Lambdaアーキテクチャとは何か?
Lambdaアーキテクチャは、ビッグデータ処理においてリアルタイム性(低レイテンシ)とデータ完全性・正確性を両立させることを目的に考案されたデータ処理アーキテクチャです。大量のデータを扱う場合、従来はHadoopなどによるバッチ処理で全データを一括集計し高精度な結果を得ていましたが、その結果が得られるまでに数時間〜数日かかることも多く、常に最新の状態を反映できない問題がありました。一方で、ストリーム処理(リアルタイム処理)はデータ到着の度に即座に処理を行うため低レイテンシですが、分散環境でデータ損失や重複を防ぎつつ正確性を担保することは極めて難しいという課題がありました。Lambdaアーキテクチャは、この矛盾に対しバッチ処理とリアルタイム処理の双方を組み合わせるハイブリッドな仕組みを提供します。全履歴データに基づく網羅的で正確な集計結果(ビュー)と、最新データに基づく即時的なビューを別々の経路で生成し、それらを統合してクエリに応答することで、低レイテンシと高精度の双方を実現するのがLambdaアーキテクチャの特徴です。
Lambdaアーキテクチャ登場前の課題とトレードオフ
Lambdaアーキテクチャが登場する以前、大規模データの集計にはバッチ処理とリアルタイム処理の2つの手法がありました。しかし、それぞれ次のようなトレードオフを抱えていました。
-
バッチ処理の限界: 大量データをまとめて処理するバッチ処理では、過去を含む全データから高精度な結果を得られる一方、その処理完了までに長時間(時に数時間〜日単位)が必要です。そのため最新のデータ変化を即座に反映できないという欠点がありました。例えば深夜にバッチ集計を行う場合、日中に起きた変化は次の集計までシステムに反映されません。このタイムラグは、刻一刻と変化するビジネス状況に追随する上で大きな障壁となっていました。
-
リアルタイム処理の課題: 一方、ストリーム処理(リアルタイム処理)はデータ到着ごとに瞬時に計算を行うため、最新情報を即時に得ることができます。しかし処理の信頼性と正確性を保つことが極めて困難です。常時稼働するストリーミングシステムでは障害発生時にも処理を続行する必要があり、遅延到着や順序乱れしたデータの整合性保持、エラー検出と補正、重複除去など解決すべき問題が多数あります。一度流れてしまったデータを後から再計算・修正するのも容易ではなく、複雑な状態管理が必要になります。結果として、リアルタイム処理のみで全データの完全な正確性を保証するのは非常に難しいのです。
こうした背景から、「すぐに最新状況を知りたい」という要求と「過去を含めた全データを正確に集計したい」という要求は表面的には相反するものでした。単一のパイプライン上でこれら双方を実現しようとすると、システム設計が極度に複雑化し、僅かな不整合が連鎖的に累積して全体の信頼性を損なうリスクが高まります。つまり、リアルタイム性と正確性を一つの仕組みで両立しようとすること自体が大きな技術的挑戦であり、従来は低レイテンシを追求すれば精度を犠牲に、精度を追求すれば即時性を犠牲にせざるを得ないというトレードオフの限界に直面していたのです。
Lambdaアーキテクチャの3層モデルと解決策
Lambdaアーキテクチャは上記の課題を解決するため、データ処理基盤を3つのレイヤーに分離するアプローチを取ります。具体的には1) バッチレイヤー、2) スピードレイヤー、3) サービングレイヤーの3層モデルを採用し、それぞれ役割を分担させることで低レイテンシと高精度の両立を図ります。以下に各レイヤーの役割を説明します。
バッチレイヤー (Batch Layer)
イミュータブルな生データのマスタデータセットを蓄積し、分散バッチ処理によって網羅的かつ高精度な集計結果(バッチビュー)を定期的に生成するレイヤーです。バッチレイヤーでは過去も含めたすべてのデータを一から計算し直すため、多少時間はかかっても誤差や抜け漏れのない正確な結果を得ることができます。仮に過去の計算に誤りやデータ不整合があっても、次回のバッチ処理で全データを再計算することで修正できるため、常に真実性の高いデータビューが保証されます。
スピードレイヤー (Speed Layer)
データ到着からバッチ処理完了までの間に生じるタイムラグを埋めるために、最新データのみをリアルタイムで取り込み、即座に簡易な集計処理を行って近時点のビュー(リアルタイムビュー)を生成する層です。スピードレイヤーは低レイテンシを最優先するため、処理対象は直近の増分データに限定され、計算ロジックも必要最小限に留めます。その代わり一部データの重複や誤差を許容する設計となっており、バッチレイヤーほどの完全性・網羅性は担保しません。言い換えれば、スピードレイヤーは精度と引き換えにリアルタイムで結果を提供する役割を担っています。
サービングレイヤー (Serving Layer)
バッチレイヤーで生成されたバッチビューと、スピードレイヤーで生成されたリアルタイムビューを統合して保持し、外部からのクエリに応答する層です。サービングレイヤー上には高速な問い合わせに適したデータストアが用意され、クエリ要求が来るとまずバッチビュー(過去分の確定値)を参照し、そこにスピードビュー(最新分の暫定値)を適宜加算・上書きして結果を返します。この仕組みにより、利用者は単一の問い合わせで過去から直近まで含めた、できる限り最新かつ正確な集計結果を得ることができます。スピードレイヤー由来の結果に多少の誤差があっても、次のバッチ処理完了時により正確な値で上書きされるため、最終的なデータ整合性も損なわれません。
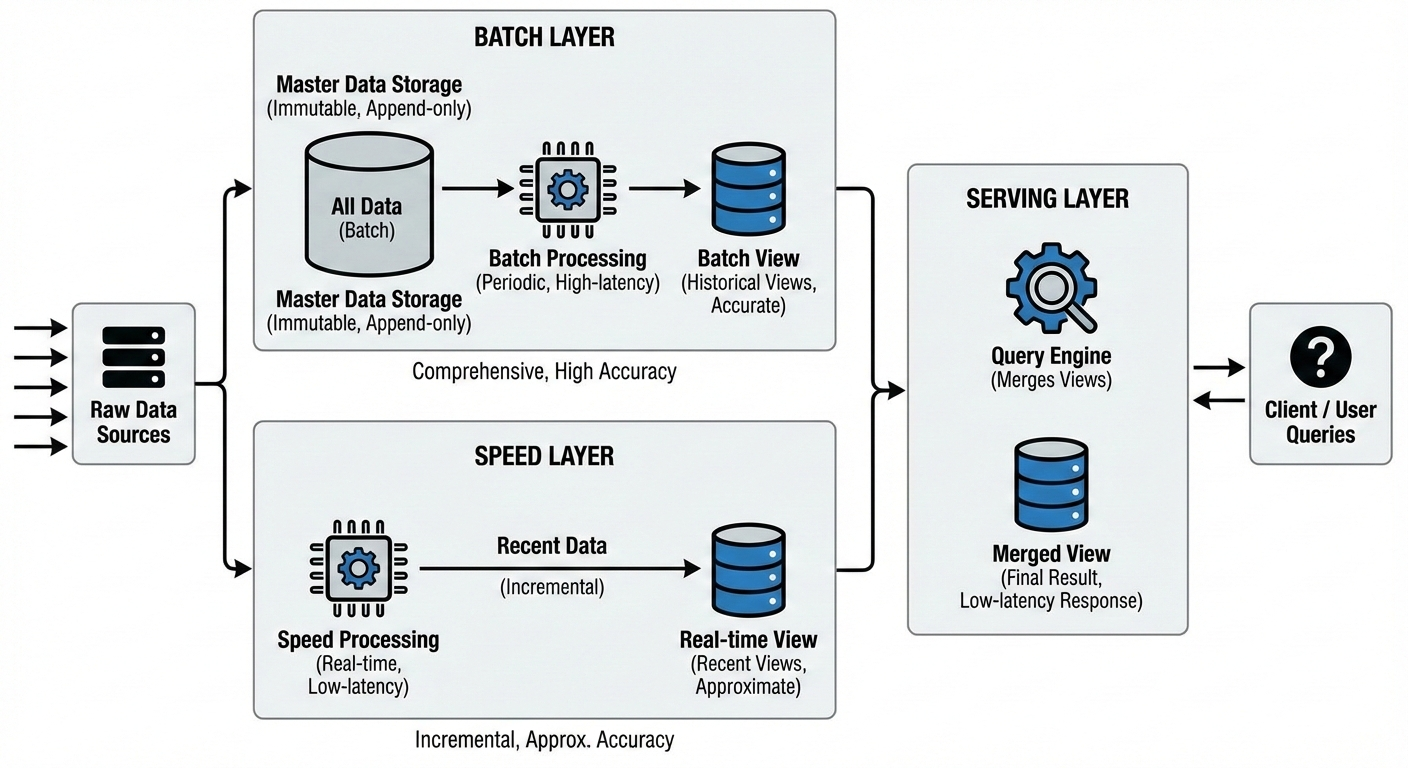
Fig. 1 Lambdaアーキテクチャの3層構成(バッチレイヤー、スピードレイヤー、サービングレイヤー)の概略図。バッチ処理系とリアルタイム処理系が並行してデータを処理し、その結果が統合されて利用者に提供される。
以上のようにLambdaアーキテクチャでは、時間軸に沿って速度を犠牲にした正確な計算と正確さを一部犠牲にしたリアルタイムな計算を分業させています。バッチレイヤーが提供する過去データに基づく正確な集計結果と、スピードレイヤーが提供する速報結果とをサービングレイヤーで相補的に合成することで、単一の処理系では両立し得なかった低レイテンシと高精度の共存を実現しているのです。
Lambdaアーキテクチャがもたらす利点と具体例
Lambdaアーキテクチャを採用することで、企業のデータ活用には大きなメリットが生まれます。最新の状況を逃さず捉えつつ、長期間の蓄積データに基づいた信頼性の高い分析が可能になるため、より的確でタイムリーな意思決定を行えるようになります。
例えば、大規模なSNSにおけるトレンド分析のケースを考えてみましょう。Xでは特定のハッシュタグに関する過去の累計ツイート数に加えて、直近数秒〜数分間の投稿数をリアルタイムに把握することで、より緻密なトレンド変化を分析しています。Lambdaアーキテクチャを用いることで、長期的な履歴データに基づく正確な集計とある瞬間の投稿動向に基づく即時集計を組み合わせて提供することが可能になります。これにより、急上昇中の話題をいち早く検知しつつ、その勢いを過去の傾向と比較して評価するといった高度なリアルタイム分析が実現できます。
またマーケティング分野でも、Lambdaアーキテクチャの利点は大いに活かされています。たとえばECサイトにおいてユーザーの行動を検知した際、スピードレイヤーで直近の行動データを即座に分析しつつ、バッチレイヤーで蓄積された当該ユーザーの過去の購買・閲覧履歴と突き合わせることで、そのユーザーに最適なリアルタイムの施策(レコメンデーションやクーポン配信など)を行うことができます。このように現在のコンテキストと蓄積されたコンテキストの両方を同時に考慮した意思決定ができる点は、Lambdaアーキテクチャならではの強みと言えるでしょう。
まとめ
Lambdaアーキテクチャは、従来トレードオフ関係にあった低レイテンシと高精度というニーズを満たすために考案された画期的な設計手法です。バッチ処理系とリアルタイム処理系という二つの経路を並行運用し、その結果を統合することで、システム全体としてリアルタイム性と信頼性を同時に提供するデータ処理基盤を実現しました。これにより、最新データの迅速な活用と長期データに基づく正確な分析を両立でき、ビジネス要求に対してタイムリーかつ正確なインサイトを享受できます。我々エンジニアにとってLambdaアーキテクチャの概念を理解することは、ビッグデータ時代のシステム設計における重要な指針となるでしょう。今回紹介した3層モデルの考え方は、将来的なデータ基盤の設計やアーキテクチャ選定において大いに役立つはずです。各々のシステム要件にLambdaアーキテクチャは当てはまるのか、はたまた別のデザインが適当なのか考えてみるのも面白いかもしれません。