背景・目的
Glue Crawlerを実行することなく、パーティションを作れるので試してみました。
まとめ
- GlueのDynamicFrameにより、Glue Crawlerを使用しなくてもパーティションが作成されます。
- 下記のパラメータを指定します。
- setCatalogInfoでスキーマ
- enableUpdateCatalog=True
- partitionKeys
概要
AWS Glue ETL ジョブからの Data Catalog でのテーブルの作成、スキーマの更新、および新規パーティションの追加の内容をまとめます。
新しいパーティション
ジョブが終了すると、クローラを再実行することなく、コンソールで新しいパーティションがすぐに表示されます。この機能は、次の例に示すように、ETL スクリプトに数行のコードを追加して有効にすることができます。このコードは enableUpdateCatalog 引数を使用して、新しいパーティションの作成時のジョブ実行中に Data Catalog を更新する必要があることを示します。
enableUpdateCatalog に partitionKeys と getSink() を渡して、DataSink オブジェクトで setCatalogInfo() を呼び出します。
ドキュメントを読むと、下記のように記述することでCrawlerを実行することなく、データの作成と同時にパーティションが作られるとのことでした。
- setCatalogInfoでスキーマを指定する
- enableUpdateCatalog=Trueを指定する
- partitionKeysを指定する
sink = glueContext.getSink(
connection_type="s3",
path="<S3_output_path>",
enableUpdateCatalog=True,
partitionKeys=["region", "year", "month", "day"])
sink.setFormat("json")
sink.setCatalogInfo(catalogDatabase=<target_db_name>, catalogTableName=<target_table_name>)
sink.writeFrame(last_transform)
実践
事前準備
- S3バケットに、下記のデータをアップロードします。
{"id":1,"group":"blue","ymd":"20230613"} {"id":2,"group":"blue","ymd":"20230614"} {"id":3,"group":"yellow","ymd":"20230615"}
Glueのスキーマを作成
-
テーブルを作成します。

-
パーティションはこの時点でありません。

Glueジョブを作成
-
Visual Editorで作成します。

-
生成されたコードを確認します。下記が作成されているのでカスタマイズする必要はなさそうです。
- setCatalogInfoスキーマ
- enableUpdateCatalog=True
- partitionKeys
import sys from awsglue.transforms import * from awsglue.utils import getResolvedOptions from pyspark.context import SparkContext from awsglue.context import GlueContext from awsglue.job import Job args = getResolvedOptions(sys.argv, ["JOB_NAME"]) sc = SparkContext() glueContext = GlueContext(sc) spark = glueContext.spark_session job = Job(glueContext) job.init(args["JOB_NAME"], args) # Script generated for node S3 bucket S3bucket_node1 = glueContext.create_dynamic_frame.from_options( format_options={"multiline": False}, connection_type="s3", format="json", connection_options={ "paths": ["s3://XXXXXX/input/json/20230615/"], "recurse": True, }, transformation_ctx="S3bucket_node1", ) # Script generated for node ApplyMapping ApplyMapping_node2 = ApplyMapping.apply( frame=S3bucket_node1, mappings=[ ("id", "int", "id", "int"), ("group", "string", "group", "string"), ("ymd", "string", "ymd", "string"), ], transformation_ctx="ApplyMapping_node2", ) # Script generated for node S3 bucket S3bucket_node3 = glueContext.getSink( path="s3://XXXXX/output/partition/", connection_type="s3", updateBehavior="UPDATE_IN_DATABASE", partitionKeys=["ymd"], enableUpdateCatalog=True, transformation_ctx="S3bucket_node3", ) S3bucket_node3.setCatalogInfo( catalogDatabase="test_db", catalogTableName="partition_test" ) S3bucket_node3.setFormat("json") S3bucket_node3.writeFrame(ApplyMapping_node2) job.commit()
実行結果の確認
-
ジョブを実行し「Succeeded」になることを確認します。

-
データはパーティションキーごとに出力されています。

-
パーティションも作成されています。
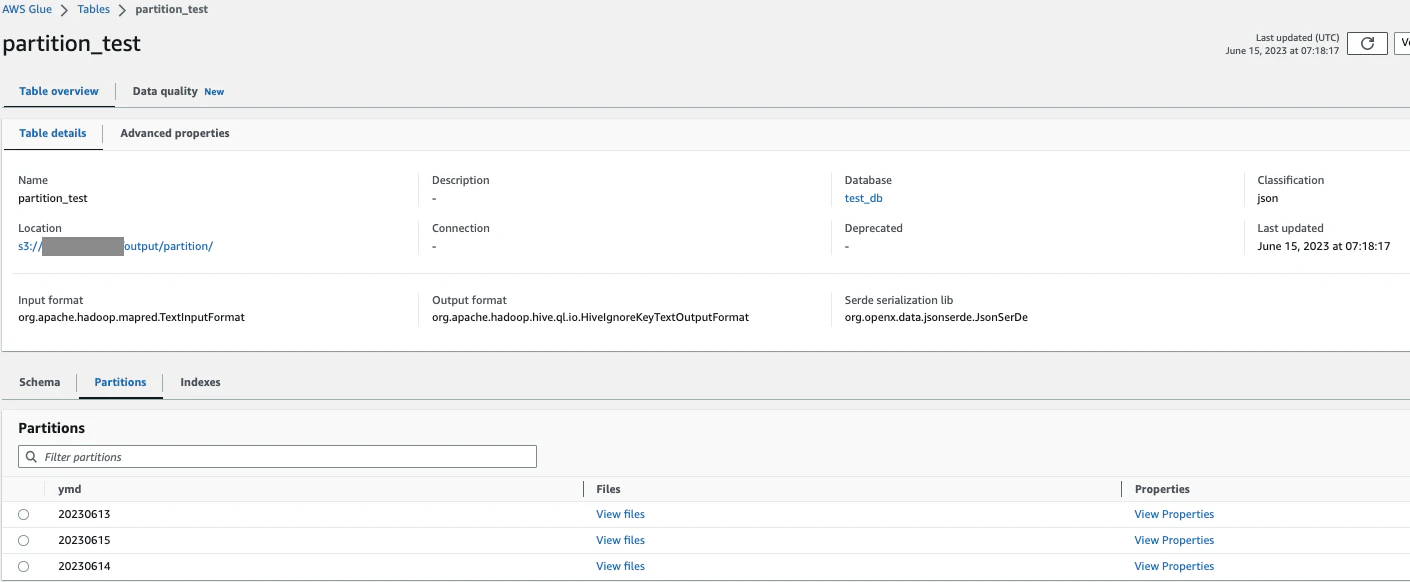
-
Athenaでクエリすることも可能です。

考察
Glue Crawlerを使用しなくてもパーティションが作成されることを確認できました。
参考