- DeepLearning(1): まずは順伝播(上)
- [DeepLearning(2): まずは順伝播(下)]
(http://qiita.com/eijian/items/24d7e6aee332d59509ec) - DeepLearning(3): そして逆伝播(でも全結合層まで)
- DeepLearning(4): CNNの逆伝播完成?
- DeepLearning(5): スペースリーク解消!
前回で形だけは写経が完成したわけだが、最後に書いたとおりひどいスペースリークが起こって使い物にならないことがわかった。今回はスペースリークの解消に取り組もう。(前回記事ではメモリリークと書いたが、Haskell界隈では(?)スペースリークと言うようだ。どう違うのか、同じなのかよくわからない)
(今回のソース)
1. 再帰の改善
いくつかのWebサイトを読んでみたが、Haskellは遅延評価のためにスペースリークを起こしやすいそうだ。素人には細かいことはわからないが、遅延評価のため必要になるまで計算を保留し、その情報をメモリ(ヒープ領域)に置くようだ。だから保留される計算が増えるほどメモリを消費するらしい。再帰といえばスタックオーバーフローだが、それは右再帰での話のようで、、、
さて計算が保留されるような処理がどこにあるのか、ということだがじつはさっぱりわからない。が、どうもfoldlのような左再帰で起こるらしいので、まずはメインループを疑ってみた。もとの実装は次のような感じ。
main = do
(中略)
let
is = [(epoch_ed st), (epoch_ed st - 1) .. (epoch_st st)]
getTeachers = getImages (poolT st) (batch st)
putF = putStatus tm0 (epoch_st st) (epoch_ed st) (opstep st)
putStrLn "Training the model..."
putF 0 (layers st) sampleE
layers' <- trainLoop getTeachers sampleE putF (learnR st) (layers st) is
(中略)
trainLoop :: (Int -> IO [Trainer]) -> [Trainer]
-> (Int -> [Layer] -> [Trainer] -> IO ()) -> Double -> [Layer] -> [Int]
-> IO [Layer]
trainLoop _ _ _ _ ls [] = return ls
trainLoop getT se putF lr ls (i:is) = do
ls' <- trainLoop getT se putF lr ls is
teachers <- getT i
let
rls = tail $ map reverseLayer $ reverse ls' -- fist element isn't used
dls = map (train ls' rls) teachers
ls'' = update lr (transpose dls) ls' -- dls = diff of layers
putF i ls'' se
return ls''
このtrainLoopがメインループというかメイン再帰であるが、ご覧の通り珍妙なコードになっている。trainLoopは処理の最初でさらにtrainLoopを呼んでいる。これはこのループが学習によってレイヤをどんどん更新していくためで、書いた当時はその更新を表現する方法がこれしか思い浮かばなかったのだ。これが左再帰なのか深く考えていないが、わかりにくく汚いコードには違いないので書き直してみよう。foldlはアキュームレータという"変数"を使って計算結果で更新していくそうだが、これは使えそうだ。
trainLoopはIOがあるのでfoldlを使うことができないがfoldMが使えそうだ。一方で、Haskellのfoldlはスペースリークを起こしやすいとの記事もありfoldl'を使えとある。foldl'版のfoldMはないのかと思ったら下記のページに簡単な実装が書いてあった。
StackOverflow: Does Haskell have foldlM'?
これを使って書き直したのが下記のコード。
main = do
(中略)
let
is = [(epoch_st st) .. (epoch_ed st)]
getTeachers = getImages (poolT st) (batch st)
putF = putStatus tm0 (epoch_st st) (epoch_ed st) (opstep st)
loopFunc = trainLoop' getTeachers sampleE putF (learnR st)
putStrLn "Training the model..."
putF 0 (layers st) sampleE
layers' <- foldM' loopFunc (layers st) is
(中略)
foldM' :: (Monad m) => ([a] -> b -> m [a]) -> [a] -> [b] -> m [a]
foldM' _ z [] = return z
foldM' f z (x:xs) = do
z' <- f z x
z' `seq` foldM' f z' xs
trainLoop' :: (Int -> IO [Trainer]) -> [Trainer]
-> (Int -> [Layer] -> [Trainer] -> IO ()) -> Double -> [Layer] -> Int
-> IO [Layer]
trainLoop' getT se putF lr ls i = do
teachers <- getT i
let ls' = updateLayers lr teachers ls
putF i ls' se
return ls'
updateLayers :: Double -> [Trainer] -> [Layer] -> [Layer]
updateLayers lr ts ls = update lr ls (transpose dls)
where
rls = tail $ map reverseLayer $ reverse ls -- fist element isn't used
dls = map (train ls rls) ts -- dls = diff of layers
ついでにtrainLoop'内も小ぎれいにしてコアとなる更新処理をupdateLayersに出しておいた。
trainLoop'は再帰がなくなり非常にすっきりした。また、ループのために追番リストを渡しているが、前は逆順だったのが正順に改まった。
で、大事なのはこれでスペースリークが改善するかだが、、、「ダメ」だった。やはりこの問題をきちんと理解せず表面的に再帰処理をどうこうしてもダメなんだろうなと思う。ただ、メインループの気色悪い実装が多少は改善したので、それでよしとしよう。
2. BangPattern
スペースリークの件でググるとBangPatternなるものに言及されている記事がいろいろ見つかる。先述の「計算が保留されてメモリに一時置かれたもの」(これをthunkというらしい)を"とっとと計算しつくす"ように指示するもののようだ(間違ってたらご指摘を)。
ということで、上記のメインループに使ってみた。BangPatternを使うにはソースファイルの先頭にその旨を書くようだ。
:
{-# LANGUAGE BangPatterns #-}
(中略)
foldM' :: (Monad m) => ([a] -> b -> m [a]) -> [a] -> [b] -> m [a]
foldM' _ <font color="red">!z</font> [] = return z
foldM' f <font color="red">!z</font> (x:xs) = do
z' <- f z x
z' `seq` foldM' f z' xs
(中略)
trainLoop' :: (Int -> IO [Trainer]) -> [Trainer]
-> (Int -> [Layer] -> [Trainer] -> IO ()) -> Double -> [Layer] -> Int
-> IO [Layer]
trainLoop' getT se putF lr <font color="red">!ls</font> i = do
:
(中略)
updateLayers :: Double -> [Trainer] -> [Layer] -> [Layer]
updateLayers lr ts <font color="red">!ls</font> = update lr ls (transpose dls)
:
foldM'、trainLoop'、updateLayersの引数についている"!"がその指定。とにかく手当たり次第入れてみた。が、「全滅」した。全く効果がない。。。
thunkをつぶすために deepseq を使うという記事もいくつかあったが、やってみようとすると対象のデータ型をNFData型クラスのインスタンスにする(?)とか、結局素人にはなすすべがなく断念した次第である。
3. hmatrixの採用
効果がありそうなことを試してもちゃんと原因を特定していないので無関係な場所に適用してしまっているのだろう。やっぱりもう少しちゃんと原因を探してみたい。
-1. 問題発生箇所はどこか
スペースリークに気づいたのは畳み込み層を含めた逆伝播処理(Aとしよう)が仕上がった時であり、その前の全結合層だけ逆伝播(Bとする)していた時は気にならなかった。なので両方の実行時のメモリ割り当てを比べてみた。
AもBも処理が進むたびにメモリをどんどん食っていくので、残念ながらスペースリークは前から起こっていたらしい。しかし、Aでは繰り返し1回で約30MB増えていくのに比べ、Bでは約1MBしか増えない。だからBでは500回程度の繰り返しではメモリが足りて問題に気づかなかったようだ。一方Aでは500回も繰り返すと15GB必要になる計算なのでとてもではないが私のPCでは無理だ。
Aの方が極端にメモリを食うので、Aで追加したコード(畳み込み・プーリングの逆伝播)を重点的に調べることにした。特に重そうな畳み込み層の逆伝播処理は次の通り。
deconvolve :: Int -> [FilterC] -> Image -> Delta -> (Delta, Layer)
deconvolve s fs im d = (delta, ConvLayer s (zip dw db))
where
delta = convolve s fs $ addBorder s d
db = map (sum . map sum) d -- delta B
sim = slideImage s im
dw = map (hadamard sim) d
delta =...はほぼ順伝播の処理そのままなので無視、その他を「ダミー(全部0のデータを代わりに与えたり空リストを渡したり)」に変更して実行してみた。
すると、使用メモリの増加が30MBから10MB程度になった!やはりここが悪いらしい。これら処理にはmapやsumなど再帰関数が多用されている。データは全て「リスト」で表現しており、処理内容からしてmapやsumを多用することは避けられない。どうしようもない?
-2. 思い切ってリストからhmatrixに書き換え
このプログラムでは型(ImageとかFilterCとか)は全てリストで定義してきた。これはまず標準の機能・ライブラリでやれるところまでやってみたかったから。リストでは処理が遅いのはわかっているのでゆくゆくはhmatrixとかRepaとかに移そうと思ってはいたが、速度改善のネタとしてとっておくつもりだったんだがなぁ。。。
だが私のレベルではリストを使いつつ問題を解決することができそうにない。とにかくリストをできるだけ使わないようにするしかないが、代わりに行列ライブラリを使うとして何を使うか。本命はRepaだった。高速化の一環でGPUを使った並列化も考えているため、Accelerateに書き方が似ているからだ(逆か)。
しかしこの記事ではRepaはどうもhmatrixに比べだいぶ遅いようだ。またRepaの解説記事も読んだが書き方が私にはとても難解で奇妙で理解しがたい。一方こちらのhmatrixの解説を読むと素直な書き方ができるようだし、ライブラリのページをみるといろいろ使えそうな関数が揃ってそうだ。ということで、hmatixに決定!
導入と設定は次の通り。
$ cabal install hmatrix
cabalファイルにも追加が必要だ。
:
executable train
main-is: Main-train.hs
-- other-modules:
-- other-extensions:
build-depends: base >=4.8 && <5.0
, mersenne-random >= 1.0
, containers
, time
, deepseq
, hmatrix
:
hmatrixは一次元配列相当のVectorと二次元のMatrixからなり三次元以上はなさそう。これらを使って既存の型を定義し直す。
(before)
type Plain = [[Double]] -- 2D: X x Y pixels
type Class = [Double] -- teacher vector
type ActFunc = [Double] -> [Double]
type Kernel = [[Double]]
type FilterF = [Double]
(after)
type Plain = Matrix R -- 2D: X x Y pixels
type Class = Vector R -- teacher vector
type ActFunc = Matrix R -> Matrix R
type Kernel = Matrix R
type FilterF = Matrix R
できるだけMatrixかVectorに変更した。RはDoubleと同じらしい。注意が必要なのがFilterFで、前の実装ではこれは[FilterF]とリストにしていた。今回これをFilterFに改めた。要は[[Double]]をMatrix Rに変えたのだ。
この変更により、既存の関数は引数の型合せが大変だったが、それよりも従来リストで書いていたものを全部新しい型を使って全面的に書き直すのに苦労した。特に畳み込み層、プーリング層。これらを見ていこう。
deep learning では行列を使うのが有効だと思うが、前回までのプログラムはあえてリストにしたため、例えば畳み込みで画像の一部を切り取るためにややこしくわかりにくい関数を作ってしまった。
今回型は行列なので、hmatrixの便利な関数subMatrixを使うことでそれが超簡単にできてしまった。逆に、これまで「一部を切り出して畳み込み、次を切り出して畳み込み」と直列処理?をしていたのを、切り取りを最初に一括で行い、それを順に畳み込むよう変更することになった。今回コードの畳み込み処理は次のよう。
convolve :: Int -> [FilterC] -> Image -> Image
convolve s fs im = map (convolveImage x iss) fs
where
pl = head im
x = cols pl - (s - 1)
y = rows pl - (s - 1)
ps = [(i, j) | i <- [0..(x-1)], j <- [0..(y-1)]]
iss = map subImage im
subImage :: Plain -> Matrix R
subImage i = fromColumns $ map (\p -> flatten $ subMatrix p (s, s) i) ps
convolveImage :: Int -> [Matrix R] -> FilterC -> Plain
convolveImage x iss (k, b) = reshape x $ cmap (+ b) $ vsum vs
where
vs = zipWith (<#) (toRows k) iss
面倒な行列の切り出しがsubMatrixで済んでしまうことは大きい。前のコードに比べかなり短くなった(28行から14行)。
(参考:前のコードの同じ部分)
convolve :: Int -> [FilterC] -> Image -> Image
convolve s fs im = map (convolveImage s im) fs
convolveImage :: Int -> Image -> FilterC -> Plain
convolveImage s im (ks, b) = sumPlains b (zipWith (convolvePlain s) ks im)
sumPlains :: Double -> [Plain] -> Plain
sumPlains b [] = repeat $ repeat b -- 2 Dimensions (X*Y)
sumPlains b (p:ps) = zipWith f p (sumPlains b ps)
where
f :: [Double] -> [Double] -> [Double]
f [] _ = []
f (a:[]) (b:_) = [a + b]
f (a:as) (b:bs) = (a + b) : f as bs
convolvePlain :: Int -> [Double] -> Plain -> Plain
convolvePlain s k ps
| len < s = []
| otherwise = convolveLine s k p : convolvePlain s k ps'
where
len = length ps
p = take s ps
ps' = tail ps
convolveLine :: Int -> [Double] -> [[Double]] -> [Double]
convolveLine s k ps
| len < s = []
| otherwise = sum (zipWith (*) vs k) : convolveLine s k ps'
where
len = minimum $ map length ps
vs = concatMap (take s) ps
ps' = map tail ps
プーリング層も同様で、行列を小領域に区分けして処理していくため、subMatrixが活躍する。
こちらも始めに小領域を全部作って順に処理する形に変えたので、行数は31行から19行にへった。
poolMax :: Int -> Image -> [Image]
poolMax s im = [os, is]
where
pl = head im
x = cols pl `div` s
y = rows pl `div` s
ps = [(i*s, j*s) | i <- [0..(x-1)], j <- [0..(y-1)]]
(os, is) = unzip $ map (toPlain x y . maxPix s ps) im
toPlain :: Int -> Int -> [Pix] -> (Plain, Plain)
toPlain x y pls = ((x><y) op, (x><y) ip)
where
(op, ip) = unzip pls
maxPix :: Int -> [(Int, Int)] -> Plain -> [Pix]
maxPix s ps is = map (max' . toPix) ps
where
toPix :: (Int, Int) -> [Pix]
toPix p = zip (concat $ toLists $ subMatrix p (s, s) is) [0.0..]
(参考:前の実装はこう)
poolMax :: Int -> Image -> [Image]
poolMax s im = [fst pixs, snd pixs]
where
pixs = unzip $ map unzipPix (poolMax' s im)
unzipPix :: [[Pix]] -> ([[Double]], [[Double]])
unzipPix pixs = unzip $ map unzip pixs
poolMax' :: Int -> Image -> [[[Pix]]]
poolMax' s = map (poolMaxPlain s)
poolMaxPlain :: Int -> Plain -> [[Pix]]
poolMaxPlain s p = map (poolMaxLine s) ls
where
ls = splitPlain s p
splitPlain :: Int -> Plain -> [[[Double]]]
splitPlain s [] = []
splitPlain s p = p' : splitPlain s ps
where
(p', ps) = splitAt s p
poolMaxLine :: Int -> [[Double]] -> [Pix]
poolMaxLine _ [] = []
poolMaxLine s ls
| len == 0 = []
| otherwise = pixs : poolMaxLine s ls'
where
len = length $ head ls
pixs = max' $ zip (concatMap (take s) ls) [0.0 ..]
ls' = map (drop s) ls
hmatrixの使用前後を比べてみるとわかるが、かなり作り方というか処理の流れが変わってしまった。関数は、ほとんど一から作りなおしたようなものだ。
ここで、テストコードに大いに助けられた。私はズボラなのでテストコードを書くのは嫌いで苦手だが、deep learningでは思った通りの変換ができているか確認しておかないと各層の実装間違いが後に響くため、いつもより多めにテストコードを入れていた。
前述の通り一部の関数はほぼ作り直しだったが、テストで得られる結果は前の実装と同じはずだ。データ型を変更したので入力・出力の形は異なるが結果の値は同じだ(見難いので一部改行を入れてある)。
(old code)
>>> let filter = [
([[1.0,2.0,3.0,4.0],[5.0,6.0,7.0,8.0]],0.25),
([[3.0,4.0,5.0,6.0],[7.0,8.0,1.0,2.0]],0.5),
([[5.0,6.0,7.0,8.0],[1.0,2.0,3.0,4.0]],0.75)] :: [FilterC]
>>> let img1 = [
[[1.0,2.0,3.0],[4.0,5.0,6.0],[7.0,8.0,9.0]],
[[4.0,5.0,6.0],[7.0,8.0,9.0],[1.0,2.0,3.0]]] :: Image
>>> convolve 2 filter img1
[[[200.25,236.25],
[173.25,209.25]],
[[152.5,188.5],
[233.5,269.5]],
[[152.75,188.75],
[197.75,233.75]]]
(new code)
>>> let filter = [
(fromLists [[1.0,2.0,3.0,4.0],[5.0,6.0,7.0,8.0]],0.25),
(fromLists [[3.0,4.0,5.0,6.0],[7.0,8.0,1.0,2.0]],0.5),
(fromLists [[5.0,6.0,7.0,8.0],[1.0,2.0,3.0,4.0]],0.75)] :: [FilterC]
>>> let img1 = [
fromLists [[1.0,2.0,3.0],[4.0,5.0,6.0],[7.0,8.0,9.0]],
fromLists [[4.0,5.0,6.0],[7.0,8.0,9.0],[1.0,2.0,3.0]]] :: Image
>>> convolve 2 filter img1
[(2><2)
[ 200.25, 236.25
, 173.25, 209.25 ],(2><2)
[ 152.5, 188.5
, 233.5, 269.5 ],(2><2)
[ 152.75, 188.75
, 197.75, 233.75 ]]
このように、テストで前と同じ結果であることを保証できないと内部実装をガラッと変えるのは怖い。今後テストコードをこまめに書くモチベーションアップにはなったと思う。
-3. 評価
(1) 学習結果(認識精度)
改善したプログラム(新CNNと呼ぼう)を例によって10回実行し、それぞれ認識精度と実行時間を計測した。前回は10回の平均を取ったが、これだと立ち上がりのタイミングが大きくぶれるため平均したら実際よりなだらかな微妙な曲線になってしまう。そこで今回は平均ではなく中央値でグラフを書いてみることにした。前回の、全結合層のみの値と畳み込み層までの値も同じく中央値でプロットしてみた。
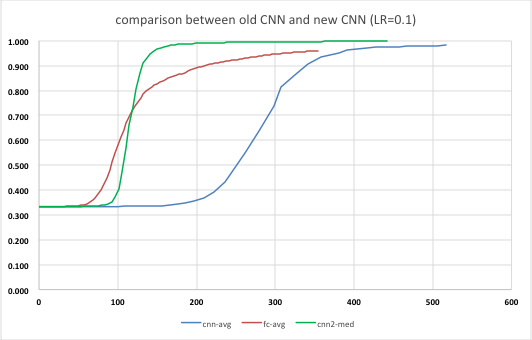
横軸が処理時間なので、新CNNの方が全結合層のみの場合より立ち上がるタイミングが遅いものの、学習効率が高く早期に95%を超えるのがわかる。今回の新CNNでは学習の進み方が圧倒的に速いためとても性能が高いと思う。
前回同様、処理にかかる時間を比較表にした。今回は500 epoch まで計測できたのでそれも追加した。
| 新CNN | CNN | 全結合層のみ学習 | |
|---|---|---|---|
| 処理時間(s) | 177 | 517 | 157 |
| 処理性能(epoch/s) | 1.130 | 0.387 | 1.273 |
| 認識精度(%) 200epochs | 97.8 | 97.5 | 74.2 |
| 認識精度(%) 500epochs | 99.6 | - | 95.1 |
単位時間あたりの処理量が、かなり全結合層のみ学習の時のそれに近づいた。一方で認識精度はさすが、かなり良い。
ということで、hmatrixを使った今回のバージョンでやっと本当の意味でのyusugomori実装の「写経」が完成したと言えるだろう。
(3) スペースリーク
そうそう、今回はスペースリークの解消が目的であった。新CNN実行時のメモリ使用量をtopコマンドで眺めていたが、繰り返し回数によらずだいたい60MBから70MBの間で推移し、多少増減するものの70MBを超えて増加することなく安定していた。スペースリークは解消したようだ!
-4. hmatrixを使った感想
このdeep learningのプログラムを実装するにあたり初めてhmatrixを知ったのだが、以下の点でこのライブラリはとてもよい。
-
わかり易い:
行列を作ったり、いろいろな操作をするのに込み入った記述はいらない。例えば 2x3行列を作りたければ(2><2) [要素のリスト]と書けばよい。 -
Numクラスのインスタンス(?):
足し算(+)、引き算(-)の関数はNumクラスのインスタンスでないと実装できないが hmatrixのMatrixやVectorはそのインスタンスなので普通に足したり引いたりできる。以前別のプログラムでNumericPreludeを使って四則演算を自作したことがある。hmatrixはどうやっているのだろうか。今度ソースを眺めてみよう。 -
便利関数多し:
高校や大学で習うような行列・ベクトルの演算はいわずもがな、CNNを作るのに「こんな関数が欲しいなぁ」と思うとちゃんと用意されている。subMatrixはもちろん、要素を全部足すsumElementsや2つのベクトルの要素をそれぞれ掛けた値を行列にするouterなど、deep learningを実装するために作られたのではと思えるほど。なお、hmatrixを使った実装が終わり評価もほぼ終わったところでcorr2という関数を見つけた。これはどうやら「畳み込みをする関数」のようだ・・・。せっかく実装したのだが・・・。しかしcorr2を使うにはデータ型を変更しなくてはいけないみたいなので今回はパス。次の改善で考えよう。
4. おまけ
これまで何回か処理性能を評価してきたが、試行毎に学習の立ち上がりや認識精度の改善度合いに大きなばらつきがあることがわかった。試行毎の違いは全結合層および畳み込み層のフィルタの初期状態による。初期状態は乱数で設定するが、その値の範囲は次のように設定している。($x$をフィルタの設定値、$in$と$out$はその層の入力数・出力数とする)
(全結合層)
\left|x\right| \leq \frac{1.0}{in}
(畳み込み層)
\left|x\right| \leq \sqrt{\frac{6}{in+out}}
一方でこの記事によると、deep learningの論文では学習効率を上げるためのフィルタの初期値として次の式が示されているという(私は原論文を読んでいないが)。
(活性化関数が$\tanh$のとき)
\left|x\right| \leq \sqrt{\frac{6}{in + out}}
(活性化関数が$\mathrm{sigmoid}$のとき)
\left|x\right| \leq 4 \cdot \sqrt{\frac{6}{in + out}}
特に全結合層では大きく違いがある。これを論文で示された値にしたらどうなるか全結合層の実装で下記のように試してみた。
initFilterF :: Int -> Int -> IO FilterF
initFilterF k c = do
rs <- forM [1..k] $ \i -> do
w <- forM [1..c] $ \j -> do
r <- MT.randomIO :: IO Double
return ((r * 2.0 - 1.0) * a)
return (0.0:w)
return $ fromLists rs
where
a = 1.0 / fromIntegral c
↓
a = 4.0 * sqrt (6.0 / fromIntegral (c + k))
実行結果を表にしたものがこちら。
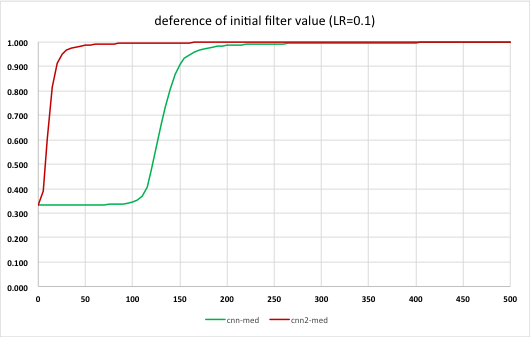
効果は歴然、学習効率が格段に向上していることがわかる。フィルタの初期値の違いがこれほど大きな差を生むとは驚きだ。逆に言えば、初期値を適切に与えないとなかなか学習が進まないということでもあり、おそらく個々の問題毎に最適な値が違うと思うので、これはもう試行錯誤しかないのだろう。ただ上記の論文ではその中でも比較的良い結果を得る指針かと。
5. まとめ
今回の改善で、やっとまともに動作するyusugomori実装の「写経」が完成し、初回に書いたステップ1が完了した。さすがに深層学習を一から勉強しないといけなかったのでしんどかった。。。
それでは次回、MNISTデータを使った学習(ステップ2)に取り組もう。