0. 前提
各手順の確認には、SW版のwatsonx.data および Prestoエンジンを利用しています。
また、カタログとバケットのペアおよびスキーマは、事前に追加済みのものを利用しています。
| カタログ名 | カタログ用バケット | 検証用スキーマ |
|---|---|---|
| hive_data | hive-bucket | hive_test_01 |
| iceberg_data | iceberg-bucket | iceberg_test_01 |
1. テーブル作成オプションの確認方法
watsonx.data/Prestoではテーブル作成時、オプションのWITH句を使用して、テーブルに対するプロパティを設定できます。
CREATE TABLE [ IF NOT EXISTS ]
table_name (
{ column_name data_type [ COMMENT comment ] [ WITH ( property_name = expression [, ...] ) ]
| LIKE existing_table_name [ { INCLUDING | EXCLUDING } PROPERTIES ] }
[, ...]
)
[ COMMENT table_comment ]
[ WITH ( property_name = expression [, ...] ) ]
オプションのWITH句で指定可能なプロパティは、システム・テーブル system.metadata.table_properties から確認します。
SELECT * FROM system.metadata.table_properties;
出力結果へ下記項目が含まれます。
- catalog_name: カタログタイプが含まれます。
hive_dataまたはiceberg_dataです。 - property_name: CREATE TABLEステートメントのWITH句で指定可能なプロパティ名です。
- default_value: デフォルトのプロパティ値です。
- type: プロパティ値の指定方法です。
- description: プロパティ名の説明です。

watsonx.data製品資料: CREATE TABLE statement
https://www.ibm.com/docs/en/watsonxdata/1.1.x?topic=statements-create-table
2. パーティション表の作成
1. Hiveテーブル
① テーブルのプロパティ確認
まず、CREATE TABLE のWITH句で指定するため、パーティション表のプロパティを確認します。
システム・テーブル system.metadata.table_propertiesを照会する際、WHERE条件で catalog_name='hive_data' AND property_name LIKE '%partition%' とすることで、Hiveテーブル向けかつパーティション関連のプロパティに絞り込みます。
SELECT *
FROM system.metadata.table_properties
WHERE
catalog_name='hive_data' AND
property_name LIKE '%partition%'
;
プロパティ名 partitioned_by がヒットしました。
CREATE TABLE のWITH句で、このプロパティを指定すれば良さそうです。

② テーブル作成
パーティション表を作成します。
Hiveテーブルにけるパーティションキーは、テーブルの最後の列位置(右端)で、テーブルのプロパティと同じ順序であることが必要です。
例では、year/month/day の3列をパーティションキーとして指定します。
/*Hiveテーブルのパーティション表作成*/
CREATE TABLE hive_data.hive_test_01.hive_sample_partition_table(
id INT,
val_1 INT,
val_2 DECIMAL,
val_3 DECIMAL,
measure_timestamp TIMESTAMP,
year INT,
month INT,
day INT
) WITH (
partitioned_by = ARRAY ['year', 'month', 'day']
);
パーティション表が作成されました。

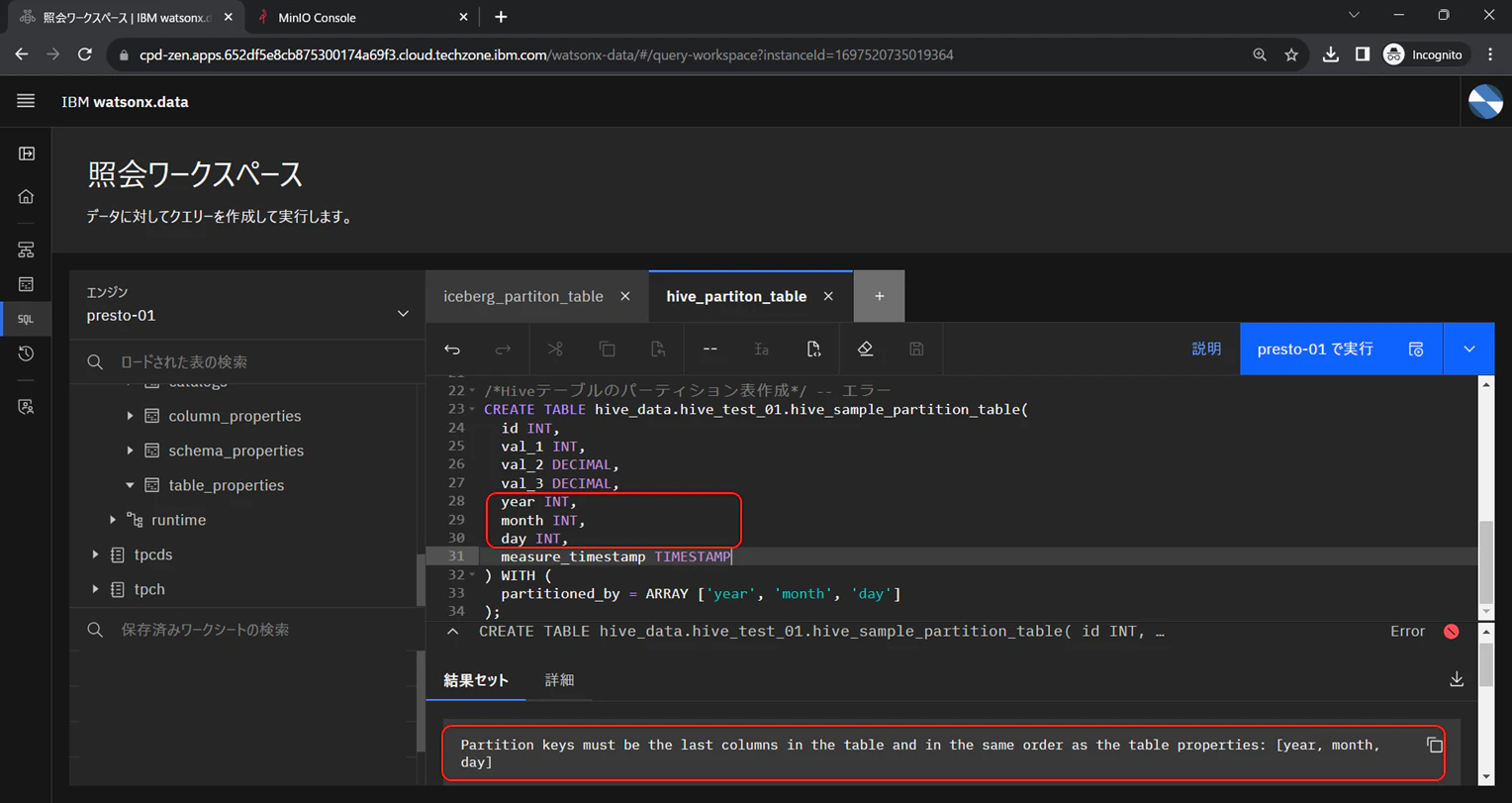
パーティション表作成の失敗例
パーティションキーはテーブルの最後の列位置(右端)で、テーブルのプロパティと同じ順序であることが必要ですが、試しにパーティションキーの列位置を中間に配置したCREATE TABLE文を実行してみます。
/*Hiveテーブルのパーティション表作成*/ -- エラー
CREATE TABLE hive_data.hive_test_01.hive_sample_partition_table2(
id INT,
val_1 INT,
val_2 DECIMAL,
val_3 DECIMAL,
year INT,
month INT,
day INT,
measure_timestamp TIMESTAMP
) WITH (
partitioned_by = ARRAY ['year', 'month', 'day']
);
やはりテーブル作成は失敗し、下記のエラーメッセージが返されました。
Partition keys must be the last columns in the table and in the same order as the table properties: [year, month, day]
③ テーブルへデータを挿入
パーティションキー day に、それぞれ異なる値を指定した行をINSERTします。
-- パーティションキーdayに1を指定
INSERT INTO hive_data.hive_test_01.hive_sample_partition_table VALUES
(1, 10, 0, 100, timestamp '2023-11-1 1:00:00.000', 2023, 11, 1),
(2, 20, 0, 200, timestamp '2023-11-1 2:00:00.000', 2023, 11, 1);
-- パーティションキーdayに3を指定
INSERT INTO hive_data.hive_test_01.hive_sample_partition_table VALUES
(3, 30, 0, 300, timestamp '2023-11-3 3:00:00.000', 2023, 11, 3);
④ パーティションの確認
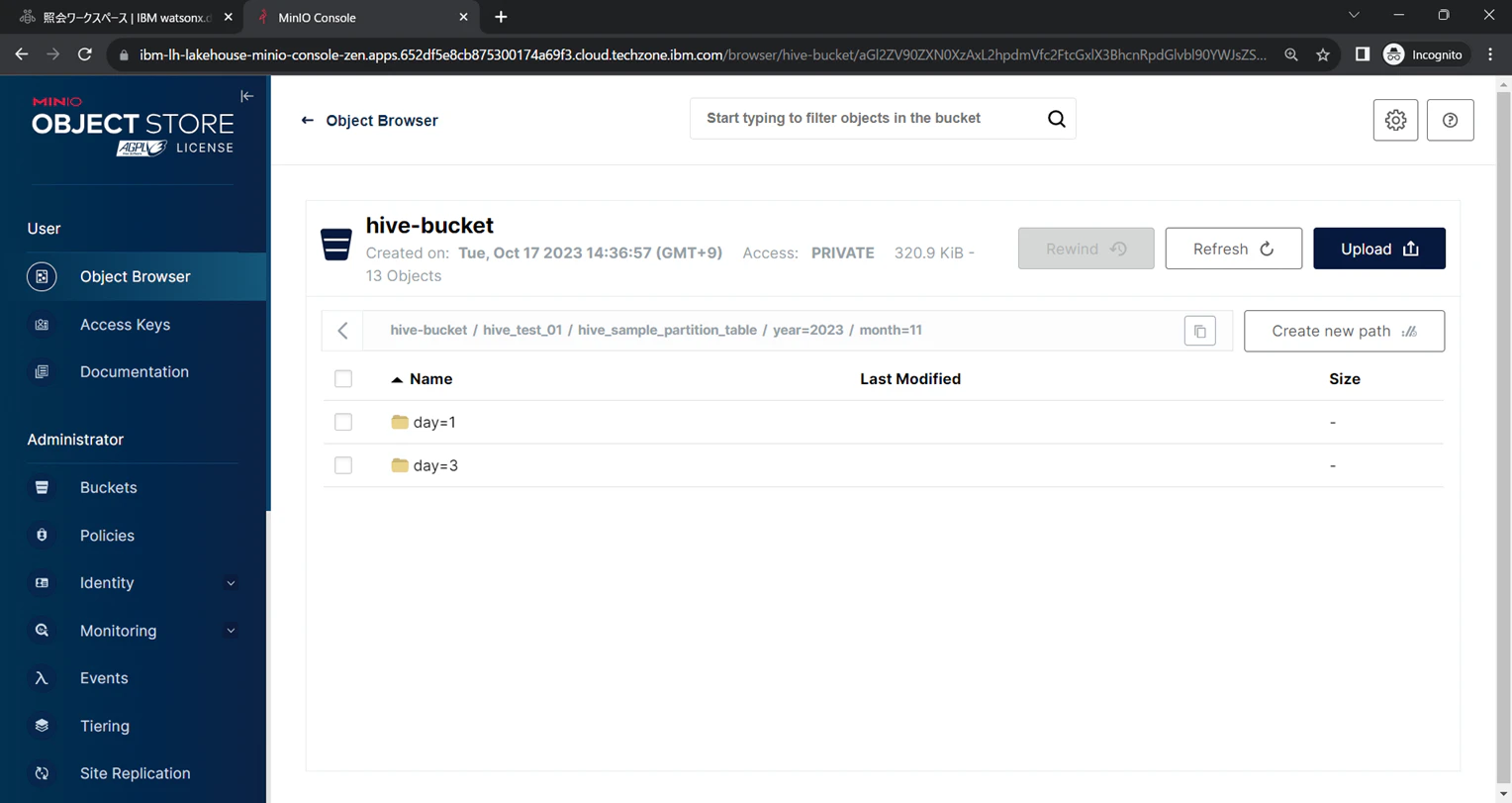
Hiveテーブルのデータファイルは、バケット上に格納されています。
テーブル用のパス配下を確認すると、パーティションキーの値に応じてさらにパスが分割されています。
パーティションキー1階層目 year

パーティションキー2階層目 month

パーティションキー3階層目 day
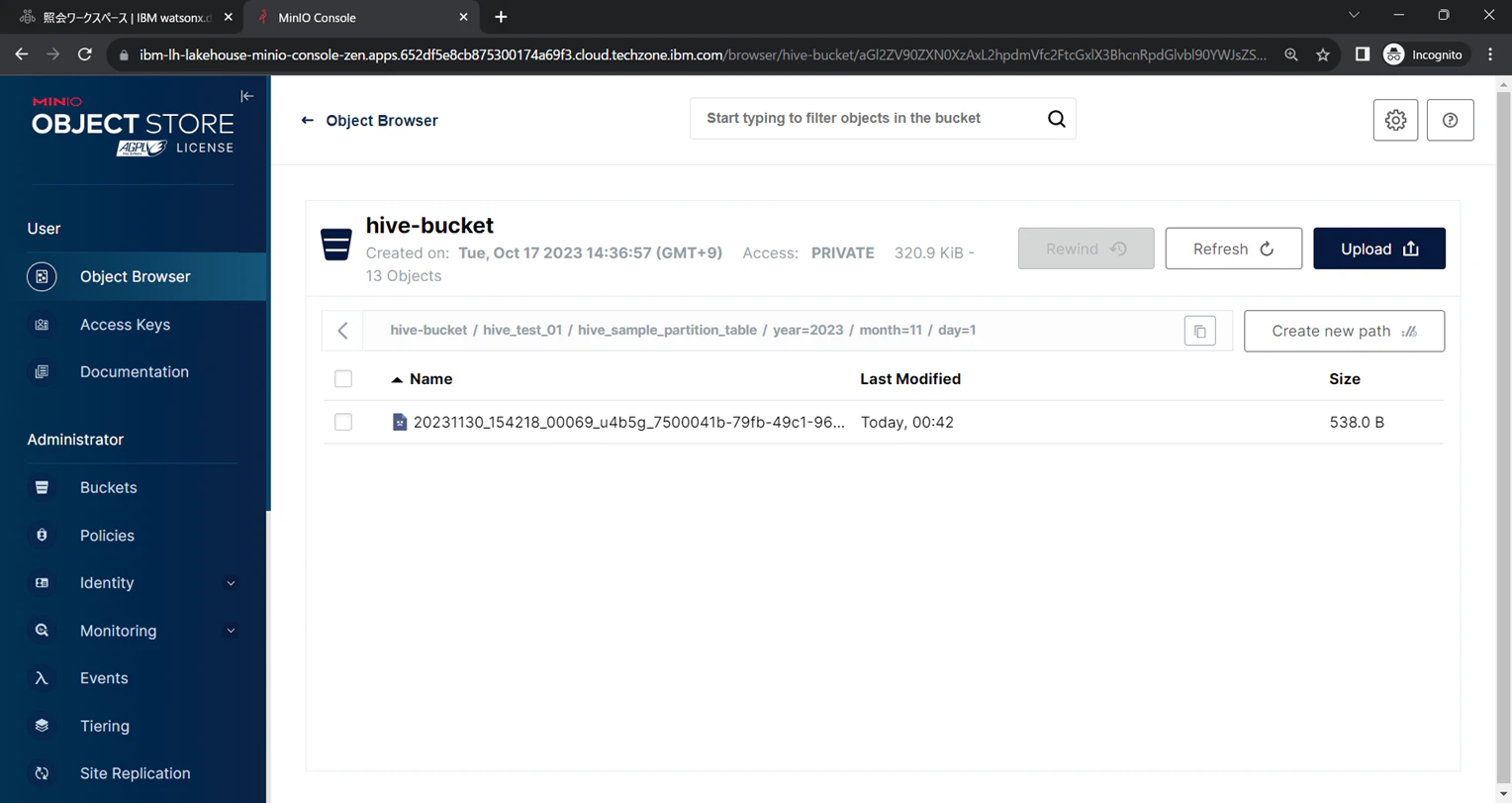
day=1とday=3に分かれていることが確認できます。
パーティションキーで分割されたパスの最下層へ、データファイルの実体が配置されています。
2. Icebergテーブル
① テーブルのプロパティ確認
まず、CREATE TABLE のWITH句で指定するため、パーティション表のプロパティを確認します。
システム・テーブル system.metadata.table_propertiesを照会する際、WHERE条件で catalog_name='iceberg_data' AND property_name LIKE '%partition%' とすることで、Icebergテーブル向けかつパーティション関連のプロパティに絞り込みます。
SELECT *
FROM system.metadata.table_properties
WHERE
catalog_name='iceberg_data' AND
property_name LIKE '%partition%'
;
プロパティ名 partitioning がヒットしました。
CREATE TABLE のWITH句で、このプロパティを指定すれば良さそうです。

② テーブル作成
パーティション表を作成します。
先述のHiveテーブルでは、パーティションキーがテーブルの最後の列位置(右端)で、テーブルのプロパティと同じ順序であることが必要でした。
一方、今回作成するIcebergテーブルではこの制約はありません。パーティションキーの列位置を中間に配置することが可能です。
例では、year/month/day の3列をパーティションキーとして指定します。
/*Icebergテーブルのパーティション表作成*/
CREATE TABLE iceberg_data.iceberg_test_01.iceberg_sample_partition_table(
id INT,
val_1 INT,
val_2 DECIMAL,
val_3 DECIMAL,
year INT,
month INT,
day INT,
measure_timestamp TIMESTAMP
) WITH (
partitioning = ARRAY ['year', 'month', 'day']
);
パーティション表が作成されました。

③ テーブルへデータを挿入
パーティションキー day に、それぞれ異なる値を指定した行をINSERTします。
-- パーティションキーdayに1を指定
INSERT INTO iceberg_data.iceberg_test_01.iceberg_sample_partition_table VALUES
(1, 10, 0.1, 100, 2023, 11, 1, timestamp '2023-11-1 1:00:00.000'),
(2, 20, 0.2, 200, 2023, 11, 1, timestamp '2023-11-1 2:00:00.000');
-- パーティションキーdayに3を指定
INSERT INTO iceberg_data.iceberg_test_01.iceberg_sample_partition_table VALUES
(3, 30, 0.3, 300, 2023, 11, 3, timestamp '2023-11-3 3:00:00.000');
④ パーティションの確認
Icebergテーブルのデータファイルは、バケット上に格納されています。
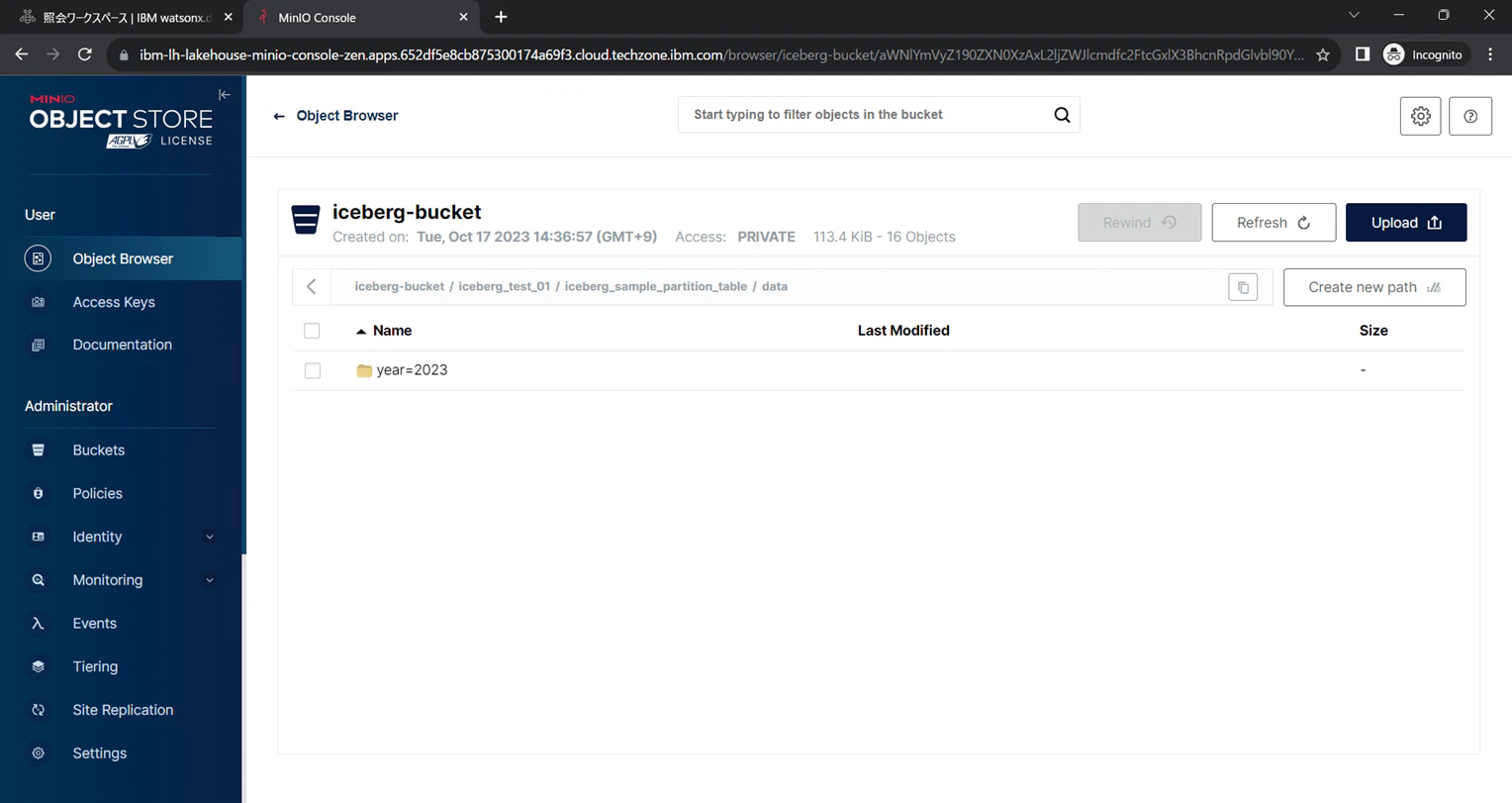
まず、テーブル用のパス配下にmetadataとdataフォルダが存在します。このうちdataフォルダを確認します。
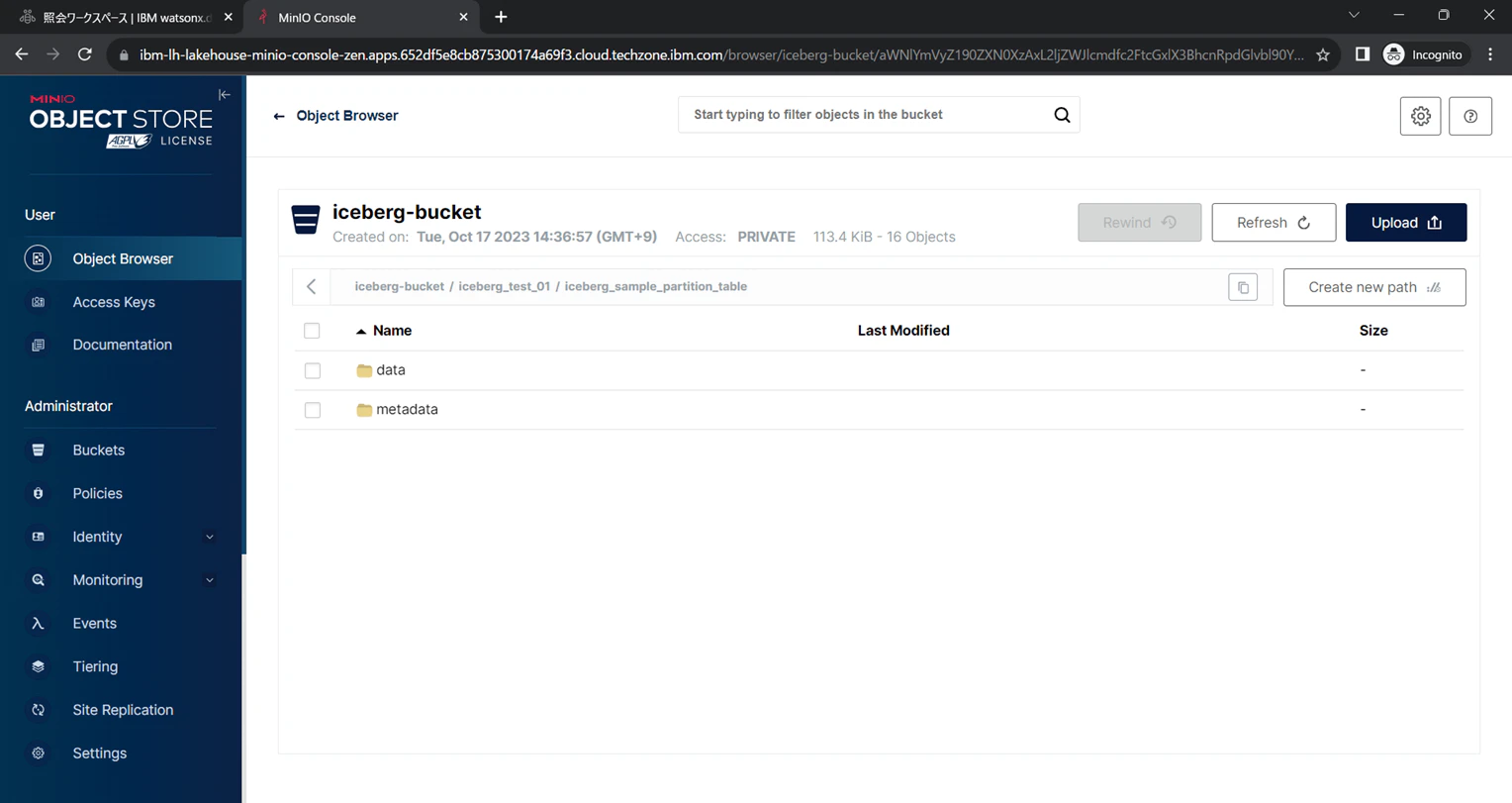
dataフォルダを確認すると、パーティションキーの値に応じてさらにパスが分割されています。
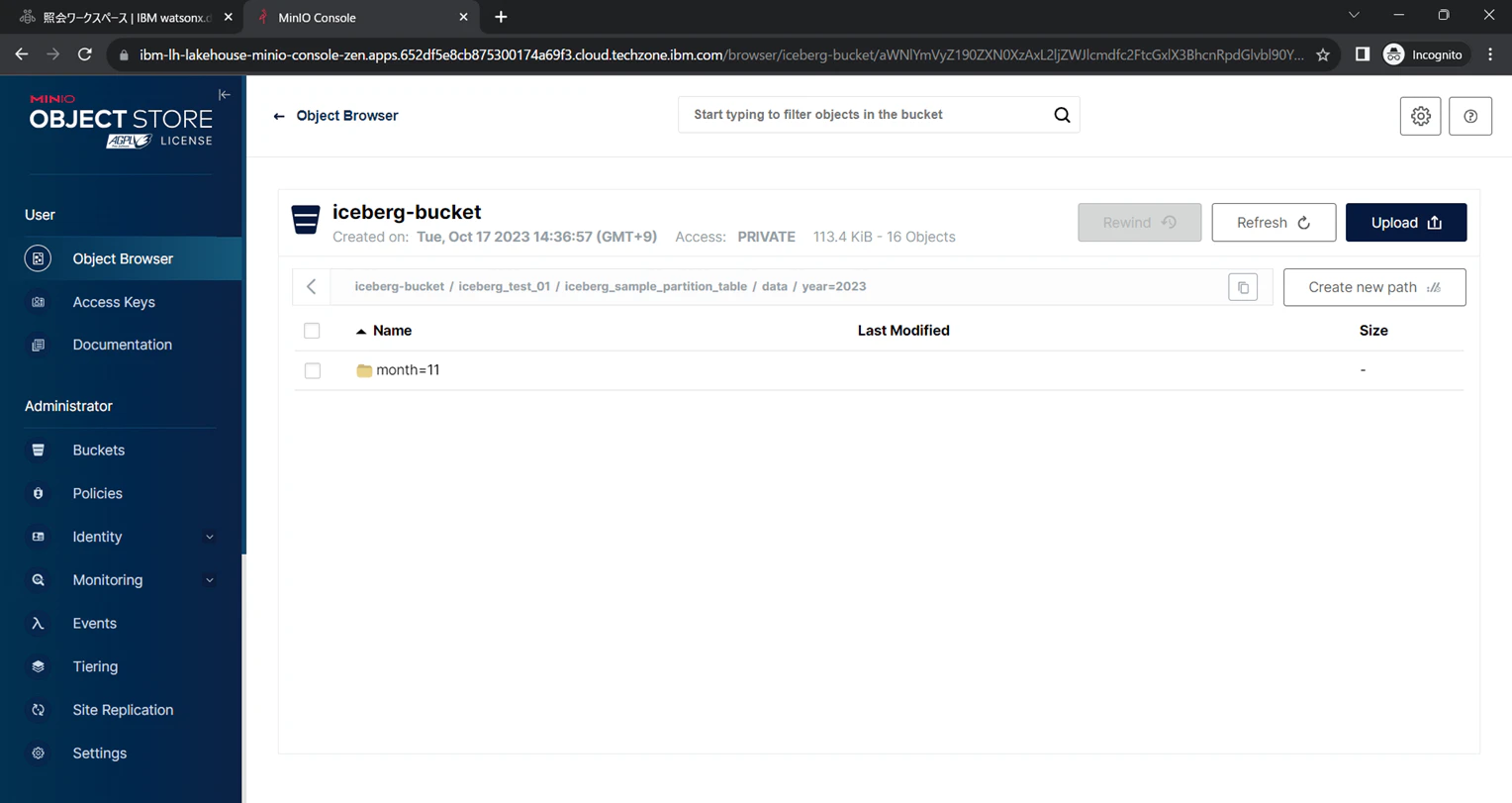
パーティションキー1階層目 year
パーティションキー2階層目 month
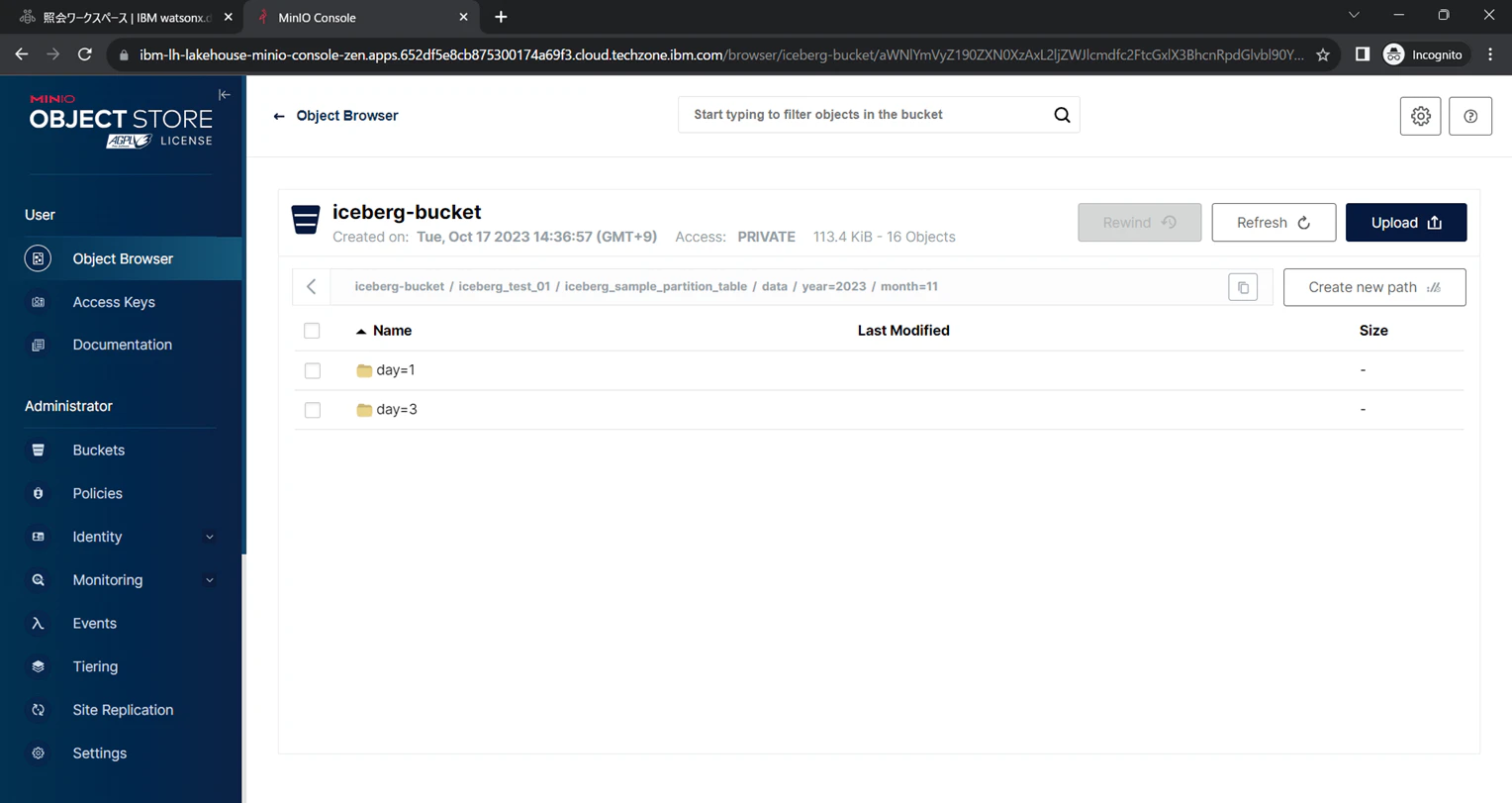
パーティションキー3階層目 day
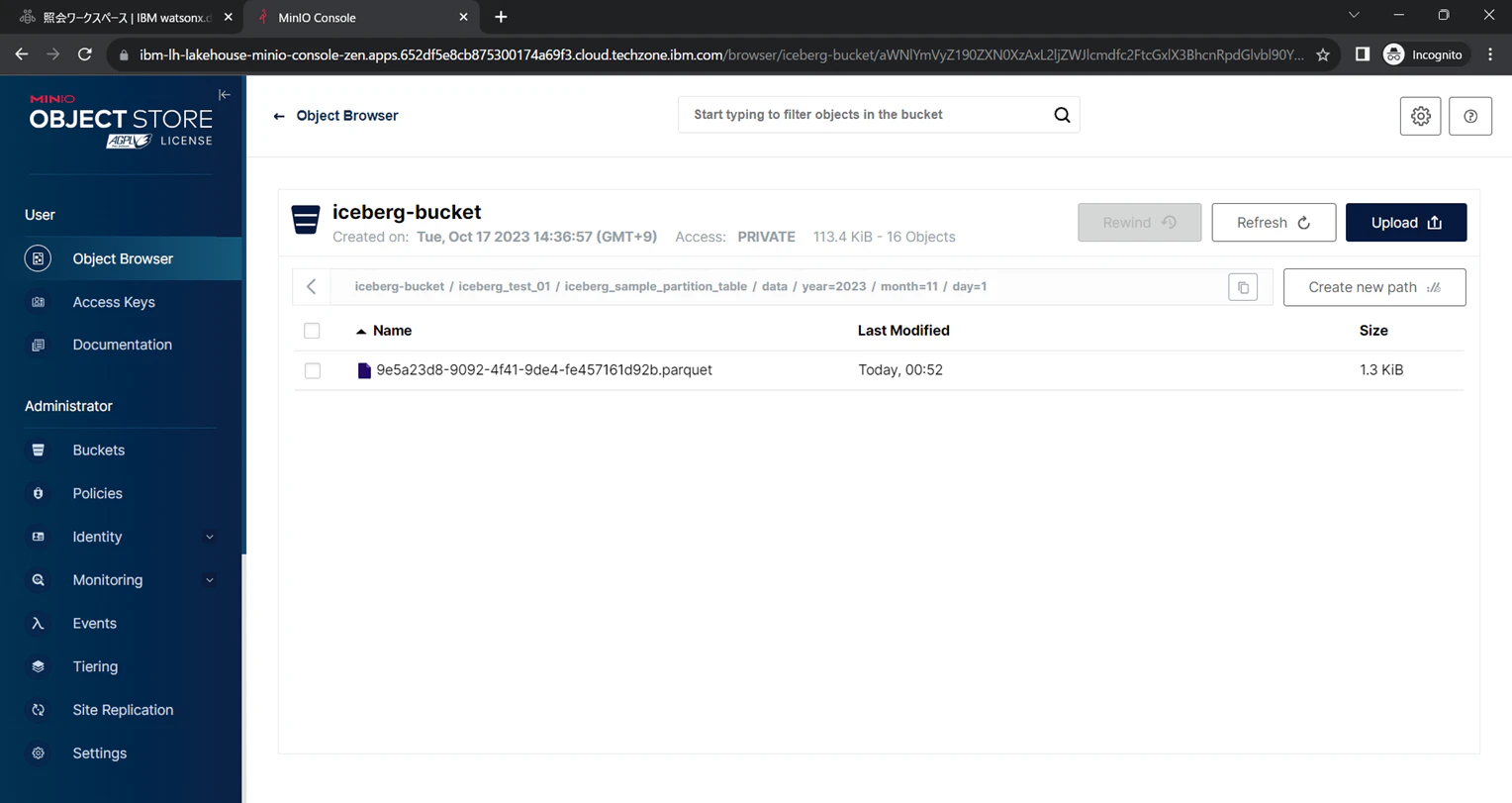
day=1とday=3に分かれていることが確認できます。
パーティションキーで分割されたパスの最下層へ、データファイルの実体が配置されています。
3. 関連資料
watsonx.data製品資料: CREATE TABLE statement
https://www.ibm.com/docs/en/watsonxdata/1.1.x?topic=statements-create-table
Presto製品資料:CREATE TABLE
https://prestodb.io/docs/current/sql/create-table.html
Apache Iceberg製品資料:Partitioning
https://iceberg.apache.org/docs/latest/partitioning/