背景・目的
今までテキスト処理に関する経験はありましたが、画像や動画の加工等には関わってきませんでした。
今回は、画像や動画の加工処理を行うための手法について、特徴を整理しハンズオンをします。
ネットで調べたところ、Pythonで画像や動画の加工するには、OpenCVというライブラリが多く使われていることがわかりました。そのため、今回はOpenCVを試してみます。
まとめ
下記に特徴を整理します。
| 特徴 | 説明 |
|---|---|
| OpenCVとは | ・Open Source Computer Vision Libraryの略 ・コンピュータービジョンとマシンラーニングソフトウェアのライブラリ ・コンピュータービジョンアプリケーションに共通のインフラを提供 ・Apache 2.0 ライセンス |
| OpenCVの特徴 | ・2500を超える最適化されたアルゴリズムがある ・古典的なものと最先端のコンピュータービジョン、機械学習アルゴリズムの両方の包括的なセットが含まれる |
| OpenCVでできること | ・顔の検出と認識 ・オブジェクトの識別 ・ビデオ内の人間の動作の分類 ・カメラの動きの追跡 ・移動するオブジェクトの追跡 ・オブジェクトの3Dモデルの抽出 ・ステレオカメラからの3Dポイントクラウドの生成 ・画像をつなぎ合わせてシーン全体の高解像度画像を生成 ・画像データベースから類似画像を検索 ・フラッシュを使用して撮影した画像から赤目を除去する ・目の動きを追跡する ・風景を認識してマーカーを確立して拡張現実に重ね合わせる |
| コンピュータービジョンとは | マシンが画像を自動的に認識して正確かつ効率的に記述するために使用する技術 |
| コンピュータービジョン特徴 | オブジェクトの識別、顔認識、分類、レコメンド、監視、検出を行う |
| コンピュータービジョンできできること | コンピューターシステムは、下記のデバイス等から取得された、それらにより作成された大量の画像及びビデオデータにアクセスできる ・スマホ ・交通カメラ ・セキュリティシステム ・その他のデバイス |
| コンピュータービジョンの用途 | ・セキュリティと安全 ・運用効率 ・医療 ・自動走行車 ・農業 |
| 動画の画質 | 下記の要素できまる。 ・解像度 ・ビットレート ・フレームレート ・圧縮方式(コーデック) |
| COCO | COCOは、大規模オブジェクト検出、セグメンテーション、キャプション付きデータセット |
| NumPy | Python での科学計算の基本パッケージ 多次元配列オブジェクト、さまざまな派生オブジェクト (マスクされた配列や行列など)、および数学、論理、形状操作、ソート、選択、I/O、離散フーリエ変換、基本的な線形代数、基本的な統計演算、ランダム シミュレーションなど、配列に対する高速操作のためのさまざまなルーチンを提供する Python ライブラリ |
| matplotlib | Matplotlib は、Python で静的、アニメーション化されたインタラクティブなビジュアライゼーションを作成するための包括的なライブラリ |
概要
OpenCVとは
下記のドキュメントを基に整理します。
OpenCV (Open Source Computer Vision Library) is an open source computer vision and machine learning software library. OpenCV was built to provide a common infrastructure for computer vision applications and to accelerate the use of machine perception in the commercial products. Being an Apache 2 licensed product, OpenCV makes it easy for businesses to utilize and modify the code.
- OpenCVは、Open Source Computer Vision Libraryの略
- コンピュータービジョンとマシンラーニングソフトウェアのライブラリ
- コンピュータービジョンアプリケーションに共通のインフラを提供
- Apache 2.0 ライセンス
The library has more than 2500 optimized algorithms, which includes a comprehensive set of both classic and state-of-the-art computer vision and machine learning algorithms. These algorithms can be used to detect and recognize faces, identify objects, classify human actions in videos, track camera movements, track moving objects, extract 3D models of objects, produce 3D point clouds from stereo cameras, stitch images together to produce a high resolution image of an entire scene, find similar images from an image database, remove red eyes from images taken using flash, follow eye movements, recognize scenery and establish markers to overlay it with augmented reality, etc. OpenCV has more than 47 thousand people of user community and estimated number of downloads exceeding 18 million. The library is used extensively in companies, research groups and by governmental bodies.
- 2500を超える最適化されたアルゴリズムがある
- 古典的なものと最先端のコンピュータービジョン、機械学習アルゴリズムの両方の包括的なセットが含まれる
- アルゴリズムを使用して下記が実現できる
- 顔の検出と認識
- オブジェクトの識別
- ビデオ内の人間の動作の分類
- カメラの動きの追跡
- 移動するオブジェクトの追跡
- オブジェクトの3Dモデルの抽出
- ステレオカメラからの3Dポイントクラウドの生成
- 画像をつなぎ合わせてシーン全体の高解像度画像を生成
- 画像データベースから類似画像を検索
- フラッシュを使用して撮影した画像から赤目を除去する
- 目の動きを追跡する
- 風景を認識してマーカーを確立して拡張現実に重ね合わせる
- OpenCVには47,000人を超えるユーザーコミュニティがある
- 推定ダウンロード数は 1,800万回を超えている
- このライブラリは、企業、研究グループ、政府機関で広く使用されている
Along with well-established companies like Google, Yahoo, Microsoft, Intel, IBM, Sony, Honda, Toyota that employ the library, there are many startups such as Applied Minds, VideoSurf, and Zeitera, that make extensive use of OpenCV. OpenCV’s deployed uses span the range from stitching streetview images together, detecting intrusions in surveillance video in Israel, monitoring mine equipment in China, helping robots navigate and pick up objects at Willow Garage, detection of swimming pool drowning accidents in Europe, running interactive art in Spain and New York, checking runways for debris in Turkey, inspecting labels on products in factories around the world on to rapid face detection in Japan.
- 下記のような企業がOpenCVを利用している
- 大手企業
- Yahoo
- Microsoft
- Intel
- IBM
- Sony
- Honda
- Toyota
- スタートアップ
- Applied Minds
- VideoSurf
- Zeitera
- 大手企業
- OpenCV の導入用途は、下記のように多岐にわたる
- ストリートビュー画像のつなぎ合わせ
- イスラエルの監視ビデオでの侵入検知
- 中国の鉱山設備の監視
- Willow Garage でのロボットの移動と物体の回収
- ヨーロッパでのプールでの溺死事故の検知
- スペインとニューヨークでのインタラクティブ アートの実行
- トルコでの滑走路の残骸のチェック
- 世界中の工場での製品ラベルの検査
- 日本における迅速な顔検出
It has C++, Python, Java and MATLAB interfaces and supports Windows, Linux, Android and Mac OS. OpenCV leans mostly towards real-time vision applications and takes advantage of MMX and SSE instructions when available. A full-featured CUDAand OpenCL interfaces are being actively developed right now. There are over 500 algorithms and about 10 times as many functions that compose or support those algorithms. OpenCV is written natively in C++ and has a templated interface that works seamlessly with STL containers.
- 下記のI/Fがある
- C++
- Python
- Java
- MATLAB
- 下記のOSをサポートしている
- Windows
- Linux
- Android
- Mac OS
- OpenCV は主にリアルタイム ビジョン アプリケーション向け
- 利用可能な場合は MMX および SSE 命令を活用する
- フル機能の CUDAおよび OpenCL インターフェイスは現在積極的に開発されている
- 500 を超えるアルゴリズムと、それらのアルゴリズムを構成またはサポートする関数の数は、その約 10 倍
- OpenCV はネイティブに C++ で記述されており、STL コンテナーとシームレスに連携するテンプレート インターフェイスを備えている
コンピュータービジョンとは
下記の記事を基に整理します。
コンピュータビジョンは、マシンが画像を自動的に認識して正確かつ効率的に記述するために使用する技術です。現在、コンピューターシステムは、スマートフォン、交通カメラ、セキュリティシステム、およびその他のデバイスから取得された、またはそれらによって作成された大量の画像およびビデオデータにアクセスできます。コンピュータビジョンアプリケーションでは、人工知能と機械学習 (AI/ML) を使用してこのデータを正確に処理し、オブジェクトの識別や顔認識、分類、推奨、監視、検出を行います。
- マシンが画像を自動的に認識して正確かつ効率的に記述するために使用する技術
- コンピューターシステムは、下記のデバイス等から取得された、それらにより作成された大量の画像及びビデオデータにアクセスできる
- スマホ
- 交通カメラ
- セキュリティシステム
- その他のデバイス
- 人工知能と機械学習を使用して上記のデータを正確に処理しオブジェクトの識別、顔認識、分類、レコメンド、監視、検出を行う
ユースケース
-
セキュリティと安全
- 政府や企業は、資産、施設、設備のセキュリティを向上させるためにコンピュータービジョンを利用している
- 例えば、カメラとセンサーは下記を監視する
- 公共スペース
- 工業用地
- および高度なセキュリティ環境
- 権限のない個人が立ち入り禁止区域に入るなど、通常とは異なることが発生した場合、自動アラートを送信する
- 例えば、カメラとセンサーは下記を監視する
- 自宅だけでなく職場でも個人の安全を向上させることが可能
- 例えば、認識技術は安全に関連する無数の問題を監視できる
- ペットを検出する自宅でのリアルタイムストリーム
- 訪問者や配達された荷物を検知するライブフロントドアカメラなど
- 職場での監視には、下記がある
- 作業者による適切な個人用保護具の着用
- 警告システムへの通知
- 報告書の作成
- 例えば、認識技術は安全に関連する無数の問題を監視できる
- 政府や企業は、資産、施設、設備のセキュリティを向上させるためにコンピュータービジョンを利用している
-
運用効率
- コンピュータービジョン
- 画像を分析してビジネスインテリジェンスのメタデータを抽出することで、新たな収益機会と業務効率を創出する
- 例えば、下記が可能
- 製品が工場から出荷される前に品質欠陥を自動的に特定
- マシンのメンテナンスと安全上の問題を検知
- ソーシャルメディアの画像を分析して、顧客行動の傾向とパターンを発見
- 自動顔認識による従業員認証
- コンピュータービジョン
-
医療
- ヘルスケアは、コンピュータービジョン技術を応用する主要産業の1つ
- 特に、医療画像解析は臓器や組織を視覚化して医療従事者が迅速かつ正確な診断を下すのに役立つ
- 結果として治療成績や平均余命の向上につながる
- 例
- ほくろや皮膚病変の分析による腫瘍検出
- 自動 X 線分析
- MRI スキャンによる症状発見
- ヘルスケアは、コンピュータービジョン技術を応用する主要産業の1つ
-
自動走行車
- 自動運転車技術は、コンピュータービジョンを使用してリアルタイムの画像を認識し、自律輸送に搭載された複数のカメラから 3D マップを作成する
- 画像を分析して、他の道路利用者、道路標識、歩行者、または障害物を特定する
- 半自動運転車では、コンピュータービジョンが機械学習 (ML) を使用してドライバーの行動を監視する
- 例えば、下記を探す
- ドライバーの頭の位置
- アイトラッキング
- 上半身の動きに基づいて、注意散漫や疲労、眠気の兆候を探す
- 例えば、下記を探す
- このテクノロジーが特定の警告標識を検出すると、ドライバーに警告し、運転事故の可能性を減らす
-
農業
- 生産性の向上からインテリジェントオートメーションによるコスト削減まで、コンピュータービジョンアプリケーションは農業部門全体の機能を強化する
- 衛星画像や UAV 映像は、広大な土地の分析と農業慣行の改善に役立つ
- コンピュータビジョンアプリケーションは、下記のタスクの自動化する
- 畑の状態の監視
- 作物の病気の特定
- 土壌水分のチェック
- 天候や収穫量の予測など
- コンピュータービジョンによる動物モニタリングは、スマートファーミングのもう 1 つの重要な戦略
コンピュータービジョンはどのように機能するか
コンピュータビジョンシステムは、人工知能 (AI) 技術を使用して、物体認識と物体分類を担う人間の脳の機能を模倣します。コンピューター科学者は、膨大な量の情報を入力して視覚データを認識するようにコンピューターをトレーニングします。機械学習 (ML) アルゴリズムは、こうした画像や動画の一般的なパターンを識別し、その知識を適用して未知の画像を正確に識別します。例えば、コンピューターが何百万もの車の画像を処理すると、画像内の車両を正確に検出できる識別パターンが構築され始めます。コンピュータビジョンには、以下のような技術が使われています。
- 人工知能 (AI) 技術を使用して、物体認識と物体分類を担う人間の脳の機能を模倣
- コンピューター科学者は、膨大な量の情報を入力して視覚データを認識するようにコンピューターをトレーニングする
- 機械学習 (ML) アルゴリズムは、こうした画像や動画の一般的なパターンを識別し、その知識を適用して未知の画像を正確に識別する
- 例えば、コンピューターが何百万もの車の画像を処理すると、画像内の車両を正確に検出できる識別パターンが構築される
- 下記のような技術が利用されている
- 深層学習
- 深層学習は、ニューラルネットワークを使用する機械学習の一種
- 深層学習ニューラルネットワークは、コンピューター内で連携して動作する人工ニューロンと呼ばれるソフトウェアモジュールを何層にも重ねて構成されている
- 数学的な計算を使って画像データのさまざまな側面を自動的に処理し、画像に関する総合的な理解を徐々に深めていく
- 畳み込みニューラルネットワーク
- 畳み込みニューラルネットワーク (CNN) は、ラベリングシステムを利用して視覚データを分類し、画像全体を理解する
- 画像をピクセルとして分析し、各ピクセルにラベル値を与える。この値を入力して、コンボリューションと呼ばれる数学演算を実行し、画像について予測を行う
- 人間が遠くにある物体を認識しようとするように、CNN はまず輪郭や単純な形を識別してから、色、内部の形、質感などの詳細を入力する
- 最後に、予測プロセスを数回繰り返して精度を向上させる
- リカレントニューラルネットワーク
- リカレントニューラルネットワーク(RNN)は CNN に似ているが、一連の画像を処理してそれらの間のリンクを見つけることができる
- CNN は単一画像の分析に使用されるが、RNN は動画を分析して画像間の関係を理解できる
- 深層学習
コンピュータビジョンと画像処理の違い
画像処理では、アルゴリズムを使用して、シャープ化、スムージング、フィルタリング、強調などの画像を変更します。コンピュータービジョンは、画像を変えるのではなく、見たものを理解してラベル付けなどのタスクを実行するという点で異なります。場合によっては、画像処理を使用して画像を変更し、コンピュータービジョンシステムが画像をよりよく理解できるようにすることができます。また、コンピュータービジョンを使用して画像や画像の一部を識別し、画像処理を使用して画像をさらに修正する場合もあります。
- 画像処理
- アルゴリズムを使用して、シャープ化、スムージング、フィルタリング、強調などの画像を変更する
- コンピュータービジョン
- 画像を変えるのではなく、見たものを理解してラベル付けなどのタスクを実行する
- 画像処理+コンピュータービジョン
- 画像処理を使用して画像を変更し、コンピュータービジョンシステムが画像をよりよく理解できるようにする事が可能
- コンピュータービジョンを使用して画像や画像の一部を識別し、画像処理を使用して画像をさらに修正するなどもある
NumPy
下記を基に整理します
- Python での科学計算の基本パッケージ
- 多次元配列オブジェクト、さまざまな派生オブジェクト (マスクされた配列や行列など)、および数学、論理、形状操作、ソート、選択、I/O、離散フーリエ変換、基本的な線形代数、基本的な統計演算、ランダム シミュレーションなど、配列に対する高速操作のためのさまざまなルーチンを提供する Python ライブラリ
matplotlib
下記を基に整理します
- Matplotlib は、Python で静的、アニメーション化されたインタラクティブなビジュアライゼーションを作成するための包括的なライブラリ
- Matplotlib は、簡単なことを簡単に、そして難しいことを可能にする
動画の画質
下記の記事とChatGPTを参考に動画の画質について整理します
動画の画質の構成要素
下記の要素で決まるようです。
- 解像度
- ビットレート
- フレームレート
- 圧縮方式(Codec)
解像度
- 解像度は、画素数を指す
- 横✕縦のピクセル数で表記する
- 1280 ✕ 820 Pxなどの数値表す事ができる。単位はpx(ピクセル)が使われる
- 数値が大きいほど高精細
代表的な解像度
解像度=動画サイズで表現できる
- SD(Sntandard definition television):720 ✕ 480 px
- HD(High definition video):1280 ✕ 720 px
- フルHD(Full High Ddefinition Video):1920 ✕ 1080 px
- WQHD(Wide Quad High Definition):2560 ✕ 1440 px
- 4K:4096 ✕ 2160 px
- 8K:7680 ✕ 4320 px
アスペクト比
- 動画のアスペクト比は、動画サイズ(解像度)の横と縦のサイズの比率を指す
- PCの視聴は、16:9が一般的
ビットレート
- 1秒間あたりのデータ量のこと
- 単位はbps(bit per second)を使用する
- 動画ビットレートには下記がある。これらの合算が総合ビットレートという
- 映像ビットレート
- 音声ビットレート
- 映像ビットレートのほうが大きくなりがち
フレームレート
- 1秒間に何枚のフレームを使用するか
- 単位は、fps(frame per socond)
- 30fpsは、30枚、15fpsは15枚
- フィルムのコマと同様。1秒間の枚数が多いほどスムーズで少ないとカクカクする
- エンコードの際には、ただ枚数を増やせば良いかというわけでもない。同じビットレートで配信するとコマ1枚の品質は少ないほうが良くなる
- 例:下記では1秒間に流れるデータ量は変わらない。15fpsのほうが1枚あたりのフレームの静止画に割当てられるデータ量は2倍になる
- 1Mbps 30fps
- 1Mbps 15fps
- 例:下記では1秒間に流れるデータ量は変わらない。15fpsのほうが1枚あたりのフレームの静止画に割当てられるデータ量は2倍になる
コーデック(Codec)
- データの規格
- 映像や音声データをエンコード(符号化)/デコード(復号化)するプログラム
- 下記のようなもので何かしらのコーデックが使われている
- ビデオCD
- DVD
- デジタルビデオカメラ
- ワンセグ
- 車載プレイヤー等
- 動画のコーデックでは下記のようなものがある
- H.264
- H.265
- MPEG-2
- WMV
- 音声データでは下記のようなものがある
- MP3
- AAC
- WMA
- 動画をインターネットで配信するためには、これらのコーデックを用いてエンコード作業を行う必要がある
- 動画ファイルとコーデックは異なる
- 動画は、音声と映像がそれぞれコーデックという規格になり、映像データ、音声データとなり動画ファイルという入れ物にまとめられている
- 動画と音声を同梱できる動画ファイルを「コンテナファイル」という
音声・映像は別々のデータとして動画ファイルに格納される
- 動画ファイルには、各形式により格納できる映像、音声データのコーデックが決まる
- 例)MP4に格納できるコーデック
- 映像コーデック:MPEG-1、MPEG-2、MPEG-4、H.264/MPEG-4 AVC、H.265など
- 音声コーデック:AAC、HE-AAC、MP1、MP2、MP3、MPEGE-4 ALS、TwinVQ、CELPなど
同じファイル形式でも、コーデックが違えば別物である
- 同じファイル形式でも、コーデックが違えばその中身は別物
- 動画ファイルは、ファイルの拡張子を見ただけでは、どのコーデックを使用しているかわからない
- 再生に関しては、提供と受け手のコーデックがあっていないとエラーになる
- 受け手の視聴環境にコーデックがないと再生されない
COCO
下記を基に整理します。
COCO is a large-scale object detection, segmentation, and captioning dataset. COCO has several features:
- Object segmentation
- Recognition in context
- Superpixel stuff segmentation
- 330K images (>200K labeled)
- 1.5 million object instances
- 80 object categories
- 91 stuff categories
- 5 captions per image
- 250,000 people with keypoints
- COCOは、大規模オブジェクト検出、セグメンテーション、キャプション付きデータセット
- いくつかの特徴がある
- オブジェクトのセグメンテーション
- コンテキストの認識
- セグメンテーション
- 330K画像(200Kラベル付き)
- 150万のオブジェクトインスタンス
- 80のオブジェクトカテゴリ
- 91のカテゴリ
- 画像ごとの5つのキャプション
- キーポイントを持つ25万人
実践
AWS上でOpenCVを使用していろいろ試してみます。
環境構築
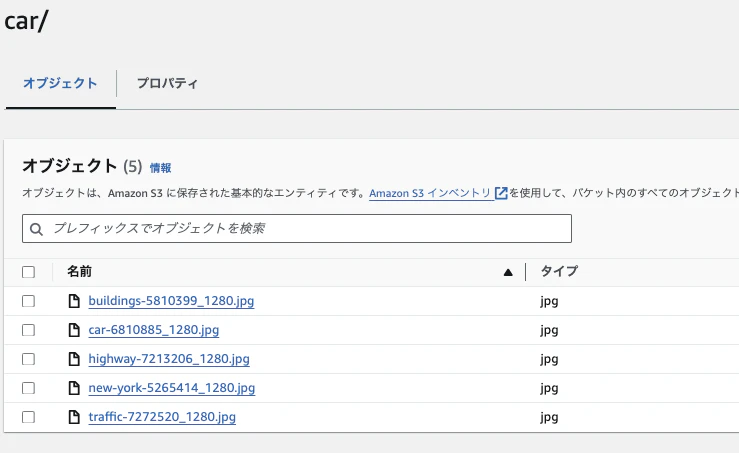
S3バケットの作成
- S3バケットを事前に作成しておきます
データセットのダウンロード
-
権利的に問題ない画像を取得します。私は、O-DANからダウンロードしました
-
ダウンロードしたファイルを解凍し、S3にアップロードします
SageMakerインスタンスの起動
-
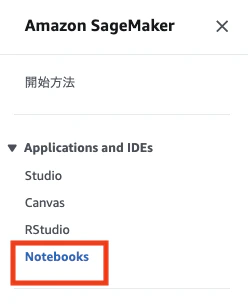
AWSにサインインし、SageMakerに移動します
-
ナビゲーションペインから「Notebooks」をクリックします
-
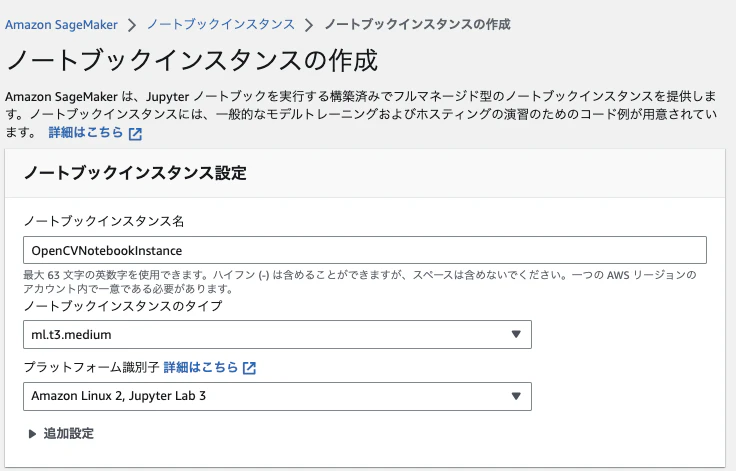
「ノートブックインスタンスの作成」をクリックします
-
下記を入力します
- ノートブックインスタンス名
- ノートブックインスタンスのタイプ
- プラットフォーム識別子
-
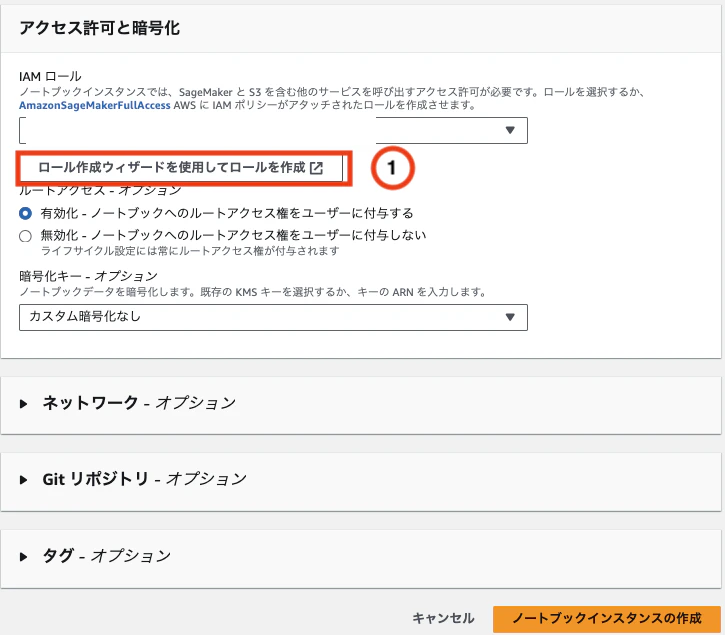
「ロール作成ウィザードを使用してロールを作成」をクリックすると、別タブが開きます。
-
ロール名のサフィックス、ロール許可のペルソナを選択し「次へ」をクリックします
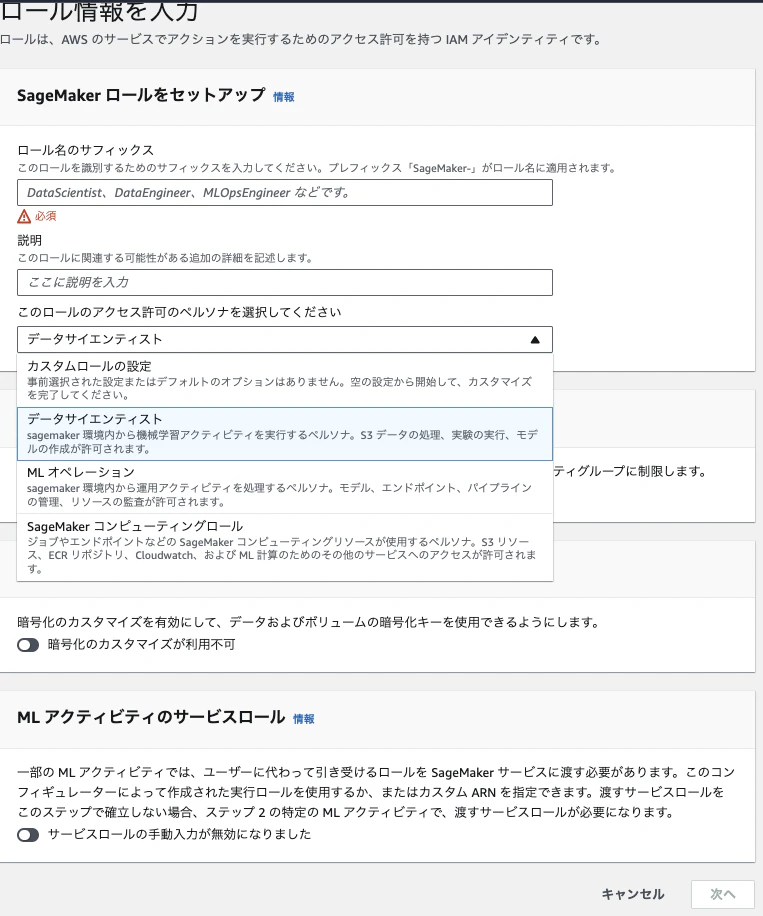
-
IAMポリシーを追加し「次へ」をクリックします
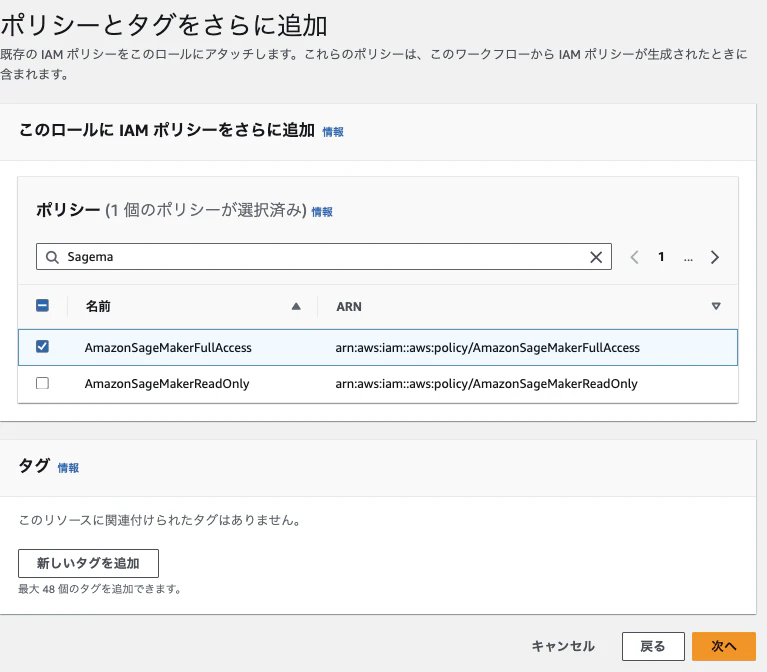
-
最後に「送信」します
-
作成したIAMロールを指定し「ノートブックインスタンスの作成」をクリックします
-
しばらくすると、利用可能になります

ノートブックの作成
-
「Jupyterを開く」をクリックします

-
「New」を選択し、「conda_python3」をクリックすると、別タブでノートブックが開きます
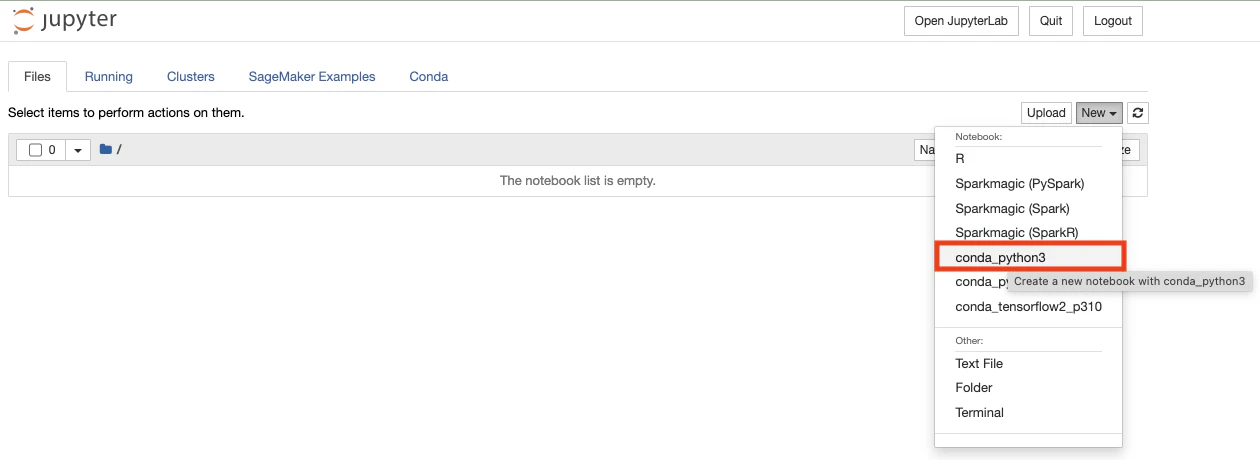
OpenCVのインストール
- OpenCVとboto3をインストールします
!pip install opencv-python !pip install boto3 - バージョンを確認します。4.10がインストールされました
import cv2 cv2.__version__
事前準備
- S3パスのパスを設定しておきます
S3_BUCKET_NAME="XXXX" S3_ODAN_PATH="odan/car"
画像を読み込んで表示する
-
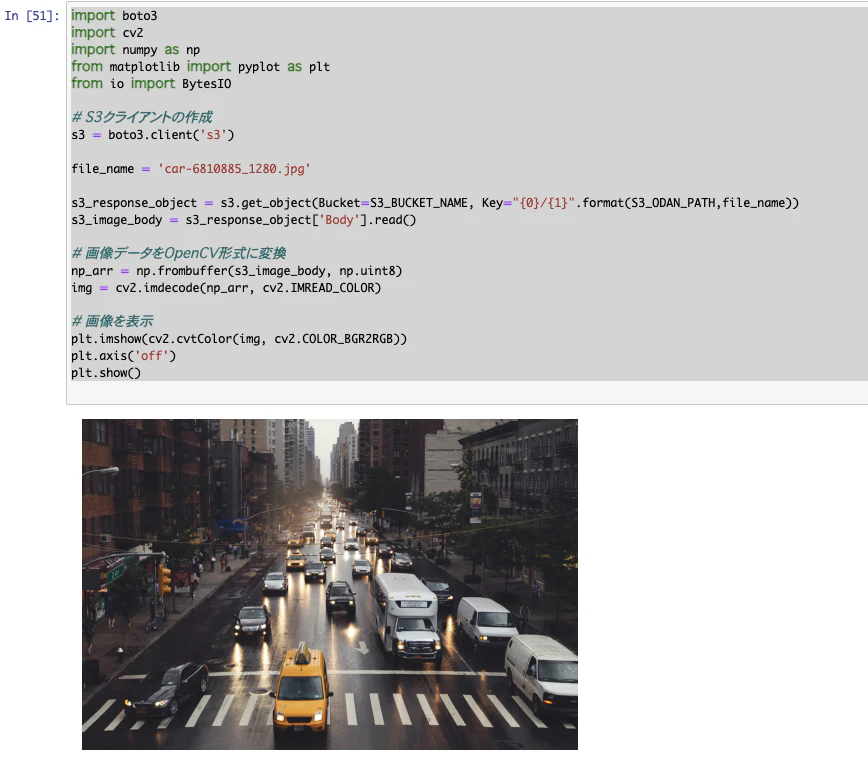
下記のコードを書いて実行します
import boto3 import cv2 import numpy as np from matplotlib import pyplot as plt from io import BytesIO # S3クライアントの作成 s3 = boto3.client('s3') file_name = 'car-6810885_1280.jpg' s3_response_object = s3.get_object(Bucket=S3_BUCKET_NAME, Key="{0}/{1}".format(S3_ODAN_PATH,file_name)) s3_image_body = s3_response_object['Body'].read() # 画像データをOpenCV形式に変換 np_arr = np.frombuffer(s3_image_body, np.uint8) img = cv2.imdecode(np_arr, cv2.IMREAD_COLOR) # 画像を表示 plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB)) plt.axis('off') plt.show()- s3_response_object['Body'].read():S3から画像を読み込む
- np.frombuffer:バッファを 1 次元配列として解釈する
- cv2.imdecode:メモリ内のバッファから画像を読み取る
- cv2.cvtColor:画像をあるカラースペースから別のカラースペースに変換する
- plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB)):データを画像として、つまり 2D の通常のラスターとして表示する
-
画像が表示されました
画像をグレースケール
- 下記のコードを書いて実行します
# グレースケールに変換 gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # グレースケール画像を表示 plt.imshow(gray_img, cmap='gray') plt.axis('off') plt.show()- gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
- plt.imshow(gray_img, cmap='gray')
- グレースケールに変換します
- グレースケールの画像が表示されます

エッジ検出 (Cannyアルゴリズム)
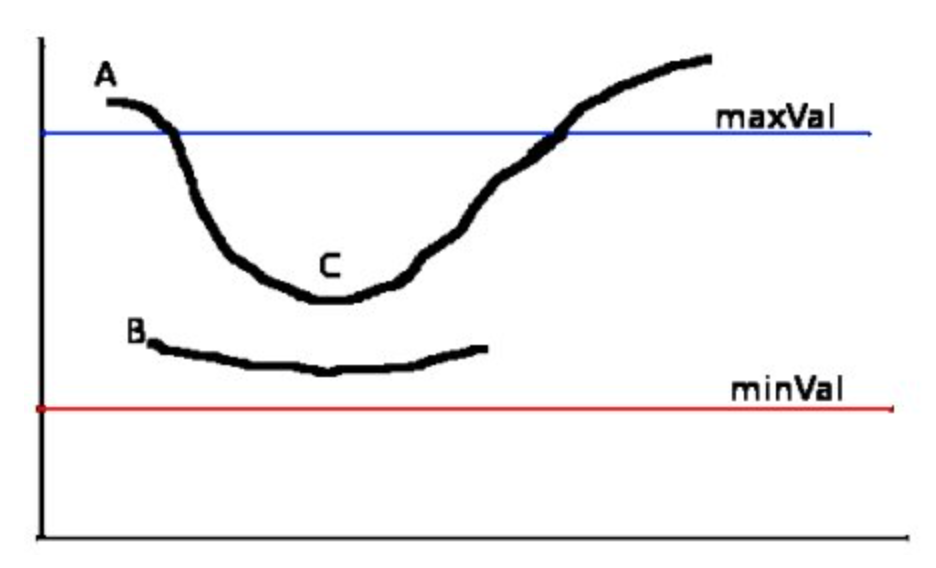
cv2.Canny(gray_img, 100, 200):画像に対して、minとmaxのしきい値を設定しています。
- 下記のコードを書いて実行します
# Cannyエッジ検出を適用 edges = cv2.Canny(gray_img, 100, 200) # エッジ画像を表示 plt.imshow(edges, cmap='gray') plt.axis('off') plt.show() - エッジ検出を行われた、画像の輪郭が抽出されました

画像のリサイズ
-
下記のコードを書いて実行します
# リサイズしたい新しいサイズ (例: 幅400px、高さ150px) new_width = 400 new_height = 150 # 画像をリサイズ resized_img = cv2.resize(img, (new_width, new_height)) # リサイズされた画像を表示 plt.imshow(cv2.cvtColor(resized_img, cv2.COLOR_BGR2RGB)) plt.axis('off') plt.show()- cv2.resize() 関数を使って、指定したサイズにリサイズできます
-
画像サイズが変更されました

画像にぼかしを適用
-
下記のコードを書いて実行します
# ぼかしのカーネルサイズ (例: 99x99のカーネル) kernel_size = (99, 99) # ガウシアンブラーを適用して画像をぼかす blurred_img = cv2.GaussianBlur(img, kernel_size, 0) # ぼかされた画像を表示 plt.imshow(cv2.cvtColor(blurred_img, cv2.COLOR_BGR2RGB)) plt.axis('off') plt.show()- cv2.GaussianBlur:画像にぼかしを適用しています。ガウシアンブラーではカーネルサイズを指定して、どれだけ画像をぼかすかを調整します
-
ブラーが適用されました

テンプレートマッチング
テンプレート マッチングは、大きな画像内でテンプレート画像の位置を検索して見つける方法です。
cv.matchTemplate()を使用して、テンプレート画像を入力画像の上にスライドさせ (2D 畳み込みのように)、テンプレートと入力画像のパッチをテンプレート画像の下側で比較します。
今回は、この画像をもとにマッチングします

-
切り抜いた画像をS3にアップロードします
-
下記のコードを書いて実行します
image_key = "{0}/{1}".format('odan/car','car-6810885_1280.jpg') template_key = "{0}/{1}".format('odan/car/template','template.png') # S3から画像を取得 def download_image_from_s3(bucket, key): s3_response_object = s3.get_object(Bucket=bucket, Key=key) s3_image_body = s3_response_object['Body'].read() np_arr = np.frombuffer(s3_image_body, np.uint8) img = cv2.imdecode(np_arr, cv2.IMREAD_GRAYSCALE) # グレースケールで読み込み return img # 元画像とテンプレート画像をS3から読み込む img = download_image_from_s3(S3_BUCKET_NAME, image_key) template = download_image_from_s3(S3_BUCKET_NAME, template_key) # テンプレートの幅と高さを取得 w, h = template.shape[::-1] # テンプレートマッチングを実行(TM_CCOEFF_NORMEDメソッドを使用) result = cv2.matchTemplate(img, template, cv2.TM_CCOEFF_NORMED) # 一致度が最も高い位置を取得 min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(result) # 一致した部分の左上の位置 top_left = max_loc bottom_right = (top_left[0] + w, top_left[1] + h) # 元の画像に一致部分の矩形を描画 cv2.rectangle(img, top_left, bottom_right, 255, 2) # 結果を表示 plt.imshow(img, cmap='gray') plt.title('Template Matching Result') plt.axis('off') plt.show() -
矩形で囲われました

考察
今回は、SageMaker NotebookでOpenCVを試してみました。今後もいろいろな機能を試してみます。
参考