-
mecab-ipadic-NEologdは、MeCab標準の辞書を補完するかたちでカスタマイズされた辞書です。
-
Web 上の多数の言語資源から語句が追加されたもので、新語や複合語、慣用的な表現などに対応しています。

-
上記のとおり、MeCab標準では「個人」と「主義」に分割されてしまいますが、mecab-ipadic-NEologdでは「個人主義」という一語として扱われています。
課題
- mecab-ipadic-NEologdを使って、併せてストップワードの除去を行い、共起ネットワークに表現するという一連の作業を行ないます。
1. テキストデータの準備
⑴ テキストデータの読み込み
- コーパスには、国連総会における菅首相の演説(令和2年9月26日)を使います。なお、以下URLに、歴代総理の演説や記者会見などがノーカットでテキストや動画で公開されています。
- https://www.kantei.go.jp/jp/99_suga/statement/index.html
- あらかじめ当該のテキストを画面上でコピーしてローカル PC にテキストファイルを作成しました。それをColaboratoryにアップロードして読み込みます。
from google.colab import files
uploaded = files.upload()

with open('20200926_suga_un.txt', mode='rt', encoding='utf-8') as f:
read_text = f.read()
sugatxt = read_text

⑵ データクリーニング
- 改行コードや記号などのノイズを除去し、句点「。」で文単位に分割します。
# 不要な文字・記号の削除
def clean(text):
text = text.replace("\n", "")
text = text.replace("\u3000", "")
text = text.replace("「", "")
text = text.replace("」", "")
text = text.replace("(", "")
text = text.replace(")", "")
text = text.replace("、", "")
return text
text = clean(sugatxt)
# 行単位に分割
lines = text.split("。")

2. 共起データの作成
- MeCabとmecab-ipadic-NEologdを用いて一文毎に形態素解析を行ない、ストップワードを除く名詞だけのリストを作成します。
⑶ MeCabとmecab-ipadic-NEologdのインストール
# MeCab
!apt-get -q -y install sudo file mecab libmecab-dev mecab-ipadic-utf8 git curl python-mecab > /dev/null
!pip install mecab-python3 > /dev/null
# mecab-ipadic-NEologd
!git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git > /dev/null
!echo yes | mecab-ipadic-neologd/bin/install-mecab-ipadic-neologd -n > /dev/null 2>&1
# シンボリックリンクによるエラー回避
!ln -s /etc/mecabrc /usr/local/etc/mecabrc
- リンクの切断や間違ったファイルを指すなどのエラーを回避して、次項の
pathが正常に機能するための対策を施しています。
⑷ mecab-ipadic-NEologdを指定してインスタンスを生成
# 辞書のパスを確認
!echo `mecab-config --dicdir`"/mecab-ipadic-neologd"
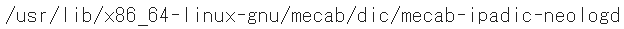
- 出力モードを
path(=mecab-ipadic-NEologd)としてインスタンスm_neoを生成します。
import MeCab
path = "-d /usr/lib/x86_64-linux-gnu/mecab/dic/mecab-ipadic-neologd"
m_neo = MeCab.Tagger(path)
⑸ 文単位の名詞リストを作成
- 削除する単語ストップワードを設定します。数字・数詞・指示代名詞など、単独では解釈に有益な意味を持たない単語をリストアップしています。なお、この例では形態素解析後に残った記号なども加えています。
stopwords = ["1", "2", "3", "4", "5", "6", "7", "8", "9", "0",
"1", "2", "3", "4", "5", "6", "7", "8", "9", "0",
"一", "二", "三", "四", "五", "六", "七", "八", "九", "〇",
"年", "月", "日", "次", "割", "回", "的", "症", "以上", "以下", "周年", "件", "度",
"の", "もの", "こと", "よう", "さま", "ため", "がち", "これ", "それ", "あれ", "誰",
"*", ",", ","]
- 文単位の名詞リスト
noun_listを作成します。 - 行単位に分割したテキストデータ
linesから1行ずつ、以下の処理をくり返してnoun_listに追加していきます。 - 形態素解析の結果を
v1とし、これをsplitlines()で語単位に分割したリストをv2とします。 -
v2から1語ずつ、以下の処理をくり返してresultに追加していきます。 - 1語分の解析結果を
split("\t")すなわち空白で分割して、「元の語」と「解析の内容部分」に2分割してv3とします。 -
if len(v3) == 2とすることで"EOS"や" "を除き、解析の内容部分v3[1]をsplit(',')すなわちカンマで分割してv4とします。 - この第1番目の要素
v4[0]が名詞で、かつ原形のv4[6]がストップワードでなければresultに追加します。 - すべての単語の処理を終えたら
resultをnoun_listに追加して、次の文の処理に移ります。
noun_list = []
for line in lines:
result = []
v1 = m_neo.parse(line)
v2 = v1.splitlines()
for v in v2:
v3 = v.split("\t")
if len(v3) == 2:
v4 = v3[1].split(',')
if (v4[0] == "名詞") and (v4[6] not in stopwords):
result.append(v4[6])
noun_list.append(result)

⑹ 共起データの生成
- 文単位の名詞リスト
noun_listから順次、if len(noun_list) >= 2で2語以上あるものを対象に、itertools.combinations()でペア(2単語の組み合せ)を生成し、それをlist()でリスト化したものをpair_listに格納します。 - 次いで、文単位になっている
pair_listを平坦化してall_pairsとしてからペアの出現回数をカウントします。
import itertools # イテレータ関数を集めたモジュール
from collections import Counter # 辞書型の出現回数をカウントするクラス
# 文単位の名詞ペアリストを生成
pair_list = []
for n in noun_list:
if len(noun_list) >= 2:
lt = list(itertools.combinations(n, 2))
pair_list.append(lt)
# 名詞ペアリストを平坦化
all_pairs = []
for p in pair_list:
all_pairs.extend(p)
# 名詞ペアの頻度をカウント
cnt_pairs = Counter(all_pairs)

3. ネットワーク図の描画
⑺ 作図用データの作成
- 作図には、出現回数で上位30ペアのみを使うことにしましょう。
- ソートして30組を取り出す
sorted()[:30]の引数ですが、cnt_pairsの要素をkey=lambda x:x[1]で出現回数を対象としてreverse=Trueで降順ソートしています。 - さらに、辞書型の
dictを2次元配列に変換して作図用のdataとします。
import pandas as pd
import numpy as np
# 上位30ペアの辞書を生成
dict = sorted(cnt_pairs.items(), key=lambda x:x[1], reverse=True)[:30]
# dict型を2次元配列に変換
result = []
for key, value in dict:
temp = []
for k in key:
temp.append(k)
temp.append(value)
result.append(temp)
data = np.array(result)

⑻ 可視化ライブラリのインポート
- Pythonで複雑なネットワークやグラフ構造を作成・操作するためのパッケージnetworkXを使います。
import matplotlib.pyplot as plt
import networkx as nx
%matplotlib inline
# matplotlibを日本語表示に対応させるモジュール
!pip install japanize-matplotlib
import japanize_matplotlib
⑼ NetworkXによる可視化
- グラフ構造のオブジェクトを生成し、それにデータを読み込ませて、matplotlib上でノードやエッジ等の仕様を指定して描画します。
- ノードラベルを日本語表示に対応させるため、
font_family = "IPAexGothicとして日本語フォントを指定しています。
# グラフオブジェクトの生成
G = nx.Graph()
# データの読み込み
G.add_weighted_edges_from(data)
# グラフの描画
plt.figure(figsize=(10,10))
nx.draw_networkx(G,
node_shape = "s",
node_color = "chartreuse",
node_size = 800,
edge_color = "gray",
font_family = "IPAexGothic") # 日本語フォント指定
plt.show()
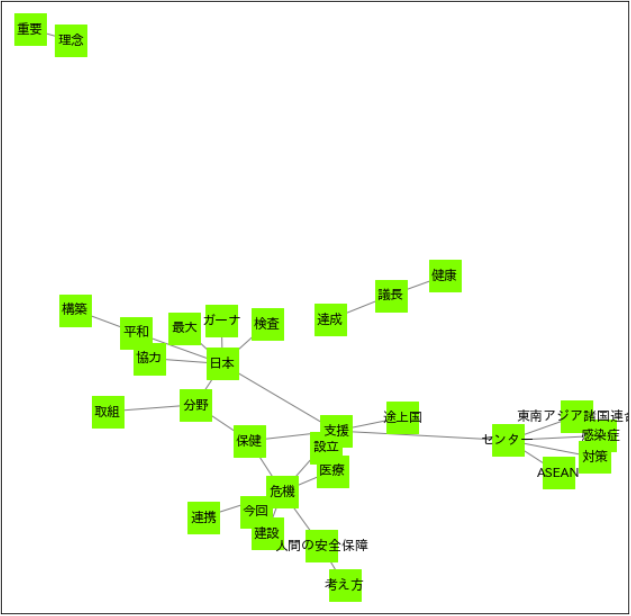
- 次のように、MeCab標準ならば分割されてしまう単語が、一語として処理されています。
| mecab-ipadic-NEologd | MeCab標準 |
|---|---|
| "感染症" | "感染", "症" |
| "途上国" | "途上", "国" |
| "東南アジア諸国連合" | "東南アジア", "諸国", "連合" |
| "人間の安全保障" | "人間", "の", "安全", "保障" |
- 生きている人間が書いたり話したりする言葉は、それ自体が生き物のようなもので、常に新陳代謝をしています。それに応じて辞書もアップデートされていくものでなくてはならないと、切に感じるところです。