原文:
Getting Started With Cloudera Open Data Lakehouse on Private Cloud
https://www.cloudera.com/blog/technical/getting-started-with-cloudera-open-data-lakehouse-on-private-cloud.html
Part 1:ストリーミング・データ取り込み

⸻
はじめに
Cloudera は昨年からパブリッククラウド向けに提供してきた Open Data Lakehouse に加え、プライベートクラウド向けにも Apache Iceberg ベースのフル機能版をリリースしました。これにより 「Iceberg をあらゆる場所へ」 という Cloudera のビジョンが実現し、Public / Private / Hybridを問わず、データの存在する環境に合わせて Open Data Lakehouse を展開し、ワークロードをシームレスに移行できます。
プライベートクラウド版 Cloudera Open Data Lakehouse では、次の主要機能を利用できます。
- マルチエンジン互換性
NiFi、Flink/SQL Stream Builder(SSB)、Spark、Impala などが Iceberg と連携。 - タイムトラベル
指定時点やスナップショット ID でクエリを再現可能。監査・ML モデル検証・誤操作のロールバックに有用。 - テーブルロールバック
問題発生時にテーブルを即座に正常状態へ復元。 - 豊富な SQL(DDL/DML)
データベースオブジェクトの操作、データのロード/更新、タイムトラベル、Hive 外部テーブルからの Iceberg 変換を SQL で実行。 - インプレースのテーブル進化
スキーマやパーティションをデータを書き換えずに変更可能。 - SDX 連携
共通のセキュリティ/ガバナンス、データリネージ、監査を提供。 - Iceberg レプリケーション
DRとテーブルバックアップに対応。 - ワークロードの移動
コード改修なしでパブリッククラウドへ移行・戻しが容易。
本ブログでは、最新の Cloudera Iceberg 機能を用いてプライベートクラウドに Open Data Lakehouse を構築する方法を解説します。
第 1 回は ストリーミングデータの取り込み に焦点を当て、Iceberg テーブルへデータをロードし、後続ブログで処理を行える状態にします。
⸻
ソリューション概要
アーキテクチャ図:
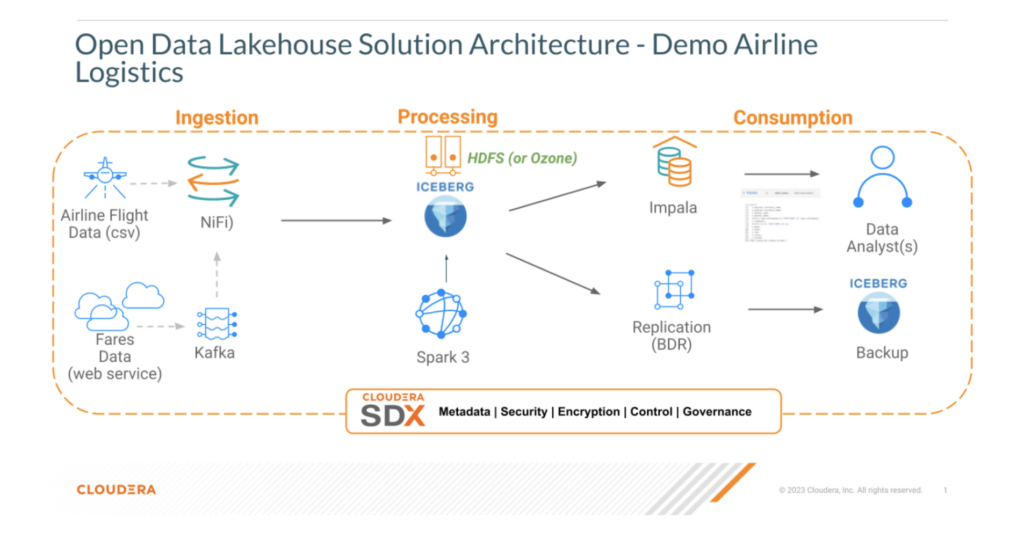
⸻
前提条件
以下のコンポーネントがCloudera Open Data Lakehouse(プライベートクラウド)にインストール・設定済みであること:
- Cloudera Data Platform Private Cloud Base 7.1.9
- Cloudera Flow Management 2.1.6
- 航空会社データセット(GitHubリポジトリからflights.csv.gzipを解凍)
Flink と SSB(CSA 1.11)を利用したストリーミング取り込みも可能ですが、本記事では NiFi を使用します。
⸻
NiFi で Iceberg テーブルへストリーミング取り込みの手順
1. Hue/Impala でルート(routes)Iceberg テーブルを作成
-- NiFi用のルートテーブル作成
CREATE TABLE airlines.routes_nifi_iceberg (
airline_code STRING,
airline_name STRING,
src_airport_code STRING,
src_airport_name STRING,
dst_airport_code STRING,
dst_airport_name STRING,
equipment STRING
) STORED AS ICEBERG;
※実際の DDL は環境に合わせて調整してください。
2. NiFi データフローを取得
https://github.com/jingalls1217/airlines/blob/main/Data%20Flow/NiFiDemo.json をダウンロード。
3. NiFi で新規プロセスグループを作成し、フローをインポート

概要:
- プロセスグループを作成。
- 右パネルの Browse で NiFiDemo.json を選択し Addボタンを押す。
4. パラメータコンテキストを更新
事前に用意した Kafka ブローカーや Iceberg カタログの接続情報を入力。


5. NiFiDemo プロセスグループを開き、Controller Service を有効化
- Canvas 右クリック → Configuration → すべての Controller Service を Enable。
- 各プロセスグループも同様に有効化。

6. Routes → Kafka フローを開始し、キューを監視
成功/失敗キューでメッセージを確認。

7. Routes Kafka → Iceberg フローを開始し、キューを監視

8. Hue/Impala でテーブルを確認
SELECT * FROM airlines.routes_nifi_iceberg;
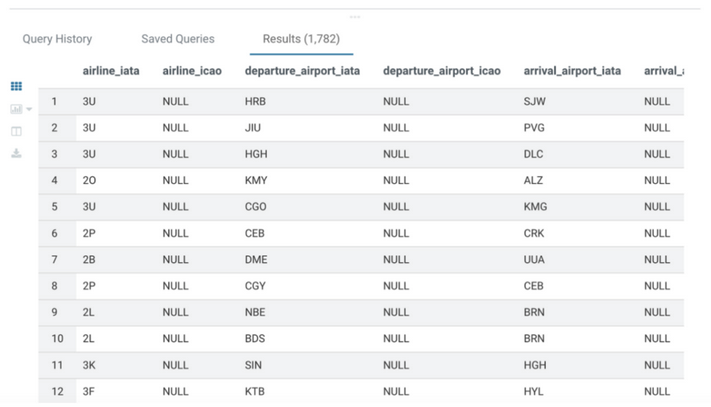
⸻
まとめ
本記事では Cloudera Flow Management(NiFi) を利用し、コードレスで Kafka 経由に Iceberg テーブルへストリーミングデータを取り込む方法を紹介しました。
次回は Apache Spark によるデータ処理 を取り上げます。
プライベートクラウドで Open Data Lakehouse を構築するには、CDP Private Cloud Base 7.1.9 をダウンロードし、本シリーズの他の記事もぜひご覧ください。