Amazonの最新AIモデル「Nova Lite」と「Nova Canvas」を対象に、生成AIの監視とモニタリングの手法を探ります。DatadogのLLM オブザーバビリティを駆使し、どのような観測性を実現できるのか検証します。
AWSのAIモデル Amazon Nova Lite で遊んでみる
Pythonコードで画像生成。AWSのAIモデル Amazon Nova Canvas
生成AIのモニタリング
最初に結論から。Datadog の LLM Observability で実現できたことは以下の通りです。
- 時系列の実行回数
- テキスト生成にかかった応答時間
- 入出力プロンプトのテキスト内容を確認
- 入出力のトークン数
- LLM呼び出し回数
- 成功した結果(OK, ERROR)
- アラート通知
- APMと連動したトレース確認
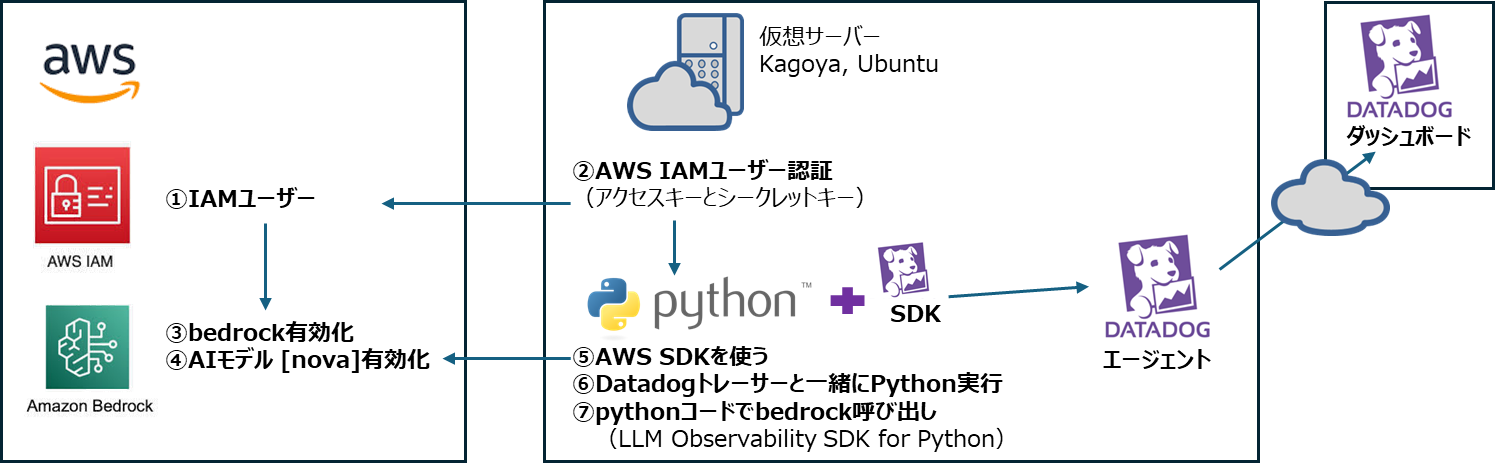
対象の環境
-
AWS
- AWS Amazon Bedrock + Nova Lite
- 生成AIはpythonコードで実行
-
Kagoya 仮想サーバー
- Ubuntu22.04
-
Datadog
- Datadog Agent
- Datadog トレーサー
- 参考(AWS integration はしていません)
Datadog の設定手順
- Datadog ダッシュボードでの設定は必要なかった
- Datadog の AWS integration は必須でない
- Amazon Bedrockを実行するサーバーのPython周りで2つ設定する
- ddtraceをインストールして、コマンドラインでpythonを呼び出し
- LLM Observability SDK を呼んで、pythonコード内に記述
1. Pythonコマンドライン設定
生成AIを実行する仮想サーバーにログインしたら、ddtraceをインストールして、コマンドラインでpythonコードを実行する。
$ pip install ddtrace
公式サイトが日本語化されていないので概要のみパラメータを記載。
パラメーターを最低4つ指定してpythonを実行する。
- DD_SITE: "datadoghq.com"を指定する
- DD_LLMOBS_ENABLED: オブザーバビリティを有効化(1またはtrue)
- DD_LLMOBS_ML_APP: 自分アプリの名前
- DD_API_KEY: Datadogダッシュボードの[Organization Settings > API Keys]で取得
- DD_LLMOBS_AGENTLESS_ENABLED: Datadog Agentを使わないエージェントレスの時だけ指定(1またはtrue)
▼ 実行コマンドのサンプル(見やすいように改行してあるが一行で指定できる)
$ DD_SITE=datadoghq.com \
DD_API_KEY= ~略~ \
DD_LLMOBS_ENABLED=1 \
DD_LLMOBS_ML_APP=Bedrock_Nova \
ddtrace-run python3 bedrock_dd.py "ここに生成したい文章を説明する(プロンプト)"
コマンドラインだけで Datadog の LLM Observability で取得できるメトリックは下記の通り。しかし、これだけでは生成AIの監視・モニタリングには不足であり、PythonコードにLLMObsモジュールを導入する。
- テキスト生成にかかった応答時間
- 入出力のトークン数
- LLM呼び出し回数

APM Traces にも記録される
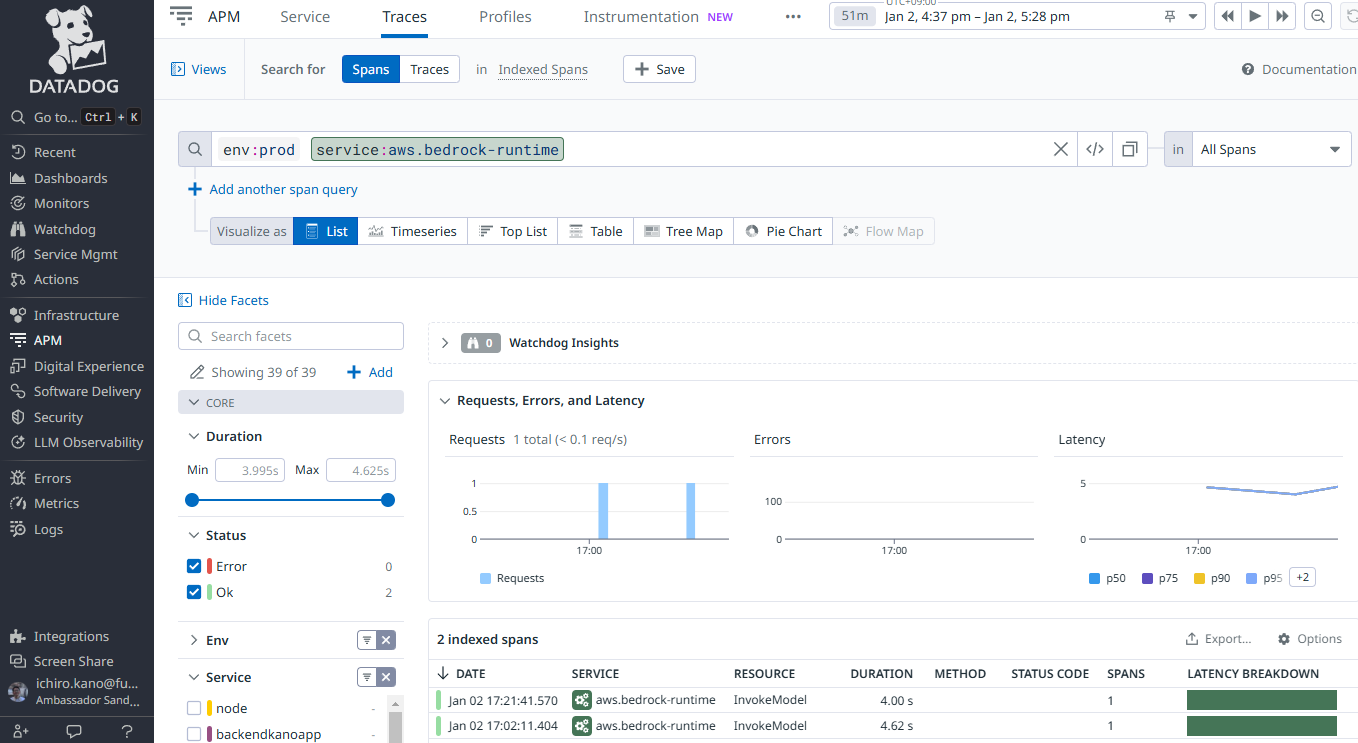
2. Pythonコード設定
コマンドラインのDatadogトレーサーだけではメトリックやトレースが不十分。詳細はPythonコードにLLMobsオブザーバビリティモジュールの追記が必要。最初はAmazon Bedrockを呼ぶだけのPythonコードを作って生成AIの機能検査をおこなった。その後、LLMobsモジュールを追加した。
モニタリング設定に成功すると、プロンプト入力テキストと生成されたテキストの出力結果など、詳細をモニタリングできる。
詳細なLLMオブザーバビリティを実現するために追加したコード抜粋
from ddtrace.llmobs import LLMObs # Datadog
from ddtrace.llmobs.decorators import embedding, llm, retrieval, workflow # Datadog
@llm(model_name="nova-lite-v1:0", model_provider="amazon")
def llm_call( prompt ):
response = bedrockRuntime.invoke_model( …ここにLLM呼び出しコード…)
LLMObs.annotate(
span=None,
input_data=[{"role": "user", "content": prompt}],
output_data=[{"role": "assistant", "content": generatedText}],
metadata={"temperature": 0.7, "max_tokens": 512},
tags={"host": "game.funnygeekjp.com"},
)
return response
Datadog LLM Observability 付きのpythonコード全体
import sys
import boto3
import json
from botocore.exceptions import ClientError
from ddtrace.llmobs import LLMObs # Datadog
from ddtrace.llmobs.decorators import embedding, llm, retrieval, workflow # Datadog
# Bedrock runtime client の作成, Nova Lite モデルを使う。バージニア北部リージョンで利用可能
bedrockRuntime = boto3.client("bedrock-runtime", region_name="us-east-1")
MODEL_ID = "amazon.nova-lite-v1:0"
# モデルのネイティブ構造を使ってリクエストする
@llm(model_name="nova-lite-v1:0", model_provider="amazon")
def llm_call( prompt ):
requestPayload = {
"messages": [
{
"role": "user",
"content": [
{"text": prompt}
]
}
],
"inferenceConfig": {
"maxTokens": 512,
"stopSequences": [],
"temperature": 0.7,
"topP": 0.9
}
}
# リクエスト実行
try:
response = bedrockRuntime.invoke_model(
modelId = MODEL_ID,
body = json.dumps( requestPayload ),
contentType = "application/json"
)
# generated_text の取得と表示
responseBody = json.loads( response['body'].read() )
generatedText = responseBody['output']['message']['content'][0]['text']
print( generatedText )
LLMObs.annotate(
span=None,
input_data=[{"role": "user", "content": prompt}],
output_data=[{"role": "assistant", "content": generatedText}],
metadata={"temperature": 0.7, "max_tokens": 512},
tags={"host": "game.funnygeekjp.com"},
)
return response
except (ClientError, Exception) as e:
print(f"ERROR: 実行できません '{MODEL_ID}', Reason: {e}")
exit(1)
if __name__ == "__main__":
# コマンドラインからプロンプトを取得
if len(sys.argv) < 2:
print("書式$ python3 bedrock.py 'ここに質問をテキストで記載する'")
sys.exit(1)
else:
prompt = sys.argv[1]
llm_call( prompt )
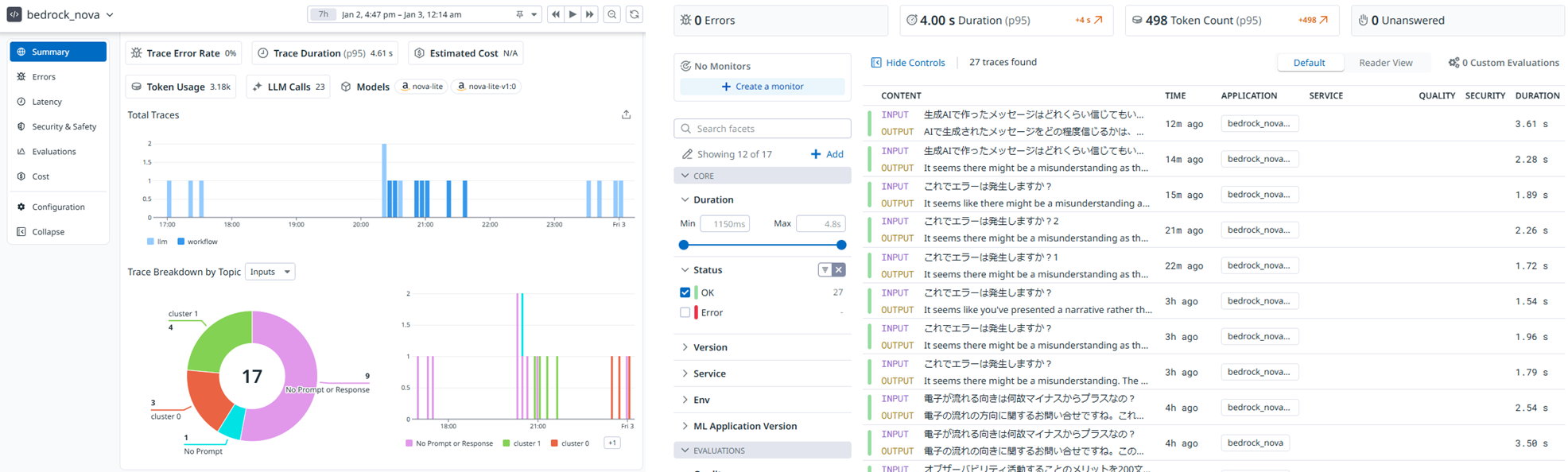
LLMオブザーバビリティできること
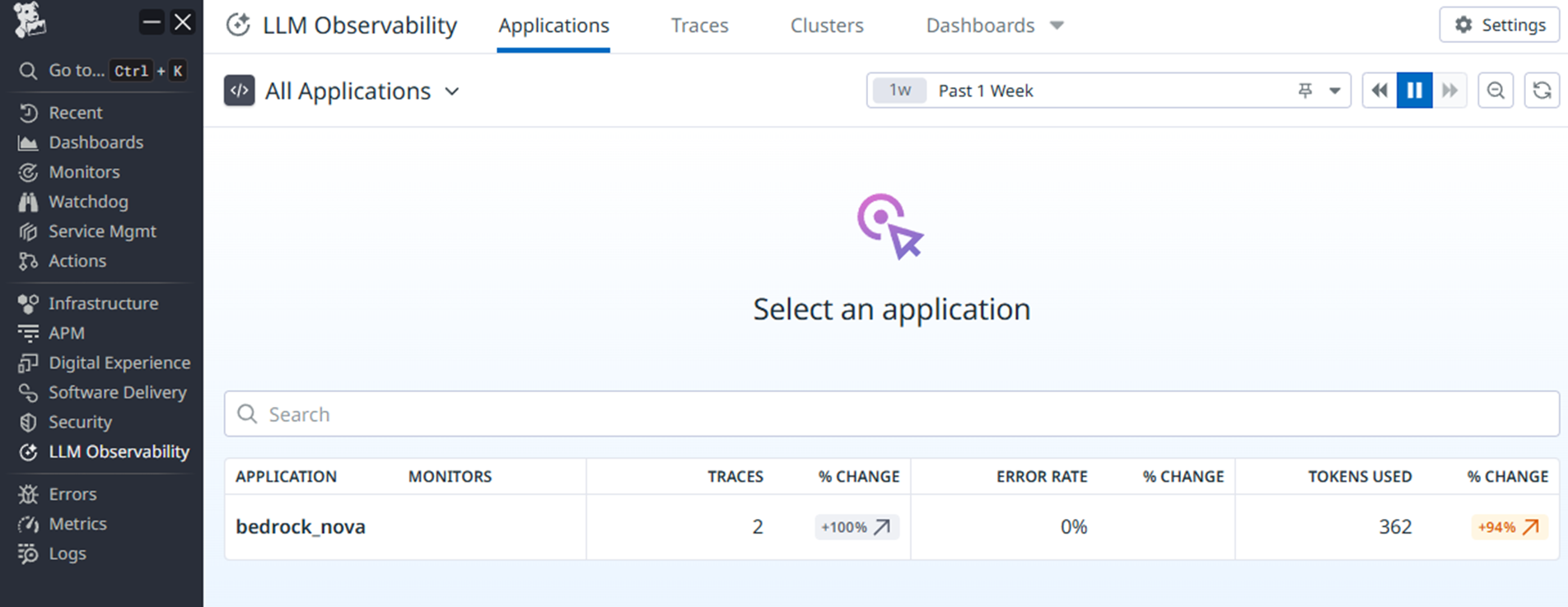
アプリ一覧
《 LLM Obsevability > Applications 》
この例では一個(bedrock_nova)しか表示されていないけど生成AIアプリ一覧が表示される。アプリを分けて運用管理したいときはコマンドラインのDD_LLMOBS_ML_APP=Bedrock_Novaのように記載するアプリ名で指定する
アプリのサマリー
《 LLM Obsevability > Applications > アプリ選択 》
いつどれだけ生成AIが実行されたのか一目でわかる
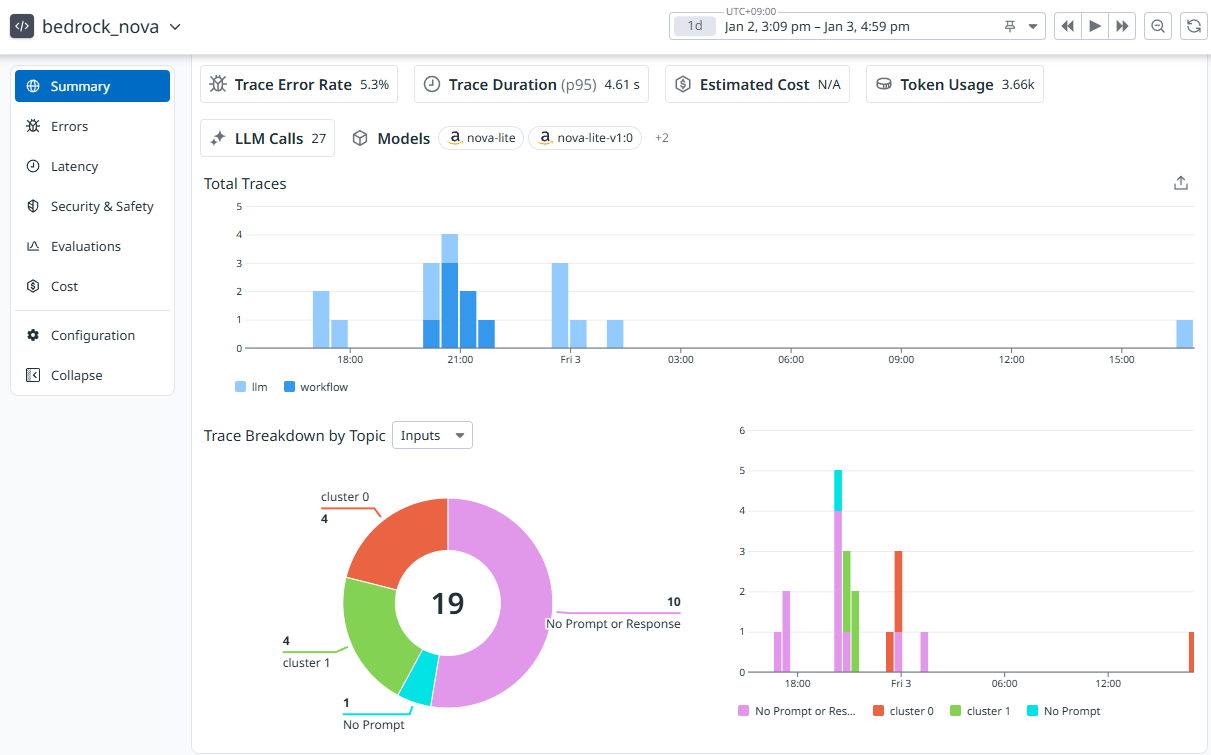
トレース一覧
《 LLM Obsevability > Traces 》
生成AIが実行されるとトレースが追加されていく。エラー有無, プロンプトの入出力結果をリストで表示できる。

トレース確認
《 LLM Obsevability > Traces > トレース選択 》
プロンプトの入出力と呼ばれたAIモデル名, パラメータを確認できる。

トレースはAPMにも遷移できる
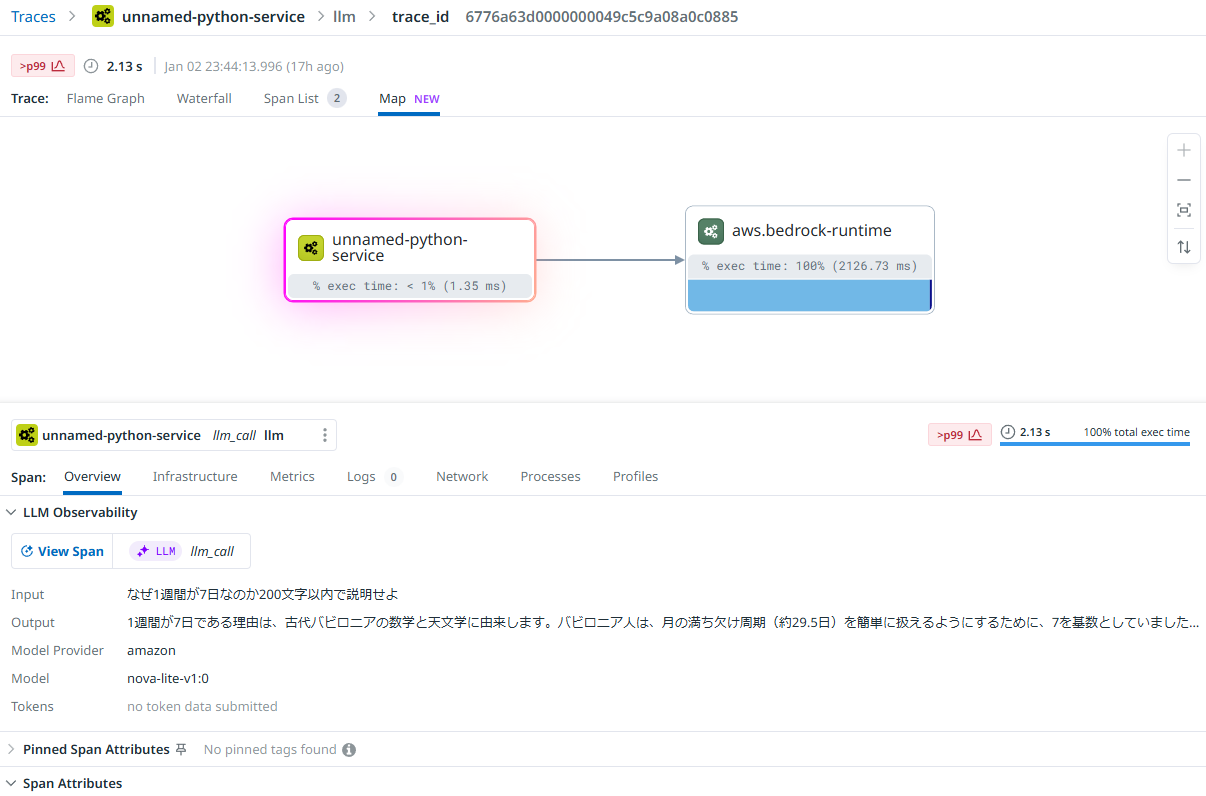
エラー確認
生成AIを実行するモジュールでエラーが発生した場合の例。標準出力に表示されるエラー内容を確認できる。
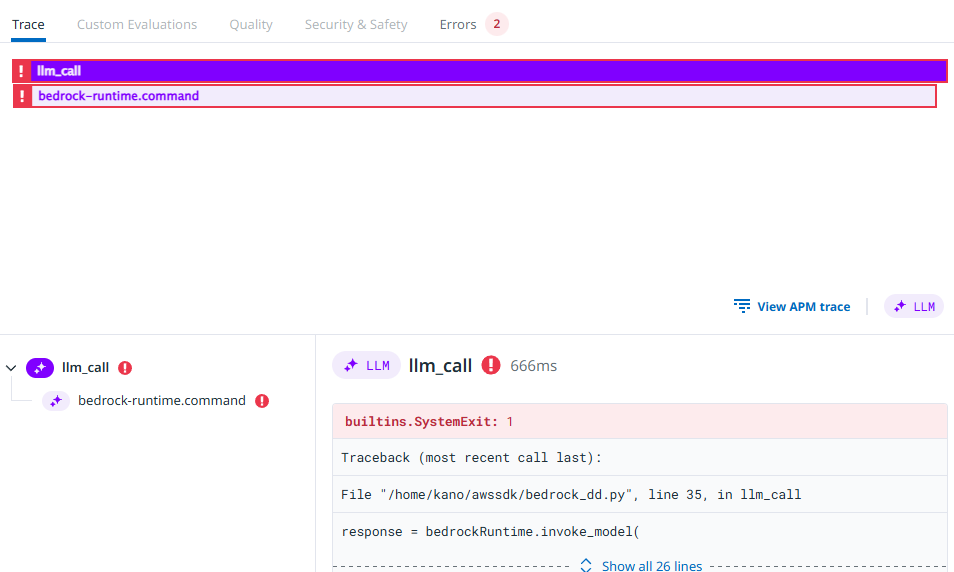
無効なモデルIDが指定されてエラーになっています。
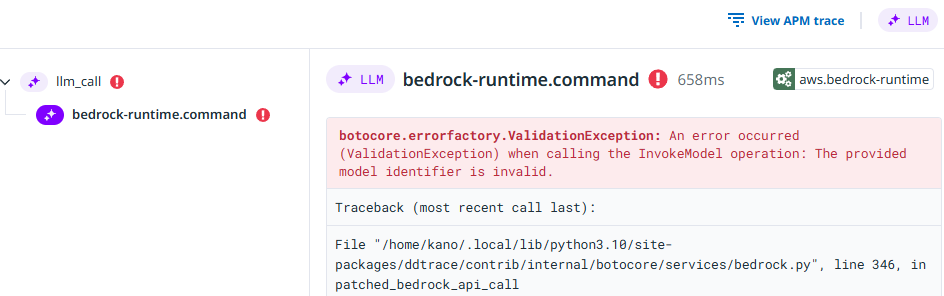
監視アラート(通知)
5分間に5回以上エラーが発生した場合にアラート通知するモニターを設定した。
存在しないAIモデルIDを指定してエラーを発生させてみるとメールを受信できた。

できたこと
- LLM実行回数(時系列でいつ何回、AIが実行されたか)
- テキスト生成にかかった応答時間(AIモデル nova lite はバージニア北部リージョンだけで使えるがテキスト生成まで2~4秒で生成できた)
- 入力プロンプトのテキスト内容を確認できる
- 出力プロンプトのテキスト内容を確認できる
- 入出力のトークン数
- LLM呼び出し回数
- 成功した結果(OK または Error)
- Errorを検知したらメール通知するモニターを設定できる
- APMと連動したトレース確認
- 利用しているAIモデル, バージョンがわかる
まとめ
ユーザーが問合せしたプロンプトの入出力テキストが表示される。個人的な質問や個人情報を覗き見できてしまうことの是非が問われそうだが、生成AIの正確性を検査するには必要だと思った。個人情報は入力させないなどアプリの利用条件で注意喚起するとか生成AIの利用ガイドラインが大切。
-
できたこと
「できたこと」の章に記載したが、生成AIで何をモニタリングすべきかざっと理解できた。生成AIが実行されてプロンプト出力が成功したことを観測するアプリ開発者にメリットがある。インフラ面ではレスポンス時間を計測してパフォーマンスの維持改善に役立つ。LLM SDKを組み込んだpythonアプリがエラー終了するとアラート通知できる。 -
できないかも
「できない | 難しい」ことを挙げるとしたら、コマンドラインでのモニタリング設定だけでは詳細なモニタリングができないこと。PythonコードにLLMobsモジュールを組み込まなければならず、ITインフラチームだけで監視運用の初期設定は難しいので、アプリ開発者の協力が必要。 -
次にやりたいこと
AWS従量課金を月額で数百円に抑えながら、しばらくヒートラン実行させてみて時系列でのパフォーマンスも計測してみたい。あと、Novaシリーズの違うAIモデルでも試してみる。