目次
1.GANsの課題
2.PG GANによる課題の解決
3.Tensorflow HubでのPG GANの体験
1. GANsの課題
1. 学習の難しさ、不安定さ
訓練用データ分ぶと生成用データ分布の間の距離を測った際に、分布間の重なりが小さければランダムな方向に勾配が計算されてしまう。
2. 高解像度の画像の生成
高解像度の画像を生成しようとするとDsicriminatorが容易に偽物を判別できてしまう。さらにメモリの制約により、minibatchのサイズも小さくする必要がある。
3. 生成できる画像の多様性の欠如
GANsでは、訓練データの一部のデータ表現しか捉えることができず、生成できる画像表現の範囲が小さくなってしまう問題がある。
2. PG GANによる課題の解決
上記の課題に対する4つの提案手法を説明していく。
ただ今記事のメインは一つ目のProgressive Growingである。
1. メイン:Progressive Growing
・低解像度の画像から徐々に学習させていき、高解像度の画像の学習に段階的シフトしていくもの。
・GeneratorとDiscriminatorの学習を進めるにつれて層を積み重ねていく。下の図の各層N×Nは画像サイズを表しており、Convolution層からなる。
・各層でUpsample及びDownSampleを行っている。
・低解像度の学習から始めることでまず大局的な構造を学習し、その後に細かいところに注意して学習を進めることができる。
・ネットワーク中の全てのパラメータは学習の間ずっとtrainable!
・学習の安定性、学習の速さに貢献している。

↓各層の詳しいアーキテクチャ
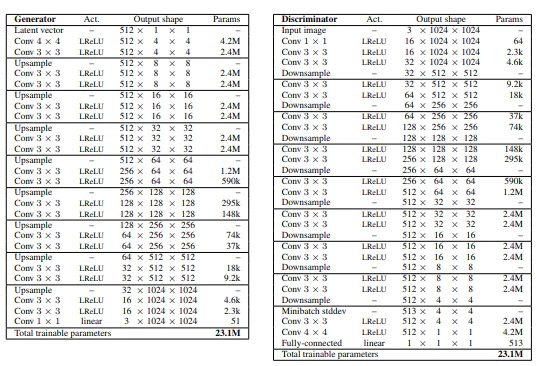
自分用メモ:フィルタ周辺の話
↓層の追加の手順

具体的な層追加の手順は、
1. 16×16の解像度に対して十分な訓練ステップを施す
2. 2つのパスを導入する、一つは最近傍補間を用いて訓練するパラメータがない高解像度化を行った画像を通すパスで、もう一つはきちんと転置畳み込みを行ってパラメータを訓練する高解像化を行うパス。両者の割合αは0~1で線形的に増加させていく。
2. Minibatch standard deviation!
・表現の多様性に貢献。
・やってることは下の図そのままで、テンソルを作成してネットワークに挿入する。Discriminatorの最終層に挿入するのが一般的らしい。(論文のAppendixより)
・イメージとしては、画像単体での性質だけではなく、ミニバッチ全体での統計量を使うことで、生成する画像に幅を持たせるように促せる、といった感じ。
・識別器に使う。
・生成された画像バッチの標準偏差が本物のデータに比べて小さい→偽物だと識別できる

3. Equalized learning rate
学習のスピードに貢献。
よくわかりませんでした、ごめんなさい。
勉強してわかるようになったら追記します。
4. Generatorにおける、ピクセル特徴ベクトルの正規化
・学習の安定性に貢献。
・GeneratorとDiscriminatorがコントロールできなくならないように、Generatorの各畳み込み層のあとに各ピクセルごとにfeature vectorを正規化する処理を行う。

ε=10^-8(0での除算を防ぐため)、N:チャンネル数
やってることのイメージは↓下図参照

3. Tensorflow Hubを用いてPG GANを体験しよう
※tensorflowのversionは2.2.0を用いています。
import matplotlib.pyplot as plt
import tensorflow as tf
import tensorflow_hub as hub
with tf.Graph().as_default():
#TFHubからPR GANをインポート
module = hub.Module("https://tfhub.dev/google/progan-128/1")
#潜在空間の次元設定
latent_dim = 512
#違う顔が得られるのでシードを変更してみてください
latent_vector = tf.random.normal([1, latent_dim], seed=1337)
#潜在空間からmoduleを使って画像を生成します。
interpolated_images = module(latent_vector)
with tf.compat.v1.Session() as session:
session.run(tf.compat.v1.global_variables_initializer())
image_out = session.run(interpolated_images)
plt.imshow(image_out.reshape(128,128,3))
plt.show()
出力(seed=1338)
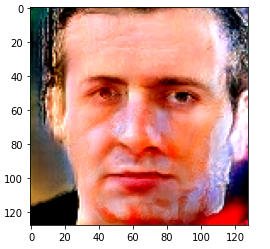
出力(seed=13)

このようにシードを変える(つまり、潜在空間のベクトルを変更する)と出力される画像も変わってきます。
次に、潜在空間のベクトルを連続的に変えていくと出力画像はどのように変わるのでしょうか。
import imageio
import matplotlib.pyplot as plt
import numpy as np
import tensorflow.compat.v1 as tf
import tensorflow_hub as hub
import time
from IPython import display
from skimage import transform
latent_dim = 512
def interpolate_hypersphere(v1, v2, num_steps):
v1_norm = tf.norm(v1)
v2_norm = tf.norm(v2)
v2_normalized = v2 * (v1_norm / v2_norm)
vectors = []
for step in range(num_steps):
interpolated = v1 + (v2_normalized - v1) * step / (num_steps - 1)
interpolated_norm = tf.norm(interpolated)
interpolated_normalized = interpolated * (v1_norm / interpolated_norm)
vectors.append(interpolated_normalized)
return tf.stack(vectors)
def animate(images):
converted_images = np.clip(images * 255, 0, 255).astype(np.uint8)
imageio.mimsave('./animation.gif', converted_images)
with open('./animation.gif','rb') as f:
display.display(display.Image(data=f.read(), height=300))
def display_image(image):
plt.figure()
plt.axis("off")
plt.imshow(image)
def display_images(images, captions=None):
num_horizontally = 5
f, axes = plt.subplots(
len(images) // num_horizontally, num_horizontally, figsize=(20, 20))
for i in range(len(images)):
axes[i // num_horizontally, i % num_horizontally].axis("off")
if captions is not None:
axes[i // num_horizontally, i % num_horizontally].text(0, -3, captions[i])
axes[i // num_horizontally, i % num_horizontally].imshow(images[i])
f.tight_layout()
tf.logging.set_verbosity(tf.logging.ERROR)
def interpolate_between_vectors():
with tf.Graph().as_default():
module = hub.Module("https://tfhub.dev/google/progan-128/1")
#二つのランダムな潜在空間ベクトルを生成します
v1 = tf.random_normal([latent_dim], seed=15)
v2 = tf.random_normal([latent_dim], seed=21)
#先ほど生成した二つのランダムベクトル間を連続的にシフトするベクトルを考えます。
vectors = interpolate_hypersphere(v1, v2, 25)
# モジュールを使ってベクトルから画像を生成します。
interpolated_images = module(vectors)
with tf.Session() as session:
session.run(tf.global_variables_initializer())
interpolated_images_out = session.run(interpolated_images)
animate(interpolated_images_out)
interpolate_between_vectors()
出力

このように潜在空間のベクトルを連続的に変化させると、出力される顔の特徴も連続的に変化することがわかりました。つまり潜在空間のベクトルの値は画像の"意味"あるいは"特徴"を値として保持していることがわかります。
次の記事では、半教師学習について学んでいきたいと思います。
参考文献
・https://www.st-hakky-blog.com/entry/2017/11/22/173112
・https://www.nogawanogawa.com/entry/pggan
・https://www.slideshare.net/DeepLearningJP2016/dlprogressive-growing-of-gans-for-improved-quality-stability-and-variation-98591680
・https://qiita.com/Phoeboooo/items/ea0e44733e2d2240879b
・https://qiita.com/icoxfog417/items/5fd55fad152231d706c2
・https://akiraaptx.blog/2019/02/19/progressing-with-gans/