本記事の目的
本記事では、IBM Cloud上で提供される Cloud Pak for Data as a Service を対象に、
Watson Studio および Machine learning サービスを使用した Federated Learning 機能を、Watson StudioのUIから利用する方法をご紹介します。
1. Federated Learning とは
さまざまな場所に存在するデータを直接共有することなく、共同でモデルをトレーニングするための手法です。
一般に、モデルの汎化性能を高めるために、十分な質と量のデータを確保することが重要です。
しかし、個々の組織だけでは、限られた質・量のデータしか保有していないユースケースがあります。
1つの解決策として、複数の組織が協業し、保有するデータを集め、1つのモデルをトレーニングする方法が考えらえます。
一方で、対象データの機密性が高い場合、複数の組織間でのデータそのものを移動したり共有したりすることは困難です。
このような場面で、Federated Learning が有用な可能性があります。
Federated Learningでは、データそのものではなく、データから学習した結果を集め、1つのモデルに統合します。
各組織は自環境で、保有データを使ってモデルをトレーニングし、結果のみを統合機能へ送信します。
統合機能は 集められた各組織のトレーニング結果を使用し、1つのモデルへ統合します。
このように、データそのものを共有することなく、共同でモデルを開発することができます。
2. CP4DaaS の Federated Learning 概要
Cloud Pak for Data as a Serviceでは、Federated Learningの機能を提供しています。
2021年11月に 一般提供が開始されており、Production用途での利用が可能です。
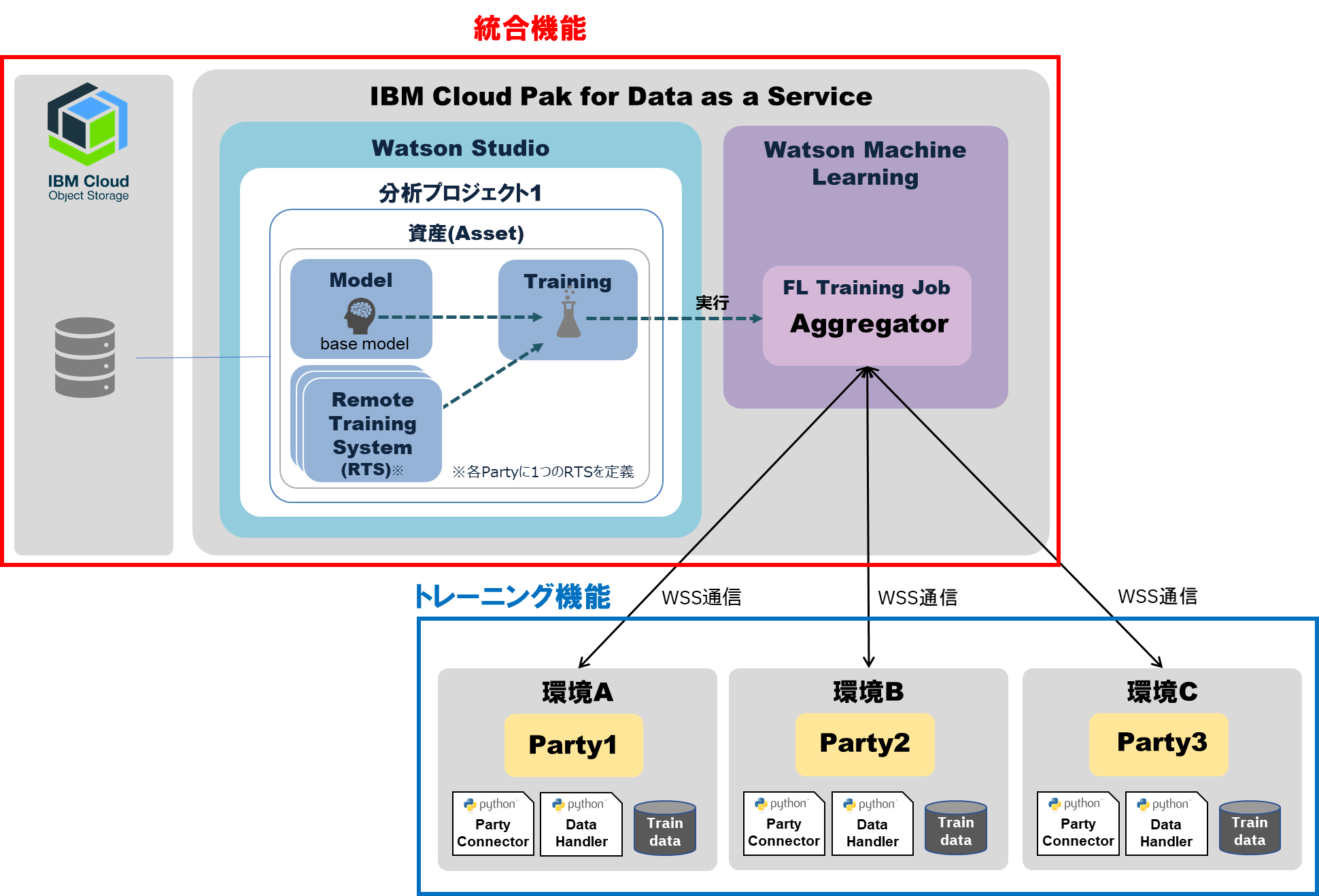
学習の仕組み
大きく「統合機能」 と「トレーニング機能」 の2つに分かれており、両者はWSSプロトコルを使用して通信します。
下記に概要を示します。
| 機能 | CP4DaaSにおける名称 | 実行環境 | 説明 |
|---|---|---|---|
| 統合機能 | Aggregator | Watson Machine Learning | Partyから集められたローカル・モデルを基に、共通モデルへの統合を実施 |
| トレーニング機能 | Party | 任意※ | トレーニング参加者が保有するデータを使ってモデルをトレーニングし、結果をaggregatorへ送信 |
※トレーニング機能を実行する環境は、指定バージョンのPython および Pythonライブラリ ibm-watson-machine-learning を導入済みで かつ aggregator と通信可能であれば、任意の環境を使用可能です。
IaaS環境、SaaS の Jupyter Notebook環境、PC等、いずれの環境でも動作します。
2022/7/21 追記
Partyの実行環境について製品資料が更新されていました。
サポートされるOSは以下となります。現状、Windowsは未サポートのためご注意ください。
Supported environments
Linux
Mac OS/Unix
(詳細)Party hardware and software requirements
https://dataplatform.cloud.ibm.com/docs/content/wsj/analyze-data/fl-setup.html?audience=wdp&locale=en
「統合機能(aggregator)」 と 「トレーニング機能(Party)」は、具体的には、複数のコンポーネントによって構成されます。
| 機能 | コンポーネント | 説明 | 作成方法 |
|---|---|---|---|
| Aggregator | Training | モデルのトレーニング情報を定義 | Watson Machine Learningに登録 |
| Remote Training System(RTS) | モデルのトレーニング参加者を定義。Trainingから参照する形で使用。 | Watson Machine Learningに登録 | |
| Base Model | 未トレーニングのモデル定義。XGBoost以外のフレームワークで必要。 | Watson Machine Learningに登録 | |
| Party | Party Connector | Aggregatorと通信し、自環境でモデルのトレーニングを実行するための処理を定義したファイル。トレーニング参加者はこのファイルを実行する。 | Pythonファイル |
| Data Handler | モデルのトレーニングに使用する学習用データの処理方法を定義したPythonのクラス。Party Connectorから参照する形で使用。 | Pythonファイル | |
| 学習用データ | モデルのトレーニングに使用するデータ。Data Handlerから参照する形で使用。データの保有者が自環境へ準備。 | csvファイルや画像ファイル等 |
- アーキテクチャ
サポートされるフレームワーク
2022年4月時点では、下記のフレームワークおよび手法サポートされています。
最新情報につきましては、製品資料をご確認ください。
| 手法 | フレームワーク |
|---|---|
| 回帰 | Scikit-Learn Regression, XGBoost Regression, Tensorflow2, Pytorch |
| 分類 | Scikit-Learn Crassification, XGBoost Crassification, Tensorflow2, Pytorch |
| クラスタリング | Scikit-Learn K-Means |
製品資料:Choosing your framework, fusion method, and hyperparameters
3. CP4DaaS の Federated Learning を動かす
製品資料のチュートリアル一覧には UI版とAPI版のシナリオがあります。
本記事では、XGBoost の UI版チュートリアルに沿ってFederated Learning を動かします。
Federated Learning XGBoost tutorial for UI
https://dataplatform.cloud.ibm.com/docs/content/wsj/analyze-data/fl-xg-tutorial.html?audience=wdp&locale=en
チュートリアル・シナリオにおいて、統合機能の設定を行う人を管理者、データの保有者であり自環境でトレーニングを実行する人をトレーニング参加者とします。
管理者とトレーニング参加者は兼任可能です。
UI版のチュートリアルでは、管理者が Watson Studio のUIを使って 統合機能(aggregator)を作成します。
トレーニング参加者は、自環境からPartyを実行し、トレーニングに参加します。
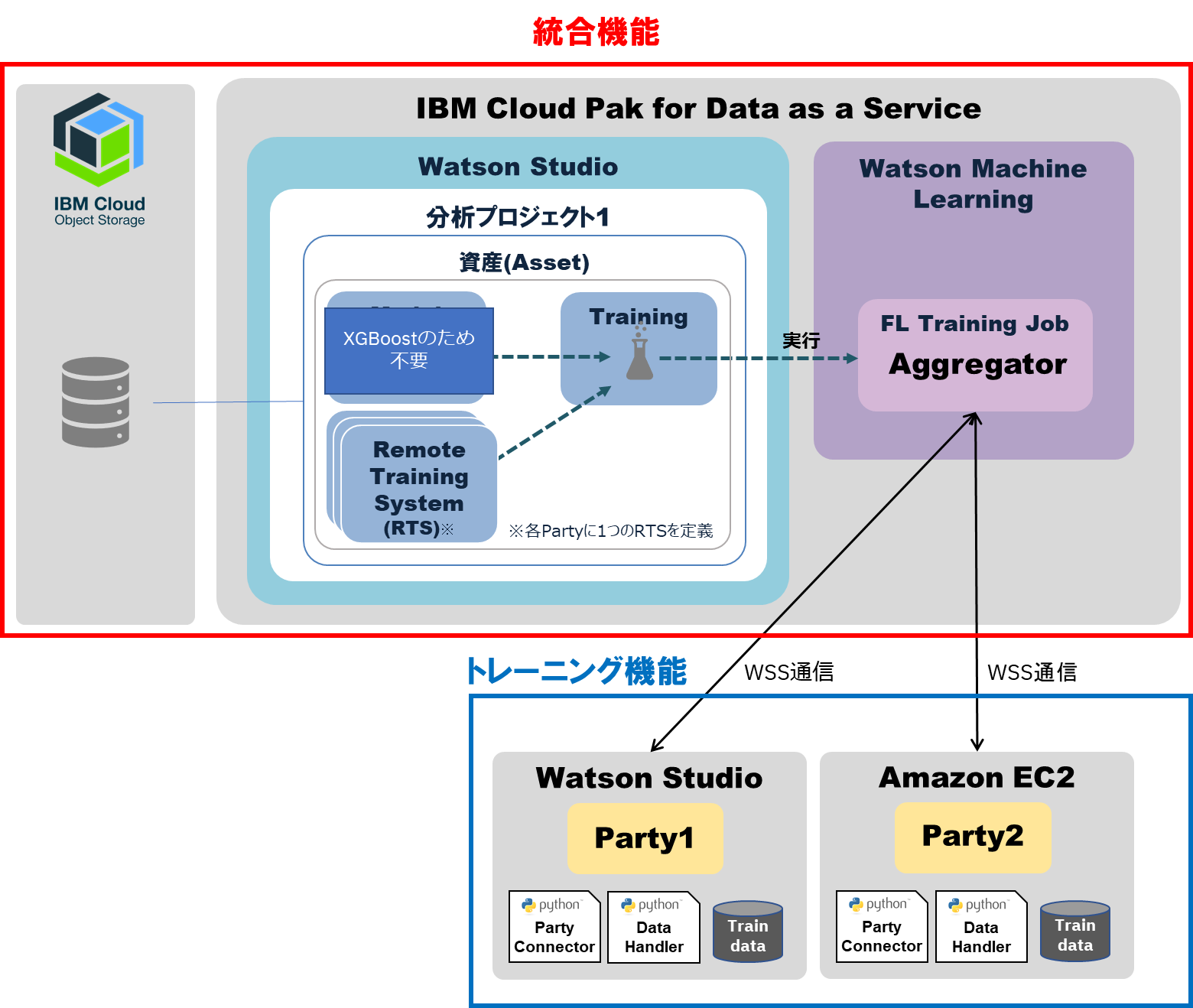
本記事ではトレーニング実行環境として、下記の2パターンを使用します。
| 実行環境 | 詳細 |
|---|---|
| SaaS の Jupyter Notebook | Watson Studio の Notebook |
| IaaS | Amazon EC2 へ Pythonを導入 |
- 本記事の構成
管理者の作業
チュートリアル Step 1 の手順に沿って作業を実施します。
Step 1: Start Federated Learning as the admin
https://dataplatform.cloud.ibm.com/docs/content/wsj/analyze-data/fl-xg-tutorial.html?audience=wdp&locale=en#step-1
開始の前に
-
もし持っていない場合、IBM Cloudアカウントを作成します。
無料のIBM Cloudアカウントを作成
https://www.ibm.com/jp-ja/cloud/free -
Federated Learningに使用するサービスを作成します。
3サービス全て、無料で機能を試せるLiteプランに対応しています。
本記事では、ダラス(us-south)へ作成したものを使用します。- Watson Machine learning
- Watson Studio
- IBM Cloud Object Storage
-
IBM Cloudアカウントへ、Federated Learning用のユーザーを追加します。
オリジナルのチュートリアルでは、1ユーザーで管理者とトレーニング参加者を兼務する手順となっていますが、本記事では、複数のトレーニング参加者でFederated Learningを動かすため、下記の2ユーザーを使用します。
役割 ユーザー名 管理者 兼 トレーニング参加者 FL管理者1 トレーニング参加者 テストユーザー1 -
管理者ユーザーにて、Watson Studioへログインします。
-
既存のプロジェクトを使用するか、新しいプロジェクトを作成します。
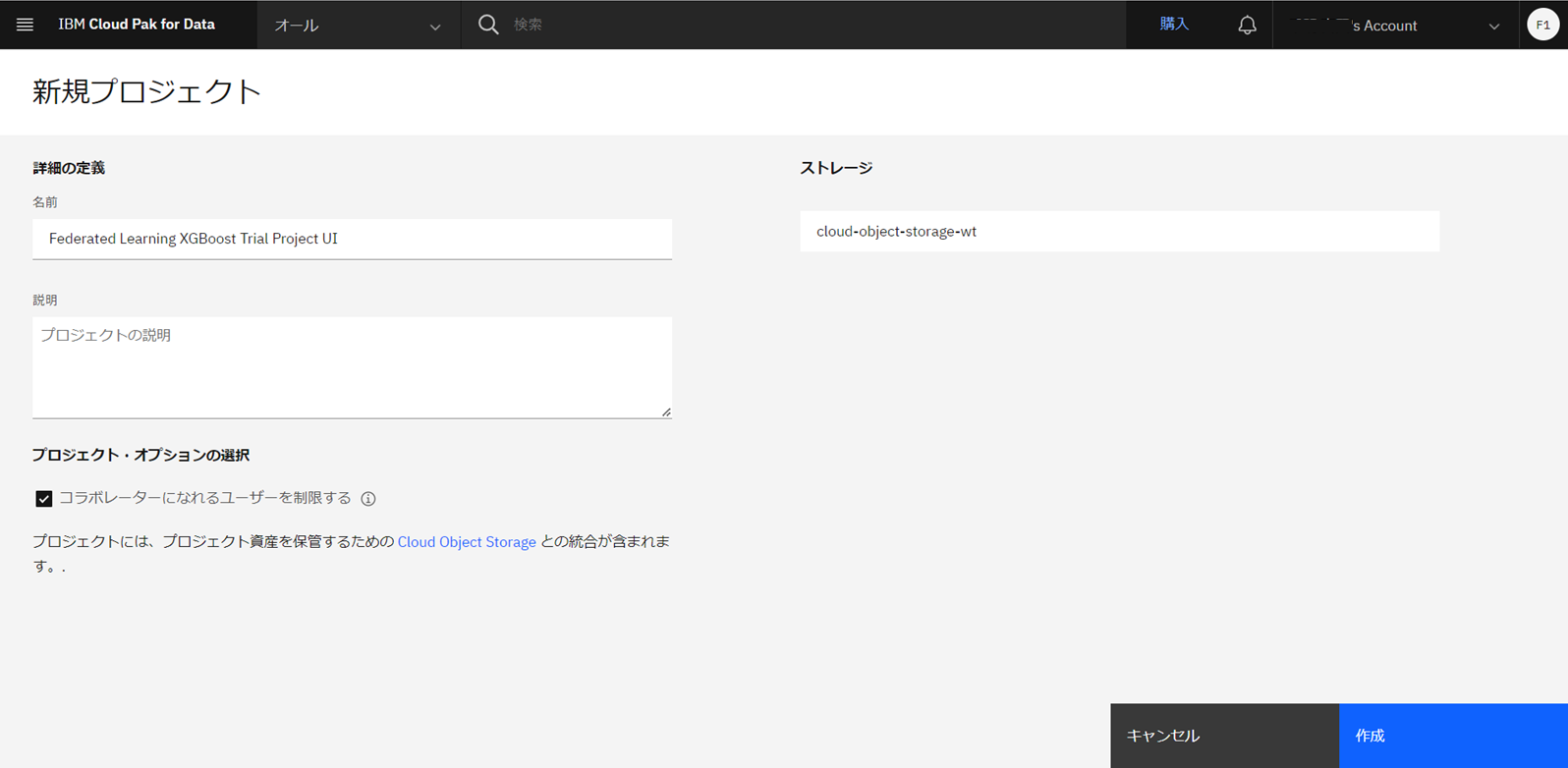
本記事では、新しいプロジェクトを作成します。「空のプロジェクトを作成」を選択し、任意の名前でプロジェクトを作成します。
-
プロジェクトの「管理」ページより、「サービスおよび統合」>「サービスの関連付け」より、作成済みのWatson Machine Learningサービスを関連付けます。
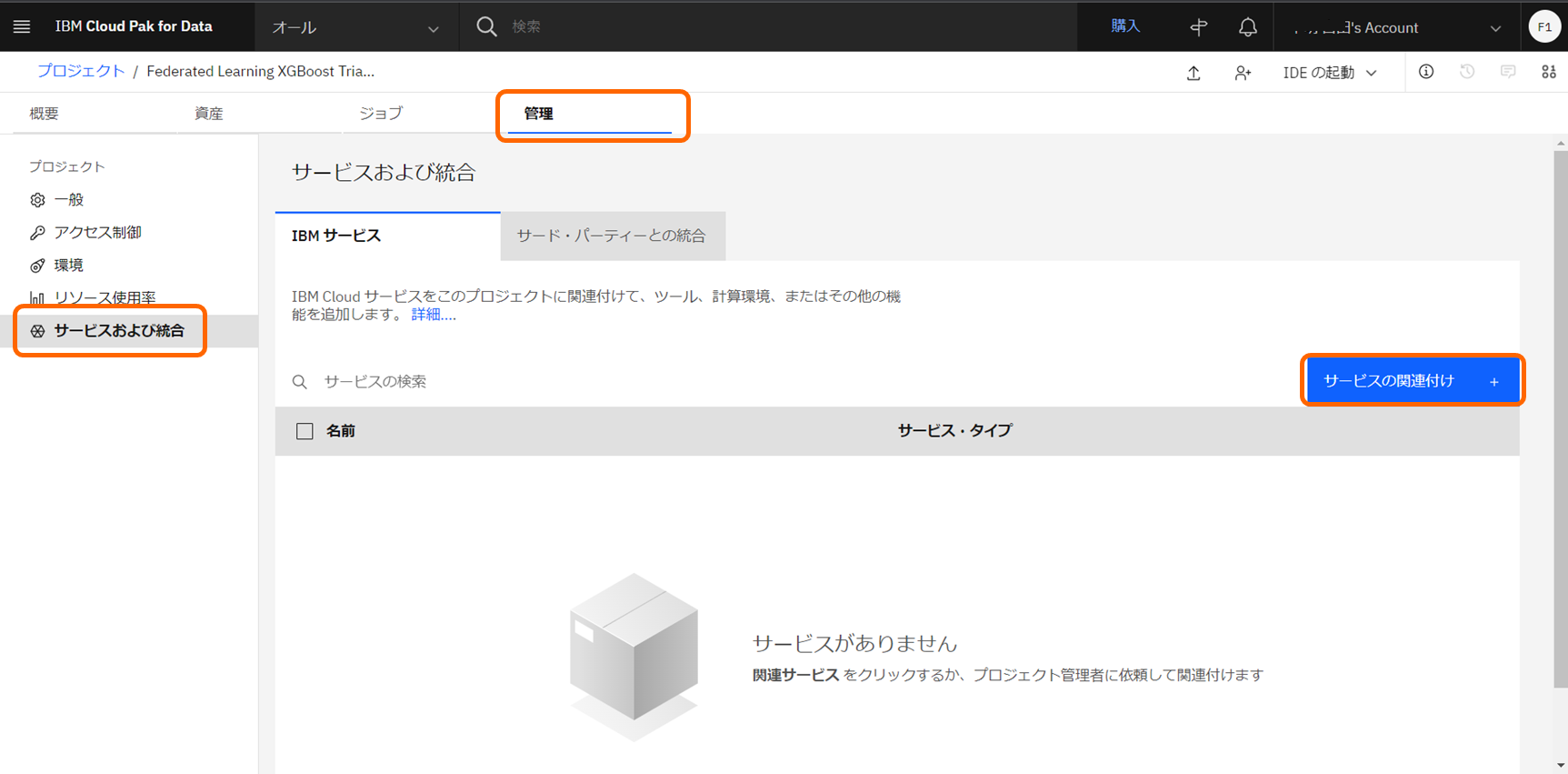
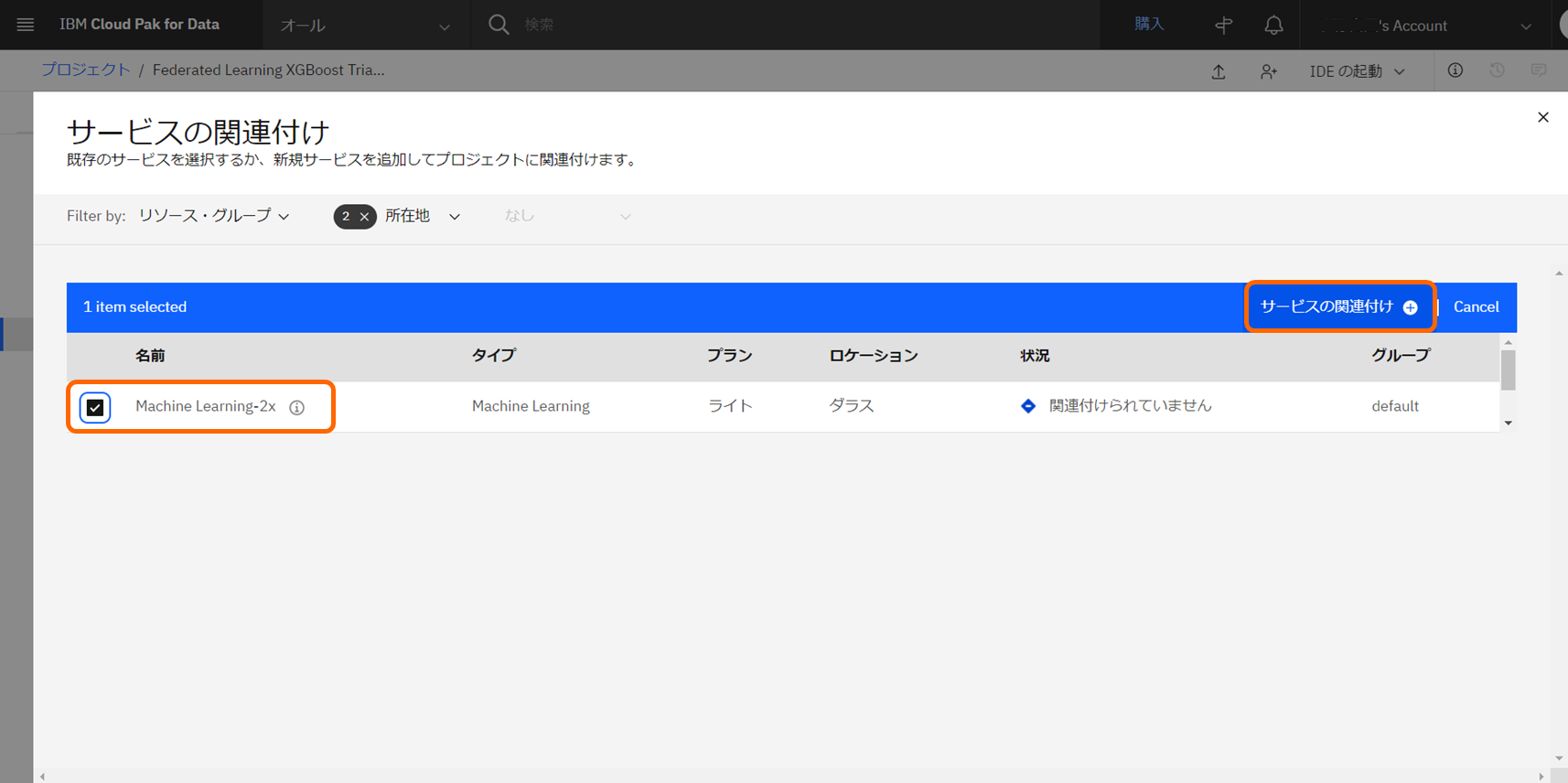
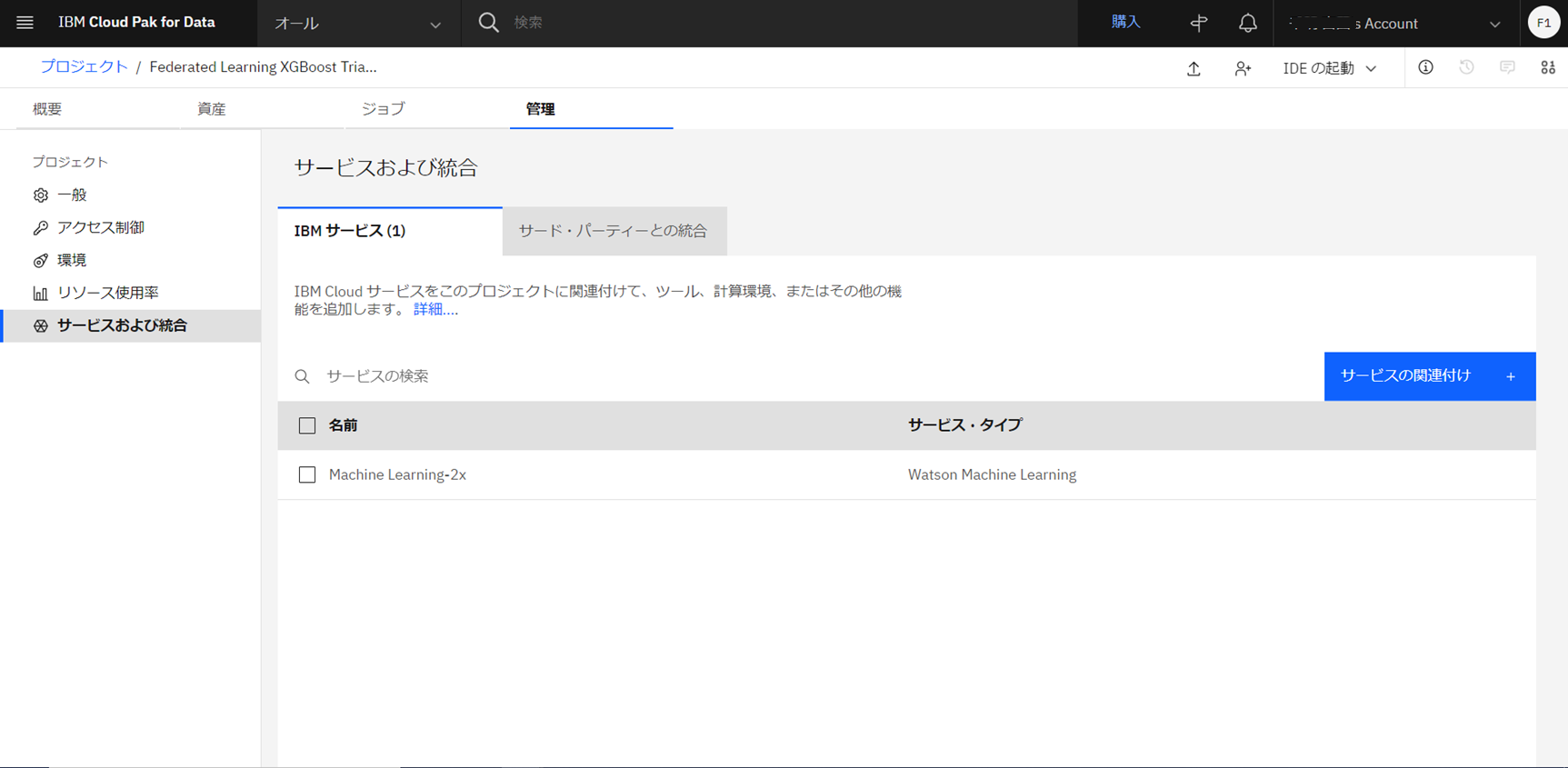
-
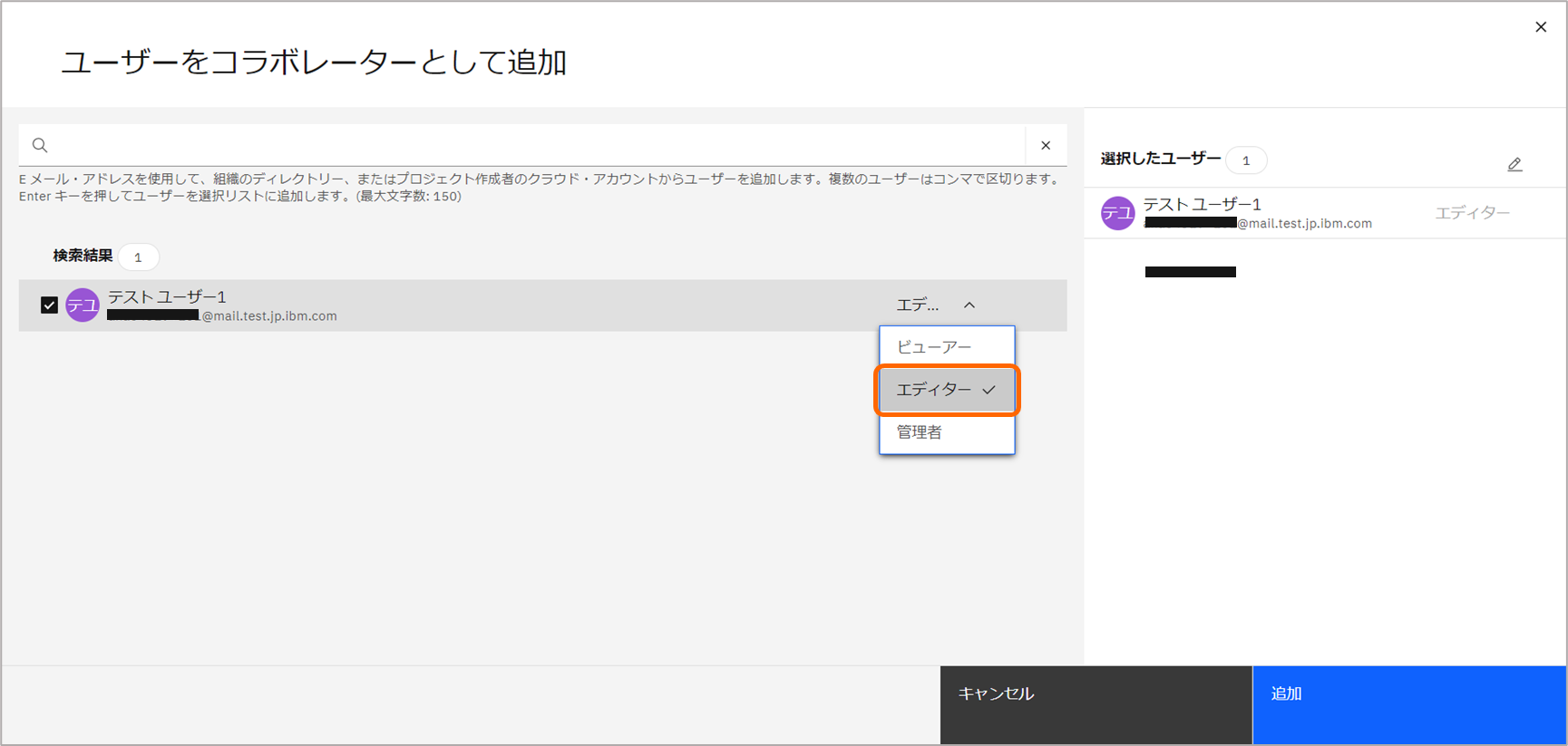
プロジェクトのコラボレータとして、トレーニング参加者を追加し、編集者ロールを付与します。
Federated Learningのトレーニング参加者は、プロジェクトでエディター権限が必要です。
「アクセス制御」>「コラボレータの招待」>「ユーザーの招待」と進み、テストユーザー1をエディター権限を付与し、追加します。
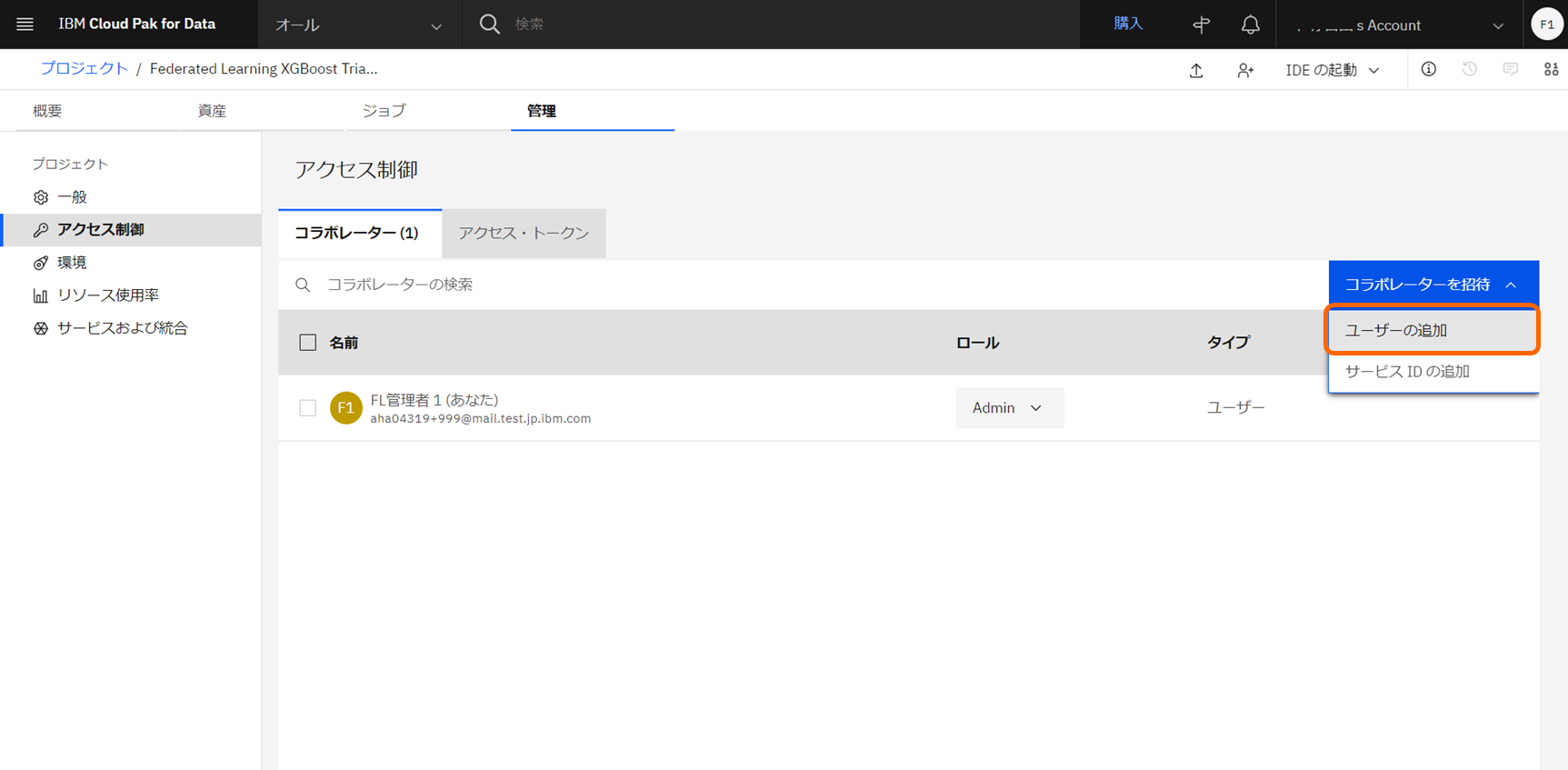
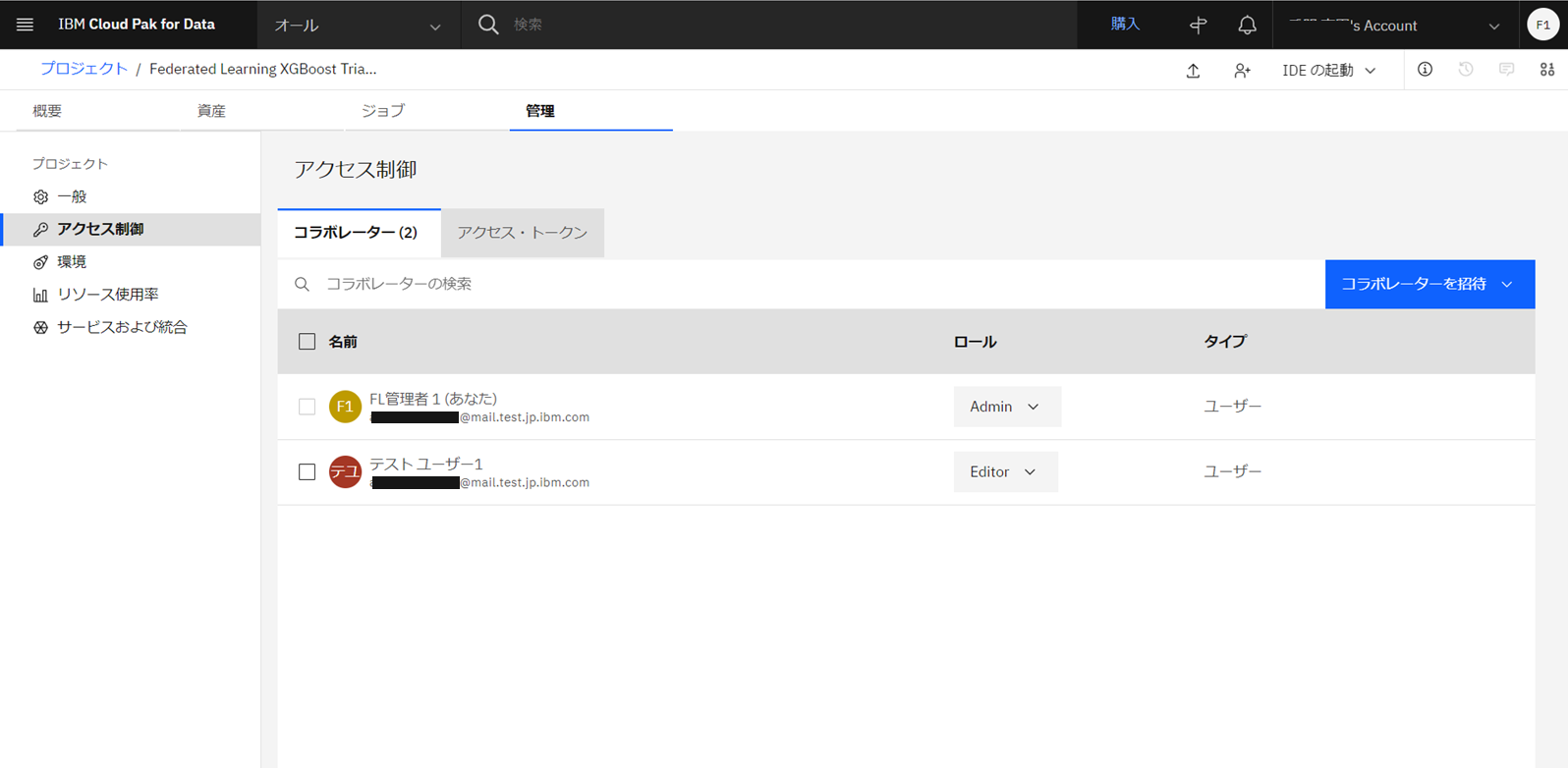
追加が完了した状態です。
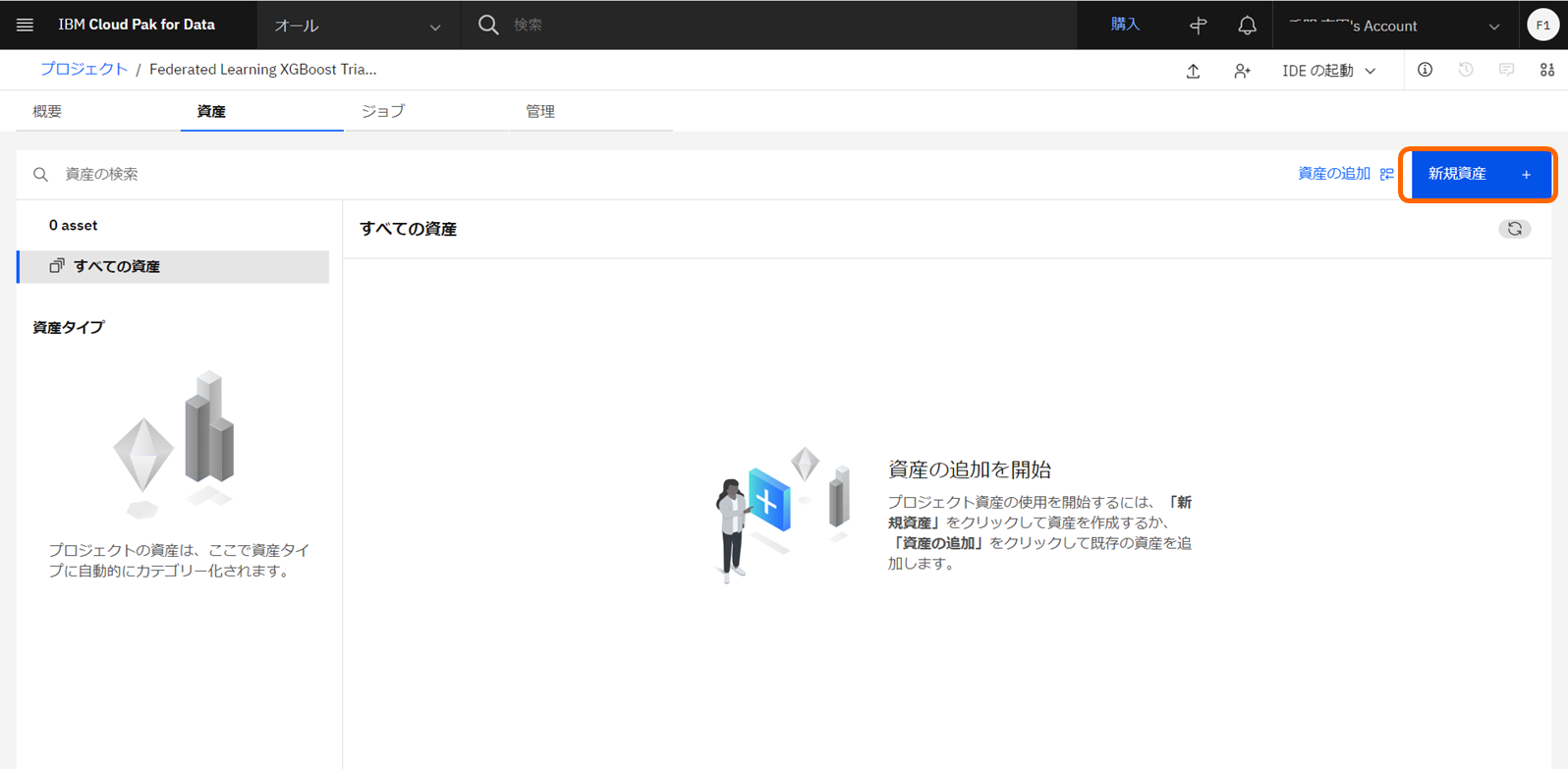
Aggregatorのセットアップ
-
資産タブにて、「新規作成」をクリックします。
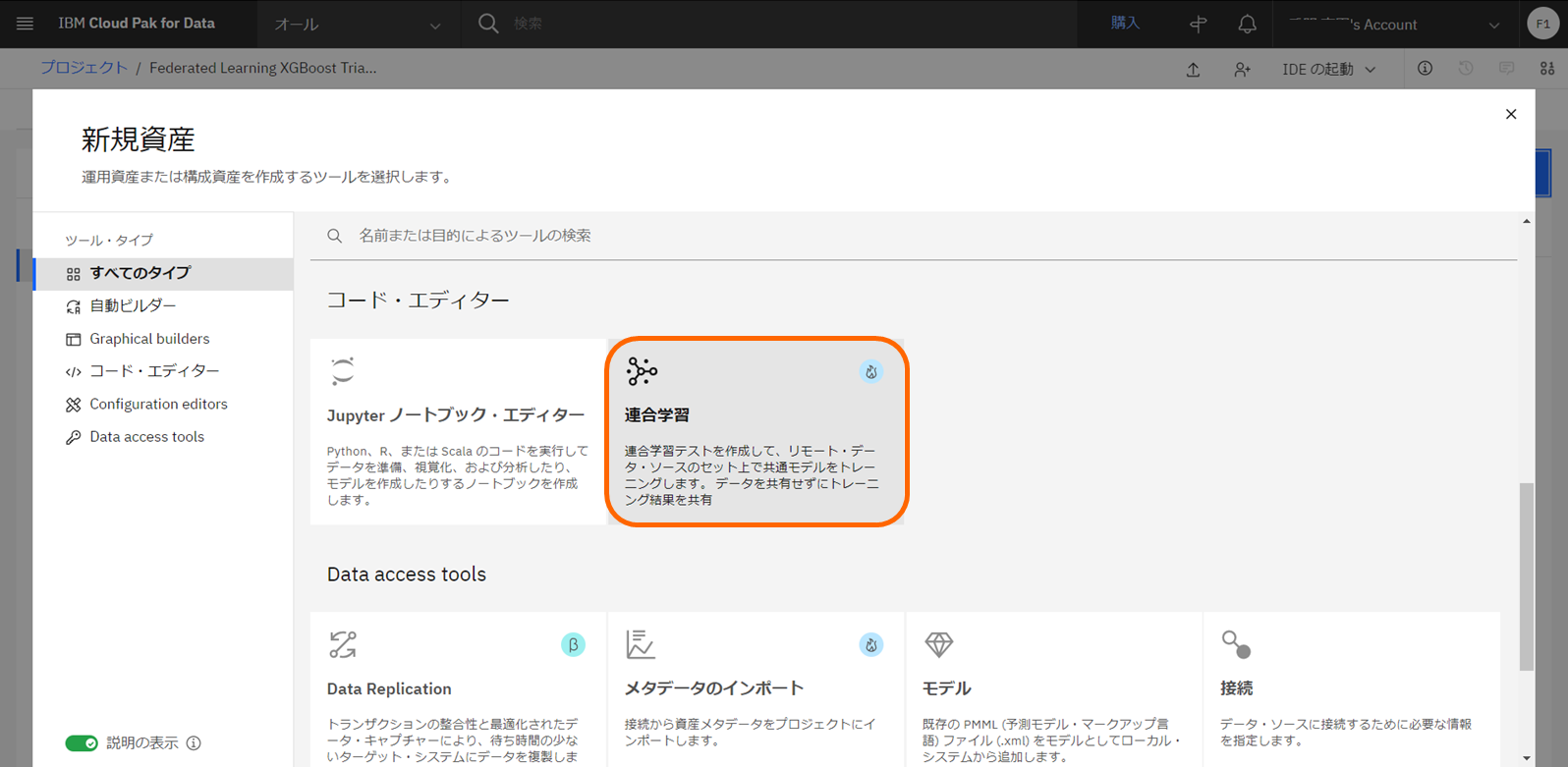
-
「統合学習」(英語表示の場合、Federated Learning experiment)を選択します
-
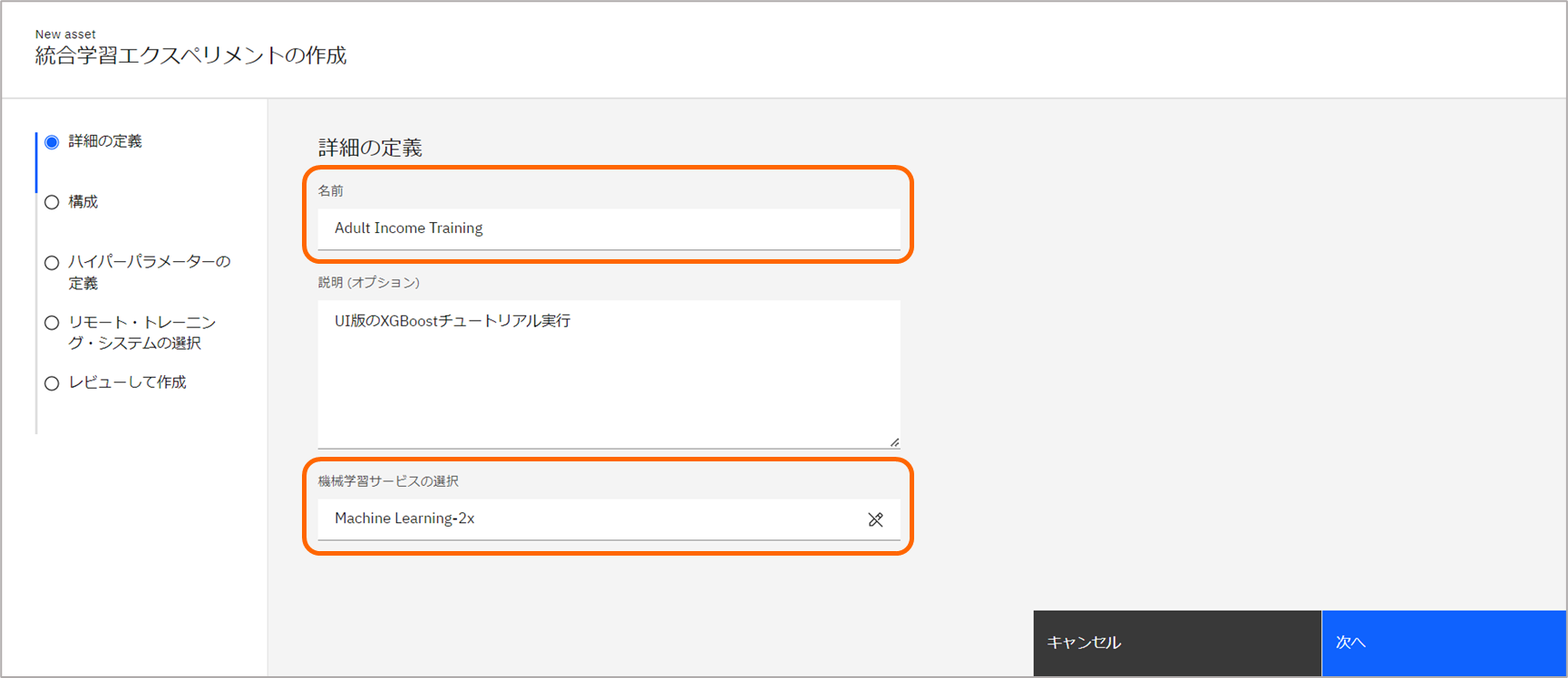
任意の名前を指定し、オプションで説明を記載します。
-
機械学習サービスの選択にて、Watson Machine Learningサービスを選択し、次へ進みます。
もし、リストへWatson Machine Learningサービスが表示されない場合は、Watson Machine Learningサービスが作成されているか、また、プロジェクトへWatson Machine Learningサービスを関連付け済みであるかご確認ください。「開始の前に」セクションに手順を記載しています。
-
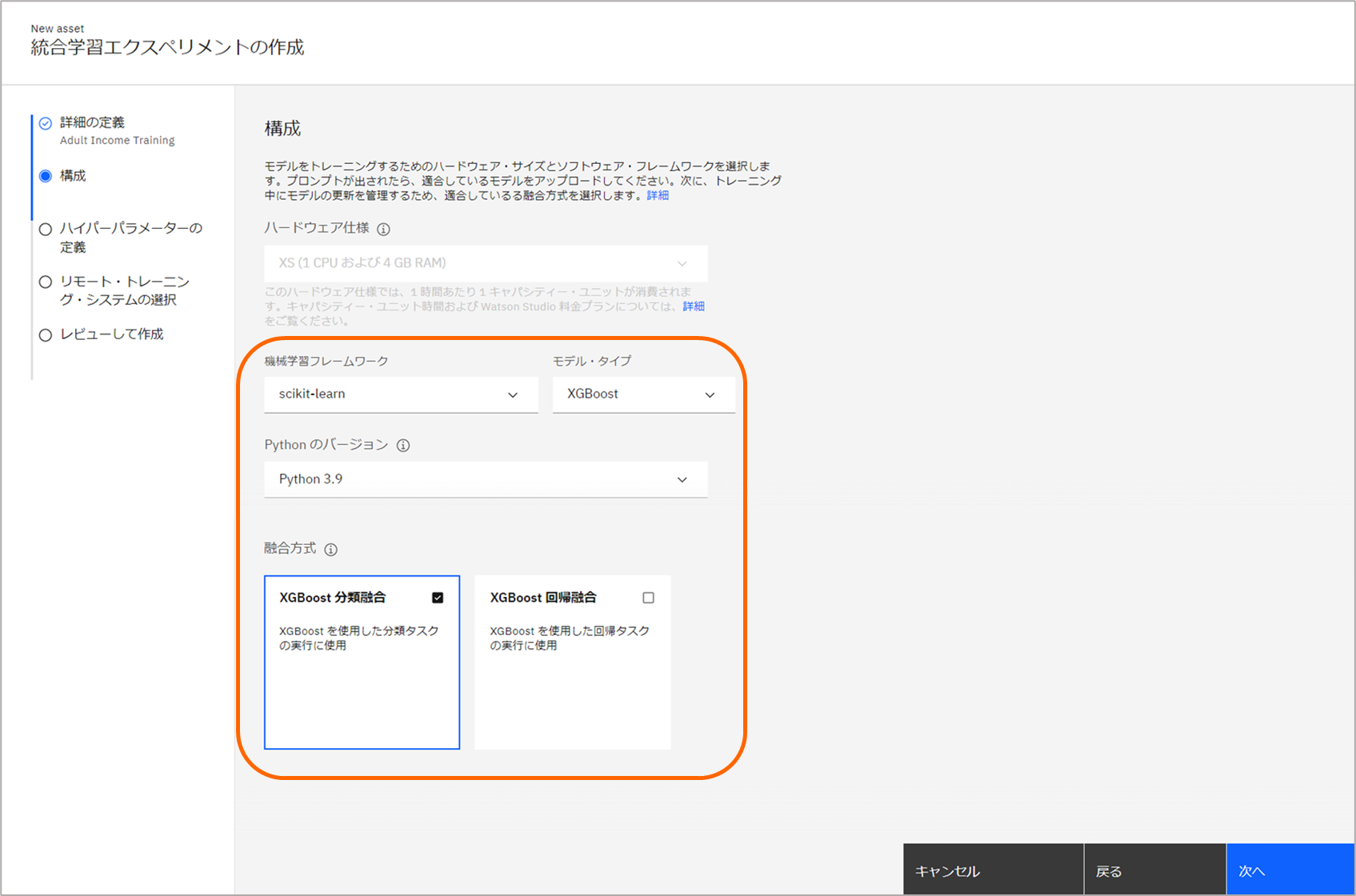
「構成」ページにて、下記のパラメーターを選択し、次へ進みます。
- 機械学習フレームワーク : scikit-learn
- モデル・タイプ : XGBoost
- Pythonのバージョン : Python 3.9 ※手順の実施時点でサポートされるバージョンのPythonを選択してください。本記事の作成時点では3.9です。
- 融合方式 : XGBoost 分類融合
-
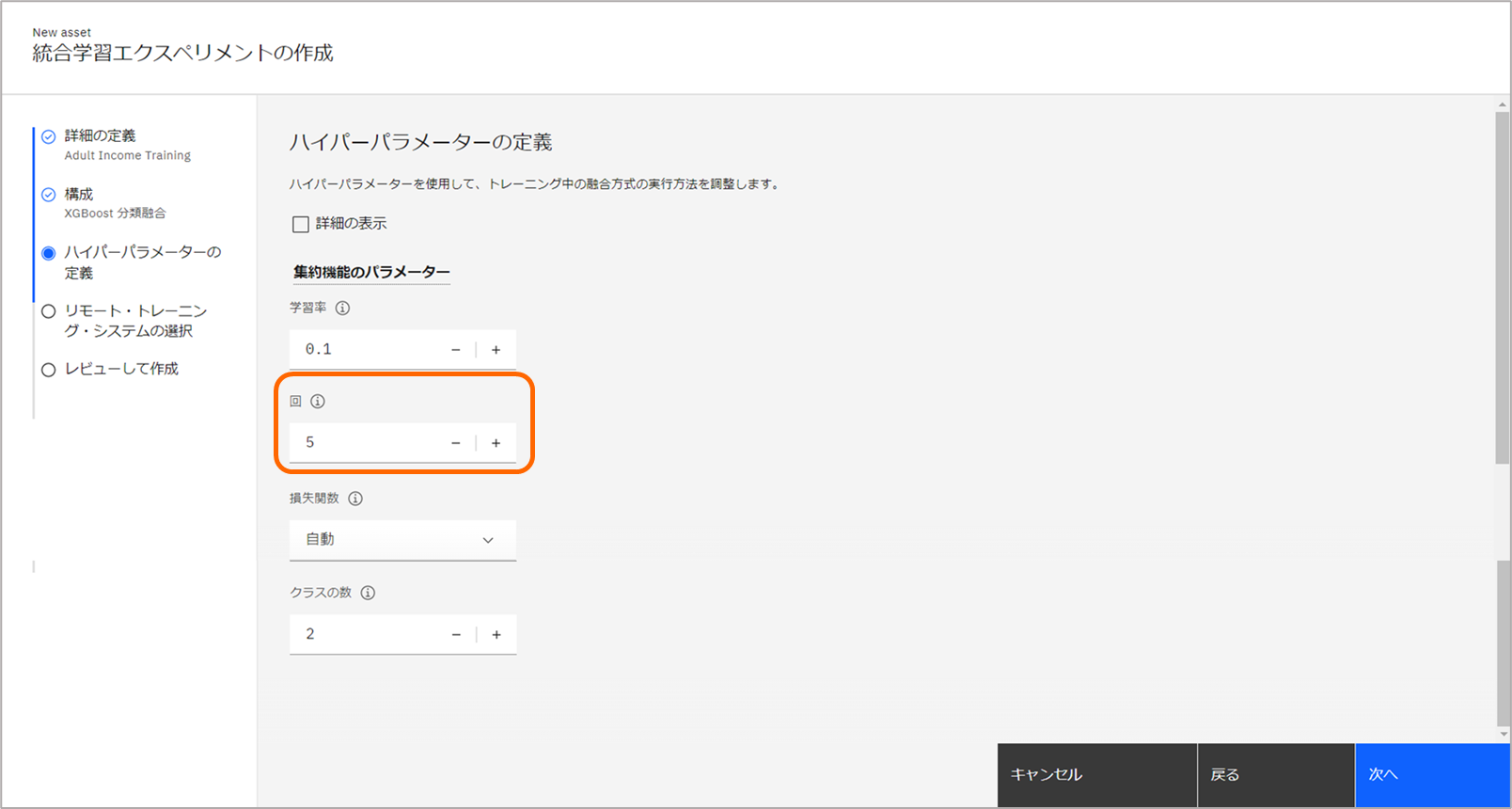
「ハイパーパラメータの定義」ページにて、回数を5へ変更します。他はデフォルトのまま次へ進みます。
- 学習率 :0.1。XGBoostのハイパーパラメータです。
- 回数 :トレーニングの繰り返し回数です。
- 損失関数 :「構成」ページで指定した、モデルのタイプおよび融合方式に対応する関数を指定します。autoとした場合、自動で適した関数を設定します。
- クラス数 :目的変数のクラス数です。二値分類の場合2となります。
-
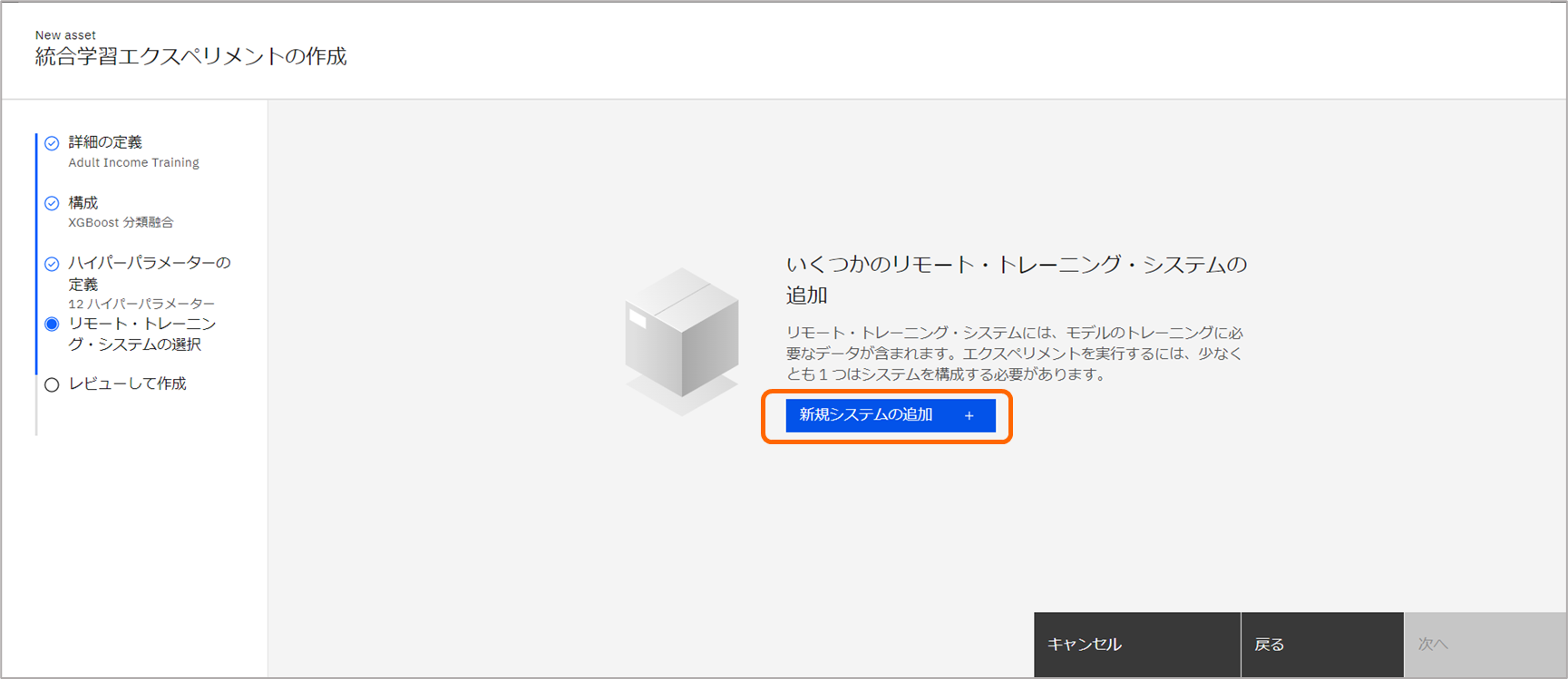
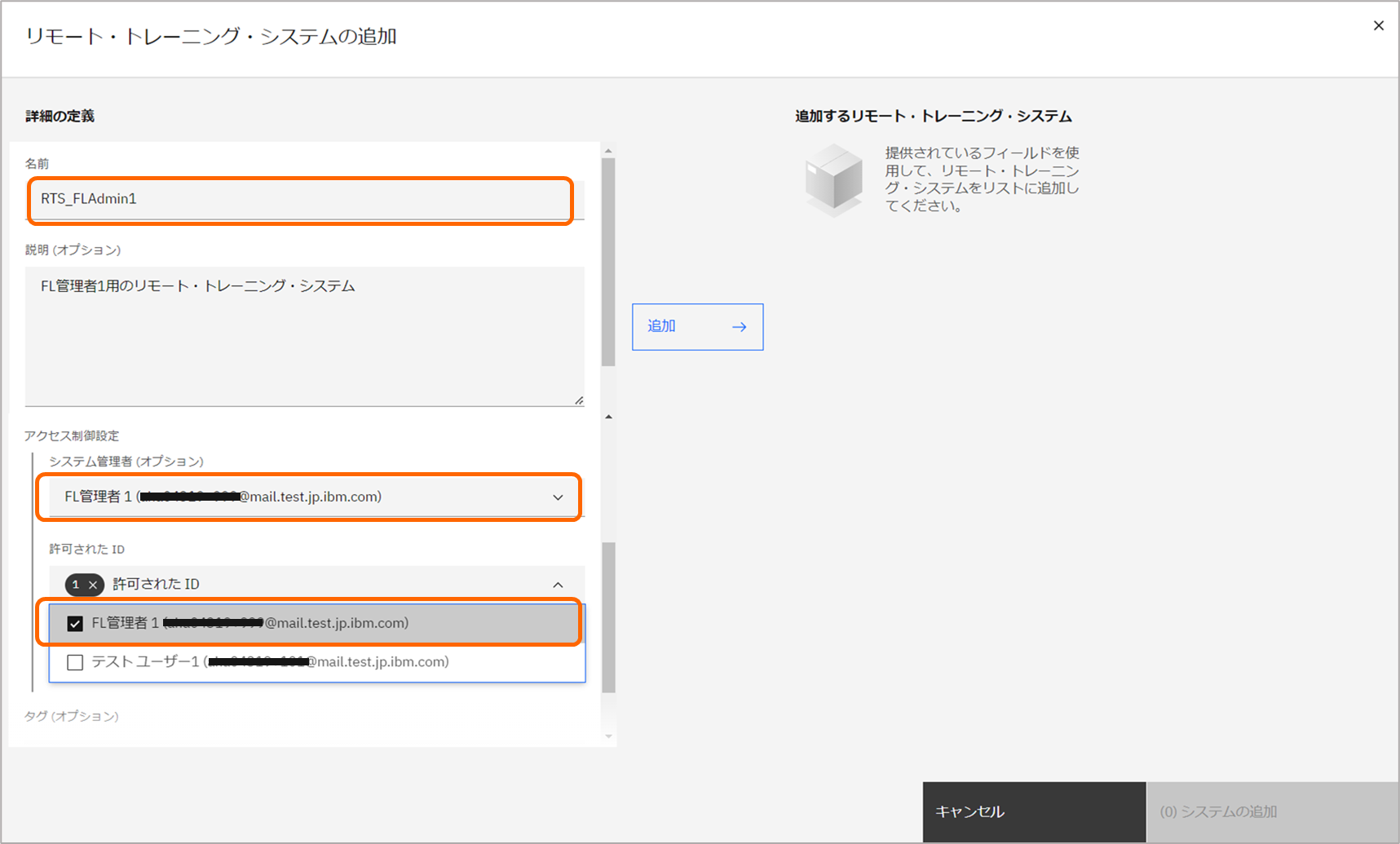
「リモート・トレーニング・システム(英語表記の場合、Remote Training Systems (RTS))」ページにて、「新規システムの追加」をクリックします。
-
任意の名前を指定し、許可されたIDとしてトレーニング参加者に対応するIDを選択し、「追加」をクリックします。
リストに表示されるIDは、プロジェクトのコラボレータとしてエディター権限を付与されたIDです。
なお、プロジェクトの作成者は、プロジェクトの管理者権限を持つため、デフォルトでリストに表示されます。
-
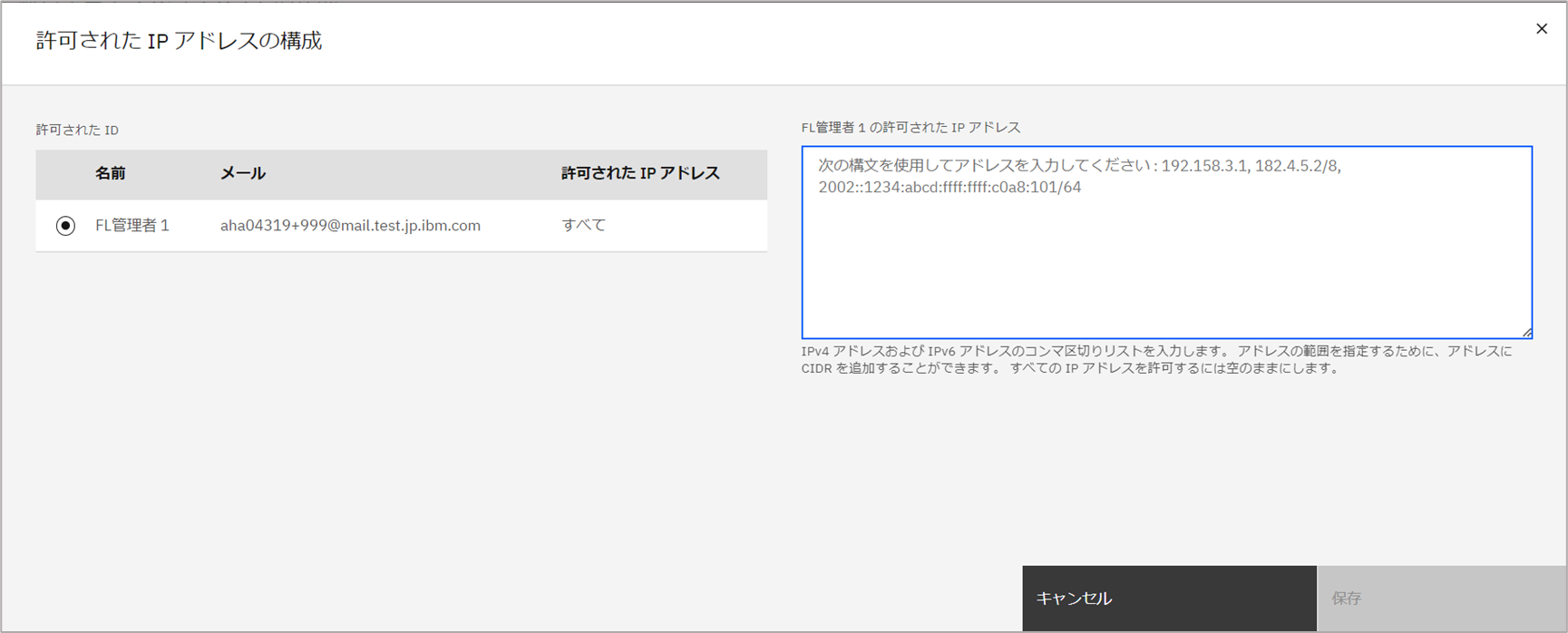
(補足) RTS作成の際、オプションとして、ユーザーがaggregatorへの通信に使用するIPアドレスの許可設定を構成可能です。本手順ではデフォルトの設定をそのまま使用し、すべてのIPアドレスからの通信を許可します。
-
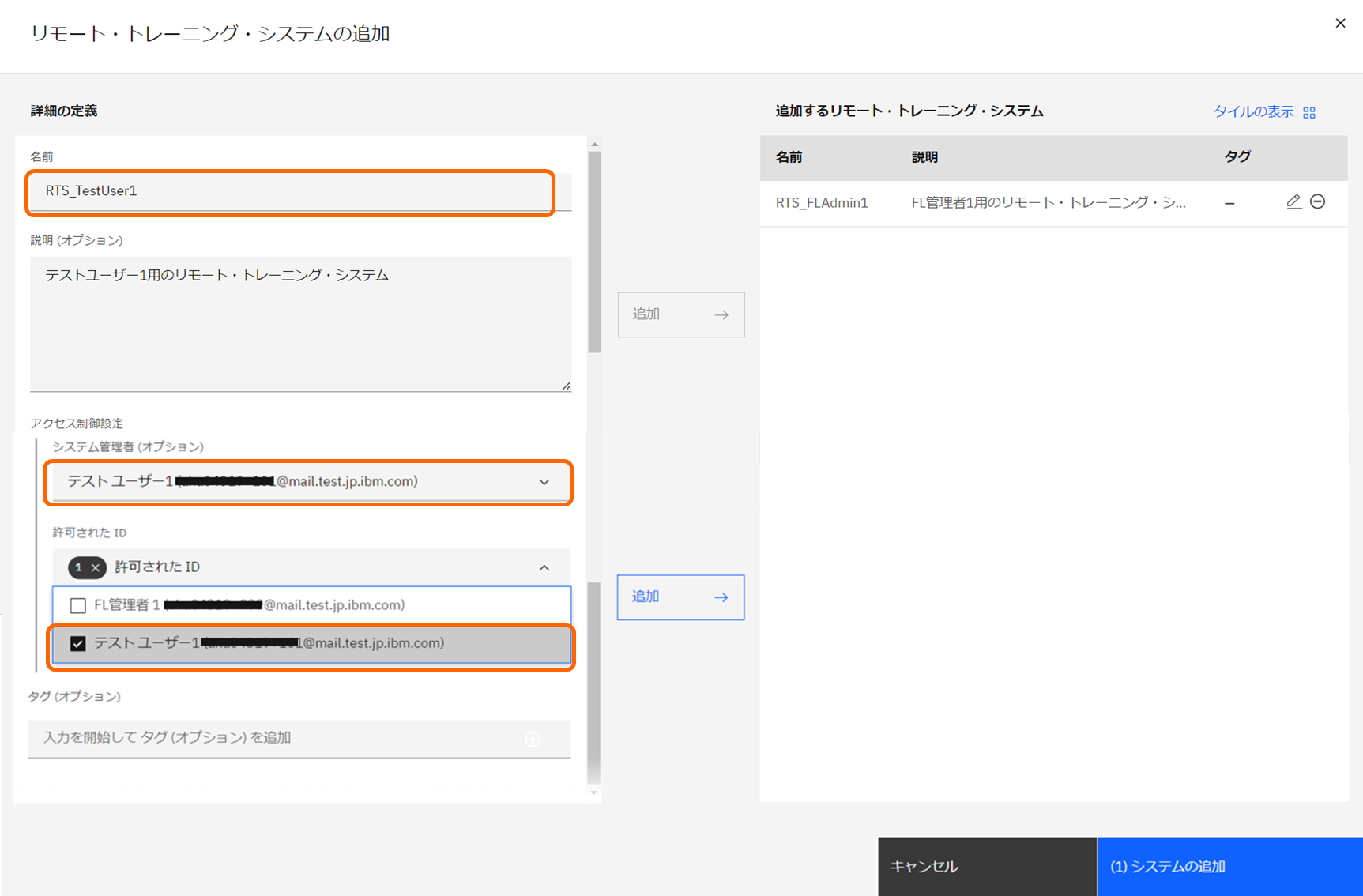
同様に、テストユーザー1用のRTSも作成し、「追加」をクリックします。
Partyを実行するユーザーごとに、1つRTSが必要です。
ユーザー数に応じ、繰り返しRTSを作成します。
-
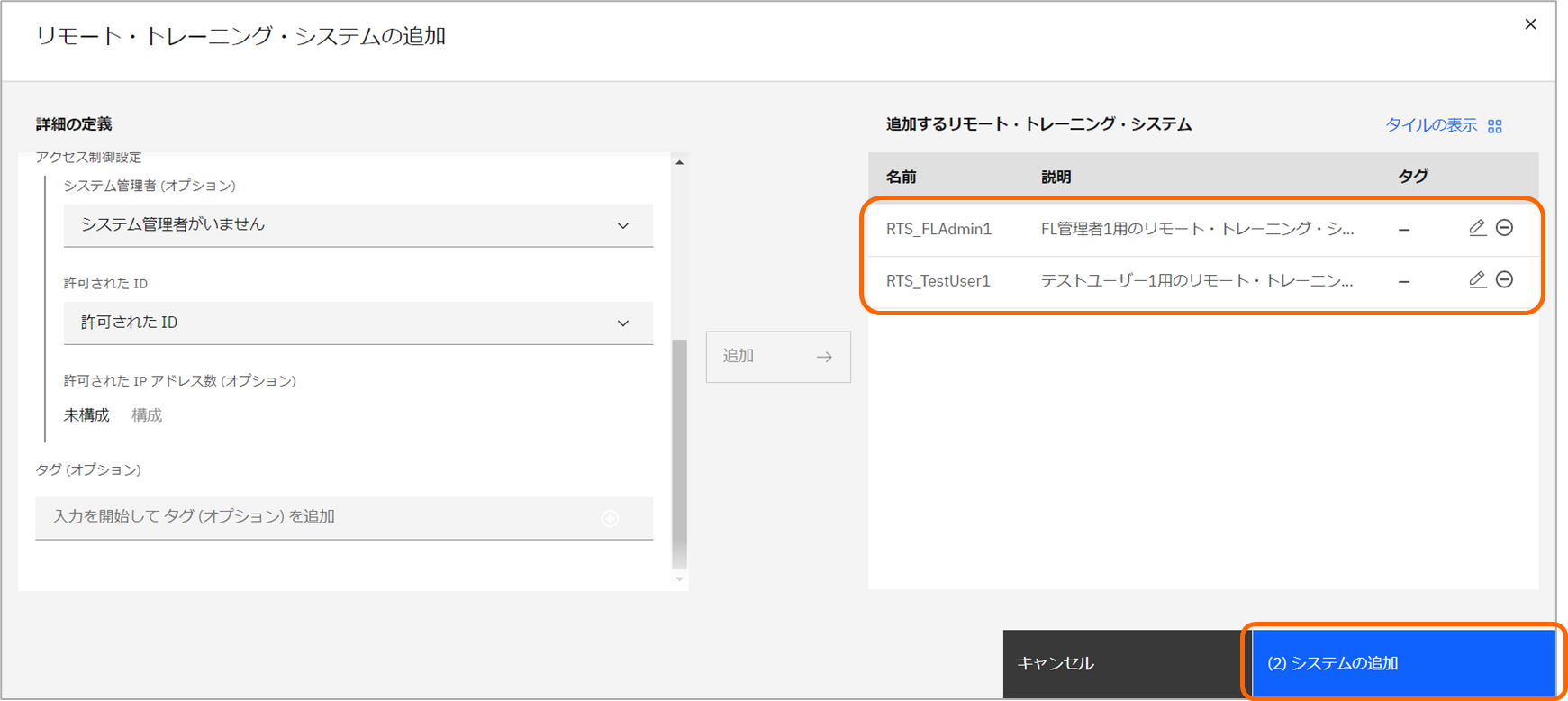
2つのRTSが表示された状態で、「(2)システムへの追加」をクリックします。
-
追加した全てのRTSを選択し、次へ進みます。
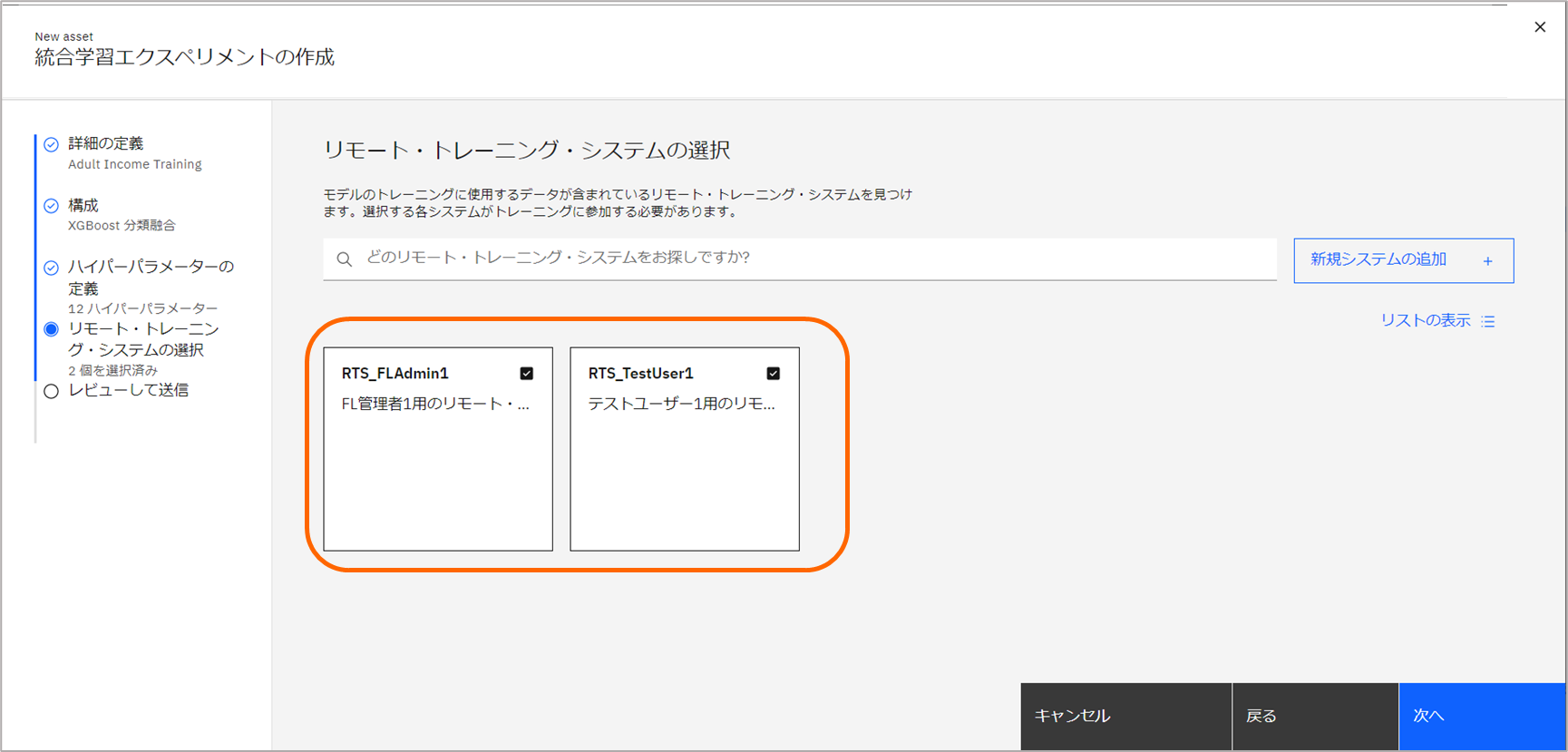
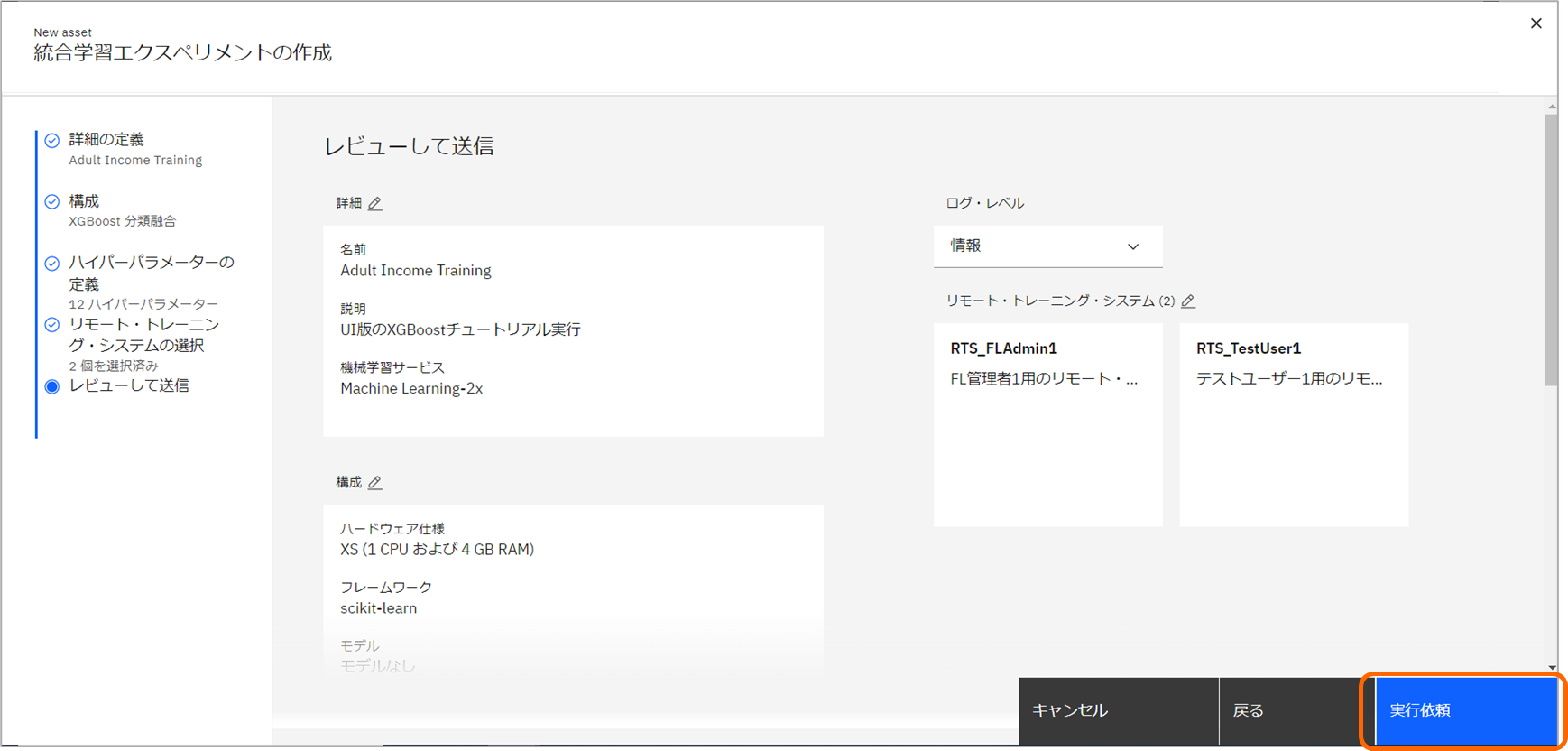
-
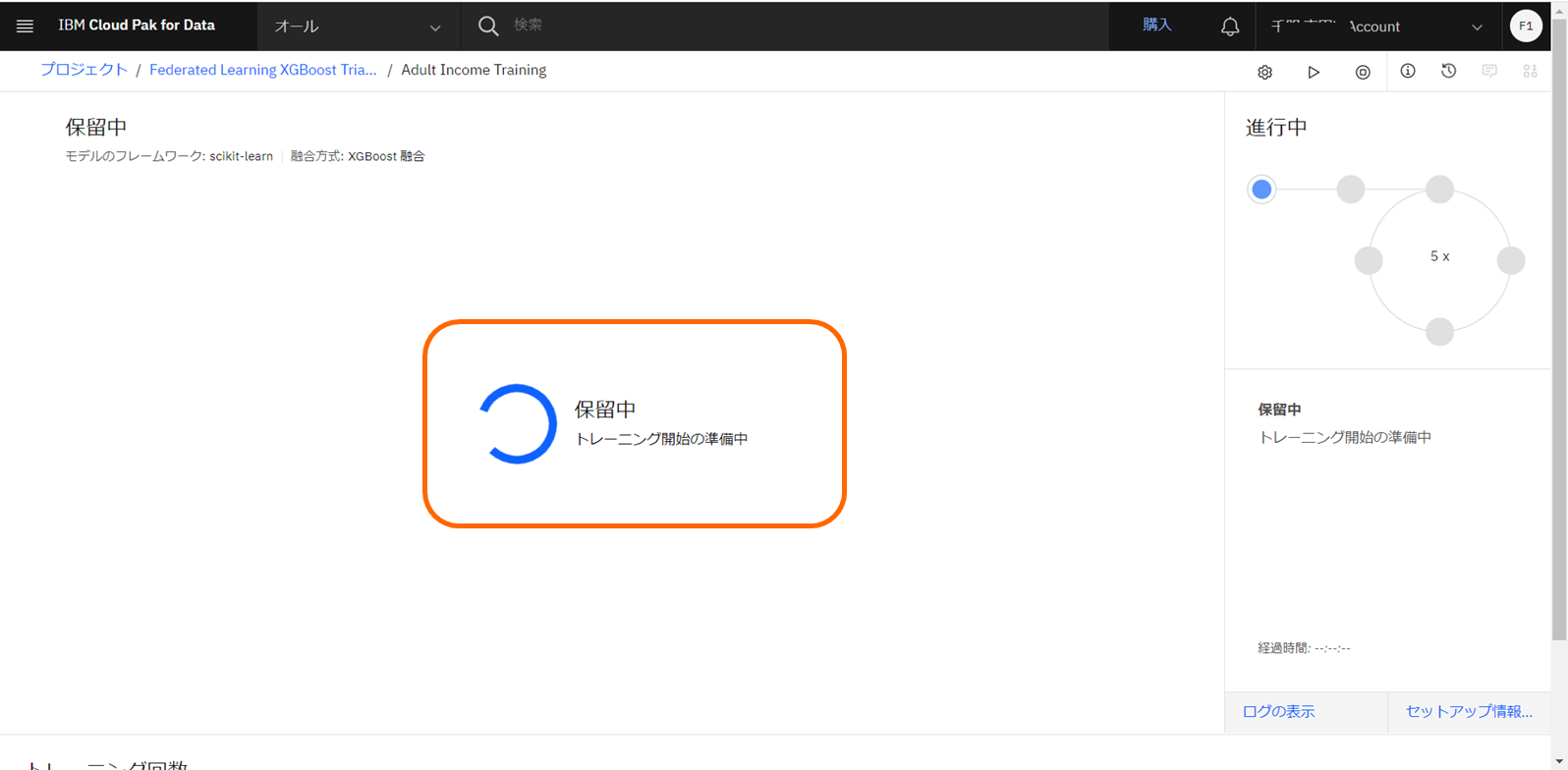
統合学習の設定内容を確認し、「実行依頼」をクリックします。aggregatorが開始するまで、数分程度、「保留中」ステータスとなります。
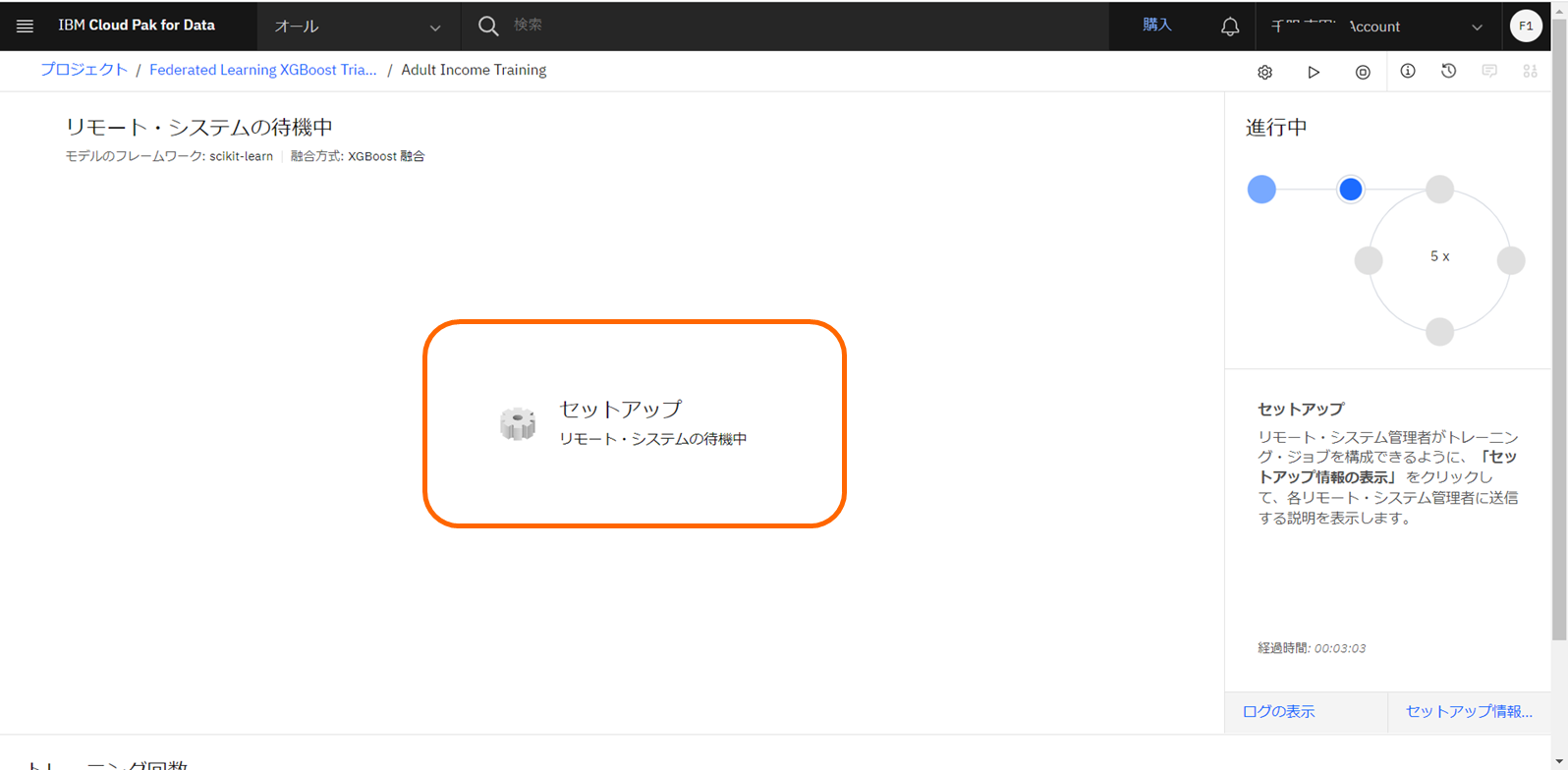
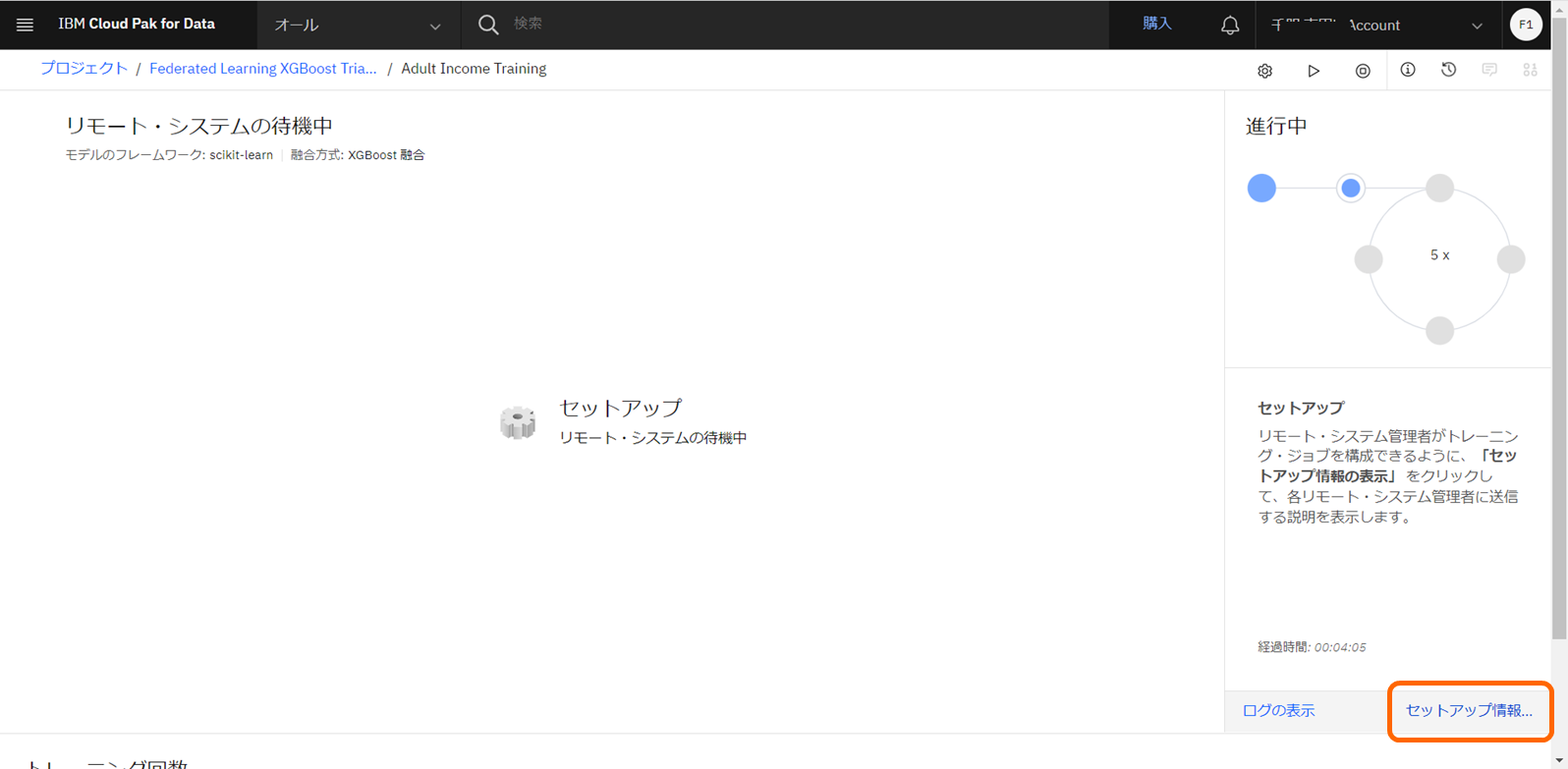
トレーニングの準備が完了すると、aggregatorは「リモート・システムの待機中」となります。
全てのトレーニング参加者がトレーニングを開始するまで、この状態が継続します。
「リモート・システムの待機中」ステータスの間、Watson Machine Learning はアクティブな状態となり、CUHを消費します。CUHの消費に基づき、課金が行われます。
全てのトレーニング参加者がトレーニングに参加し、トレーニングが完了するか、または、トレーニングのタイムアウトに達するまで、「リモート・システムの待機中」ステータスが維持されます。
トレーニング参加者の作業
本記事では、複数のトレーニング参加者でFederated Learningを動かすため、2ユーザーを使用します。
各ユーザーのトレーニング実行環境は以下となります。
| ユーザー | 実行環境 | 詳細 |
|---|---|---|
| FL管理者1 | SaaS の Jupyter Notebook | Watson Studio の Notebook |
| テストユーザー1 | IaaS | Amazon EC2 へ Pythonを導入 |
トレーニングの実行
Step 2: Train model as a party
https://dataplatform.cloud.ibm.com/docs/content/wsj/analyze-data/fl-xg-tutorial.html?audience=wdp&locale=en#step-2
-
管理者へaggregatorで設定したPythonのバージョンを確認し、自環境へ同じバージョンのPythonを導入します。本記事では、
Python 3.9です。-
FL管理者1
- Watson Studioプロジェクトへ、
IBM Runtime 22.1 on Python 3.9 XSのNotebookを作成します。
-
Watson Studio上のnotebookからIBM Cloud Object Storage(ICOS)へのFileの読み書き - project-libを使うを参照し、Watson Studioプロジェクトへ、エディター権限のプロジェクトトークンを作成し、Notebookへ挿入・セルを実行します。
- Watson Studioプロジェクトへ、
-
テストユーザー1
Amazon EC2 へ、conda仮想環境を作成し、Python 3.9を導入済です。
環境の作成方法はこちらを参照してください。Last login: Sun Apr 10 15:00:41 2022 from xxx.xxx.xx.xxx __| __|_ ) _| ( / Amazon Linux 2 AMI ___|\___|___| https://aws.amazon.com/amazon-linux-2/ (base) [ec2-user@ip-10-0-1-11]~% (base) [ec2-user@ip-10-0-1-11]~% conda activate fl_env (fl_env) [ec2-user@ip-10-0-1-11]~% python -V Python 3.9.7
-
-
任意の名前で作業ディレクトリを作成し、移動します。
mkdir <作業ディレクトリ名> cd <作業ディレクトリ名>本記事の手順では、作業ディレクトリ名にfl-partyを使用しました。
- FL管理者1
%mkdir fl-party %cd fl-party
- テストユーザー1
(fl_env) [ec2-user@ip-10-0-1-11]~% mkdir fl-party (fl_env) [ec2-user@ip-10-0-1-11]~% cd fl-party -
チュートリアル用のデータセット
adult.csvをダウンロードします。wget https://api.dataplatform.cloud.ibm.com/v2/gallery- assets/entries/5fcc01b02d8f0e50af8972dc8963f98e/data -O adult.csv-
FL管理者1
-
テストユーザー1
(fl_env) [ec2-user@ip-10-0-1-11]~/fl-party% wget -O adult.csv https://api.dataplatform.cloud.ibm.com/v2/gallery-assets/entries/5fcc01b02d8f0e50af8972dc8963f98e/data --2022-04-13 12:51:52-- https://api.dataplatform.cloud.ibm.com/v2/gallery-assets/entries/5fcc01b02d8f0e50af8972dc8963f98e/data Resolving api.dataplatform.cloud.ibm.com (api.dataplatform.cloud.ibm.com)... 104.20.63.236, 104.20.62.236, 2606:4700:10::6814:3fec, ... Connecting to api.dataplatform.cloud.ibm.com (api.dataplatform.cloud.ibm.com)|104.20.63.236|:443... connected. HTTP request sent, awaiting response... 200 OK Length: unspecified Saving to: ‘adult.csv’ [ <=> ] 3,844,219 2.86MB/s in 1.3s 2022-04-13 12:51:54 (2.86 MB/s) - ‘adult.csv’ saved [3844219] -
-
チュートリアル用のData Handler
adult_sklearn_data_handler.pyをダウンロードします。wget https://raw.githubusercontent.com/IBMDataScience/sample-notebooks/master/Files/adult_sklearn_data_handler.py -O adult_sklearn_data_handler.py-
FL管理者1
-
テストユーザー1
(fl_env) [ec2-user@ip-10-0-1-11]~/fl-party% wget https://raw.githubusercontent.com/IBMDataScience/sample-notebooks/master/Files/adult_sklearn_data_handler.py -O adult_sklearn_data_handler.py --2022-04-13 12:52:46-- https://raw.githubusercontent.com/IBMDataScience/sample-notebooks/master/Files/adult_sklearn_data_handler.py Resolving raw.githubusercontent.com (raw.githubusercontent.com)... 185.199.108.133, 185.199.109.133, 185.199.110.133, ... Connecting to raw.githubusercontent.com (raw.githubusercontent.com)|185.199.108.133|:443... connected. HTTP request sent, awaiting response... 200 OK Length: 8519 (8.3K) [text/plain] Saving to: ‘adult_sklearn_data_handler.py’ 100%[=====================================================================================================================>] 8,519 --.-K/s in 0.001s 2022-04-13 12:52:46 (12.8 MB/s) - ‘adult_sklearn_data_handler.py’ saved [8519/8519] -
-
Watson Machine Learningのライブラリを導入します。導入バージョンは、手順実施時点で最新のバージョンを指定してください。製品資料のこちらよりご確認いただけます。
pip install --upgrade 'ibm-watson-machine-learning[バージョン]'-
FL管理者1
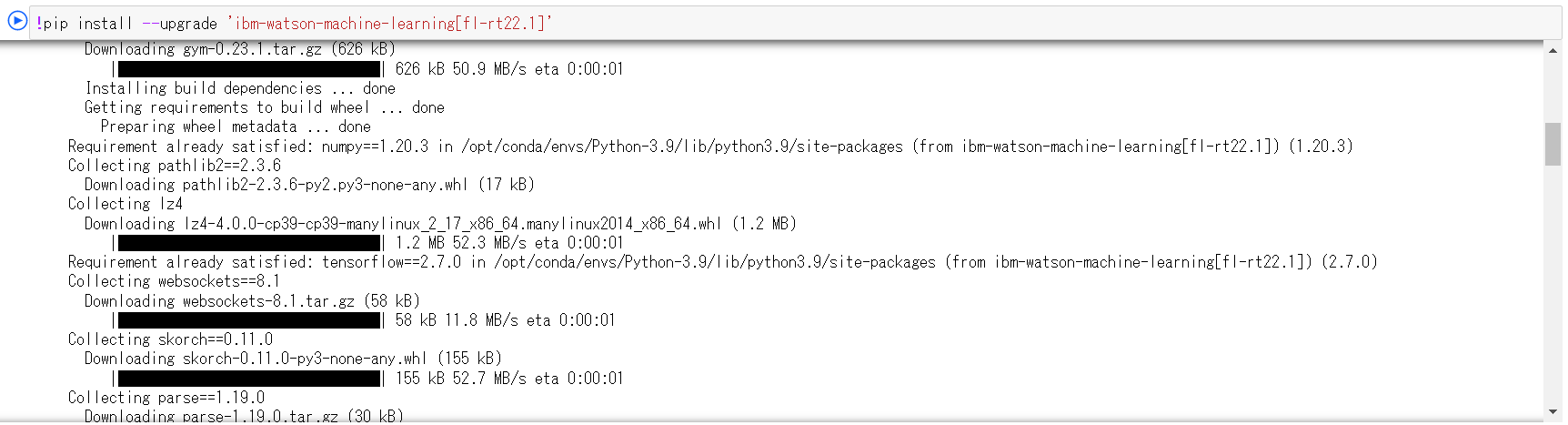
-
テストユーザー1
実行例(fl_env) [ec2-user@ip-10-0-1-11]~% pip install --upgrade 'ibm-watson-machine-learning[fl-rt22.1]'  Collecting ibm-watson-machine-learning[fl-rt22.1] Downloading ibm_watson_machine_learning-1.0.204-py3-none-any.whl (1.7 MB) |????????????????????????????????| 1.7 MB 20.3 MB/s Collecting tabulate Downloading tabulate-0.8.9-py3-none-any.whl (25 kB) Collecting urllib3 (略) Installing collected packages: urllib3, six, pyasn1, idna, charset-normalizer, zipp, rsa, requests, python-dateutil, pyasn1-modules, oauthlib, jmespath, cachetools, requests-oauthlib, pyparsing, numpy, importlib-metadata, ibm-cos-sdk-core, google-auth, werkzeug, threadpoolctl, tensorboard-plugin-wit, tensorboard-data-server, sqlparse, scipy, pytz, protobuf, packaging, markdown, joblib, ibm-cos-sdk-s3transfer, grpcio, google-auth-oauthlib, asgiref, absl-py, wrapt, typing-extensions, tqdm, toml, termcolor, tensorflow-io-gcs-filesystem, tensorflow-estimator, tensorboard, tabulate, scikit-learn, python-dotenv, py, pluggy, pillow, pandas, opt-einsum, marshmallow, lomond, libclang, keras-preprocessing, keras, iniconfig, ibm-cos-sdk, h5py, gym-notices, google-pasta, gast, flatbuffers, django, cloudpickle, attrs, astunparse, websockets, torch, tensorflow, skorch, setproctitle, pyYAML, pytest, psutil, pathlib2, parse, numcompress, lz4, jsonpickle, image, ibm-watson-machine-learning, gym, environs, diffprivlib, ddsketch Successfully installed absl-py-1.0.0 asgiref-3.5.0 astunparse-1.6.3 attrs-21.4.0 cachetools-5.0.0 charset-normalizer-2.0.12 cloudpickle-1.3.0 ddsketch-1.1.2 diffprivlib-0.5.1 django-4.0.3 environs-9.5.0 flatbuffers-2.0 gast-0.4.0 google-auth-2.6.3 google-auth-oauthlib-0.4.6 google-pasta-0.2.0 grpcio-1.44.0 gym-0.23.1 gym-notices-0.0.6 h5py-3.6.0 ibm-cos-sdk-2.11.0 ibm-cos-sdk-core-2.11.0 ibm-cos-sdk-s3transfer-2.11.0 ibm-watson-machine-learning-1.0.204 idna-3.3 image-1.5.33 importlib-metadata-4.11.3 iniconfig-1.1.1 jmespath-0.10.0 joblib-1.1.0 jsonpickle-1.4.1 keras-2.7.0 keras-preprocessing-1.1.2 libclang-13.0.0 lomond-0.3.3 lz4-4.0.0 markdown-3.3.6 marshmallow-3.15.0 numcompress-0.1.2 numpy-1.20.3 oauthlib-3.2.0 opt-einsum-3.3.0 packaging-21.3 pandas-1.3.4 parse-1.19.0 pathlib2-2.3.6 pillow-9.1.0 pluggy-1.0.0 protobuf-3.20.0 psutil-5.9.0 py-1.11.0 pyYAML-5.4.1 pyasn1-0.4.8 pyasn1-modules-0.2.8 pyparsing-3.0.7 pytest-6.2.5 python-dateutil-2.8.2 python-dotenv-0.20.0 pytz-2022.1 requests-2.27.1 requests-oauthlib-1.3.1 rsa-4.8 scikit-learn-1.0.2 scipy-1.7.3 setproctitle-1.2.2 six-1.16.0 skorch-0.11.0 sqlparse-0.4.2 tabulate-0.8.9 tensorboard-2.8.0 tensorboard-data-server-0.6.1 tensorboard-plugin-wit-1.8.1 tensorflow-2.7.0 tensorflow-estimator-2.7.0 tensorflow-io-gcs-filesystem-0.24.0 termcolor-1.1.0 threadpoolctl-3.1.0 toml-0.10.2 torch-1.10.0 tqdm-4.64.0 typing-extensions-4.1.1 urllib3-1.26.9 websockets-8.1 werkzeug-2.1.1 wrapt-1.14.0 zipp-3.8.0 -
-
統合学習の UIへ戻り、セットアップ情報をクリックします。
aggregatorを開始する都度、新しいaggregator IDが生成されます。セットアップ情報より、Party Connector Scriptをダウンロードし直すか、既存スクリプト内のaggregator IDを新しいIDへ手で書き換えてください。
-
「許可されたID」が 自分のユーザIDに合致する行にて、ダウンロードアイコンをクリックし、自分用の「パーティー・コネクター・スクリプト(英語表記ではParty Connector Script)」をダウンロードします。ファイル名は、
rts_<RTS Name>_<RTS ID>.pyとなります。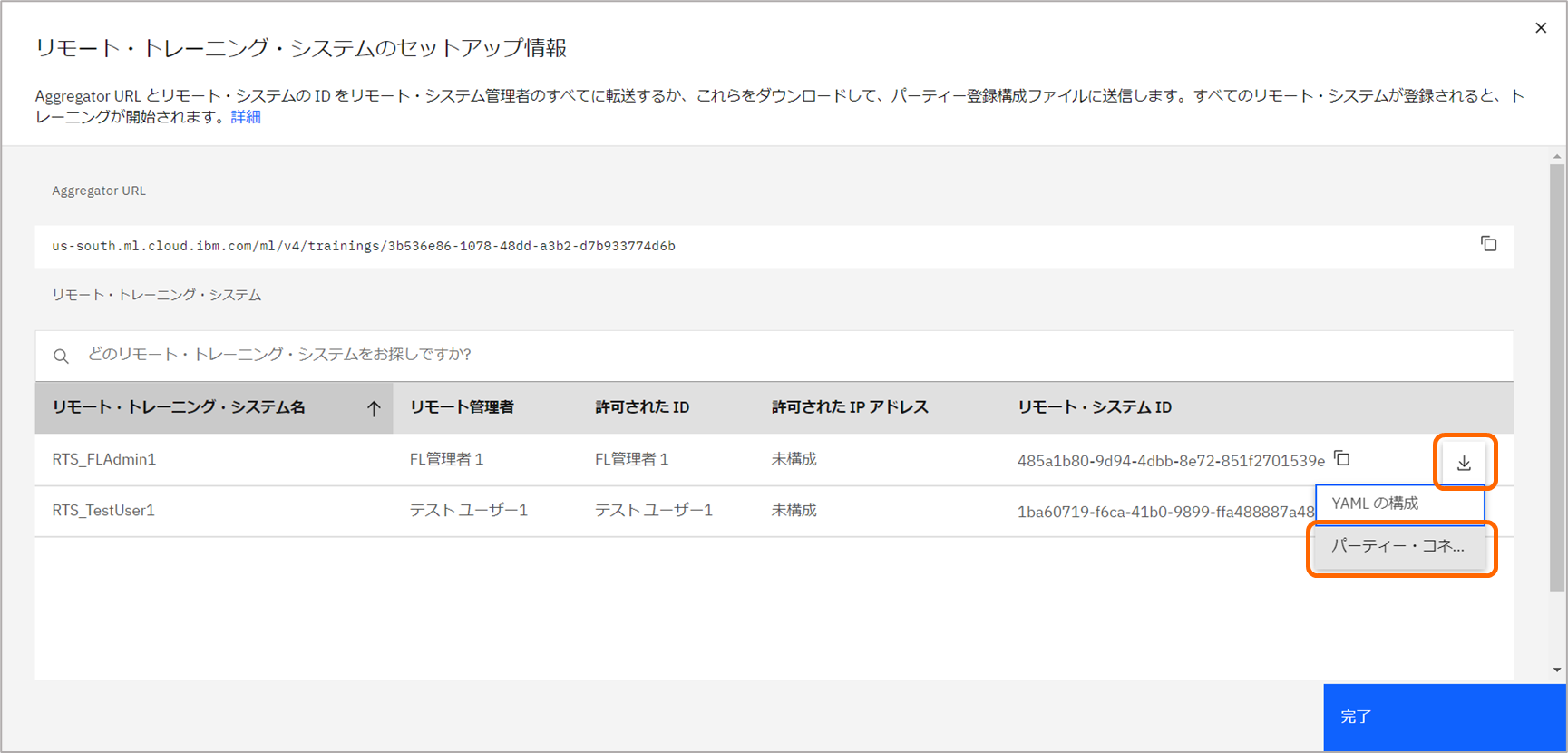
- ダウンロードしたパーティー・コネクター・スクリプト
rts_<RTS Name>_<RTS ID>.py

- ダウンロードしたパーティー・コネクター・スクリプト
-
エディター等で、ダウロードしたパーティー・コネクター・スクリプトを開き、下記箇所を自環境に合わせて書き換えます。
-
<apikey>を自分のユーザーIDで作成したAPIキーへ置き換え- APIキーの作成方法は、@nishikyonさんの下記記事を参照ください。
IBM Cloud APIKEYの作成(取得)方法
- APIキーの作成方法は、@nishikyonさんの下記記事を参照ください。
-
party_metadataのセクションで、下記の項目を変更
-
name: Data Handlerのクラス名。本記事では、チュートリアル用にダウンロ―ドした adult_sklearn_data_handler.pyで定義されたクラス名、AdultSklearnDataHandlerをセット。 -
path: Data Handlerのファイル・パス。本記事では、パーティー・コネクター・スクリプトと同じディレクトリに配置済みのため、./adult_sklearn_data_handler.pyをセット。 -
info: Data Handlerのinit関数内で定義された変数名と対応する値をkeyValue形式で記載。本記事ではkeyとしてtxt_fileという変数名、valueとして学習用データのパス./adult.csvをセット。
-
書き換え後のパーティー・コネクター・スクリプトfrom ibm_watson_machine_learning import APIClient wml_credentials = { "url": "https://us-south.ml.cloud.ibm.com", "apikey": "XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX" } wml_client = APIClient(wml_credentials) wml_client.set.default_project("ae09ff75-76f0-4093-XXXX-XXXXXXXXXXXX") party_metadata = { wml_client.remote_training_systems.ConfigurationMetaNames.DATA_HANDLER: { # Supply the name of the data handler class and path to it. # The info section may be used to pass information to the # data handler. # For example, # "name": "MnistSklearnDataHandler", # "path": "example.mnist_sklearn_data_handler", # "info": { # "npz_file":"./example_data/example_data.npz" # } "name": "AdultSklearnDataHandler", "path": "./adult_sklearn_data_handler.py", "info": { "txt_file": "./adult.csv" } } } party = wml_client.remote_training_systems.create_party("485a1b80-9d94-4dbb-XXXX-XXXXXXXXXXXX", party_metadata) party.monitor_logs() party.run(aggregator_id="3b536e86-1078-48dd-XXXX-XXXXXXXXXXXX", asynchronous=False) -
-
パーティー・コネクター・スクリプトを作業ディレクトリへ配置します。以下のように、ディレクトリ内に3ファイルが存在することを確認します。
adult.csv adult_sklearn_data_handler.py rts_<RTS Name>_<RTS ID>.py-
FL管理者1
-
プロジェクトのデータ資産へパーティー・コネクター・スクリプト
rts_<RTS Name>_<RTS ID>.pyをアップロード
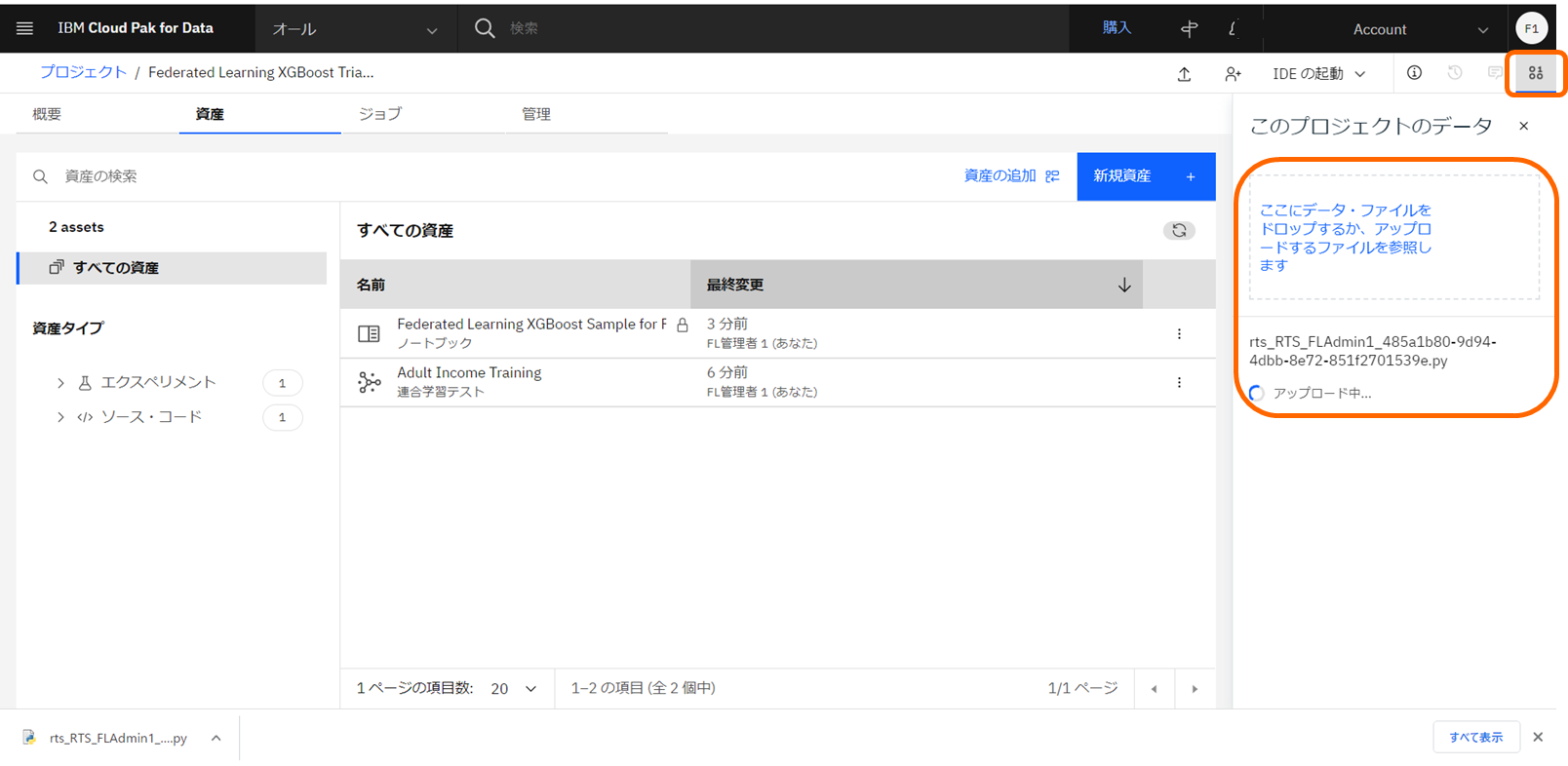
-
Notebookで下記を実行
# プロジェクトに配置した編集済みファイル名を指定 filename = "rts_<RTS Name>_<RTS ID>.py" # Notebookの作業ディレクトリへコピー fobj = open(filename, "wb") fobj.write(project.get_file(filename).read()) fobj.close() -
ファイルの確認
!ls -lh実行例total 3.7M -rw-rw---- 1 wsuser wscommon 3.7M Apr 13 12:32 adult.csv -rw-rw---- 1 wsuser wscommon 8.4K Apr 13 12:33 adult_sklearn_data_handler.py -rw-rw---- 1 wsuser wscommon 1.3K Apr 13 13:00 rts_RTS_FLAdmin1_485a1b80-9d94-4dbb-8e72-851f2701539e.py
-
-
テストユーザー1
- SCPで作業ディレクトリへパーティー・コネクター・スクリプト
rts_<RTS Name>_<RTS ID>.pyを転送 - ファイルの確認
実行例
(fl_env) [ec2-user@ip-10-0-1-11]~/fl-party% ls -lh total 3.7M -rw-rw-r-- 1 ec2-user ec2-user 3.7M Apr 13 12:51 adult.csv -rw-rw-r-- 1 ec2-user ec2-user 8.4K Apr 13 12:52 adult_sklearn_data_handler.py -rw-r--r-- 1 ec2-user ec2-user 1.3K Apr 13 12:55 rts_RTS_TestUser1_1ba60719-f6ca-41b0-9899-ffa488887a48.py
- SCPで作業ディレクトリへパーティー・コネクター・スクリプト
-
-
パーティー・コネクター・スクリプトを実行します。
python3 rts_<RTS Name>_<RTS ID>.py-
FL管理者1
!python3 rts_RTS_FLAdmin1_1ba60719-f6ca-41b0-9899-ffa488887a48.py
一人目の接続が完了すると、下記のようにメッセージが表示されます。
システムを待機中
2 台中 1 台のリモート・システムでトレーニングの準備ができました。すべてのリモート・システムの準備ができたらジョブが開始されます。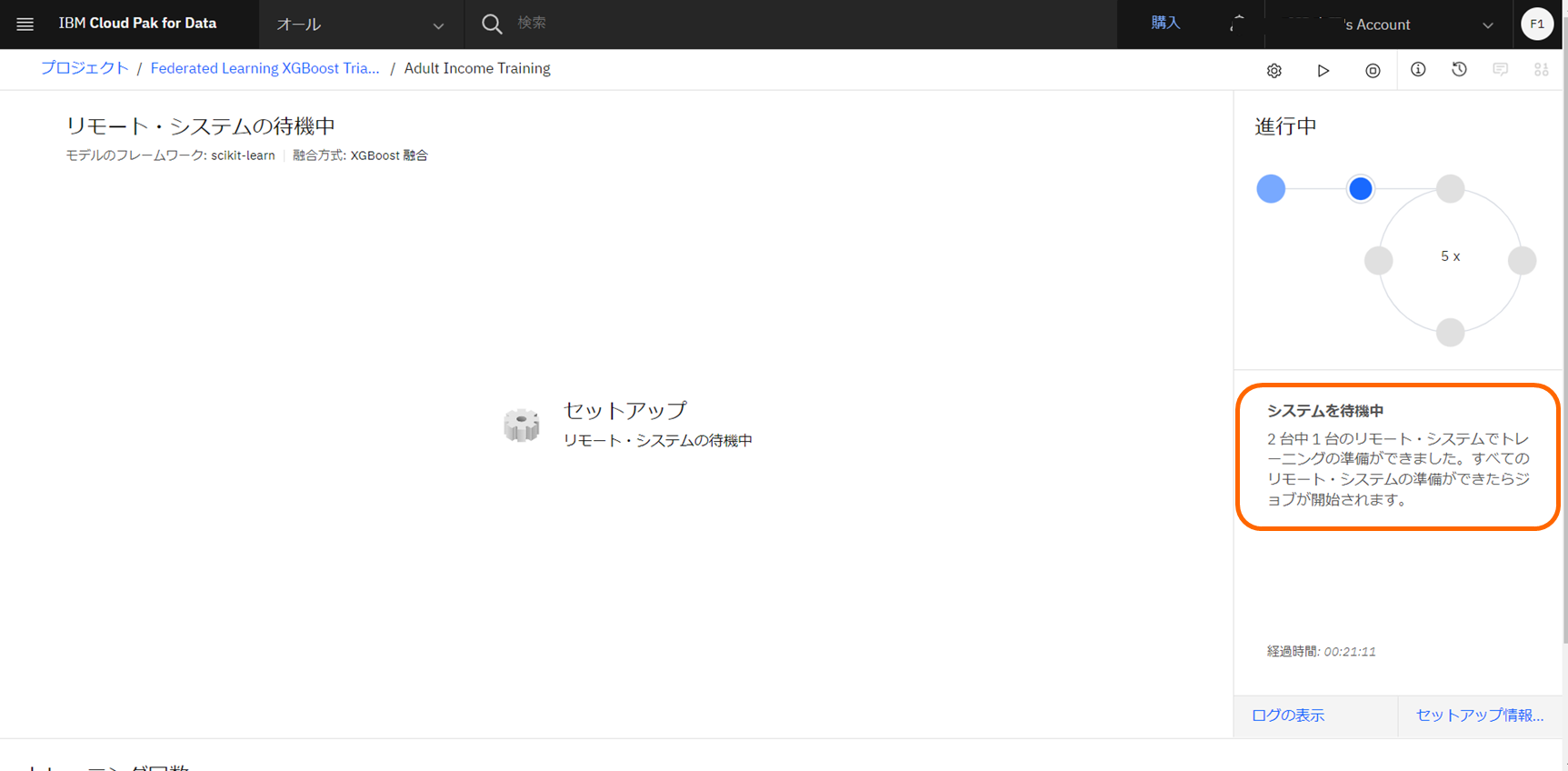
-
テストユーザー1
(fl_env) [ec2-user@ip-10-0-1-11]~/fl-party% python3 rts_RTS_TestUser1_1ba60719-f6ca-41b0-9899-ffa488887a48.py Loading py39-tf27-pt110-sk10 environment.. 2022-04-13T13:03:28.762Z | 1.0.204 | INFO | ibmfl.util.config | No model config provided for this setup. 2022-04-13T13:03:28.804Z | 1.0.204 | INFO | ibmfl.util.config | No metrics config provided for this setup. 2022-04-13T13:03:28.804Z | 1.0.204 | INFO | ibmfl.util.config | No evidencia recordeer config provided for this setup. (略) 2022-04-13T13:03:48.335Z | 1.0.204 | INFO | ibmfl.party.party | Party initialization successful 2022-04-13T13:03:48.335Z | 1.0.204 | INFO | ibmfl.party.party | Party not registered yet. 2022-04-13T13:03:48.335Z | 1.0.204 | INFO | ibmfl.party.party | Registering party... 2022-04-13T13:03:49.495Z | 1.0.204 | INFO | ibmfl.connection.websockets_connection | Received Heartbeat from aggregator
-
-
すべてのトレーニング参加者がパーティー・コネクター・スクリプトを実行し、aggregatorへの接続が完了すると、各環境でトレーニングが開始します。ローカルモデルのトレーニングが完了すると、結果がaggregator側で統合されます。aggregatorのハイパーパラメーターで指定した回数、トレーニングが繰り返し実行されます。
- party側の出力
1回のトレーニングが完了すると、下記のように精度が表示されます。
精度2022-04-13T13:05:10.259Z | 1.0.204 | INFO | ibmfl.party.training.local_training_handler | {'acc': 0.7587901120835252, 'f1': 0.0, 'precision': 0.0, 'recall': 0.0, 'average precision': 0.24, 'roc auc': 0.5, 'negative log loss': 8.33}party出力(略) 2022-04-13T13:05:08.211Z | 1.0.204 | INFO | ibmfl.model.xgb_fl_model | No models have been trained yet. 2022-04-13T13:05:08.211Z | 1.0.204 | INFO | ibmfl.party.training.local_training_handler | {} 2022-04-13T13:05:08.211Z | 1.0.204 | INFO | ibmfl.party.party_protocol_handler | successfully finished async request 2022-04-13T13:05:09.206Z | 1.0.204 | INFO | ibmfl.party.party_protocol_handler | Received request from aggregator 2022-04-13T13:05:09.206Z | 1.0.204 | INFO | ibmfl.party.party_protocol_handler | Received request in with message_type: 12 2022-04-13T13:05:09.207Z | 1.0.204 | INFO | ibmfl.party.party_protocol_handler | Received request in PH 12 2022-04-13T13:05:10.207Z | 1.0.204 | INFO | ibmfl.party.party_protocol_handler | received a async request 2022-04-13T13:05:10.207Z | 1.0.204 | INFO | ibmfl.party.party_protocol_handler | finished async request 2022-04-13T13:05:10.208Z | 1.0.204 | INFO | ibmfl.party.party_protocol_handler | Handling async request in a separate thread 2022-04-13T13:05:10.208Z | 1.0.204 | INFO | ibmfl.party.party_protocol_handler | Received request from aggregator 2022-04-13T13:05:10.208Z | 1.0.204 | INFO | ibmfl.party.party_protocol_handler | Received request in with message_type: 7 2022-04-13T13:05:10.208Z | 1.0.204 | INFO | ibmfl.party.party_protocol_handler | Received request in PH 7 2022-04-13T13:05:10.213Z | 1.0.204 | INFO | ibmfl.model.xgb_fl_model | Performing Model Inference Process 2022-04-13T13:05:10.259Z | 1.0.204 | INFO | ibmfl.party.training.local_training_handler | {'acc': 0.7587901120835252, 'f1': 0.0, 'precision': 0.0, 'recall': 0.0, 'average precision': 0.24, 'roc auc': 0.5, 'negative log loss': 8.33} 2022-04-13T13:05:10.259Z | 1.0.204 | INFO | ibmfl.party.party_protocol_handler | successfully finished async request 2022-04-13T13:05:11.210Z | 1.0.204 | INFO | ibmfl.party.party_protocol_handler | received a async request 2022-04-13T13:05:11.210Z | 1.0.204 | INFO | ibmfl.party.party_protocol_handler | finished async request 2022-04-13T13:05:11.211Z | 1.0.204 | INFO | ibmfl.party.party_protocol_handler | Handling async request in a separate thread 2022-04-13T13:05:11.211Z | 1.0.204 | INFO | ibmfl.party.party_protocol_handler | Received request from aggregator (略)- 全体のトレーニング状況は、統合学習のUIで確認できます。
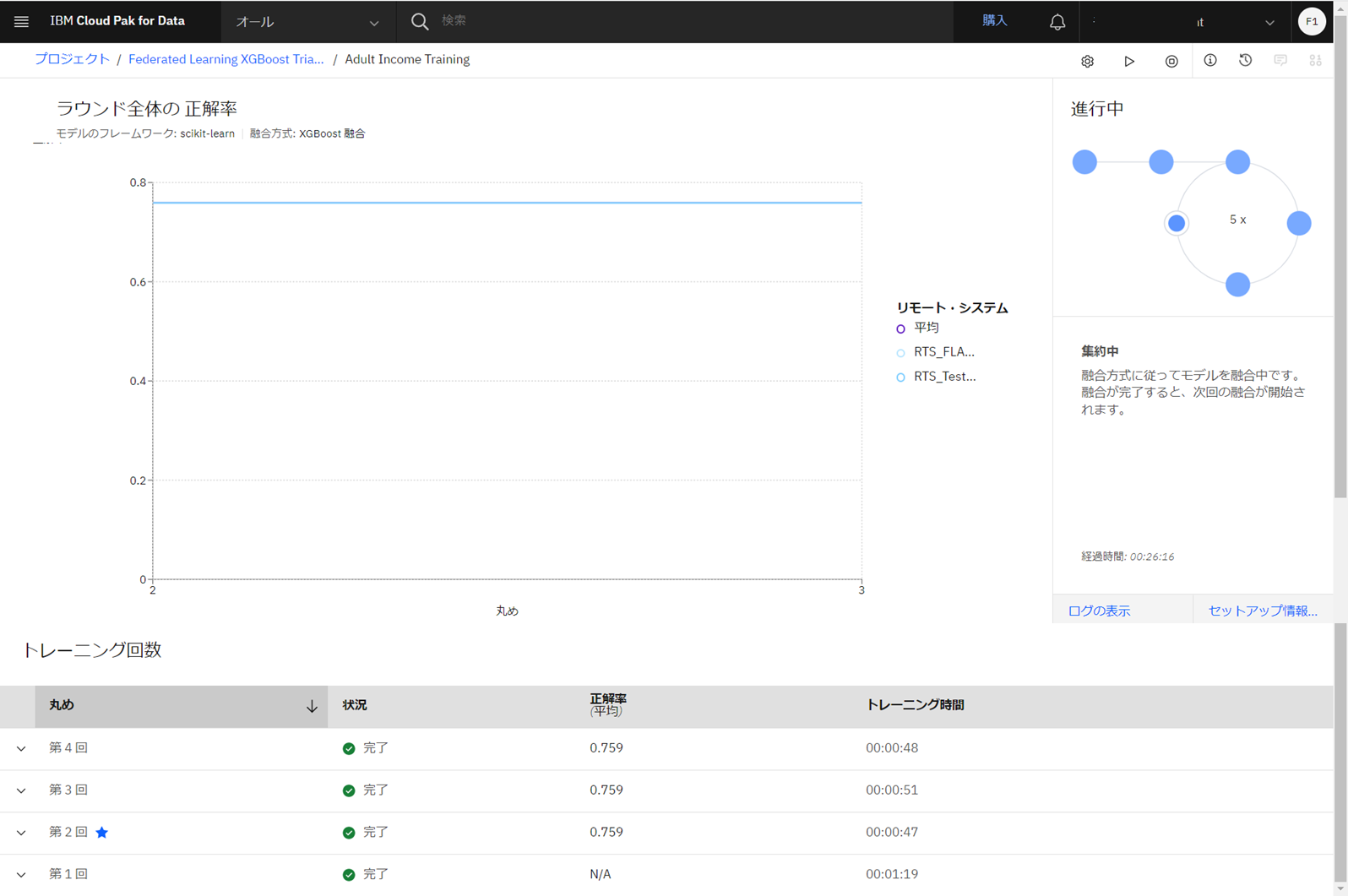
-
指定した回数のトレーニングが完了すると、party は STOP の要求を受信し、停止します。
party出力2022-04-13T13:08:31.383Z | 1.0.204 | INFO | ibmfl.party.party_protocol_handler | received a STOP request -
すべてのトレーニングが完了し、統合済みのモデルが使用可能になりました。モデルの実体はpickle形式で保存されており、Watson Machine Learning上にデプロイメントを作成したり、モデルをダウンロ―ドして任意の環境で実行することができます。
-
モデルをプロジェクトに保存
- 統合学習のUIより、「モデルをプロジェクトに保存」をクリックします。
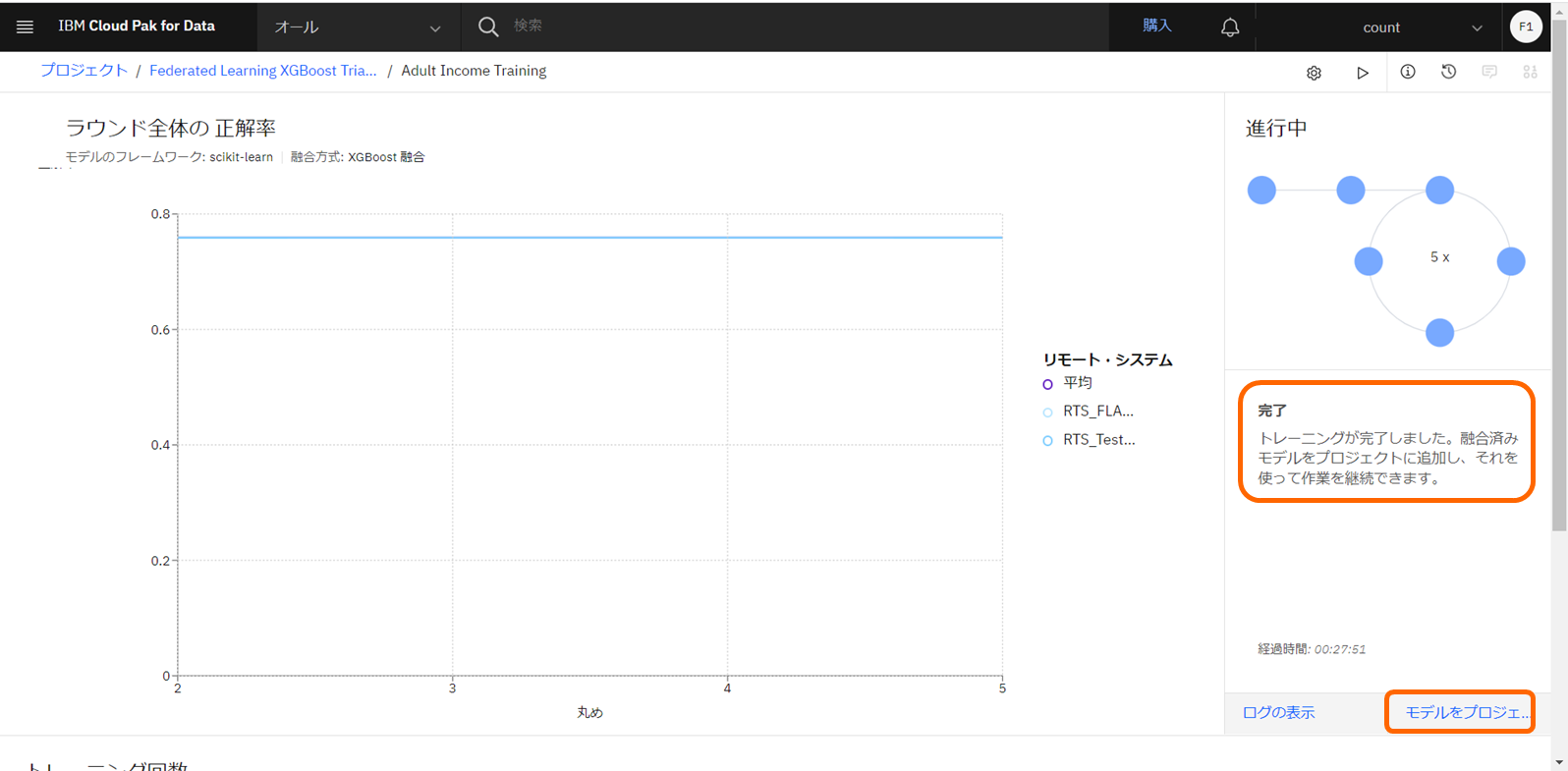
- 任意の名前と、オプションで説明を入力し、保存します。
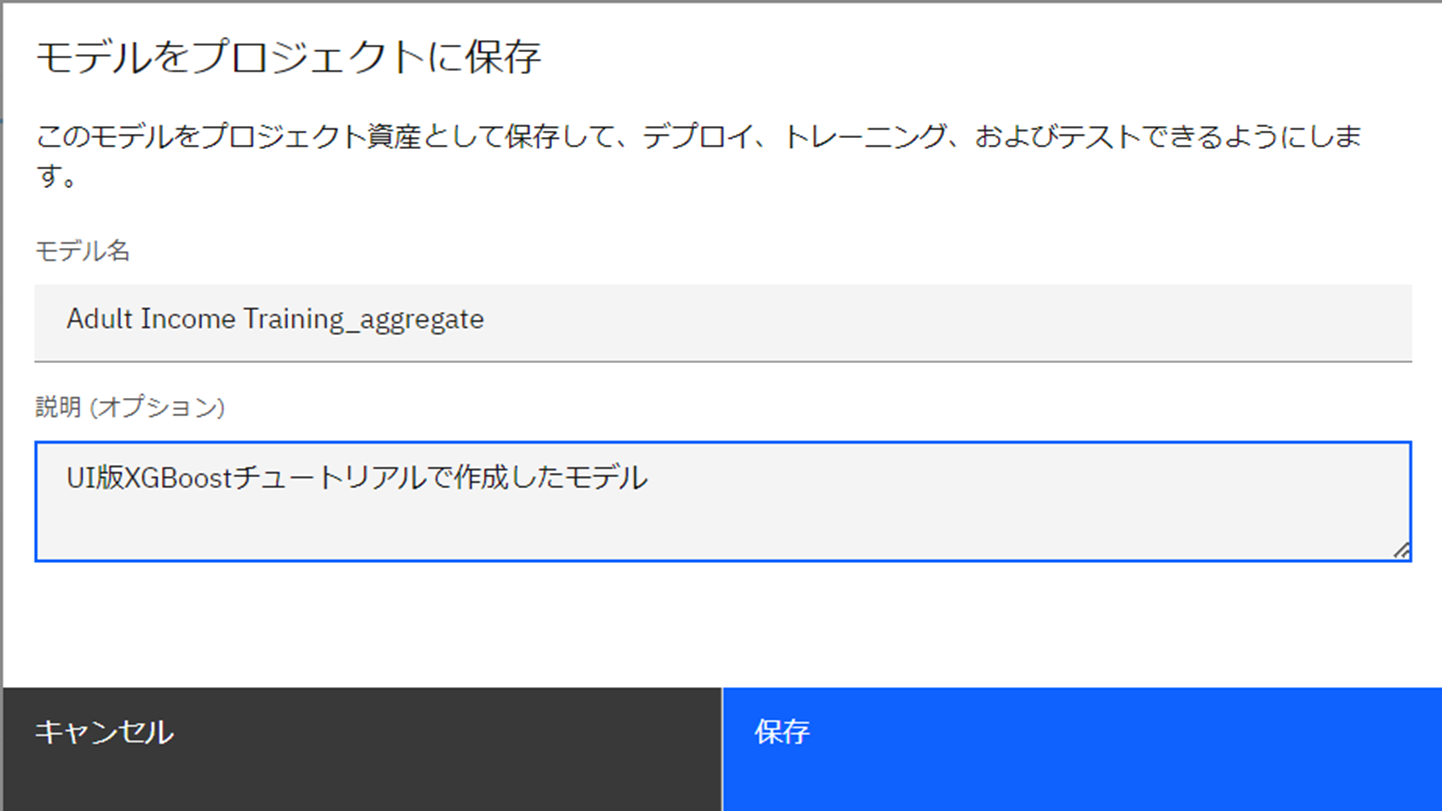
- プロジェクトの「資産」タブへ、モデルが表示されます。
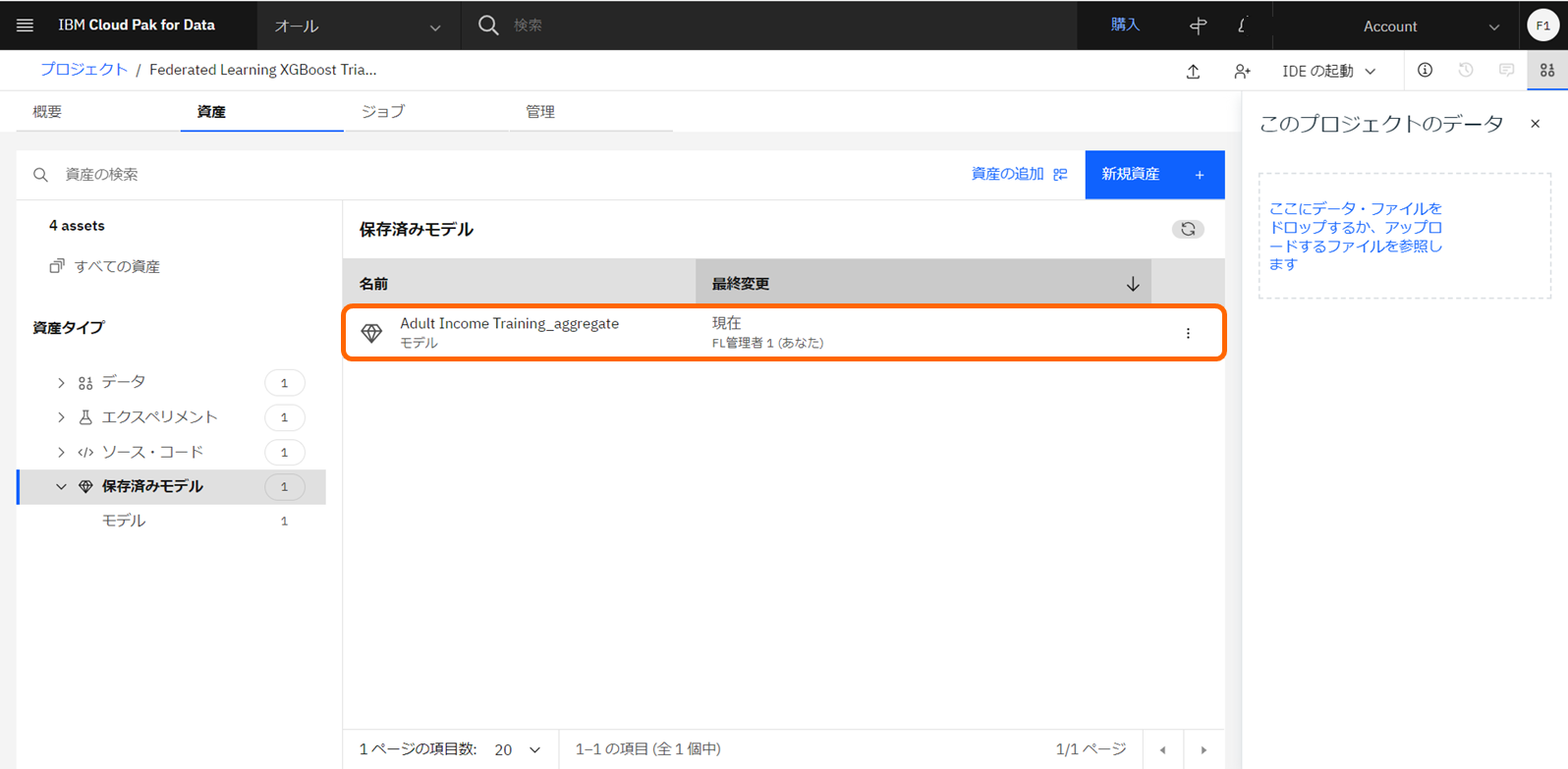
- 統合学習のUIより、「モデルをプロジェクトに保存」をクリックします。
-
モデルpickleファイルのダウンロード
- 統合学習のUIより、トレーニングIDを控えます。
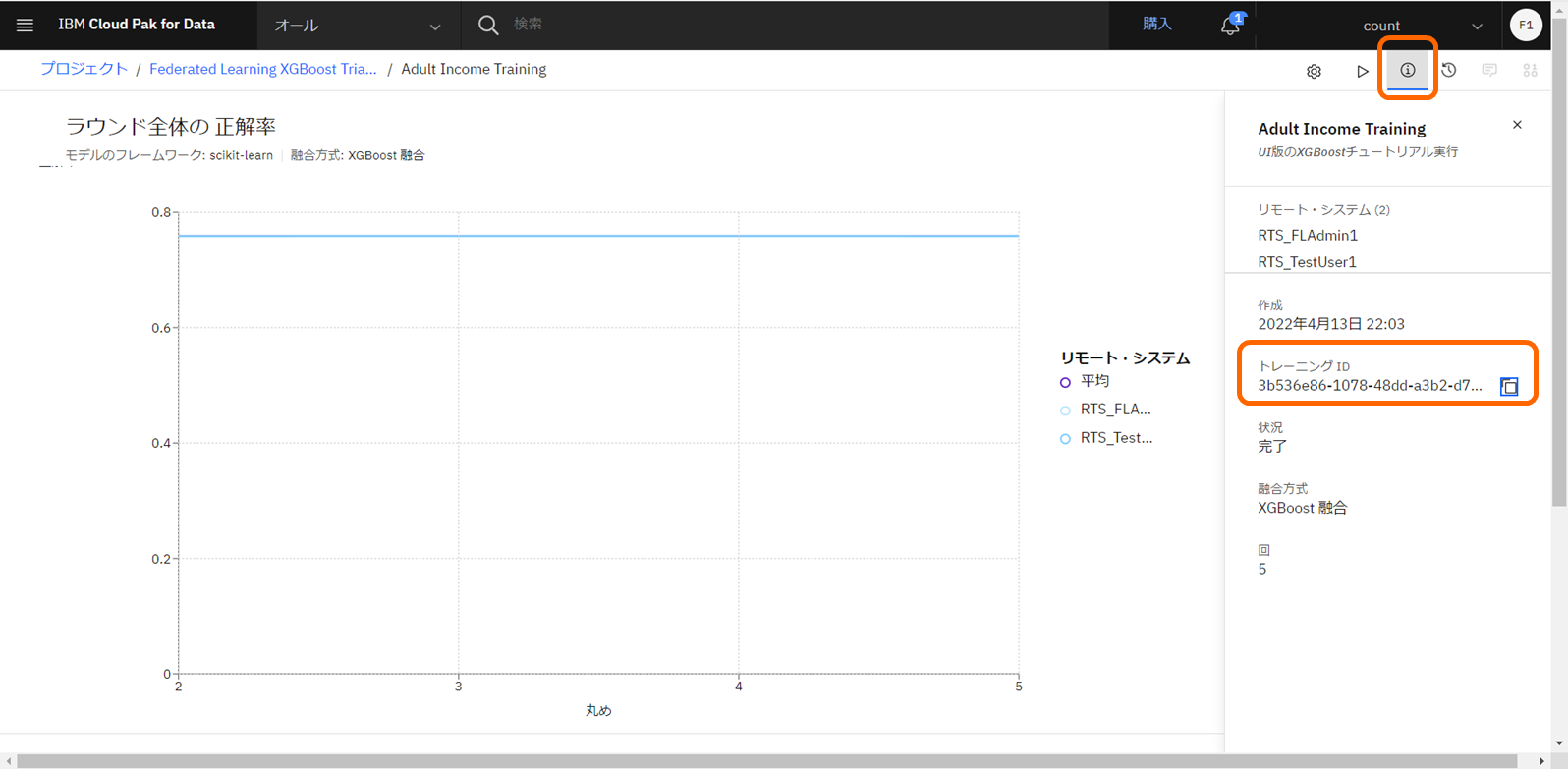
- プロジェクトの「管理」タブより、「一般」ページからプロジェクトのバケット名を確認し、「IBM Cloudで管理」をクリックします。
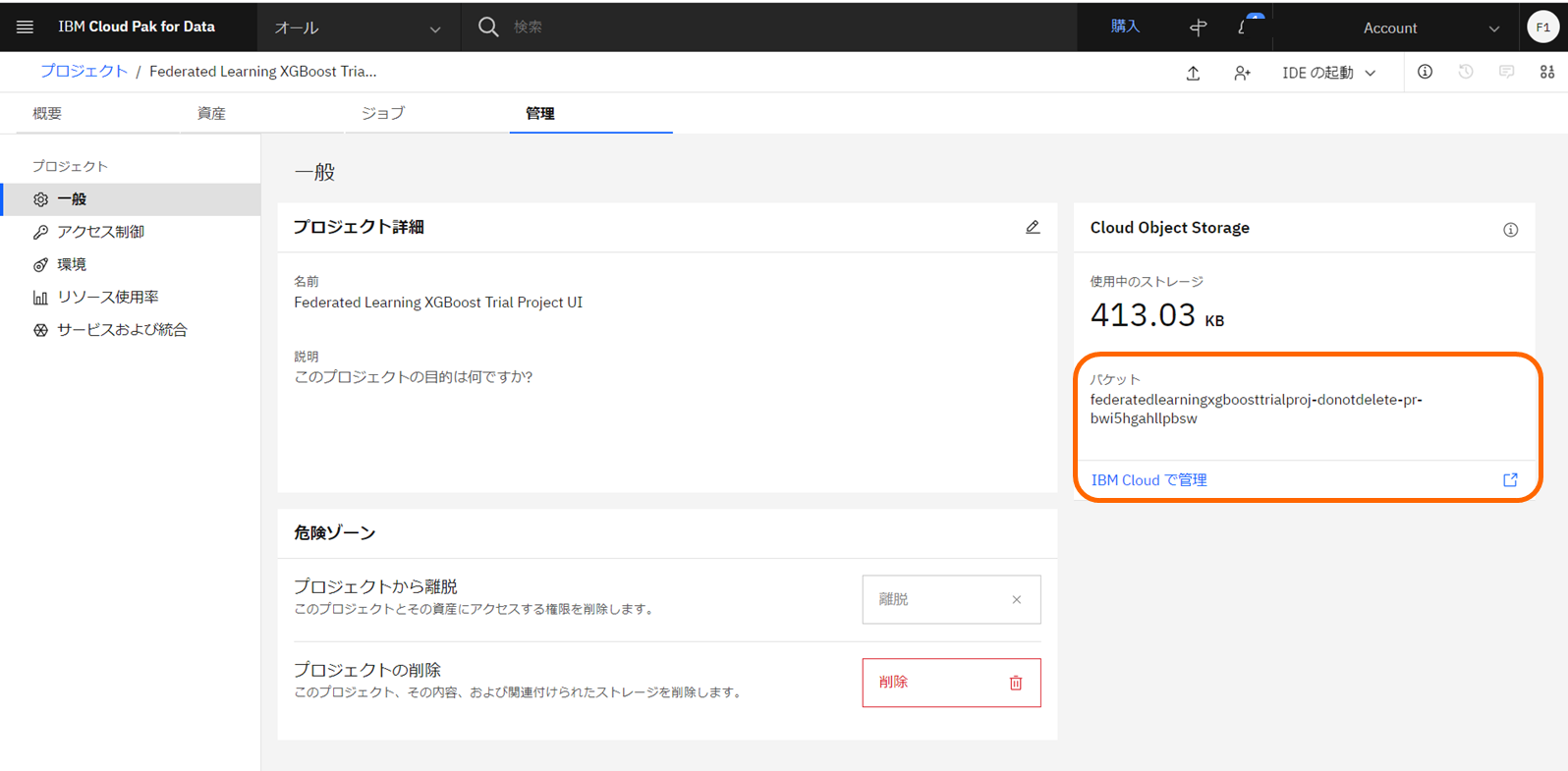
- プロジェクトのバケット名をクリックします。
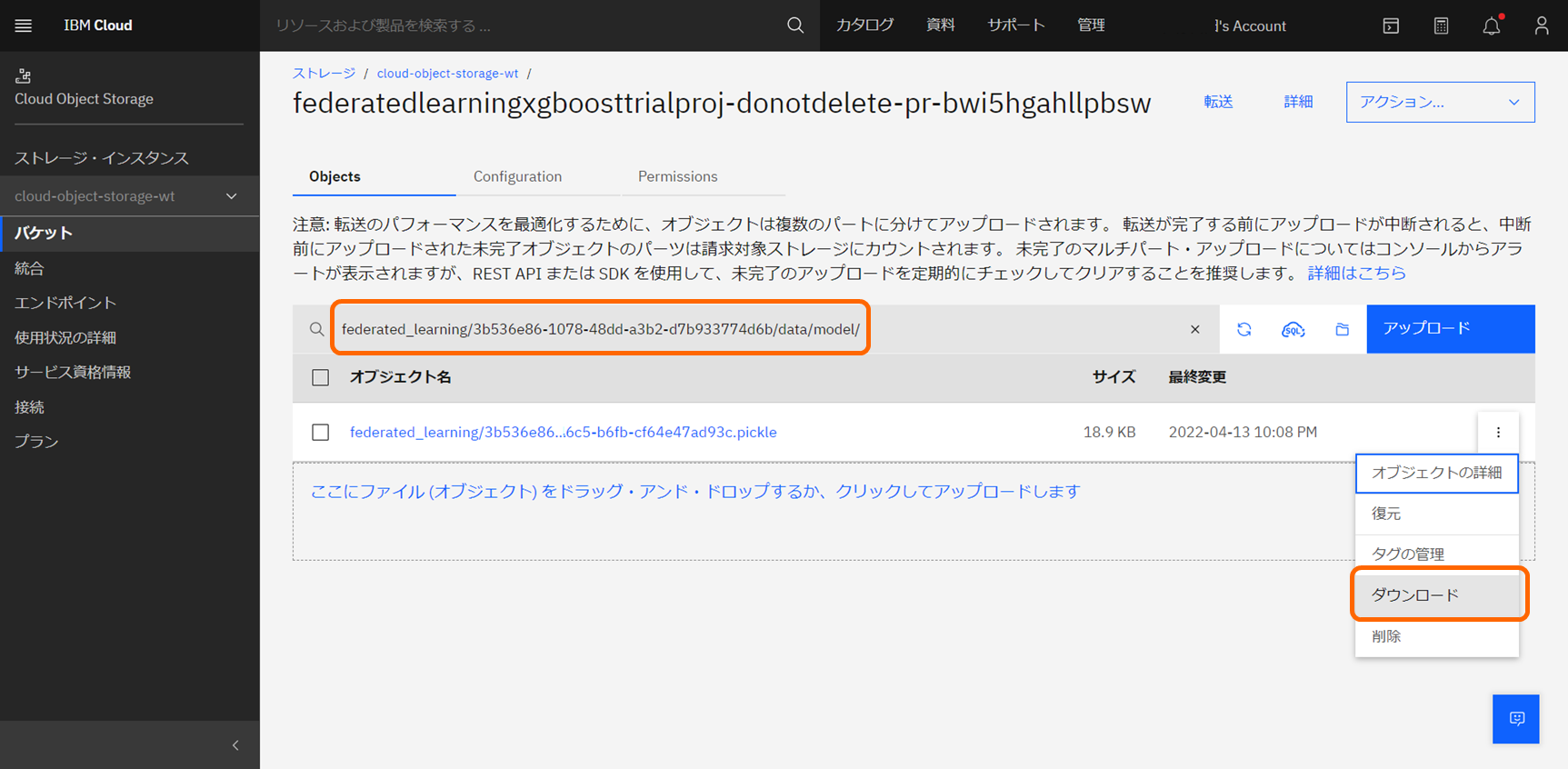
- federated_learning/
<トレーニングID>/data/model/ でフィルターし、pickleファイルをダウンロードします。
- 統合学習のUIより、トレーニングIDを控えます。
-
モデルのデプロイメント作成
Step2で作成したモデルをWatson Machine Learningへ展開し、デプロイメントを作成します。
デプロイメントを作成すると、REST APIを使用してモデルにリクエストを実行できます。
Step 3: Save and deploy the model online
https://dataplatform.cloud.ibm.com/docs/content/wsj/analyze-data/fl-xg-tutorial.html?audience=wdp&locale=en#step-3
スコアリング
Step3で作成したデプロイメントを使用し、スコアリングを実行します。
Step 4: Score the model
https://dataplatform.cloud.ibm.com/docs/content/wsj/analyze-data/fl-xg-tutorial.html?audience=wdp&locale=en#step-4
4. 関連資料
CP4DaaSのFederated Learningに関連する資料です。
製品資料:IBM Federated Learning
https://dataplatform.cloud.ibm.com/docs/content/wsj/analyze-data/fed-lea.html?audience=wdp&locale=en
APIドキュメント:Watson Machine Learning
https://cloud.ibm.com/apidocs/machine-learning-cp
Pythonライブラリ:ibm-watson-machine-learning
https://pypi.org/project/ibm-watson-machine-learning/