このアーキテクチャは流通しているものではなく、
GraphQLから着想を得て独自に設計したものです。
GraphDB あたりのキーワードで軽くサーベイした程度なので、
もしかしたら既存かもしれません。
構築例:Redis + FastAPI + Heroku
手軽に無料で運用したい場合はこちらを採用します。
Heroku の初期設定や Redis の基本操作はこちらで解説しています。
Heroku×Redis×Python で始める NoSQL DB 入門 - Qiita
Redis
オンメモリで読み書きが高速なKVSです。永続化にも対応しています。
1つのタグに複数のタグを紐付けたいので、集合型のみを使います。
ライブラリのインストール
Python で扱うため、redis-py を利用します。
python3 -m pip install redis hiredis
hiredis-py は C 実装の高速なパーサのラッパーです。
redis-py 側が hiredis を検知してパーサを切り替えてくれるので入れておきます。
Redisに接続
以下のコードで接続の初期化を行います。
Heroku Redis が自動で設定してくれる環境変数 REDIS_URLを使います。
import redis, os
conn = redis.from_url(os.environ['REDIS_URL'], decode_responses=True)
デフォルトだと日本語の表示に不具合があるので、
decode_responses=True は必須です。
全てのタグを取得
keys() を使って取得します。
def get_all_tags():
return sorted(conn.keys())
タグが一覧で見れると便利なので用意しておきます。
ただ規模が大きくなると負荷が高くなるので注意が必要です。
紐付くタグを取得する
smembers(key) 使って取得します。
def get_related_tags(tag):
r.smembers(tag) if r.exists(tag) else []
念のため、存在しないタグを指定された場合は空配列を返すようにします。
存在確認には exists(key) を使います。
2つのタグを紐付けて格納する
sadd(key, value) を使って集合型データを格納します。
双方向に紐付けたいので、key-value を入れ替えて2回実行します。
def set_relation_tags(tag1, tag2):
return conn.pipeline().sadd(t1, t2).sadd(t2, t1).execute()
Redis はトランザクションをサポートしており、redis-py の場合は
pipeline() から execute() までのチェーンにすることで、
トランザクション内での一括実行ができます。
また、pipeline メソッドによるアトミックな実行は、個別実行よりも高速のようです。
PythonでRedisを効率的に使う(redis-pyのパフォーマンスをあげるには) - [Dd]enzow(ill)? with DB and Python
FastAPI
FastAPI は Python の Web フレームワークの1つで、
シンプルな WebAPI を少ないコードで実装できるのと、
API ドキュメントを設定なしで自動生成してくれるのが特徴です。

Flask Responder Starlette DRF などはオーバースペックで、
Bottle は逆に機能が足りず、FastAPIがちょうどよくハマりました。
ライブラリのインストール
python3 -m pip install fastapi uvicorn email-validator
Uvicorn は高速なASGIサーバーです。FastAPIの起動に使います。
Gunicorn の typo ではないです。
email-validator は入れておかないと起動時に怒られます。何故か。
アプリケーションの初期化
非常にシンプルです。
from fastapi import FastAPI
app = FastAPI()
引数の title と discription を設定すると、
上記画像のような自動生成される API Doc にタイトルと説明部が反映されます。
app = FastAPI(
title='collective-intelligence',
description='文字列タグ指向無向グラフ型ナレッジベース',
)
また、docs_url を指定すると、API Doc のURLを変更できます。
デフォルトでは /docs ですが、ルートにしておくのも良いでしょう。
app = FastAPI(docs_url='/')
全てのタグを取得
シンプルに HTTPメソッド(GET) と URL と返り値を書くだけです。
リストか辞書を返り値にすることで JSON レスポンスになります。
@app.get('/api')
def read_all_tags():
return get_all_tags()
この定義が API Doc に自動で反映されます。
更に右上の Try it out からリクエストを実行できます。

指定のタグに紐付くタグを取得
タグには記号も含む任意の文字列を想定しており、
クエリストリングでは対応できないため、POST にしておきます。
@app.post('/api/pull')
def read_related_tags(tag: str):
return get_related_tags(tag)
引数に指定した tag: str をリクエストボディから受け付けます。
型アノテーションを付けていますが、これを利用してリクエストのバリデーションを行います。
適合しない場合、422 Validation Error がレスポンスになります。

2つのタグを紐付けて格納する
FastAPI は pydantic という、
型アノテーションを活用するためのライブラリを内包しています。
これを利用して独自の型を定義し、バリデーションに利用します。
from pydantic import BaseModel
class Tags(BaseModel):
tag1: str
tag2: str
@app.post('/api/push')
def create_tags_relationship(tags: Tags):
set_tags_relationship(tags.tag1, tags.tag2)
return {tag: get_related_tags(tag) for _, tag in tags}

定義した型は Schema として API Doc に反映されます。

FastAPI の起動
先ほど紹介した Uvicorn で起動します。
main.py 内の app で初期化した場合は main:app と指定します。
--reload オプションにより、ファイル変更時にリロードして反映してくれます。
$ uvicorn main:app --reload
INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
INFO: Started reloader process [57749]
INFO: Started server process [57752]
INFO: Waiting for application startup.
INFO: Application startup complete.
http://127.0.0.1:8000 または http://127.0.0.1:8000/docs にアクセスすると、
API Doc が表示されることが確認できると思います。
Heroku
Webアプリケーションを手軽にデプロイできるPaaSです。
多くの言語・フレームワークに対応しており、
PostgreSQL や Redis も一定枠まで無料でホスティングしてくれます。
最初に以下の手順が必要です。
- アカウント登録 Heroku | Sign up
- カード登録 Account · Billing | Heroku
- アプリ作成 Create New App | Heroku
- Redisアドオン追加 Heroku Redis - Add-ons - Heroku Elements
必要なファイルの用意
以下のファイルが必要になります。
これを GitHub リポジトリに用意します。
$ tree
.
├── main.py # アプリケーション
├── Procfile # プロセス実行コマンド定義ファイル
├── requirements.txt # 依存ライブラリ定義ファイル
└── runtime.txt # Pythonバージョン定義ファイル
web: uvicorn main:app --host 0.0.0.0 --port $PORT
fastapi
email-validator
uvicorn
redis
hiredis
python-3.8.0
[実際のディレクトリ](1ntegrale9/collective-intelligence at heroku
) も参考にしてください。
アプリケーションのデプロイ
Dashboard の Deploy タブからデプロイ作業を行います。
GitHub と連携してリポジトリを紐付け、Manual Deploy を実行します。
Automatic deploys も設定しておくと、master への push 時に自動でデプロイしてくれます。

build が無事に完了したら、
登録されたプロセスを Configure Dynos から ON にしておきます。

Dashboard 右上の Open app からデプロイされたアプリケーションを確認できます。
構築例:AWS(DynamoDB + Lambda + API Gateway)
執筆中のため公開をお待ちください
スケーラビリティを意識するならこちらを採用します。
柔軟にデータ構造を変えることも可能です。
初めての、LambdaとDynamoDBを使ったAPI開発 - Qiita
API Gateway + Lambda + DynamoDB - Qiita
Amazon DynamoDB
RDBと同様に1テーブル1プライマリキーが基本です。
プライマリキーはデータを一意に識別するためのキーで、「パーティションキー」または
「パーティションキーとソートキーの複合キー」のことです。
ソートキーを追加することによってパーティションキーのユニーク制限を緩和できます。
開始方法 - Amazon DynamoDB | AWS
初めてのサーバーレスアプリケーション開発 ~DynamoDBにテーブルを作成する~ | Developers.IO
無料枠で頑張るためにDynamoDBのキャパシティを理解する - ITと筋トレの二刀流
テーブルの設計
パーティションキー:タグ
ソートキー:timestamp
テーブルの作成
AWS Lambda
初めてのサーバーレスアプリケーション開発 ~LambdaでDynamoDBの値を取得する~ | Developers.IO
GitHub Actionsを使ってAWS Lambdaへ自動デプロイ (詳説+デモ手順付きver) - Qiita
2つのタグを紐付けて格納する
Lambda が呼び出されると lambda_handler 関数が実行される
import boto3, time
from decimal import Decimal
def lambda_handler(event, context):
timestamp = Decimal(time.time())
table = boto3.resource('dynamodb').Table('collective-intelligence')
with table.batch_writer() as batch: # 複数putする場合はbatch_writerを使うと良い
batch.put_item(Item={
'tag': event['tag1'],
'related_tag': event['tag2'],
'timestamp': timestamp
})
batch.put_item(Item={
'tag': event['tag2'],
'related_tag': event['tag1'],
'timestamp': timestamp
})
return {'statusCode': 201}
指定のタグに紐付くタグを取得
import boto3
from boto3.dynamodb.conditions import Key
def lambda_handler(event, context):
table = boto3.resource('dynamodb').Table('collective-intelligence')
response = table.query(KeyConditionExpression=Key('tag').eq(event['tag'])) # tag指定で検索
tags = set(item['related_tag'] for item in response['Items']) # set型に格納して重複を削る
return {'statusCode': 200, 'body': list(tags)} # JSONレスポンスのためlist型にキャスト
Amazon API Gateway
WebAPIの作成と管理をしてくれる
初めてのサーバーレスアプリケーション開発 ~API GatewayからLambdaを呼び出す~ | Developers.IO
ゼロから作りながら覚えるAPI Gateway環境構築 | Developers.IO
Amazon API Gateway チュートリアル - Amazon API Gateway
リソースとメソッドの作成
/push と /pull で POST を作成
リクエストの検証を設定
Lambdaを実行する前に弾けるとコストが下がってよい
- モデル(JSON Schema)の定義
- 設定->リクエストの検証に「本文の検証」を設定
- リクエスト本文にモデルを設定
JSON Schema Tool
リクエストおよびレスポンスマッピングのモデルおよびマッピングテンプレートを作成する - Amazon API Gateway
APIGatewayの新機能Request Validationを試してみた - エムティーアイ エンジニアブログ
メソッドの作成

メソッドの選択

メソッド管理画面

PULLモデルの作成

PUSHモデルの作成

リクエストの検証を設定
PULL API のテスト

PUSH API のテスト

利用料金に関して
Billing 画面の請求書から確認します。
まだ本稼働しているわけではないですが、
テストで数百件のリクエスト/レスポンスの送受信を行った結果0円だったので、
お試しで使う分には恐れることはなさそうです。

GCP vs AWS
GCP(Firestore)とAWS(DynamoDB)で悩みましたがDynamoDBを採用しました。
GCP側で選択する場合、4つのデータストアサービスから悩むことになると思いますが、
趣味で使うならFirestore一択だと思います。
データベースを選択: Cloud Firestore または Realtime Database | Firebase
終わりに
これらはほぼ独学で得た内容ですが、
新しい技術を習得するスキルは会社のモダンな環境で得られたものだと思います。
強いエンジニアが新技術をガンガン使っていく現場で働けるというのは最高の体験です。
また、Heroku側の構成のものを公開しています。
公開時点でデータは空ですが、自由に触ってみてください。
https://collective-intelligence.herokuapp.com/