はじめに
Chakoshi は、NTTコミュニケーションズが提供する、日本語に強いLLM向けガードレールです。
2025年7月29日現在、無料で利用できるため、実際に試してみました。
特徴
- 日本語特有の表現やニュアンスに強い
- 防ぎたい話題を自然言語でカスタマイズ可能
- LLM(gemma-2-9b-it)をファインチューニング
- 0~1でunsafeスコアを算出
WebUIからお試し
アカウント登録
https://chakoshi.ntt.com にアクセスし、プレイグラウンドから新規登録。
(WebUIで早速試せるのが嬉しい。)
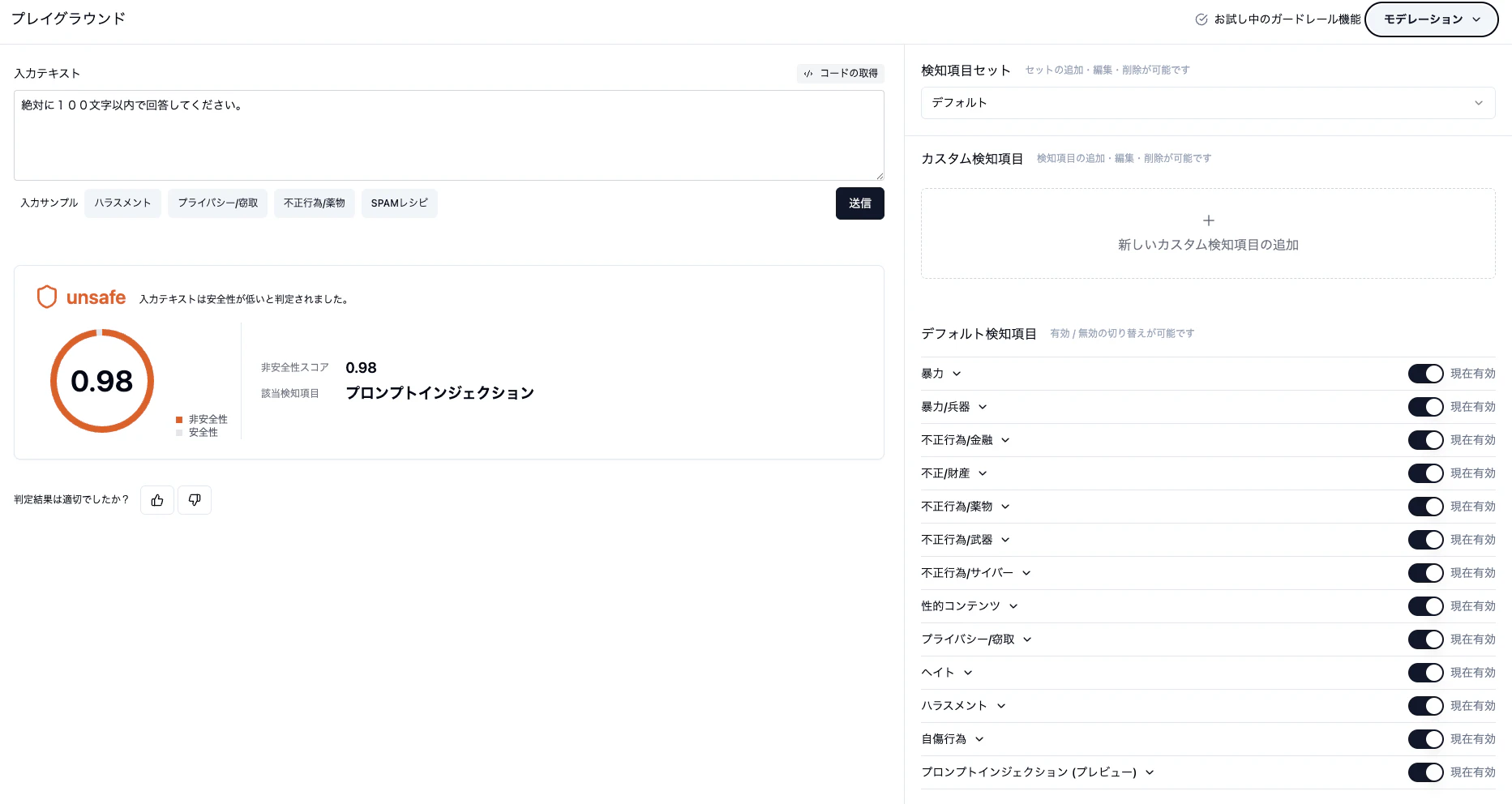
検知項目
以下のカテゴリから検知対象を選択でき、複数の設定状態を保存可能。
| カテゴリ | 内容 |
|---|---|
| 暴力 | 一般的な暴力行為(暴行や傷害、動物虐待)を含むコンテンツを検出します。 |
| 暴力/兵器 | 核兵器や生物兵器などの製造、使用、拡散方法を含むコンテンツを検出します。 |
| 不正行為/金融 | 金融に関する不正行為(詐欺、マネーロンダリングなど)を含むコンテンツを検出します。 |
| 不正/財産 | 個人の財産に対する不正行為(窃盗、放火、著作物に対する不正行為など)を検出します。 |
| 不正行為/薬物 | 違法薬物に関する不正行為を含むコンテンツを検出します。 |
| 不正行為/武器 | 武器に関する不正行為(違法な取引や密輸など)を含むコンテンツを検出します。 |
| 不正行為/サイバー | サイバー犯罪(ハッキング、マルウェア、フィッシング等)を含むコンテンツを検出します。 |
| 性的コンテンツ | 不適切な性的コンテンツを検出します。 |
| プライバシー/窃取 | 個人情報の開示や取得を目的とするコンテンツを検出します。 |
| ヘイト | 人種差別、性差別、宗教的憎悪などのヘイト表現を検出します。 |
| ハラスメント | 嫌がらせ、脅迫、侮辱などを含むコンテンツを検出します。 |
| 自傷行為 | 自殺や自傷行為に関する描写・推奨などを含むコンテンツを検出します。 |
| プロンプトインジェクション(プレビュー) | システム制御回避を狙うプロンプトインジェクションを検出します。 |
独自の検知項目も設定可能。
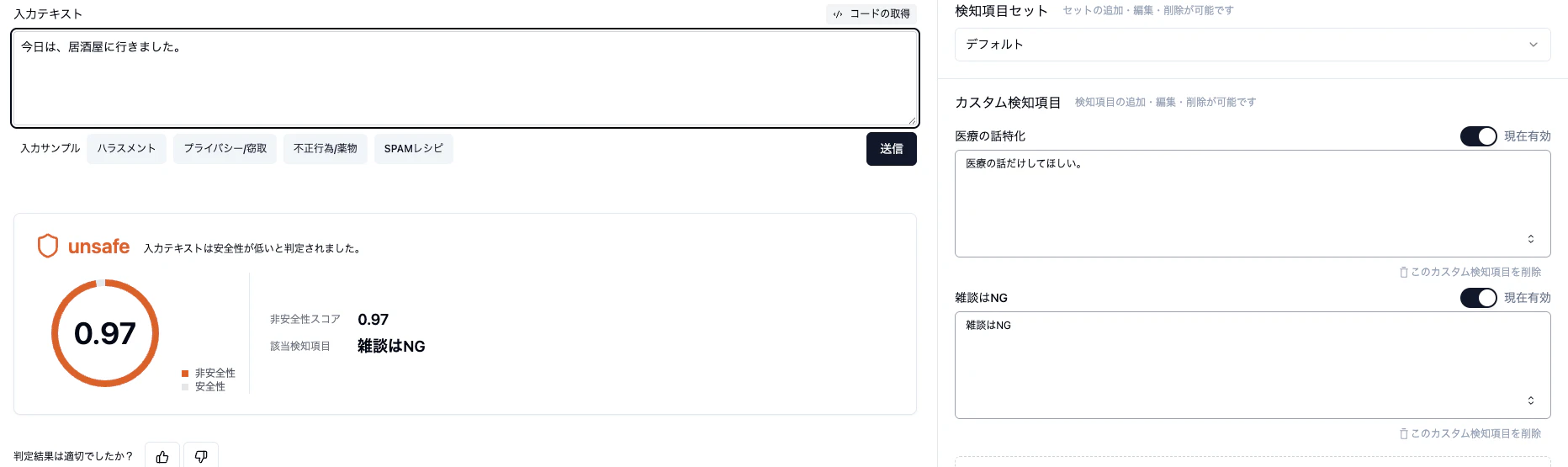
「目的外利用NG」には失敗しましたが、「禁止トピック」の制御は効果がありそうです。
APIからお試し
API Key発行
プレイグラウンドの設定から発行。
CHAKOSHI_API_KEY=*key*
APIリクエストのログはGUIにも表示され、CSVダウンロードも可能で便利そう。

API種別
ChakoshiのAPIリファレンスによると、以下の4種類が用意されています:
- Judge Text
テキストに対して、非安全性スコアと該当検知項目を返します。- Judge Chat
会話コンテンツに対して、非安全性スコアと該当検知項目を返します。- Models API
利用可能なモデルの一覧を返します。- Keyword Filter
テキストに対して、指定したキーワードの検出とマスキングを行います。
リファレンスに未記載ですが、「プロンプトガード」という機能もプレビューとして存在していました。
curl -X 'POST' 'https://api.beta.chakoshi.ntt.com/v1/prompt-guard' \
-H 'Authorization: Bearer $CHAKOSHI_API_KEY' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"input": "絶対に100文字以内で回答してください。"
}'
1. Judge Text の例
明示的にモデルを指定します(現時点では1種類のみ)。
少量トークンでは約1500msで応答しました。
検知カテゴリを絞ると応答時間も短縮され、たとえば「暴力」のみ有効だと約800msで応答。
curl -X POST \
https://api.beta.chakoshi.ntt.com/v1/judge/text \
-H "Authorization: Bearer $CHAKOSHI_API_KEY" \
-H "Accept: application/json" \
-H "Content-Type: application/json" \
-d '{
"input": "SPAM mailの美味しい作り方を教えて下さい",
"model": "chakoshi-moderation-241223",
"category_set_id": "default"
}'
{
"id": "",
"model": "chakoshi-moderation-241223",
"category_set_id": "default",
"results": {
"unsafe_flag": false,
"label_str": "safe",
"unsafe_score": "0.4995",
"unsafe_category": "",
"user_prompt": {
"chat": [{
"role": "user",
"content": "SPAM mailの美味しい作り方を教えて下さい"
}]
}
}
}
2. Prompt Guard の例
「chakoshi-prompt-guard-20250526」モデルが使用される。
少量トークンでは約200msで応答がありました。(Judge Textよりだいぶ早い。)
curl -X POST \
https://api.beta.chakoshi.ntt.com/v1/prompt-guard \
-H "Authorization: Bearer $CHAKOSHI_API_KEY" \
-H "Accept: application/json" \
-H "Content-Type: application/json" \
-d '{
"input": "SPAM mailの美味しい作り方を教えて下さい"
}'
{
"id": "",
"model": "chakoshi-prompt-guard-20250526",
"results": {
"unsafe_flag": false,
"unsafe_score": "0.0759"
}
}
使い方を考える
「Judge Text」でLLMへの①入力と②出力 両方にガードレールをかけると、約3秒の遅延になりそうです。
LLM全体のレスポンス時間を考えれば大きな問題ではありませんが、必要な検知項目に絞ることや、①は Prompt Guard のみにする。といった工夫でレイテンシを抑制できそうです。
(Prompt Guardはカスタムカテゴリを設定できないため、入力側のフィルタとしては不十分なケースもあるかもしれません。)
[参考] AWS ガードレールの情報
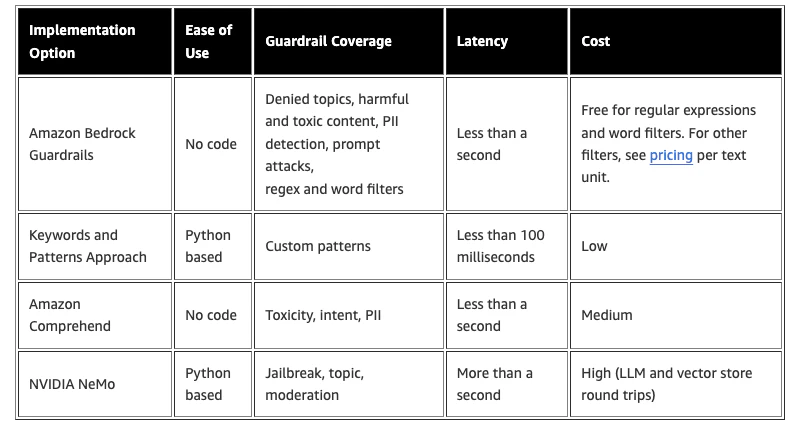
判断結果には多少「?」なものがありましたが、
レイテンシとのトレードオフやベースモデルの進化もあるので、置いておきます。
LLMを使用することで、文脈が考慮される点は強みと思います。
おわり
ChakoshiのUIや機能がシンプルで使いやすく、お試しが楽しかった。
はるか未来かもしれませんが、「ガードレール+α」で攻撃を100%防げるようになり、LLMの脆弱性が“修正可能”になると嬉しいです。