0.はじめに
近年の自然言語処理(NLP)における最大の進化は、「意味」を数式で扱えるようになったことにあります。
その根幹を支えているのが「ベクトル化」と「確率的予測」という2つの概念です。
ChatGPTのような大規模言語モデル(LLM)は、人間のように“言葉の意味”を理解しているわけではありません。
ではなぜ、あれほど自然な会話ができ、意味の通った文を生成できるのか?
その秘密は、「単語や文の意味」を数値の並び(ベクトル)に変換し、「次に出現しそうな単語」を確率で予測するという、極めて数学的なプロセスにあります。
この記事では、ChatGPTの出力が“意味あるもの”に見える仕組みを、
1.単語ベクトル(埋め込み)
2.文脈処理
3.出力トークンの確率分布とサンプリング
という3つの観点から、丁寧に解説していきます。
1. 単語は数値のベクトルで表現されている(意味の埋め込み)
AIは文字列をそのまま扱うことはできません。たとえば「リンゴ」という単語を見ても、コンピュータにとってはただの記号列にすぎません。
そこで登場するのが、「単語のベクトル化(埋め込み)」です。
これは、単語を高次元の数値ベクトル(例:768次元や1,024次元など)として表現する手法です。
たとえば:
「りんご」→ [0.14, -0.72, ..., 0.91]
「みかん」→ [0.15, -0.70, ..., 0.89]
「自動車」→ [-0.42, 0.25, ..., -0.88]
このように、意味が近い単語ほど、ベクトル空間上でも近くに配置されるという性質があります(= 意味の幾何学化)。これにより、AIは「類似語」や「言い換え」を数値的に捉えられるようになります。
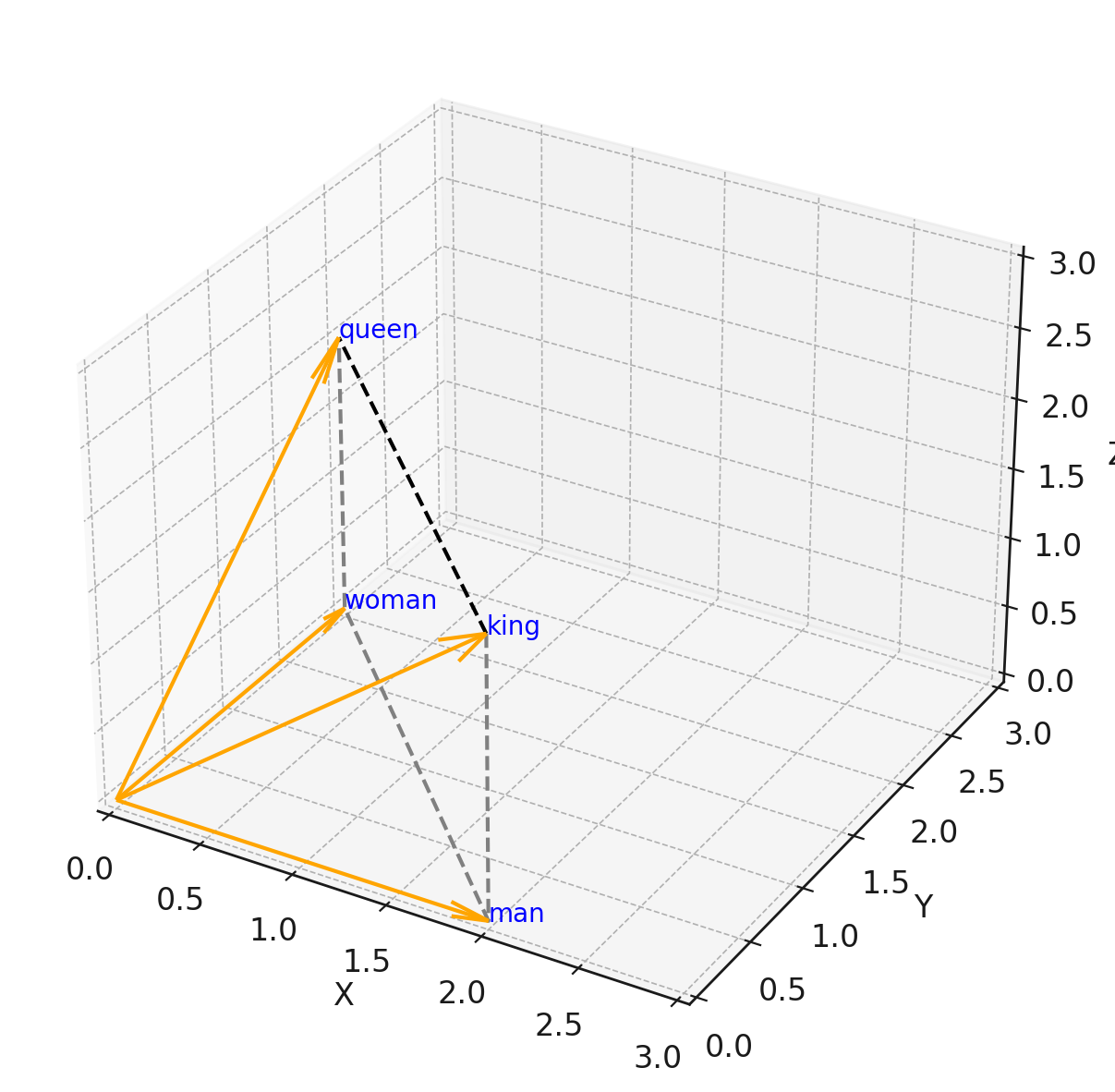
実際、以下のようなベクトル間の差分が意味的な関係を表すことが知られています:
king - man + woman = queen
下図のように、kingとqueenの関係は、manとwomanの関係とほぼ同じ方向のベクトル差として表されます。
2. 文脈は「自己注意機構」で処理されている
単語がベクトルになっただけでは、文章の意味までは理解できません。
たとえば、「私は犬が好きだ」と「犬は私が好きだ」は、使っている単語は同じでも、意味がまったく異なります。
このような文脈の違いを捉えるために使われるのが、Self-Attention(自己注意機構)です。
Self-Attentionは、ある単語の意味を決める際に、「他のどの単語をどれだけ重視すべきか」を自動的に計算します。
例1:「私は犬が好きだ」
この文では、「好きだ」という動詞の主語は「私」です。
したがって、「好きだ」の意味を理解するには、「私」に強く注目する必要があります。
| 単語 | 「好きだ」に対するAttentionの重み |
|---|---|
| 私 | 0.60 |
| は | 0.05 |
| 犬 | 0.30 |
| が | 0.05 |
| 好きだ | - |
例2:「犬は私が好きだ」
こちらの文では、主語が「犬」に変わっており、「好きだ」の対象が変化しています。
このときSelf-Attentionは、「好きだ」に対して「犬」のベクトルをより強く参照します。
| 単語 | 「好きだ」に対するAttentionの重み |
|---|---|
| 私 | 0.25 |
| は | 0.05 |
| 犬 | 0.65 |
| が | 0.05 |
| 好きだ | - |
どうやって重みが決まるのか?
Self-Attentionでは、各単語のベクトルから次の3つが計算されます:
Query(質問):「今、何を知りたいか?」(例:好きだ)
Key(鍵):「この単語は、どんな情報を持っているか?」
Value(値):「実際に取り出す意味内容」
「好きだ(Query)」が、「私」「犬」などのKeyベクトルとどれだけ関係があるかをスコア化し、
それをSoftmax関数で正規化して確率的な重み(Attention)として使います。
この仕組みにより、ChatGPTのようなモデルは「同じ単語でも、文脈に応じて意味を変える」ことができます。
つまり、「好きだ」は固定された意味を持っているのではなく、前後の単語との関係を動的に計算して意味を調整しているのです。
3. 出力は「確率分布」から選ばれる
ベクトルで意味を表現し、文脈で意味を調整した後、ChatGPTは次のトークン(単語や記号)を出力します。
その出力は、確率分布に基づいて決定されます。
例として:
「私はコーヒーが」の後に来る単語の確率分布が以下のようになったとします:
| トークン | 選ばれる確率 |
|---|---|
| 好き | 0.65 |
| 嫌い | 0.15 |
| 飲めない | 0.08 |
| 赤い | 0.01 |
このとき、ChatGPTは確率的に「好き」を選ぶわけです。
ただし、ここで「温度(temperature)」というパラメータによって、どれくらい“ランダムさ”を加えるかが調整できます。これによって、「毎回同じ答え」ではなく、「多様性のある自然な文」が生まれる仕組みになっています。
4. 終わりに
ChatGPTは、「言葉の意味を理解しているように見える」存在です。しかし本質的には、単語を数値ベクトルに変換し、その文脈的な関係性に応じて重みづけを行い、確率分布に基づいて次の単語を選び出しているだけのシステムです。
つまり、ChatGPTの賢さの正体は、「意味の数値化」と「確率的な予測」という、極めて数学的な仕組みによって成り立っています。
このような構造を知ることで、我々はAIを神秘的に捉えるのではなく、数学的・構造的に理解できる技術として向き合うことができます。そして同時に、AIの限界や誤解の余地についてもより冷静に評価できるようになります。