先日Parallel gemが更新されて、PARALLEL_PROCESSOR_COUNT環境変数で同時に実行するプロセス数を設定できるようになりました。いくつに設定するのが良いのかちょっと調べてみました。
この記事は、Heroku Advent Calendar 2019の12月9日の記事です。12月8日の「Heroku CLIの動きを観察する」から連投です。ごめんなさい!12月10日は1ntegrale9さんによる「Heroku×Redis×Python で始める NoSQL DB 入門」です。
まとめ
共有dynoでは最適な同時実行プロセス数ははっきりとはわかりませんでした。すべてのCPUコアを利用しようとするような最適化はあまり有効ではいようです。占有dynoでは、Performance/Private-M dynoでは1コア的な振舞いが、Performance/Private-Lで dynoは4コア程度のような振舞いがみられました。Performance/Private-L dynoでは、CPUがボトルネックになっている場合にはプロセスの並列度が4程度になるように調整することでより効率よくCPUを利用することができるかもしれません。
本稿の内容は2019年11月時点のものです。特にHerokuでの測定結果については、その後のインフラストラクチャやプラットフォームの変更によって変化している可能性があります。
測定方法
今回はCPUがボトルネックになるように負荷をかけて、実行にかかる時間が並列プロセス数でどう変化するか調べてみます。zunda/pipi-benchにコードの一式を公開しています。
負荷として、piコマンドで円周率を計算してみます。スワップメモリを使ってしまわないよう桁数は99999桁に抑えておき、測定誤差を抑えるため同じ計算を32回繰り返します。このひとまとまりのタスクをバックグラウンドに回していくつか並列に実行し、すべて完了するまで待ちます。
並列度を変えてこのタスクの完了までの時間を測定します。理想的な場合には、CPUのそれぞれのコアに1つずつ計算プロセスが割り当てられ、コア数と同じ並列度まではタスク完了までの時間が変化せず、並列度がコア数を越えるとタスク完了までの時間が並列度に比例して増えるはずです。
測定結果
まずはコア数とタスク完了までの時間の変化を確かめるため、手元の仮想化していない環境で測定してみました。次に、Herokuの様々な大きさのdynoで測定してみました。
コア数が少ない場合
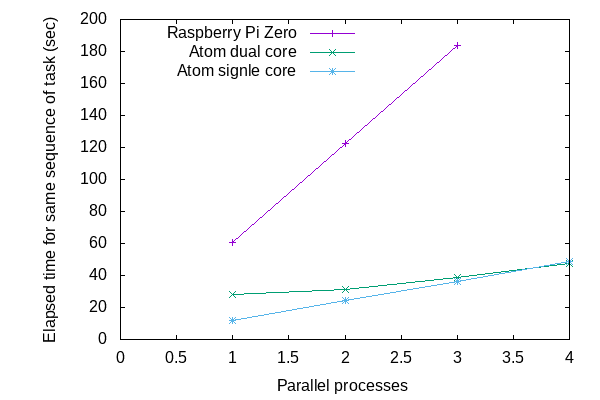
手元のRaspberry Pi Zero (1コアのARMv6-compatible processor rev 7 (v6l))、Atomネットブック2台 (1コアのIntel(R) Atom(TM) CPU E3815 @ 1.46GHzと4スレッドなのでたぶん2コアのIntel(R) Atom(TM) CPU N2600 @ 1.60GHz)で測定してみました。
予想どおり、1コアでは完了までの時間が並列度に比例しているようです。また、2コアでは並列度が2くらいまでは完了までの時間があまり変化していないように見えます。
コア数が多い場合
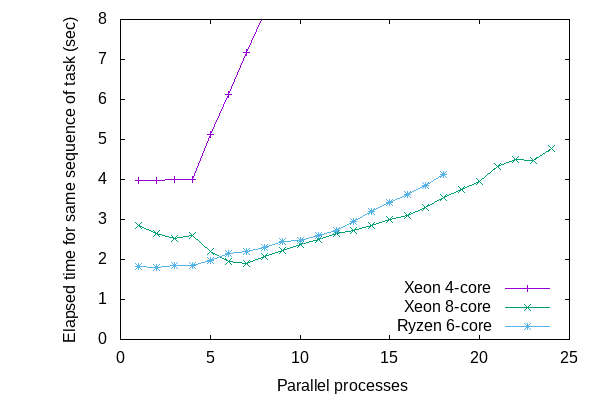
手元の古いXeonマシン (4スレッドなんだけど結果を見るとたぶん4コアのIntel(R) Xeon(R) CPU 5160。BIOSからHyper Threadingを無効にしてあったような気がしてきた)や、最近のRyzenマシン (6コアのAMD Ryzen 5 2600 Six-Core Processor)では予想どおりコア数くらいまでの並列度では完了までの時間があまり変化していません。Xeonマシン (16スレッドなのでたぶん8コアのIntel(R) Xeon(R) CPU E5-1660 v4 @ 3.20GHz) では並列度が低い場合に完了までの時間が長く、コア数と同等になると最も速く完了するようです。不思議。
インスタンスを共有するdyno
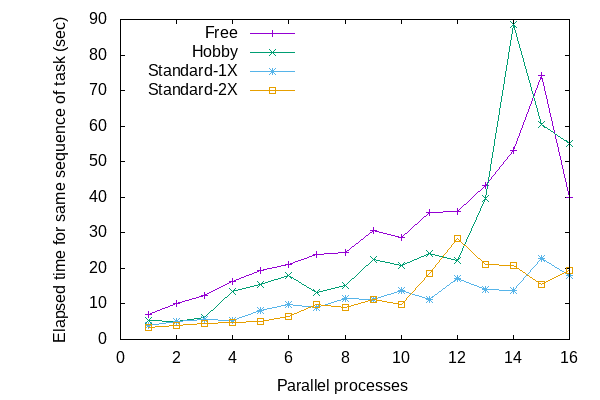
全体的に、並列度の増加に応じて完了までの時間が増えています。コードが実行される環境とハードウェアとの間に仮想化層が関連して、さらにインスタンスを共有するコンテナとのリソースの取り合いもあり、プロセスとCPUコアとの関連が明確ではないのでしょう。
これらのdynoでは、Parallel gemのデフォルトでは8コアと検出されるようです。CPUの使い過ぎでアプリの動作が遅くなっている可能性がある場合には、PARALLEL_PROCESSOR_COUNT config varで並列度を下げることで問題が起きにくくなるかもしれません。
$ heroku run "ruby -retc -e 'puts Etc.nprocessors'"
8
インスタンスを占有するdyno
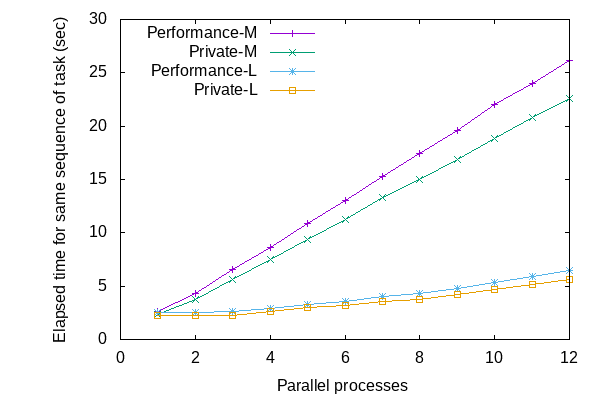
インスタンスを共有するdynoと比較して、並列度と完了までの時間が明確なようです。Performance/Private-M dynoではだいたい並列度に比例して完了までの時間が増えていて、Performance/Private-L dynoでは並列度が4程度までは完了までの時間があまり変化しませんでした。
Parallel gemのデフォルトではPerformance/Private-Mでは2コアと、Performance/Private-Lでは8コアと検出されました。
$ heroku run "ruby -retc -e 'puts Etc.nprocessors'" --size=performance-m
2
$ heroku run "ruby -retc -e 'puts Etc.nprocessors'" --size=performance-l
8
CPUがburstableなのでPrivate-S dynoでは測定していません。