目次
- やったこと
- 環境・ツール
- 中身1:文章校正機能・文章中によく出てくる語彙&関連語の探し方
- 中身2:Streamlitでアプリを起動
- 中身3:Herokuでアプリをデプロイ
やったこと
- PythonとStreamlitを使って、文章校正アプリを作りました
- Herokuにアプリをデプロイしました
環境・ツール
環境
- macOS Ventura 13.3
- Python 3.9.13
- pyenv 2.3.9
- Poetry version 1.1.15
ツール
文章校正機能
- 文章を入力すると、問題のありそうな箇所を指摘してくれます。だいたい5万字(100KB)くらいまでのテキストならそれなりの速さで動いてくれます。
- 例えば以下のように、80文字以上の文章は長すぎるとして、赤いハイライトが入ります。
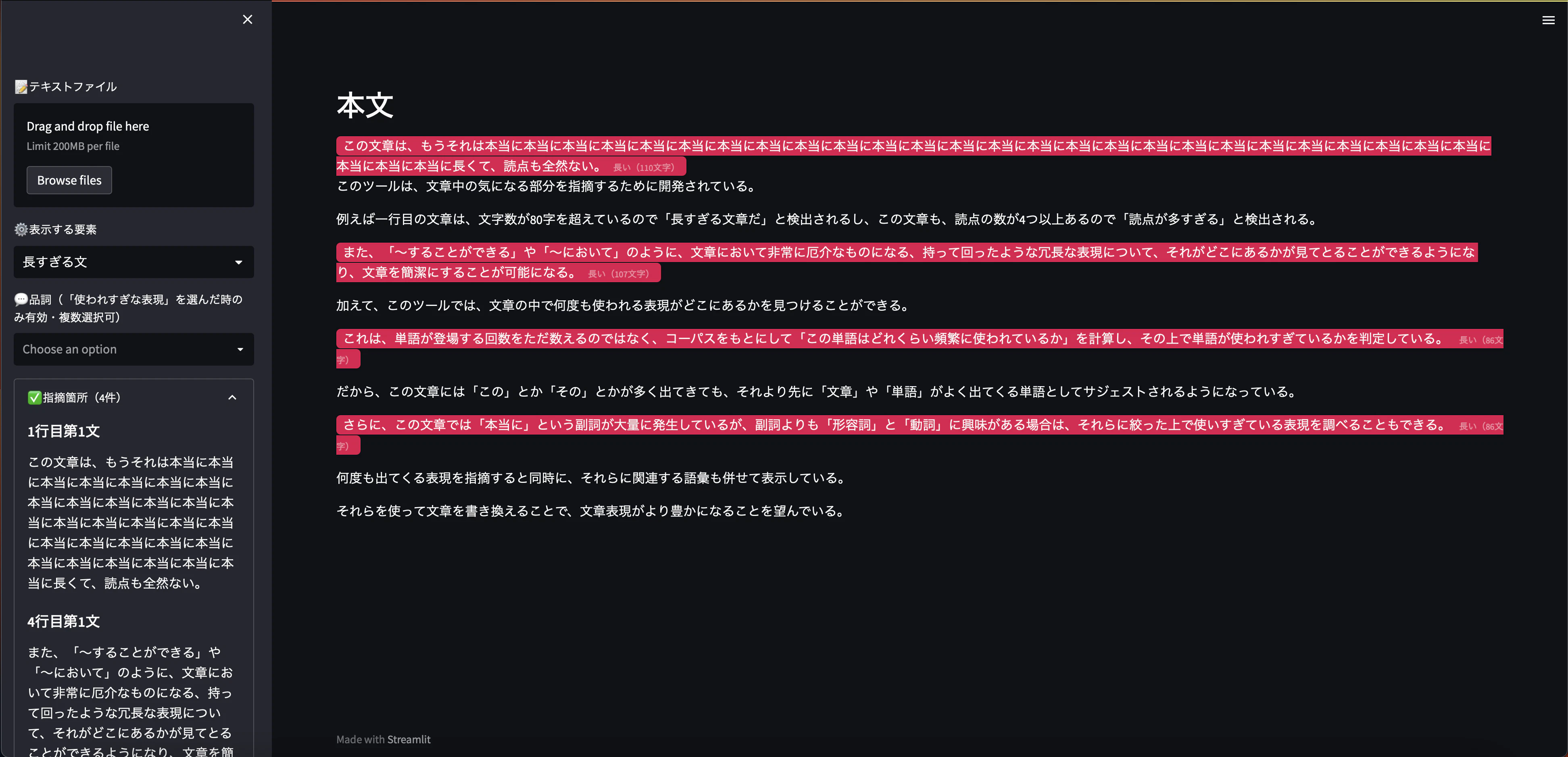
- 指摘する要素は、現在は以下の5つに対応しています
- 長すぎる文章(80文字以上の文章)
- 読点が多い文章(読点が4つ以上ある文章)
- 読点がない部分(読点なしで50文字以上続く部分)
- 冗長な表現(「〜という」や「〜することができる」といった、持って回ったような表現)
- 文章中によく出てくる語彙(上位20件)
- Wordnet & Word2Vecを利用して、関連語の候補のサジェストも行っています
文章中によく出てくる語彙&関連語の探し方
上記の5つのうち、文章中によく出てくる語彙をどのように判別しているか(+どのように関連語を探しているか)を説明します。大まかに以下のような流れになっています。
文章中によく出てくる語彙
- livedoorニュースコーパスから、ある語彙がどれくらい普遍的に使われているかをidfスコアという形で計算する。
- 校正対象の文章について、語彙の出現頻度をtfスコアという形で計算する。
- 1と2で計算したidfスコアとtfスコアを掛け合わせ、上位20件をサジェストする。
livedoorニュースコーパスには、およそ7000件のテキストファイルがあり、一つ一つが記事に相当しています。
idfスコアはその7000件の記事の中で「どれだけその語彙がレアか」を示すものであり、めったに見かけない(数件の記事にしか出てこないような)語彙は高くなり、「これ」や「この」などのよく見かける語彙は低くなります。
idfスコアはlivedoorニュースコーパスから計算されますが、tfスコアは「校正対象の文章の中でどれくらいよく出てくるか」を示します。
そのため、tfスコアとidfスコアを掛け合わせた値が高くなるのは、「一般的にはあまり見かけない|そこそこ見かける(=idfスコア中〜高)」けど、「校正対象の文章の中ではまあまあ出てくる(=tfスコア高)」という時になります。
例えば、SFモノであれば科学系の専門用語のスコアが高くなったり、料理に関連する話であれば料理関連の語彙のスコアが高くなり、それだけ目につきます。
関連語の探し方
- 頻出語彙を見出し語化する
- 日本語WordNetを使って、類義語を探す
- 事前訓練済みWord2Vecを使って、関連語を探す(コサイン類似度の上位10件)
本当は類義語だけを抽出できればよかったのですが、WordNetはいわゆる「犬スパイ問題※」があったり、Word2Vecも単語間の類似度が単純なコサイン類似度に依存しているので、「新島襄」とコサイン類似度が近いのは「同志社大学」や「内村鑑三」だったりするようなことが起こります。
今回は簡単のため、二つの手法で出てきた関連語をまとめて表示することにしました。
(※犬スパイ問題:WordNetが英語圏の概念に依存しているため、犬(dog)の類義語として密偵・スパイ(watchdog)関連の語彙が提示されてしまう問題)
Streamlitでアプリを起動
導入方法や使い方はググればいくらでも出てくるし、qiitaでもたくさん記事があると思うのでチュートリアル的なことはそちらに任せます。
ここでは、このアプリを使う時の流れを簡単に説明します。準備するべきもの(homebrew, pyenv, poetry)が何も入っていない状態を想定します。
環境の作り方(pyenv+poetry)は大体こちらのページを参考にしていただければうまくいくかと思います。
- homebrewを入れる(pyenvのインストールに必要)
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
-
poetryで指定するpythonのバーションを管理するために、pyenvを入れる(
$ brew install pyenv) -
pyenvを使って所望のPythonのバージョンを入れる(
$ pyenv install 3.x.x今回は3.9.13)-
No module named '_lzma'が出たら、$ brew install xzをしてから$ pyenv uninstall 3.x.x→pyenv install 3.x.x -
$ pyenv local 3.x.xとかやってみて、pythonのバージョンがsystem(デフォルト)から3.x.xに変わるかどうかを確かめる-
$ pyenv versionとした時は変わってるけど、コマンドラインでpython動かすとバージョンがデフォルトのまま変わってないみたいなケースがある その時は$ pyenv initをして、表示される指示に従って.zshrc(や、.bashrcなど)を書き換える - 引っかかってたのですがこちらを参考にして回避しました
-
-
-
pyenvで適切なpythonのバージョンを指定したのち、poetryのインストール(
$ pip install poetry)- The script xxx is installed in which is not on PATH. Consider adding this directory to PATH or, …と出てきたら、.zshrc(bashなら.bashrc)にexport PATH =“/Users/XXX/Library/Python/3.x/bin:$PATH”としてパスを通す。詳しくはこちら
-
$ poerty config virtualenvs.in-project trueをして.venv(仮想環境)が作られるようにしておく
-
必要なモジュールなどをインストールする(
$ poetry install --no-dev)- 使うPythonを前のステップでpoetryで指定されたバージョンにできていないと、[Errno 2] No such file or directory: ‘python3.x’とか怒られる
-
アプリを起動する(
$ poetry run streamlit run src/text_checker.py)
Herokuでアプリをデプロイ
初めて扱ったので、色々コケたりしたポイントをまとめておきます。
コケたポイント
- ✅ Heroku アカウント と Heroku CLIの準備が必要
- ⭐️ ないと何もできない
- 🛠️ アカウント登録 → やる
- 🛠️ Heroku CLI →
$ brew tap heroku/brew && brew install heroku
- ✅ クレカを登録する
- ⭐️ 登録してないとHeroku Createしたときに「クレカ登録しろ(To create an app, verify your account by adding payment information.)」と怒られる
- 🛠️自分のHerokuのページに行って設定する
- ✅ ビルドパック(どの言語を扱うか?)を設定する
- ⭐️ ないと(No default language could be detected for this app.)と怒られる
- 🛠️ 自分のHerokuのページに行って設定する
- 🛠️ もしくは、ターミナルで
$ heroku buildpacks:set heroku/pythonと打ち込む
- ✅ requirements.txt(サーバーがコードを実行するために何をダウンロードする必要があるかを認識させるもので)と、setup.sh(アプリがサーバー上で動作する環境を作るもの)を作る
- ⭐️ 作ってないとgit push heroku mainでコケる(App not compatible with buildpack: https://buildpack-registry.s3.amazonaws.com/buildpacks/heroku/python.tgz)と出る
- 🛠️ requirements.txtの作り方(poetry)→
$ poetry export -f requirements.txt --without-hashes --output requirements.txt - 🛠️ setup.shの作り方 → 色々なところにあるやつ参考にすれば基本的にOK。例えばこれ
- ✅ Procfile(サーバーがどういったコマンドで実行すればいいかを記述するもの)を作る
- ⭐️ 作ってないと(code=H14 desc="No web processes running")が出る
- 🛠️ ウェブアプリであれば、
web: sh setup.sh && streamlit run [実行ファイル].pyとすれば良い
- ✅ 課金する
- ⭐️ メモリが足りないと**Error R14 (Memory quota exceeded)**が出る
- ⭐️アプリを動かすのにメモリが1GB必要でデフォルトだと足りず、1GBのメモリを確保してくれる月額最大$50のプランにする
- 🛠️ Herokuのページに行き、アプリのOverview > Configure Dynos > Change Dyno Typeで適当なものを選ぶ
- ⭐️ メモリが足りないと**Error R14 (Memory quota exceeded)**が出る
アプリを作った上で、Herokuでアプリを立ち上げたり落としたりする流れ
- アカウントとCLIのセットアップ
- アプリのディレクトリ(いつもGitで管理しているディレクトリ)に移動
$ heroku login- クレカの設定
- heroku create
- Creating app... done と出るのを確認する
- ビルドパックの設定
- requirements.txtの作成
- setup.shの作成
- Procfileの作成
-
$ git push heroku main(Herokuサーバーにプッシュ) - URLコピペしてアプリに接続
- Metrixから使用しているメモリの情報などを得て、Dynoタイプを変える
- アプリを終了するときは、Resourcesから鉛筆マーク✏️を押し、dynoの使用料を0とかにする
- こうなってる(0dynosになってる)ことを確認する

- こうなってる(0dynosになってる)ことを確認する