はじめに
RetailAI Advent Calendar 2023 の 23日目の記事です!
こんにちは、RetailAIの@long10langです。
先日、googleさんよりgeminiが登場して、マルチモダールモデルの実力に驚きを隠せない今日のこの頃ですが、一方で、プロンプトエンジニアリングの進歩も目を見張るものがあります。
MMLUの評価で、Gemini Ultraに対して、MedPromptを駆使して匹敵する実力を発揮したという成果も報告されており、今後ますますエンジニアリングによる工夫が開発されていくんだろうと感じます。
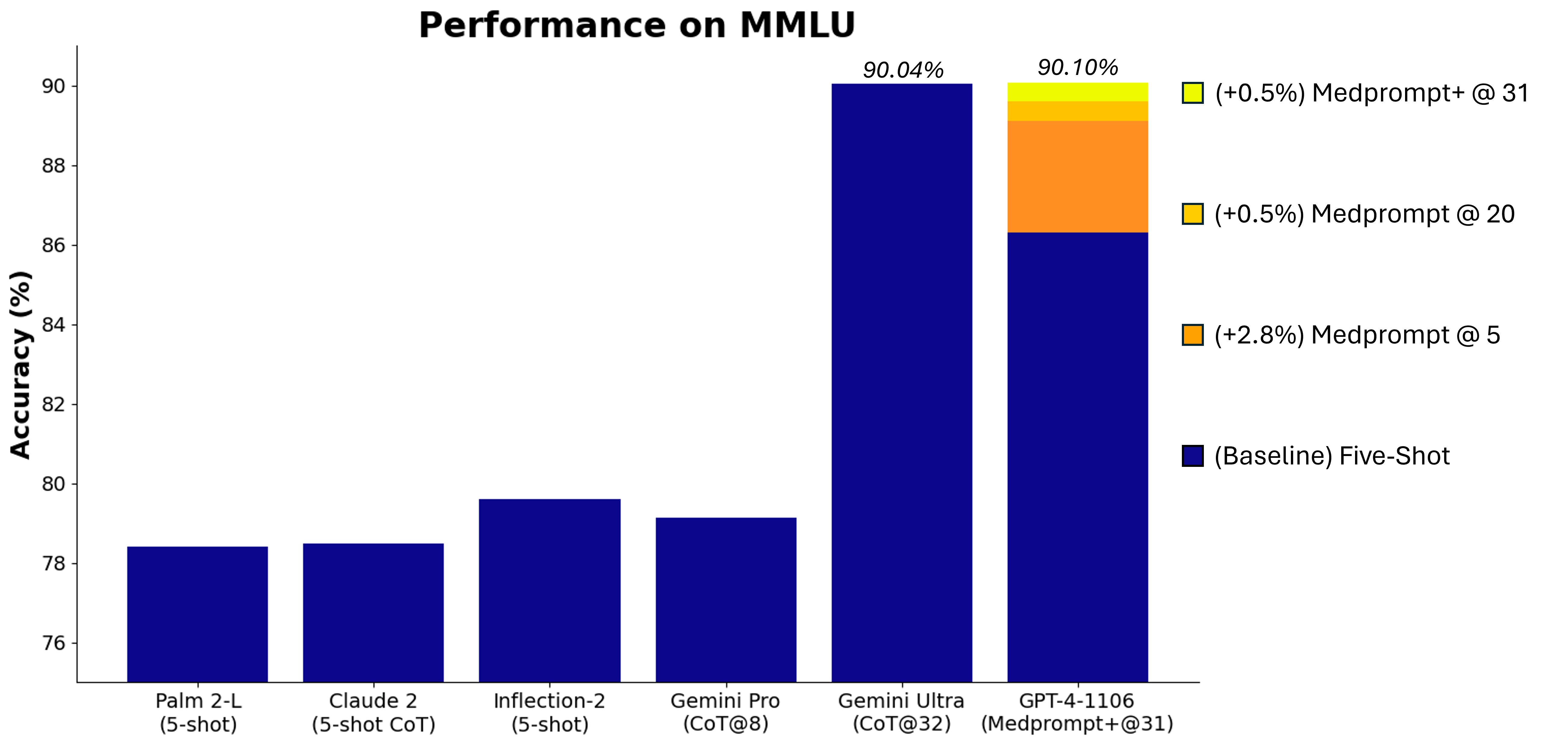
今日は、論文を紐解くというよりは、promptbaseのプログラミングを眺めていくことで、おお、これがこれから必要になるプログラミングなのかと、一緒に体感していただければというのが趣旨となっております。
目次
promptbaseとは
promptbaseは、GPT-4のような基礎モデルから最高のパフォーマンスを引き出すためのベストプラクティスとして、プロントを含むスクリプトの進化させたコレクションになります。医療課題に対して、基礎モデルを最大限に有効活用するMedpromptを拡張して考えられたスクリプトコレクションになります。
↓このように、効果が実証されているとのこと。
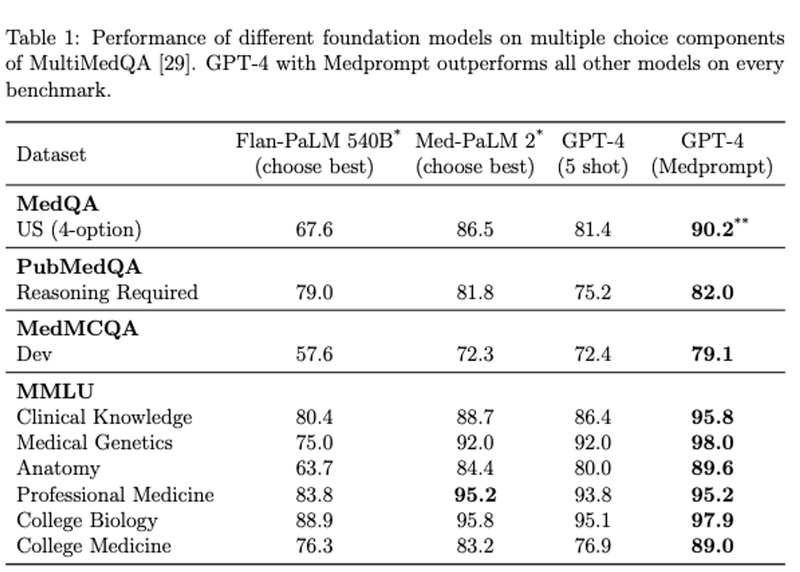
ざっくりと説明すると、①フューショット学習を動的におこなう、②自己生成のCoT(思考連鎖)、③多数決アンサンブルを1つのスクリプトで連携することで、性能を発揮させる手法をとっています。
① 動的な少数ショットでは、基礎モデルに対するタスクと応答の例をいくつか提供することになります。具体的には、埋め込み空間で k-NN クラスタリングを使用して意味的に類似した k 個のトレーニング例を選択するなど、いくつかの手法があります。
例えば、OpenAI のモデルを使用して、フューショット学習用の候補のサンプルを埋め込みます。次に、各テスト質問 x について、近傍する値 を取得します。これらの例 (埋め込みスペースがテスト問題に最も類似しているもの) は、最終的にプロンプトに登録されます。
② 自己生成の思考連鎖 (CoT) は、思考連鎖 (CoT) は、ステップバイステップで推論することによってモデルが一連の中間推論ステップを生成することを明示的に促します。このアプローチによって、基礎モデルが複雑な推論を実行する能力が大幅に向上することがわかっています。ま、要するに、質問者が簡単な質問リストを用意して、回答者が曖昧に感じることが少ないように工夫するということです。
③ 多数決アンサンブルは、複数のアルゴリズムの出力を組み合わせて、個々のアルゴリズムよりも優れた予測パフォーマンスを生み出すことを指します。各推論パスを生成する前に、回答選択肢の相対的な順序をシャッフルすることで得られる最も一貫した回答、つまり選択肢のシャッフルの影響を最も受けにくい回答を選択できます。
↓図にするとこんな感じらしい。
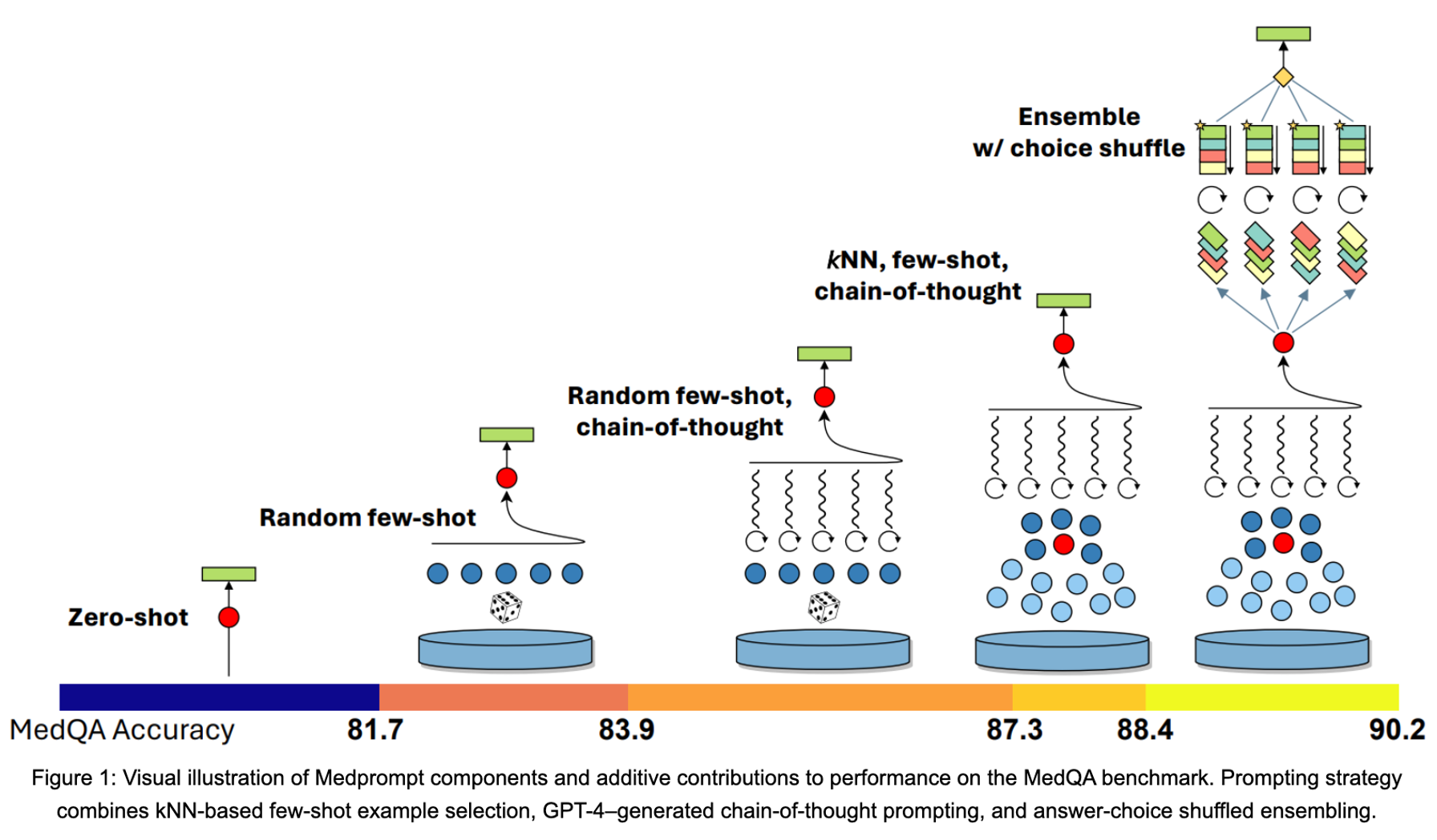
文章で、わちゃわちゃ言っても分かりにくいですので、promptbaseの中から例を一つとってきて、眺めてみましょう。
ちょっと眺めてみよう
promptbaseリポジトリにある、src/promptbase/mmlu/prompt_templates.py をみてみます。0shotプロンプトとして、このようなプロンプト形式を指定しています。
logprobs_0shots = {
"prompt_name": "logprobs_0shots",
"response_type": "logprobs",
"prompt": Template("""## Question
{{ question }}
## Task
Answer the above question with only 1 letter (such as A)
## Answer
""")
}
さらに5shotsだとこんな感じの形式が用意されています。
logprobs_5shots = {
"prompt_name": "logprobs_5shots",
"response_type": "logprobs",
"prompt": Template("""{% for item in examples %}## Question
{{ item.question }}
## Answer
{{ item.answer }}
{% endfor %}## Question
{{ question }}
## Answer
"""),
"examples": [{"question": """A 6-year-old girl is brought to the emergency department because of right elbow swelling and pain 30 minutes after falling onto her outstretched right arm. She has been unable to move her right elbow since the fall. Physical examination shows bruising, swelling, and tenderness of the right elbow; range of motion is limited by pain. An x-ray of the right arm shows a supracondylar fracture of the humerus with anterior displacement of the proximal fragment. Further evaluation is most likely to show which of the following findings?
A. Absent distal radial pulse
B. Radial deviation of the wrist
C. Inability to abduct shoulder
D. Inability to flex the elbow
""", "answer": "A"
}, {"question": """Two weeks after undergoing low anterior resection for rectal cancer, a 52-year-old man comes to the physician because of swelling in both feet. He has not had any fever, chills, or shortness of breath. His temperature is 36°C (96.8°F) and pulse is 88/min. Physical examination shows a normal thyroid and no jugular venous distention. Examination of the lower extremities shows bilateral non-pitting edema that extends from the feet to the lower thigh, with deep flexion creases. His skin is warm and dry, and there is no erythema or rash. Microscopic examination of the interstitial space in this patient's lower extremities would be most likely to show the presence of which of the following?
A. Acellular, protein-poor fluid
B. Lymphocytic, hemosiderin-rich fluid
C. Lipid-rich, protein-rich fluid
D. Protein-rich, glycosaminoglycan-rich fluid
""", "answer": "C"
}, {"question": """A 34-year-old gravida 2, para 1 woman at 37+6 weeks of gestation presents for elective cesarean delivery. She says she has been having increased fatigue over the past few weeks. Past medical history includes gestational hypertension for which she has been taking an antihypertensive drug twice daily since week 24. Her vital signs include: temperature 36.7°C (98.0°F), blood pressure 120/75 mm Hg, pulse 127/min. Physical examination reveals generalized pallor. Her laboratory results reveal microcytic, hypochromic anemia with anisocytosis, hemoglobin of 9 g/dL, a differential with 14% lymphocytes, an ESR of 22 mm/hr, and a reticulocyte production index of 3.1. A direct antiglobulin test is positive. LFTs, creatinine, ferritin level, vitamin B12 level, coagulation studies, and urinalysis are normal. Which of the following is the most likely diagnosis in this patient?
A. Preeclampsia
B. Hereditary spherocytosis
C. HELLP syndrome
D. Drug-induced immune hemolytic reaction
""", "answer": "D"
}, {"question": """You are counseling a pregnant woman who plans to breast-feed exclusively regarding her newborn's nutritional requirements. The child was born at home and the mother only plans for her newborn to receive vaccinations but no other routine medical care. Which vitamins should be given to the newborn?
A. Folic acid
B. Vitamin K
C. Vitamin D
D. Vitamin K and Vitamin D
""", "answer": "D"
}, {"question": """An investigator is studying nutritional deficiencies in humans. A group of healthy volunteers are started on a diet deficient in pantothenic acid. After 4 weeks, several of the volunteers develop irritability, abdominal cramps, and burning paresthesias of their feet. These symptoms are fully reversed after reintroduction of pantothenic acid to their diet. The function of which of the following enzymes was most likely impaired in the volunteers during the study?
A. Methionine synthase
B. Alpha-ketoglutarate dehydrogenase
C. Glutathione reductase
D. Dopamine beta-hydroxylase
""", "answer": "B"
}]
}
この他にも、いろいろなパターンのプロンプト形式があらかじめテンプレートとして用意されています。
次に、同じフォルダにある、src/promptbase/mmlu/problem_utils.py を覗いてみます。いろいろと関数があるのですが、こちらの関数に注目してみたいと思います。
こちらの関数の中では、modeが、random か knn か svm を選択して、上の① 動的な少数ショットを実現しています。埋め込みベクトルに対して、動的な操作を行うことによって、より求めている結果に近い形のCoTを実現しようとしています。
########################################
# Parse related functions
########################################
def select_examples(problem, examples, mode, options):
selected = []
num_examples = options.get("num_examples", 5)
if mode == "random":
if "problems" in examples:
examples = examples["problems"]
problems = random.sample(examples, num_examples)
for problem in problems:
if "solution" in problem:
solution = random.choice(problem["solution"])
elif "question" in problem and "answer" in problem:
solution = problem
else:
raise "Wrong format"
selected.append({"question": solution["question"], "answer": solution["answer"]})
elif mode == "knn":
problem_embedding = options["problem_embedding"]
examples_tensor = examples['tensor']
examples = examples['problems']
# Then, compute the cosine similarity for each data tensor with respect to the target
cosine_similarities = F.cosine_similarity(examples_tensor, problem_embedding, dim=1)
# Store the cosine similarity scores along with the corresponding indices
cosine_similarity_scores = [(i, cosine_similarity.item()) for i, cosine_similarity in enumerate(cosine_similarities)]
# Remove identical examples
cosine_similarity_scores = [item for item in cosine_similarity_scores if problem['question'] not in examples[item[0]]['question']]
# Sort the scores in descending order
cosine_similarity_scores.sort(key=lambda x: x[1], reverse=True)
# Add noise to the scores to get different ordering each time
noise_level = (cosine_similarity_scores[0][1] - cosine_similarity_scores[5][1]) * options.get("noise_multipler", 0)
cosine_similarity_scores = [(item[0], item[1] + random.gauss(0, noise_level)) for item in cosine_similarity_scores]
# Sort the scores in descending order
cosine_similarity_scores.sort(key=lambda x: x[1], reverse=True)
# Select the top k scores
top_k_scores = cosine_similarity_scores[:num_examples]
top_k_scores = top_k_scores[::-1] # invert the order of the samples so that the most relevant is the most 'recent'
# Print the top k cosine similarity scores
for index, score in top_k_scores:
solution = random.choice(examples[index]["solution"])
selected.append({"question": solution["question"], "answer": solution["answer"]})
elif mode.lower() == "svm":
problem_embedding = options["problem_embedding"]
examples_tensor = examples['tensor']
examples = examples['problems']
C = options.get("C", 0.001)
X = np.concatenate([problem_embedding.cpu().numpy(), examples_tensor.cpu().numpy()])
y = np.concatenate([np.array([1]), np.array([0]*len(examples_tensor))])
clf = LinearSVC(class_weight='balanced', verbose=False, max_iter=30000, tol=1e-6, C=C)
clf.fit(X, y)
similarities = clf.decision_function(X)
# Add noise to the scores to get different ordering each time
sorted_similarities = np.sort(similarities)[::-1]
noise_level = (sorted_similarities[0] - sorted_similarities[5]) * options.get("noise_multipler", 0)
similarities += noise_level * np.random.rand(*similarities.shape)
# Select the top k scores
indices = np.argsort(-similarities)[:num_examples+1][1:] -1
indices = indices.tolist()[::-1] # invert the order of the samples so that the most relevant is the most 'recent'
# Print the top k
for index in indices:
solution = random.choice(examples[index]["solution"])
selected.append({"question": solution["question"], "answer": solution["answer"]})
else:
raise "Unsupported method."
return selected
他にも、コレクションはたくさんあるので、ちょいちょい参考にさせてもらいながら、自分たちの目的に合った形にカスタマイズしていきたいと思います。
まとめ
いかがでしたでしょうか?promptエンジニアが捗ると、プログラミングコードに、自然言語が普通に介入してきて面白いですね。でも、デバッグしたり、リファクタリング?したりしようとしても、同梱されたプロンプトを1ワード変更しただけで、結果が異なるようになってしまうのは、大変困りますね・・・。
そこで、埋め込みベクトルの扱い(評価、世代管理など)や、MMLUだけではない評価手法を模索していく必要があるなぁと改めて感じた次第です!
参考文献
こちらは、弊社社長の永田洋幸が書いた書籍です!CoTの実用方法などにも詳しく触れています。よかったらご参考にしてください。
