みなさんこんにちは@1amageekです。
年末からいろいろやって、ひと段落したのでまとめました。
https://twitter.com/1amageek/status/1092774482563887107
※ ここFirebaseと呼んでるのはCloud Firestoreことをさします。
なぜTransactionが必要なのか
まず、Transactionがどういった機能なのかを簡単に説明します。
TwitterやInstagramのフォロー機能を参考に説明します。
Firestoreでこの機能を実現するならば、以下のように構成するのがもっとも効率的だと思います。
ユーザーAとユーザーBにそれぞれカウントをもたせる
/user/a
{
followerCount: 0
followeeCount: 0
}
/user/b
{
followerCount: 0
followeeCount: 0
}
さらに誰が誰をフォローしてるかを記録するためにそれぞれにSubCollectionをもたせる
/user/a/follower/
/user/a/followee/
/user/b/follower/
/user/b/followee/
これで準備は完了です。ここでAがBをフォローした時の状態を考えてみます。
/user/a
{
followerCount: 1
followeeCount: 0
}
/user/b
{
followerCount: 0
followeeCount: 1
}
/user/a/follower/b
/user/a/followee/
/user/b/follower/
/user/b/followee/a
このようになると思います。この時点ではまだトランザクションは出てきてませんね。
では、Bがとても人気のユーザーになって一瞬のうちにC D E Fにフォローされたとき、どうなるか考えてみましょう。
トランザクションを考慮せずにコーディングすると次のようになります。
// ※なんとなく理解しやすいようにデフォルメしてます。このコードは動きません。
const b: User = new User("b")
const c: User = new User("c") // C or D or E or F
b.followerCount += 1
b.follower.insert(c)
c.followeeCount += 1
c.followee.insert(b)
const batch: Batch = new Batch()
batch(BatchTyep.update, b)
batch(BatchTyep.update, c)
batch.commit()
これをCだけが実行するならば問題ないですが集中的に実行されると次のような結果になります。
/user/b
{
followerCount: 0
followeeCount: 2 // あれれれれ??
}
/user/b/followee/a
/user/b/followee/c
/user/b/followee/d
/user/b/followee/e
/user/b/followee/f
/user/a/follower/b
/user/c/follower/b
/user/d/follower/b
/user/e/follower/b
/user/f/follower/b
BのfolloweeCountは増えてませんね。
実はここに問題があります。
b.followerCount += 1
Aからフォローされていることを考えるとb.followerCountには1が入ってるはずですね?
C D E Fは同時にこのコードを実行したために、次のようなことが起こっています。
console.log(b.followerCount) // 1
b.followerCount += 1
console.log(b.followerCount) // 2
全員が2で上書きしていた。😇
ここで登場するのが__Transaction__です。
FirebaseのTransactionについて理解する
Firebaseの__Transaction__では次のようにこの問題を回避します。
これはFirebaseのTransactionの例です。
const b = new User("b")
await db.runTransaction(function(transaction) {
// bのデータを読み込む
await b.fetch(transaction)
// countアップさせる
const followerCount: number = b.followerCount + 1
// データを上書きする
transaction.set(b.reference,
{ "followerCount": followerCount },
{ merge: true })
})
公式ドキュメントの中には次のように説明があります。
トランザクションが、トランザクション外部で変更されたドキュメントを読み取る。この場合、トランザクションは自動的に再実行されます。トランザクションは一定の回数で再試行されます。
runTransactionの中のコードは、外から変更された場合再試行されます。

こうすることで、followerCountの値を最新に保ち一貫性を保つことが可能です。Firebaseでは通常5回再試行され、5回失敗するとそのトランザクションは失敗になります。
これで安全に開発可能かなと思いきやそうではありません。Firebaseの書き込みには時間的な制限があります。
1秒に1回しか書き込みを行うことができません。
Bがとても人気のユーザーになっても1秒に1フォロワーしか増やせない。
FirebaseのTransactionの負荷分散
集中アクセスがありかつトランザクションが必要な場合、負荷分散をする必要があります。これはFirebaseに限らず他のデータベースであっても同じで集中的なアクセスはいつか捌くことができなくなります。
分散カウンタ
負荷分散を行う代表として分散カウンタがあります。
FirebaseではSubCollectionへShardを定義してShard数分負荷を分散させることが可能です。
Shardの選択は__ランダム__に行われます。なぜランダムに選択されるのかに関しては後に説明します。

また、分散カウンタのデメリットとして、Documentに静的な数値を持っていないため、毎回全てのカウンタを合計して数値を算出する必要があります。
負荷分散の性能は初期値に依存してしまう
負荷分散の性能は最初に設定したShardの数に依存してしまうため、最初にShard数を多めに設定しすぎたり、少なめに設定すると余計な算出コストが必要であったり、分散性能が足りなくなることを意味します。
分散性能に関しては動的に変更する仕組みが必要かも知れません。
FirebaseのTransactionの応用
さて、フォロー機能に関しては分散カウンタを活用することで、余計なコストを払う可能性は出たものの十分に機能しそうであることがわかりました。次にトランザクションの応用を考えてみましょう。
僕はこのCloud Firestoreのトランザクションを用いてECに応用できないか考えてみました。
ECでは在庫管理機能が必要になります。
分散カウンタさえあれば、うまく行きそうな気がしますよね?実はうまく行きません。その理由を説明します。
負荷分散はRead負荷に弱い
ここではiPhoneの予約販売を想像してください。1万台の在庫を本日16時から一斉に予約開始としましょう。
これを100個のShardで捌くことにしましょう。そしてもちろんカウンタが10,000になれば受付終了です。
コードで書くならばこんな感じです。
const shardID = Math.floor(Math.random() * num_shards).toString()
const shard = new Shard(shardID)
await db.runTransaction(function(transaction) {
// countを初期化
let count = 0
let shardCount = 0
// 100個のShardから現在のCountを取得する
let tasks = []
for(let i=0; i<100; i++) {
const shard = new Shard(i.toString())
const task = async () => {
await shard.fetch(transaction)
count += shard.count
if (shard.id === shardID {
shardCount = shard.count
}
}
tasks.push(task)
}
await Promise.all(tasks)
// 10,000を超えてたら処理を終了させる
if (count >= 10000) {
throw new Error("Out of stock")
}
shardCount += 1
// データを上書きする
transaction.set(shard.reference,
{ "count": shardCount },
{ merge: true })
})
残念ながら動きません。なぜ動かないのかを説明します。16時に一斉に予約がスタートした時のことを考えてください。
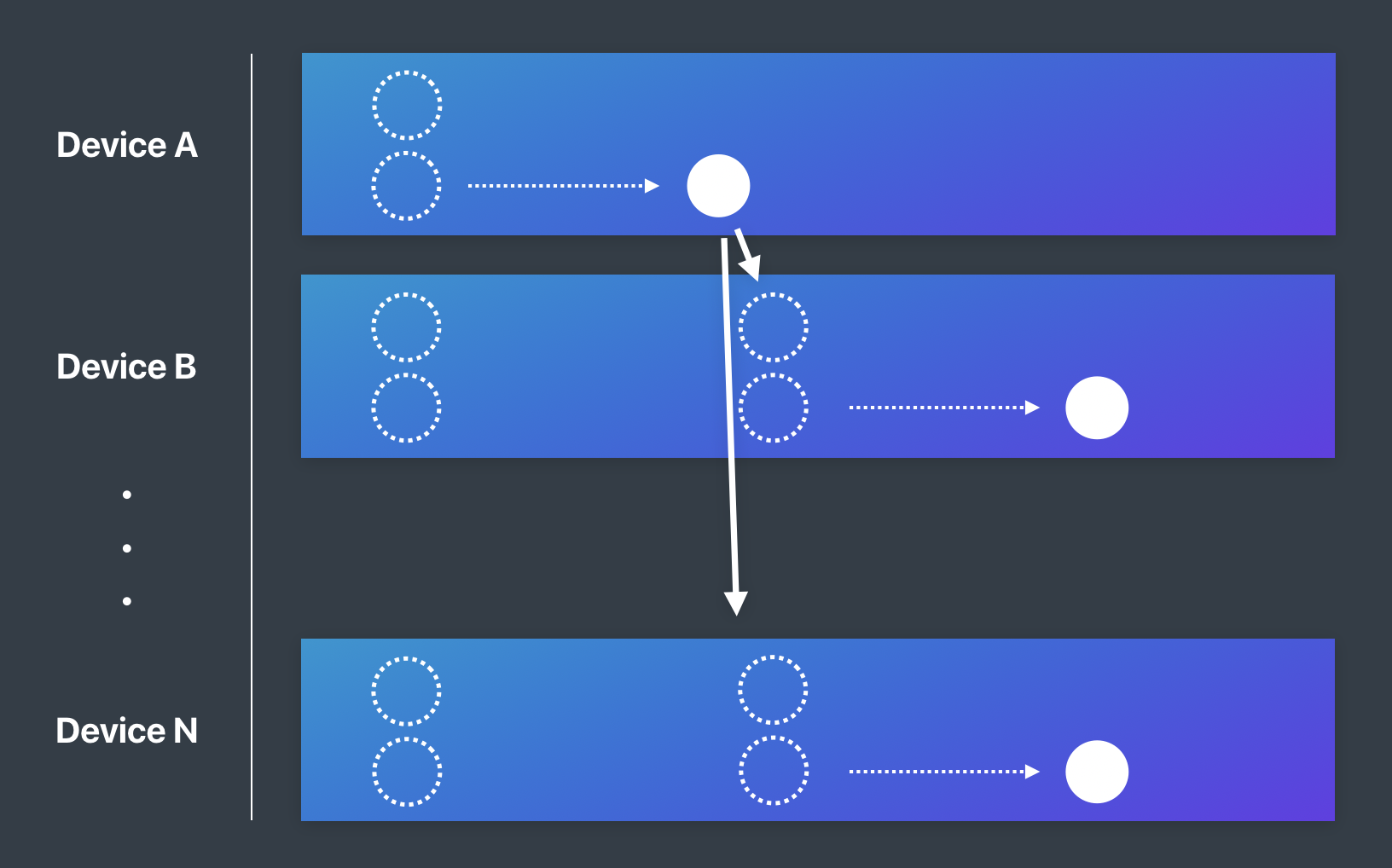
各デバイスは一斉に100個のShardをReadし始めます。Device AがWriteに成功したとしましょう。そうするとその変更をキャッチした全てのDeviceの全てのShardがまた100個のShardをReadし始めます。これが繰り返されるとなるととんでもない負荷がかかることが想像できます。
またこのことは先に話したShardをランダムに決定することと関連しています。もっとも効率的な方法は利用されないShardを選択して負荷を隔たりなく分散することですが、それは出来ません。Shardのリード数を増やすことは性能劣化を引き起こすため、ランダムに選出するしかない訳です。
ではどのようにすれば解決できるでしょうか?
この問題を解決するためにトランザクションそのものについて理解を深めましょう。
Transactionとはなにか?
そもそもTransactionとはなんでしょうか?
トランザクション (英: transaction) とは、データベース管理システム(または類似のシステム)内で実行される、分けることのできない一連の情報処理の単位である。
トランザクション処理は、既知の一貫した状態のデータベースを維持するよう設計されており、相互依存のある複数の操作が全て完了するか、全てキャンセルされることを保証する。
次の引用からなんとなく想像がついたでしょうか?このTransaction処理の特性さらに明確に言語化したもがACID特性です。
ACIDとは、信頼性のあるトランザクションシステムの持つべき性質として1970年代後半にジム・グレイが定義した概念で、これ以上分解してはならないという意味の原子性(英: atomicity、不可分性)、一貫性(英: consistency)、独立性(英: isolation)、および永続性(英: durability)は、トランザクション処理の信頼性を保証するために求められる性質であるとする考え方である[1]。この語はその4つの性質を表す英語の語の頭字語をとって作られた合成語であり、1983年にアンドレアス・ロイター[2]とテオ・ヘルダー[3]によって提唱された。
トランザクションでは、4つの特性満たしている必要があります。Cloud Firestoreではどうでしょうか?
Atomicity: 原子性
Cloud Firestoreのトランザクションは成功と失敗が明確に分かれています。トランザクション内の処理が一つでも失敗すれば処理自体が失敗するのでこの特性は満たしています。
Consistency: 一貫性
Cloud Firestoreのトランザクションは、上記のフォローカウントの説明にもあるようにデータに矛盾が置きないようになっているのでこの条件は満たしています。
Durability: 永続性
Cloud Firestoreは永続運用されるマネージドなサービスなのでこの条件も満たしています。
Isolation: 独立性
問題はここです。Cloud Firestoreのトランザクションは、他のトランザクションの影響を大きく受けます。その結果、同時処理が機能しなくなる場合さえあります。
どうやらCloud Firestoreのトランザクション性能を向上させるには独立性についてさらに理解を深める必要がありそうです。
Transactionの分離レベルについて理解する
トランザクションには分離レベルと呼ばれる概念が存在します。
トランザクション分離レベルまたは分離レベルとは、データベース管理システム上での一括処理(トランザクション)が複数同時に行われた場合に、どれほどの一貫性、正確性で実行するかを4段階で定義したものである。隔離レベル 、 独立性レベルとも呼ばれる。
あるデータに対する読み書きの処理を行う場合、わずかでも処理時間が発生する。処理が「複数同時に並行して」実行されようとした場合、感覚的にはどちらかの処理が先に行われ、残ったほうの処理が後に行われるであろう。この場合、後に行われた処理は先に行われた処理が完了するまでの間「待ち」の状態になってしまう。データベース管理システムはこれらの「待ち」の状態を可能な限り防ぐため、複数の処理を並列で行っている間でもその他の処理を受け付けられる制御方法が確立された。このとき、1つのトランザクション処理が他の処理からどれだけ独立して行われるかが焦点になる、すなわち、「待ち時間を減らすためどれだけデータの一貫性を犠牲にして良いか」を定めたものが、トランザクション分離レベルである。
簡単に言うと
一貫性と処理性能はトレードオフの関係にあり、トレードオフの度合いを定義したものが分離レベルです。
また、分離レベルは4つレベルが定義されています。
分離レベル
以下の4つを理解するためにはINSERT UPDATEを意識してトランザクションを考える必要があります。
SERIALIZABLE ( 直列化可能 )
一つ一つ全ての処理(INSERTおよびUPDATE)を直列に実行すれば、不整合は置きないがとにかく性能が悪い。
REPEATABLE READ ( 読み取り対象のデータを常に読み取る )
UPDATEは直列に実行し、INSERTは並列に処理されることを許容する。
データ数のカウントなどの処理がない場合はこのレベルで大丈夫。INSERTが解放されている分性能がよくなる。
READ COMMITTED ( 確定した最新データを常に読み取る )
UPDATE INSERTが並列に処理されることを許容する。
トランザクション内では確定した最新データを常に読み取る。
READ UNCOMMITTED ( 確定していないデータまで読み取る )
UPDATE INSERTが並列に処理されることを許容する。
トランザクション内では確定してない最新データを常に読み取る。
参考記事
Cloud FirestoreはREAD COMMITTEDであると言えます。
※分離レベルの説明には多くの用語を使用する必要がありますが、今回は可能な限りわかる範囲の言葉で説明します。トランザクション設計において重要なところなので詳しく知りたい方はさらに勉強をすることをお勧めします。
上記の理解を得た上で改めて今回の問題を考えてみましょう。
つづく。
記事をストックしてもらえると変更通知が届きます。続きが気になる方はぜひストックをしておいてください!🙏🏻
Firebaseのイベントあるからきてくださーい。
https://stamp.connpass.com/event/122066/