機械学習を学ぶのに最も適した教材と言われる、Machine Learning | Coursera を受講しているので、復習も兼ね学んだ内容を簡潔にまとめてみようと思います。
最終回、第十一弾は、**写真OCR (Photo Optical Character Recognition)**です。
機械学習の応用例としてのコンピュータービジョン (Computer Vision)ですが、**人工データ合成 (Artificial Data Synthesis)、天井分析 (Ceiling Analysis)**といった、実際に機械学習を用いるプロジェクトを行うときに欠かせない要素も一緒に学びます。
過去の記事
Coursera Machine Learning (1): 機械学習とは?単回帰分析、最急降下法、目的関数
Coursera Machine Learning (2): 重回帰分析、スケーリング、正規方程式
Coursera Machine Learning (3): ロジスティック回帰、正則化
Coursera Machine Learning (4): ニューラルネットワーク入門
Coursera Machine Learning (5): ニューラルネットワークとバックプロパゲーション
Coursera Machine Learning (6): 機械学習のモデル評価(交差検定、Bias & Variance、適合率 & 再現率)
Coursera Machine Learning (7): サポートベクターマシーン (SVM)、カーネル (Kernel)
Coursera Machine Learning (8): 教師なし学習 (K-Means)、主成分分析 (PCA)
Coursera Machine Learning (9): 異常検知 (Abnomaly Detection)、レコメンダシステム (Recommender System)
Coursera Machine Learning (10): 大規模機械学習
写真OCR (Photo Optical Character Recognition)
人間をはじめとする霊長類は、他の種に比べて優れた視覚を持っています。顔、物体によらずアイデンティティーを素早く認識し、それに基づいて行動することができます。もし機械に人間と同等の視覚認知能力を持たすことができれば、自動車の自動運転をはじめ、様々な応用が考えられます。
写真OCR、写真の光学文字認識は、機械に画像内にある文字を認識させようという試みです。

上は地下鉄にあった広告(落書きされておる……)です。緑枠で囲ったところが文字で、写真OCRのアルゴリズムは、これらを正しく認識しなければなりません。
人間なら一瞬でできることですが、これを機械でやろうとすると、処理をいくつかの工程 (Pipeline)に分け、それぞれに必要な機械学習のアルゴリズムをあてがうことになります。今回の場合、以下のようなパイプラインになります。

1: 文章検出 (Text Detection)
文字を含んだ画像 ($y=1$)と文字を含んでいない画像($y=0$)を大量に用意し、アルゴリズムに学習させます。ラベル付きデータの分類なので、教師あり学習 (Supervised Learning) ですね。

(Andrew Ng, Coursera Machine Learning Week 11より出典)
2: 文字分離 (Character Segmentation)
ラベル付きデータを学習させるのは同様ですが、今回は文章を文字毎に分解したいので、$y=1$は文字と文字の境界が見える画像、$y=0$はそうではなく、文字そのものが映っている、あるいは文字以外の何かが映っている画像を用います。
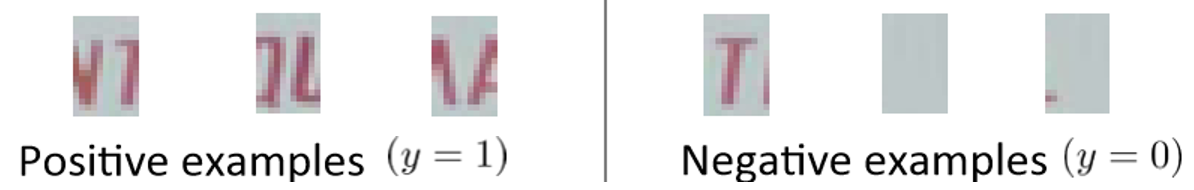
(Andrew Ng, Coursera Machine Learning Week 11より出典)
3: 文字認識 (Character Recognition)
アルファベットの場合、文字が26字しかないので厳密に分けてもラベルは26通りで済みます。ドイツ語だとウムラウトがあるので26 + 4 = 30通りに増えます。日本語だと、ひらがな、カタカナ、漢字があるので……考えたくもないですね。
そう考えると、やはりトレーニングデータが大量に必要になります。教師あり学習 (Supervised Learning) なので、ラベルが必要となるのが厄介です。どうしたらよいかというと、
- 自分で頑張る。
- バイトを雇う(クラウドサービスなどで)。
- 人工データ合成 (Artificial Data Synthesis)
など、時間やお金の都合によって色々ありますが、人工データ合成が一番エンジニアの仕事っぽいですね。
文字認識の場合は、例えば以下のことができます。
- フォントを変える。
- 文字の大きさを変える。
- 文字を回転させる。
- 文字の位置をずらす。
- 文字を歪める。
- 背景を変える。
- ランダムに選んだピクセルの値を0に置換する。
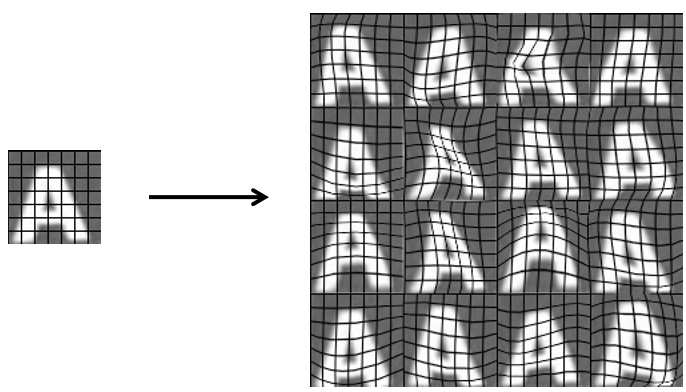
(Adam Coates & Tao Wangより出典)
上の例だと、歪み (distortion)を導入することでデータ数を16倍に増やしています。こうしたテクニックを使うと、以下のようにオリジナルと変わらない質の人工合成データを作ることができます。

注意点
例えば、ターゲットの写真が100x100ピクセルだったとして、それのどこかに文字があるわけですね。その大きさは5x5ピクセルに収まる大きさかもしれませんし、50x50ピクセルじゃないと収まらない大きさかもしれません。
いずれも検知(detect)するため、通常複数のピクセルサイズの
**スライディングウインドウ (Sliding Window)**を使って画像に文字が含まれるか走査的 (scanning)に調べます。スライディングウィンドウが被った領域に、文字が含まれているかどうか機械学習のアルゴリズムで判定していくわけですね。

天井分析 (Ceiling Analysis)
機械学習のパイプラインで、どの要素が最も改善できるポテンシャルがあるのか調べるには、**天井分析 (Ceiling Analysis)**を用います。

上の表は、各要素と、その要素の精度が100%だったときのシステム全体の精度をまとめたものです。
現状のシステム全体の精度は72%です。まだまだよくなりそうですね。このとき、文章検知のアルゴリズムがもし100%だったとしたら、システム全体の精度は89%に上がります。現状から、17%アップです。
次に、文字分離のアルゴリズムも100%の精度だとしたら、システム全体の精度は90%に上がります。
「......って、さっきより1%しか上がってねぇ!」
これにより、文字分離のアルゴリズムを改善しても大して意味がないことがわかります。
最後に、文字認識のアルゴリズムの精度も100%だとすると、当たり前ですが、システム全体の精度も100%になりますね。先ほどから、10%の精度アップです。
以上のことから、時間とお金と人員は最大17%の精度改善が見込める文章検知と、最大10%の精度改善が見込める文字認識のアルゴリズムの改善に使うべきだということがわかります。
注意点
「もしある要素の精度が100%だったらって……どうやって調べるの?」
例えば文章検知のアルゴリズムの精度を100%にしたときのシステム全体の精度を調べたければ、文章検知で使うテストデータ (Test set)をマニュアルで精度100%になるように変えてしまいます。そうして、次のパイプラインに繋いで最終的にどれくらいの精度になるか見ればよいですね。
まとめのまとめ#
- 写真OCRなどの課題には、機械学習のパイプラインがある。
- パイプラインの要素ごとの課題に合わせ、ラベル付きデータを集め、アルゴリズムを学習させる。
- データが足りなければ、人工的に合成する。
- 各要素の改善可能性を定量化するには、天井分析を用いる。
終わりに#
今回はCoursera Machine Learning の最終回でした。写真OCRという例を通して、機械学習の応用の流れを学びました。
Coursera Machine Learningもこのweek 11で終了です。
基本が本当によくまとまっていて、私のような初心者にもわかりやすいコース設計でした。11週修了すると、機械学習やデータ解析全般に対し、それまでと全く違う景色が見えます。このコースを作ってくださった、Andrew Ng教授に感謝です。
最後に、Andrew Ng教授の引用して閉めたいと思います。
私は、あなたたちが機械学習を自分の人生を良くするだけでなく、よかったらいつか、多くの他の人たちの人生も良いものにしてくれるように願っています。
I hope that you find ways to use machine learning not only to make your life better but maybe someday to use it to make many other people's life better as well. (Andrew Ng)