はじめに
DynamoDBは上手く使えば非常に強力なDBMSですがRDBとの違いは大きく、「RDBの代わりにDynamoDBを使おう!」と深く考えずに提案/採用することが難しいことから、その理由についてみていきます。
DynaomoDBの難しさ
DynamoDBの利点と表裏一体である、DynaomDBの主要な難しさについて順番に見ていきます。
1. 提供されているクエリモデルでできることが非常に限定されている
DynamoDBは次の公式サイトに記載がある通り、どんな規模でも数msの一定のパフォーマンスを発揮でき、無尽蔵にスケールできるという特徴があります。
Fast, flexible NoSQL database service for single-digit millisecond performance at any scale
この特性を上手く活用すると次の実例のように高可用性、数msのレイテンシーを維持しながら凄まじいスループットを発揮可能です。
Last year, over the course of our 66-hour Prime Day, these sources made trillions of API calls and DynamoDB maintained high availability with single-digit millisecond performance, peaking at 89.2 million requests per second.
しかしながら、この特性を維持するために、従来のRDBや流行り(?)のNewSQLとは異なり、スケーラビリティを阻害しない、非常に限られた種類のクエリしか実行できないという重大な縛りがあります。
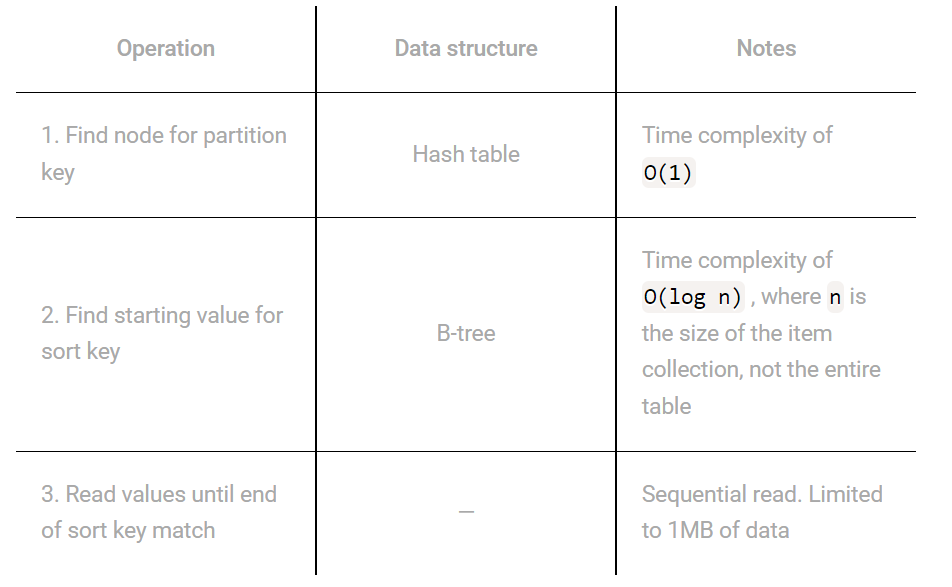
以下、DynamoDB Bookの著者であるalex debrie氏のブログの引用となりますが、DynamoDBではO(1), O(log n)の計算量、あるいは全件取得する場合には一度のリクエストで1MiBまでデータを取得する(QueryやScan)の操作のみがサポートされていることがわかります。例えばRDBで非常によく利用されるジョインや集計の機能は提供されていません。
※Scan, Queryで真面目に全件を順番に取得すればO(n)の計算量となりますが、DynamoDBがターゲットとしているWebアプリでは膨大な件数のデータを一画面に表示することは恐らくほとんどなく、通常はページネーションを実施することから、Queryで1リクエストしか投げないことが多いと思われます。
※テーブル設計次第ですが、同じパーティションキーを共有するアイテムコレクションがGiB, TiB, EiB...と無尽蔵に増大することは恐らく少ないと思われます。
※全件取得のScanに関してはParallel Scanの機能が提供されています。
SQL, NoSQL, and Scale: How DynamoDB scales where relational databases don't
一方でRDBにおけるジョインは手法にもよるものの、inner/outer tableの行数/データ量の増加により計算量が増大することから、以前は問題なく想定される時間内で応答を返せていたが、データ量の増大とともに性能が劣化するということがありえます。
また、クエリプラン管理等の機能で明示的に管理していない場合、クエリの実行計画が変化することがあり、このことが性能に非常に大きな影響を与えることがありえます。
※まれによくあります...
以上のようにDynamoDBは非常に限られた機能を提供するクエリモデルの縛りにより、「ジョイン対象のデータ量の増加によりクエリの性能が劣化する」「実行計画の変化によりクエリの性能が劣化する」等のRDBでありがちな事象は100%発生せず、データ量/ワークロードが増大しても安定したレイテンシーで応答を返せることから、この縛りを受け入れる必要があります。
RDBで非常に重要な機能であるACIDトランザクションについてはDynamoDBでもサポートされているものの、「DynamoDBの既存の特性を阻害しない」という開発目標を実現するために仕組みが従来のRDBとは著しく異なっており、APIについても癖があることに要注意です。
※癖のあるWriteのみ/Readのみのone-shot transactionを実行するAPIのみが提供されていますが、この仕組みにより既存のクエリを阻害しない、レイテンシーの削減、一定のレイテンシー、デッドロックやロック待ちの回避などを実現していると思われます。加えてこの仕組みは厳密な時刻の同期化が不要であり低コスト化/低負荷で済みます(動画中で説明がある通り、Time Sync Serviceにより数ms程度の誤差に抑えられていれば、多くのfalse negativeを防ぐことが可能です)
Amazon DynamoDB Transactions: 仕組み
Amazon DynamoDB: ACID Transactions using Timestamp Ordering
FAST '19 - Transactions and Scalability in Cloud Databases—Can’t We Have Both?
なお、スケールするRDBとして登場しているNewSQLについては、DynamoDBとしては次のような見解のようです。
一般的に考えて「ジョイン対象のデータ量の増加によりクエリの性能が劣化する」という問題は「複数のパーティションに分割され、ネットワーク越しにジョイン対象のデータを別のパーティションから取得しなければならない」となったときにデータの取得元のノードの特定と、ネットワーク越しのデータ転送によるレイテンシーにより、シングルノードのRDBで実行するよりも間違いなくオーバーヘッドが大きく、かつ実行計画を外した時のペナルティもより大きいと思われることから、RDBとしての扱いやすさとのトレードオフになると思われます。
These two factors are the primary barriers to scale for traditional RDBMS platforms. It remains to be seen whether the NewSQL community can be successful in delivering a distributed RDBMS solution. But it is unlikely that even that would resolve the two limitations described earlier. No matter how the solution is delivered, the processing costs of normalization and ACID transactions must remain significant.
2. シングルテーブルデザインが難しい
前述のようにDynamoDBではスケーラビリティを阻害しないためにクエリモデルの機能制限があることから、従来のRDBのようにジョインを実行できません。
しかしながら、現実のWebアプリではone-to-many, many-to-many等のエンティティ同士の関連が頻出することから、DynamoDB上でone-to-many, many-to-manyの関連を扱うためにシングルテーブルデザインの技法を習得する必要があります。
具体的な例は次の公式ドキュメントの記述がわかりやすいですが、アクセスパスを手動で洗い出し、DynamoDBのクエリモデルで扱えるようにパーティションキー、ソートキー、グローバルセカンダリーインデックス等を構成する必要があります。
Best practices for modeling relational data in DynamoDB
また、one-to-many/many-to-manyの関連をDynamoDBで扱う場合には、どうしてもジョインを避けるためのクエリの効率化とデータの重複が発生する非正規化のトレードオフが存在することに要注意です。
Best practices for managing many-to-many relationships
How to model one-to-many relationships in DynamoDB
有料となりますが、次の書籍にてone-to-many/many-to-manyで取りうる設計手法が非常によくまとまっているので、DynamoDBを本格的に活用される場合には目を通しておくことをお勧めします。
※「新しいアクセスパスが増えた場合にどうやって対処するのか?」「スキーマを変更したい場合にはどうすればよいのか?」「一意性制約を維持したい」等のDynamoDBで開発を行う際の重要なノウハウが多数含まれており、非常に有用な書籍です。
https://www.dynamodbbook.com/
いずれにせよ、従来のRDBで通用したスキーマ/クエリの設計手法をそのまま適用できないことから、DynamoDB専用の技術を習得する必要があります。
※とはいえ、他のNoSQL DBでも似たようなことを考える必要がありそうです。
※観測できた範囲では、シングルテーブルデザインで十数エンティティ、数十アクセスパターンをカバーしている事例をみたことがありますが、現実のアプリケーションではシステム全体でエンティティ数が数十~3桁以上に達することがあります。シングルテーブルでシステム全体のアクセスパターン(数百~数千、あるいはそれ以上)をすべて網羅することは恐らく人間の認知力的に無理があり破綻するので、一定の範囲で分割すべきだと思われます。それこそマイクロサービス化と相性が良いかもしれません。
3. 多くの場合、他のデータストアとの連携が必要になる
DynamoDBは柔軟なスキーマやグローバルセカンダリーインデックス、トランザクション等の機能を活用することにより「KVS」という分類から想像されるイメージよりはできることが多いものの、RDBよりは遥かにできることが少なく、ジョイン、集計、全文検索等の機能は提供されていないことから、その対策を考える必要があります。
大きく分けて次の3パターンの連携方法があると思われます。
Streamsによるリアルタイムの連携
例えば次のブログ記事にあるように、DynamoDBのStreamsの機能を用いて他のデータストアに変更差分を連携する、あるいはシンプルな集計であればDynamoDB上に集計テーブルを構築して更新するといった方法があります。
DynamoDB Streams Use Cases and Design Patterns
リアルタイムに近いデータを参照できることや、転送先のデータストアの性能をフルに発揮できる利点がありますが、一般的に異なるデータストア間のレプリケーションは更新クエリの記述、伝搬時の遅延の管理、データモデルの変換等の様々な要因で難易度が高いことに要注意です。
Federated Queryによるリアルタイムの検索
Athena等のサービスでFederated Queryを実行し直接DynamoDBへアクセスすることにより、リアルタイムにJOINや集計を実施する方法もあります。
この方法はセットアップが容易でデータの連携も必要もないですが、稼働中のDynamoDBのテーブルに直接負荷が発生すること、またDynamoDBからデータを取得した後に改めてJOINや集計を実施することから性能面でも制約があることに注意です。
Using Amazon Athena Federated Query
一定期間毎にデータを丸ごと入れ替える
S3へエクスポート、あるいはRedshiftの場合にはCOPY文で直接取り込むことにより、テーブルデータを丸ごと入れ替える方法も考えられます。
データのリアルタイム性は失われますが、Streamsによる変更の伝搬ほど難易度が高くなく、かつAthenaによる検索よりも性能面で優れていると思われます。
新機能 – Amazon DynamoDB テーブルデータを Amazon S3 のデータレイクにエクスポート。コードの記述は不要
Amazon DynamoDB からの COPY
いずれの方法でもデータストアそのものの管理が必要ですし、利用するアプリケーション側でも、データストア毎のドライバーの準備や接続先を切り替える等の対応が必要です。
4. そもそもDBMSとして信用できるのか、可用性や耐久性、セキュリティ、論理データ破損対策等がどうなっているのかわからない
今年公開された次の論文(と動画)にて、DynamoDBがどんな仕組みでどのような対策を実施しているのか開示されています。
過去の大規模な障害の教訓を生かして対策を実施したり、モニタリング、データ破損やソフトウェアのバグ対策、ハードウェアの故障対策等が実施されていることがわかります。
Amazon DynamoDB: A Scalable, Predictably Performant, and Fully Managed NoSQL Database Service
公式サイトでは「Enterprise Ready」の謳い文句です。
Amazon DynamoDB features
Enterprise ready
DynamoDB is built for mission-critical workloads, including support for atomicity, consistency, isolation, and durability (ACID) transactions for a broad set of applications that require complex business logic. DynamoDB helps secure your data with encryption and continuously backs up your data for protection, with guaranteed reliability through a service level agreement.
DynamoDBをなるべく労力をかけずに利用したい
セッションストアやキャッシュ、構成管理等、「殆どのケースでプライマリーキーでのアクセスのみで処理が完結し、one-to-many, many-to-manyの関連が存在せず、集計もまず実施しない」データモデルのみを扱うことで、前述の難しさの大半を回避でき、いくらスケールしても性能が一定、サーバーレスで管理が容易等のDynamoDBの恩恵を受けることができると思われます。
あるいはCQRSパターンを適用し、スケーラビリティが高いDynamoDBでは書き込みのみを受け付けて、バックエンドのRDBに変更差分をバッチ適用することで実際のクエリの発行はRDBに対して行うといった方法も考えられます。
CQRSパターン
まとめ
他にも理由を挙げればきりがないと思いますが(例: ベンダーロックインが嫌、コストの見積もりが難しい、そもそも想定されるワークロードが全く向いていない、開発のノウハウがない etc...)、特に重要と思われるものに関して理由と可能ならば対策を見ていきました。
- 2., 3.で見てきたように、DynamoDBは「Fast, flexible NoSQL database service for single-digit millisecond performance at any scale」を実現するために従来のRDBの利便性を切り捨てており、one-fit-for-allなDBMSではないことから扱いには注意が必要です。
あらゆる状況で効率的なDBMSではないので無理に採用する必要はないですし、検討なしでRDBの代わりに利用することは危険ですが、スケーラビリティや安定したレイテンシーを生かせる用途に対しては非常に強力なDBMSだと思われます。
最後に参考情報として、以下の公式の事例集にて具体的にどのような用途に活用されているのか確認できます。
※youtube上にも無数の活用事例のビデオが存在します
Amazon DynamoDB Customers