背景・目的
今まで、Timestreamについて、触れたことがなく、知識がなかったので整理します。
また、簡単に試してみます。
まとめ
下記に特徴を整理します
| 特徴 | 説明 |
|---|---|
| 概要 | ・時系列データベース ・数兆件イベントを保存、分析できる ・キャパシティとパフォーマンスを調整するために、オートスケールする |
| ユースケース | ・IoTアプリケーション ・DevOpsアプリケーション ・分析アプリケーション |
| 時系列データとは | 時間経過とともに変化する事象を測定するために、タイムスタンプとともに記録されたシーケンスデータ |
| Timestreamの特徴 | ・サーバレス ・コスト最適化 ・スケーラブル ・時系列専用 ・セキュア |
| アーキテクチャ | ・Table ・Time-Series ・Record |
| Table | ・タイムシリーズを保持するコンテナ ・テーブル内は暗号化される ・テーブル作成時のスキーマ定義は不要 ・カラム定義やインデックス設定は自動で実施 ・ストレージ階層とデータ保持ポリシーに基づいたデータライフサイクル管理を自動で実施 |
| ストレージ階層の種類 | インメモリとマグネティックの2階層をサポート |
| Time-Series | ・ある属性値で説明できる時系列に並んだレコードのまとまり ・時系列データないの欠損値は、Time-Series化したデータを使って組み込みの補間関数で値を埋めることが可能 |
| Records | ・単一の時系列データポイント ・各レコードは、タイムスタンプ、1つ以上のディメンション、及び時間の経過とともに変化するメジャーで構成 |
| Dimensions | ・各テーブルで128個のディメンションが利用可能 ・すべてのディメンションは文字列として扱われる ・ディメンションはデータが取り込まれた時に、動的に追加 ・一度定義されたディメンションは変更不可 |
| Measure | ・測定値 ・各レコードはmeasure_nameとmeasure_valueで構成 ・各テーブルは1024のメジャーで種類を定義できる ・データ型は、boolean、bigint、double、varchar ・テーブルにデータを追加された時に、動的に追加される ・一度定義されたメジャーは変更不可 |
概要
Amazon Timestreamを元に整理します
Amazon Timestream は、高速かつスケーラブルなサーバーレス時系列データベースサービスです。1 日あたり数兆件規模のイベントを最大 1,000 倍の速度でより簡単に保存および分析できます。Amazon Timestream は、容量とパフォーマンスを調整するために自動的にスケールアップまたはスケールダウンするので、基盤インフラストラクチャの管理が不要です。
- 時系列データベース
- 数兆件イベントを保存、分析できる
- キャパシティとパフォーマンスを調整するために、オートスケールする
ユースケースは次の通り
- IoTアプリケーション
- 組み込みの分析関数を使用して、IoTアプリケーションにより生成された時系列データを迅速に分析する
- DevOpsアプリケーション
- 運用メトリクスを収集および分析して、正常性と使用状況をモニタリングしデータをリアルタイムに分析する
- パフォーマンスと可視性を改善する
- 分析アプリケーション
- 分析とインサイトのための追加の集約関数を使用し、アプリケーションの着信と発信Webトラフィックを保存、処理する
BlackBelt
20201216 AWS Black Belt Online Seminar Amazon Timestreamを元に整理します
時系列データとは
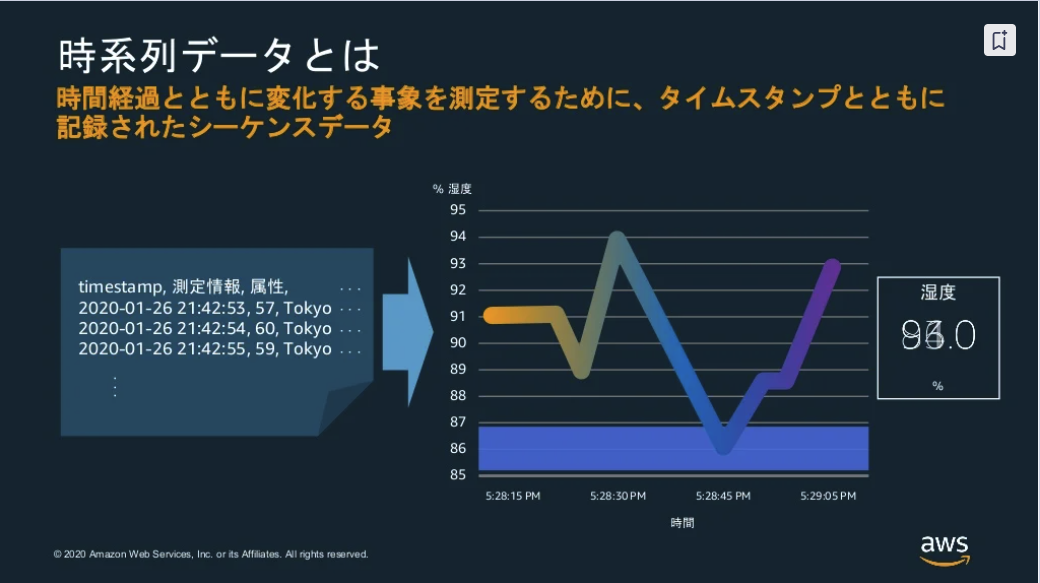
※出典:20201216 AWS Black Belt Online Seminar Amazon Timestream
- 時間経過とともに変化する事象を測定するために、タイムスタンプとともに記録されたシーケンスデータ
活用場所
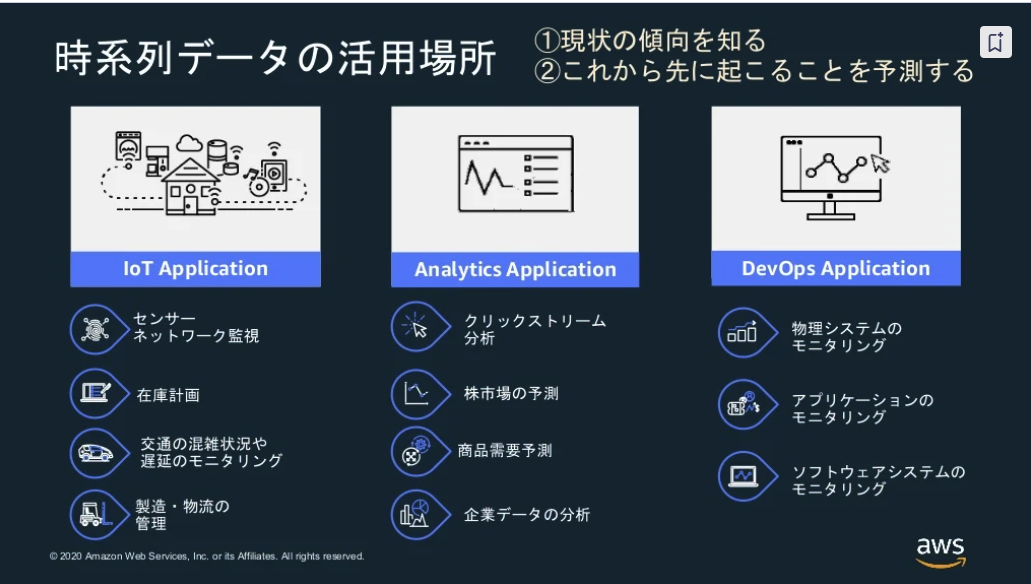
※出典:20201216 AWS Black Belt Online Seminar Amazon Timestream
| 分類 | ワークロード |
|---|---|
| IoT Application | センサーNW監視 |
| 在庫計画 | |
| 交通の混雑状況や遅延のモニタリング | |
| 製造・物流の管理 | |
| Analytics Application | クリックストリーム分析 |
| 株市場の予測 | |
| 商品需要予測 | |
| 企業データの分析 | |
| DevOps Application | 物理システムのモニタリング |
| アプリケーションのモニタリング | |
| ソフトウェアシステムのモニタリング |
時系列データを扱う上での課題

※出典:20201216 AWS Black Belt Online Seminar Amazon Timestream
- RDB
- 時系列データを効率良く扱うための設計が必要
- スキーマが固定され柔軟性に欠ける
- 時系列データ分析用の機能を必要に応じて独自で実装
- 既存の時系列データソリューション
- 大規模なデータに対してスケールすることが難しい
- データライフサイクル管理
- リアルタイムデータとヒストリカルデータの分離
Amazon Timestreamの特徴

※出典:20201216 AWS Black Belt Online Seminar Amazon Timestream
- サーバレスによるインフラ運用負荷軽減
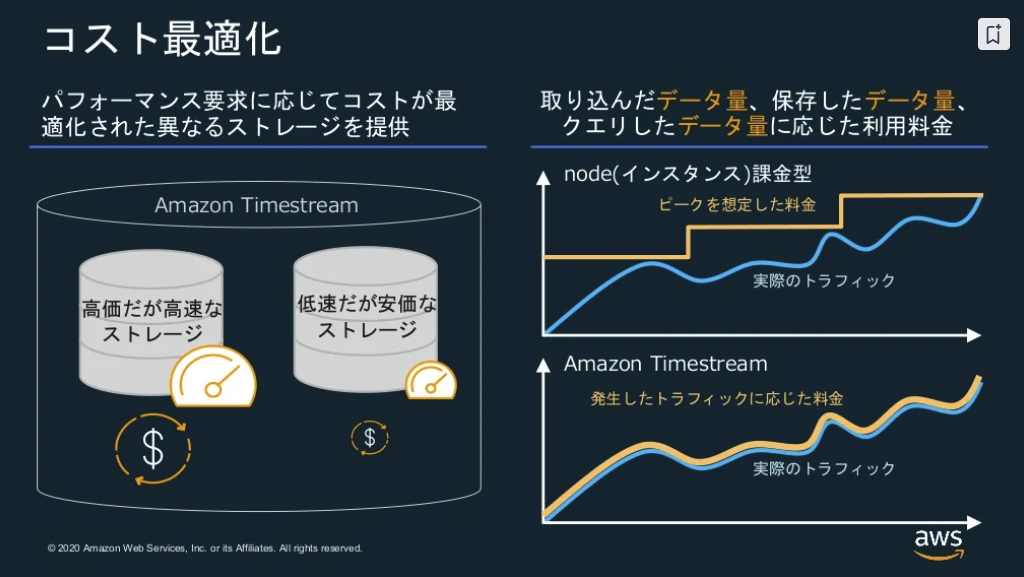
※出典:20201216 AWS Black Belt Online Seminar Amazon Timestream
- パフォーマンス要求に応じてコストが最適化された異なるストレージ
- 下記に応じた利用料金
- 取り込んだデータ量
- 保存したデータ量
- クエリしたデータ量
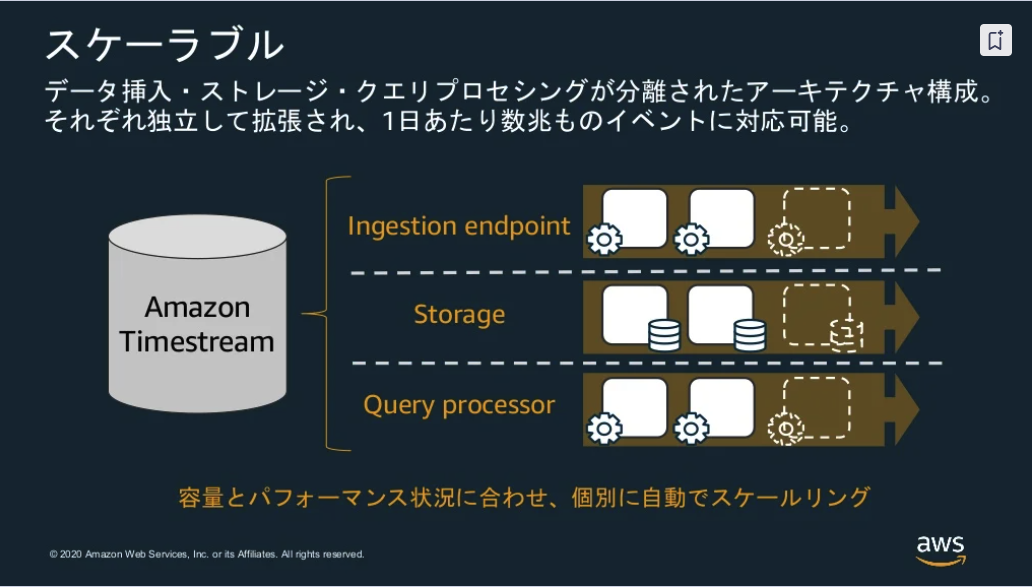
※出典:20201216 AWS Black Belt Online Seminar Amazon Timestream
- 下記で分離されている。独立して拡張される
- データIngestion
- ストレージ
- クエリプロセッシング
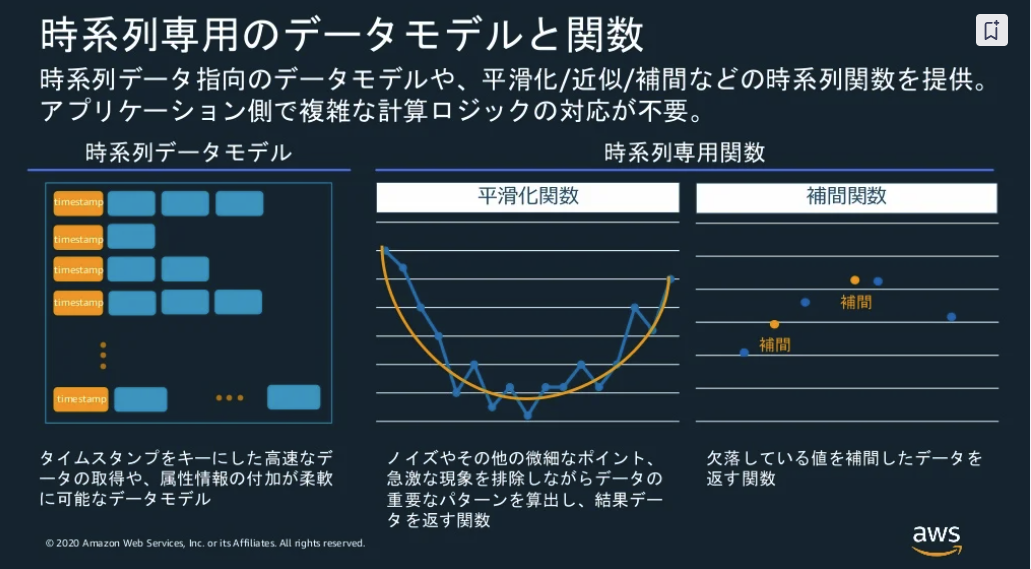
※出典:20201216 AWS Black Belt Online Seminar Amazon Timestream
- 時系列データ嗜好データモデル、平滑化/近似/補間などの時系列関数を提供
- アプリで複雑な計算ロジックの対応が不要

※出典:20201216 AWS Black Belt Online Seminar Amazon Timestream
- 通信時は、TLS
- 保管時は、KMSを利用して暗号化
- アクセス管理は、IAMユーザによる認証
アーキテクチャ
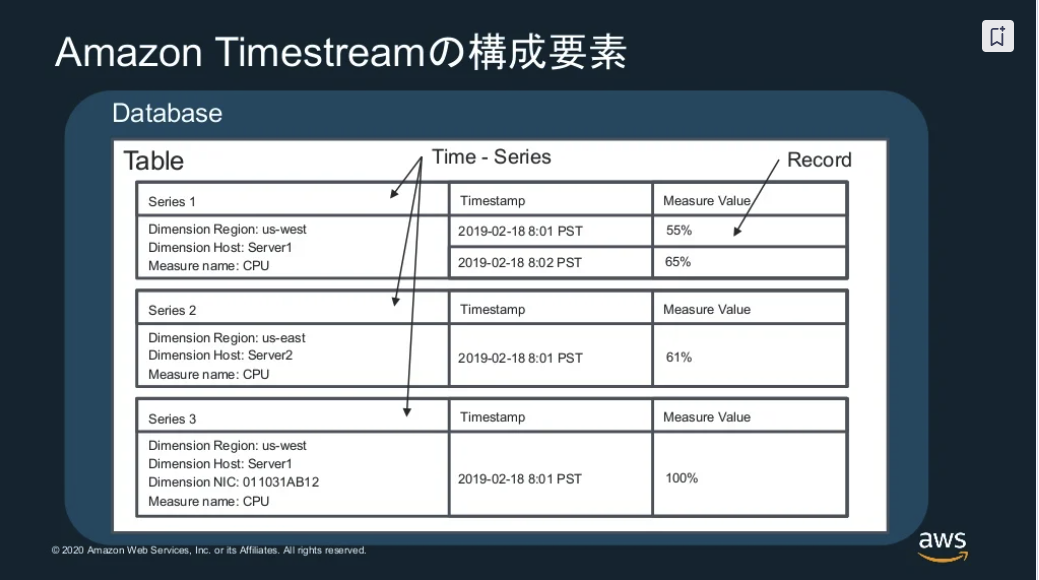
※出典:20201216 AWS Black Belt Online Seminar Amazon Timestream
下記の構成要素がある
- Table
- Time-Series
- Record
テーブル
- タイムシリーズを保持するコンテナ
- テーブル内は暗号化される
- テーブル作成時のスキーマ定義は不要
- カラム定義やインデックス設定は自動で実施
- ストレージ階層とデータ保持ポリシーに基づいたデータライフサイクル管理を自動で実施
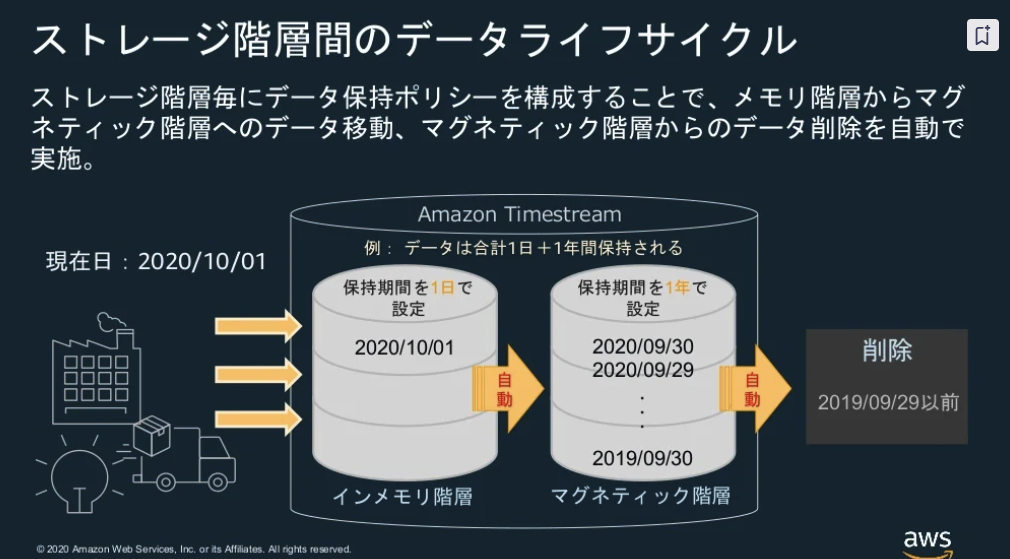
ストレージ階層の種類
インメモリと、マグネティックの2種類サポート
| 大分類 | 中分類 | インメモリ | マグネティック |
|---|---|---|---|
| 特徴 | 挿入 | すべてのデータを取り込み | すべてのデータはインメモリ階層から連携される |
| クエリ | 高速ポイントタイムクエリに合わせて最適化 | 分析クエリに合わせてパフォーマンス最適化される 長期間データの保存に対してコスト効率が高い |
|
| データライフサイクル管理 | 保持ポリシー | 1H〜最大1年 | 1日〜最大200年 |
| サイクル | 保持期間に達したデータをマグネティックに移動する | 保持期間に達したデータを削除 |
Time-Series

※出典:20201216 AWS Black Belt Online Seminar Amazon Timestream
- ある属性値で説明できる時系列に並んだレコードのまとまり
- 時系列データないの欠損値は、Time-Series化したデータを使って組み込みの補間関数で値を埋めることが可能
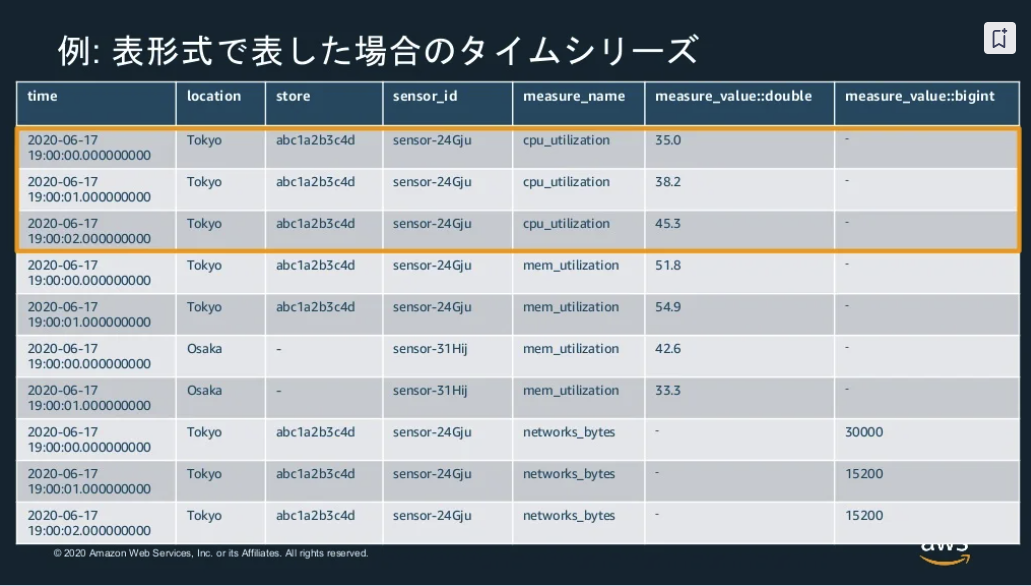
※出典:20201216 AWS Black Belt Online Seminar Amazon Timestream
Records

※出典:20201216 AWS Black Belt Online Seminar Amazon Timestream
- 単一の時系列データポイント
- 各レコードは、タイムスタンプ、1つ以上のディメンション、及び時間の経過とともに変化するメジャーで構成
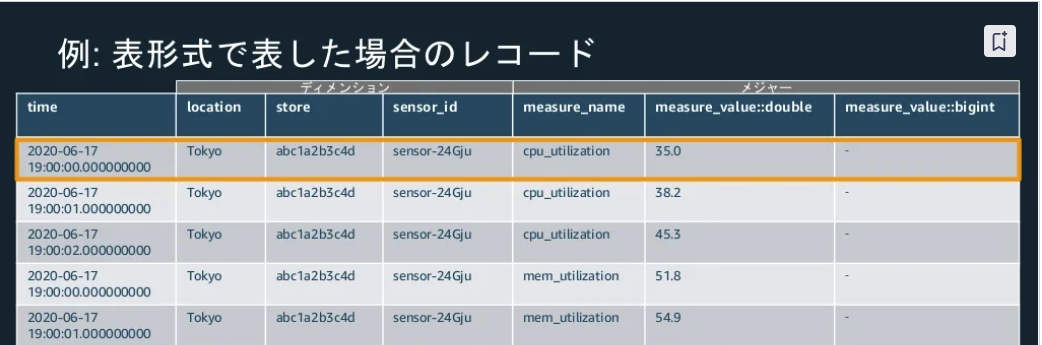
※出典:20201216 AWS Black Belt Online Seminar Amazon Timestream
Dimensions
- 各テーブルで128個のディメンションが利用可能
- すべてのディメンションは文字列として扱われる
- ディメンションはデータが取り込まれた時に、動的に追加
- 一度定義されたディメンションは変更不可
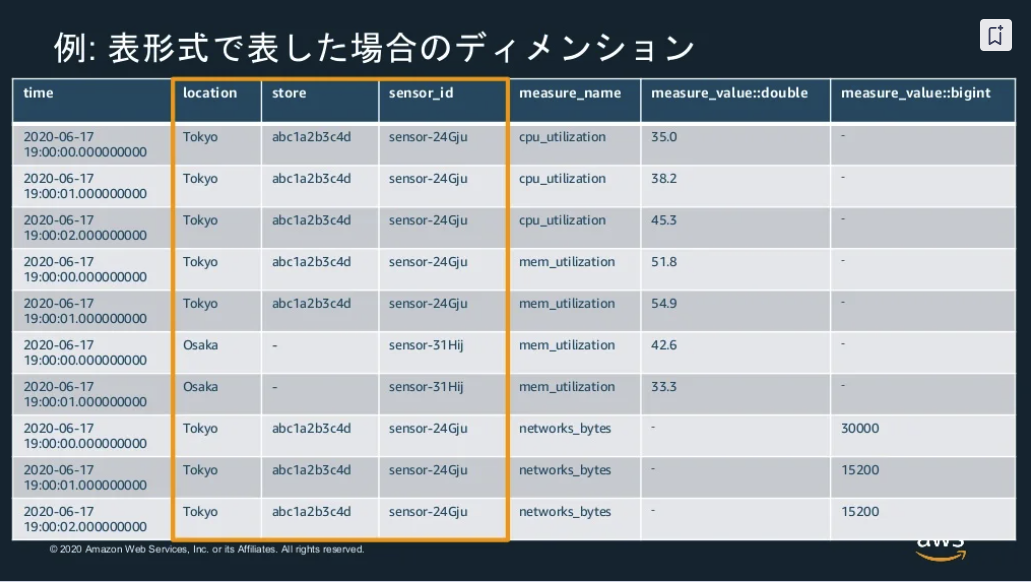
※出典:20201216 AWS Black Belt Online Seminar Amazon Timestream
Measures
- 測定値
- 各レコードはmeasure_nameとmeasure_valueで構成
- 各テーブルは1024のメジャーで種類を定義できる
- データ型は、boolean、bigint、double、varchar
- テーブルにデータを追加された時に、動的に追加される
- 一度定義されたメジャーは変更不可
Amazon Timestream for InfluxDBと Amazon Timestream for LiveAnalytics
2つのデータベースサービスがあり、どちらを使えばわかりませんでしたが、クラスメソッドさんがまとめてくださっていました。
クラスメソッドさんの、Amazon Timestream for InfluxDBを試した所感 (2024年3月時点)を元に整理しています。
- Amazon Timestream for InfluxDBはどちらかというとRDSやDocumentDBの仲間とのこと
| 項目 | LiveAnalytics | InfluxDB |
|---|---|---|
| DB | AWS 独自 | OSS版InfluxDB |
| NW | 非VPC | 要VPC |
| データアクセス | AWSのAPI | InfluxDBのAPI |
| スケーラビリティ | スケーラブル | 限定的 |
※出典:クラスメソッド Amazon Timestream for InfluxDBを試した所感 (2024年3月時点)
料金
Amazon Timestream の料金を元に整理します。
- 最新の料金はマニュアルをご確認ください
- 2024/3/31時点の東京リージョンの料金です
- Amazon Timestream for LiveAnalyticsの料金を試算しています
- 書き込み
- 1Kサイズの書き込みが100万件で、0.625USD
- バッチロードの書き込みについては、S3のGETについても課金される
- クエリ
- 1GBあたり 0.0125USD
- クエリごと最小10MBになるようだ
- メモリストア
- GB/時間あたり、0.045USD
- マグネティックストア
- GB/月あたり 0.0375USD
実践
チュートリアルを元に試してみます。
データベースの作成
-
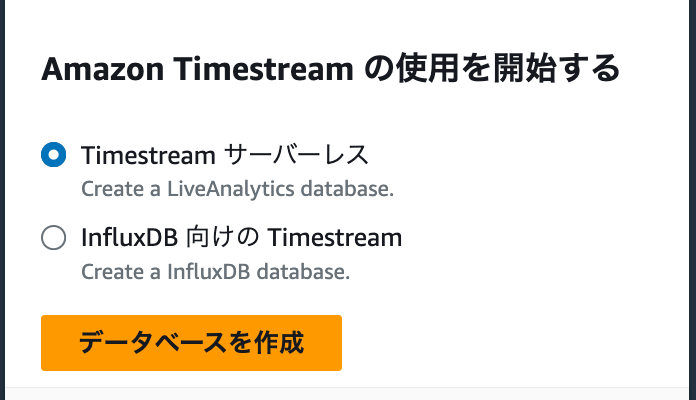
AWSにサインインし、Timestreamのトップページに遷移します
-
Timestreamサーバレスを選択し、「データベースを作成」をクリックします
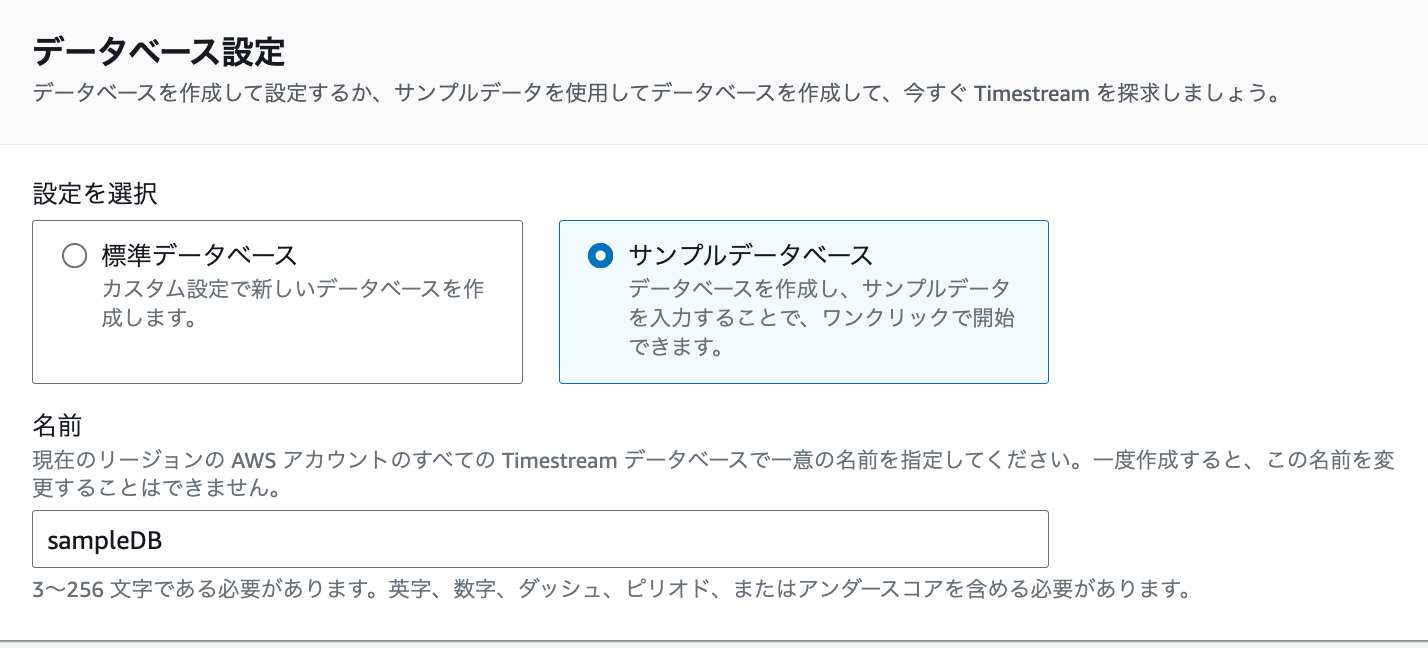
-
データベース設定で「サンプルデータベース」を選択します
-
サンプルデータを含むテーブルでは、下記を選択し、「データベースを作成」をクリックします
- サンプルデータセット:「IoT」と「DevOps」
- 時系列レコードタイプ:マルチメジャーレコード

-
できました

クエリを実行する
スキーマを確認する
-
スキーマを表示をクリックします
-
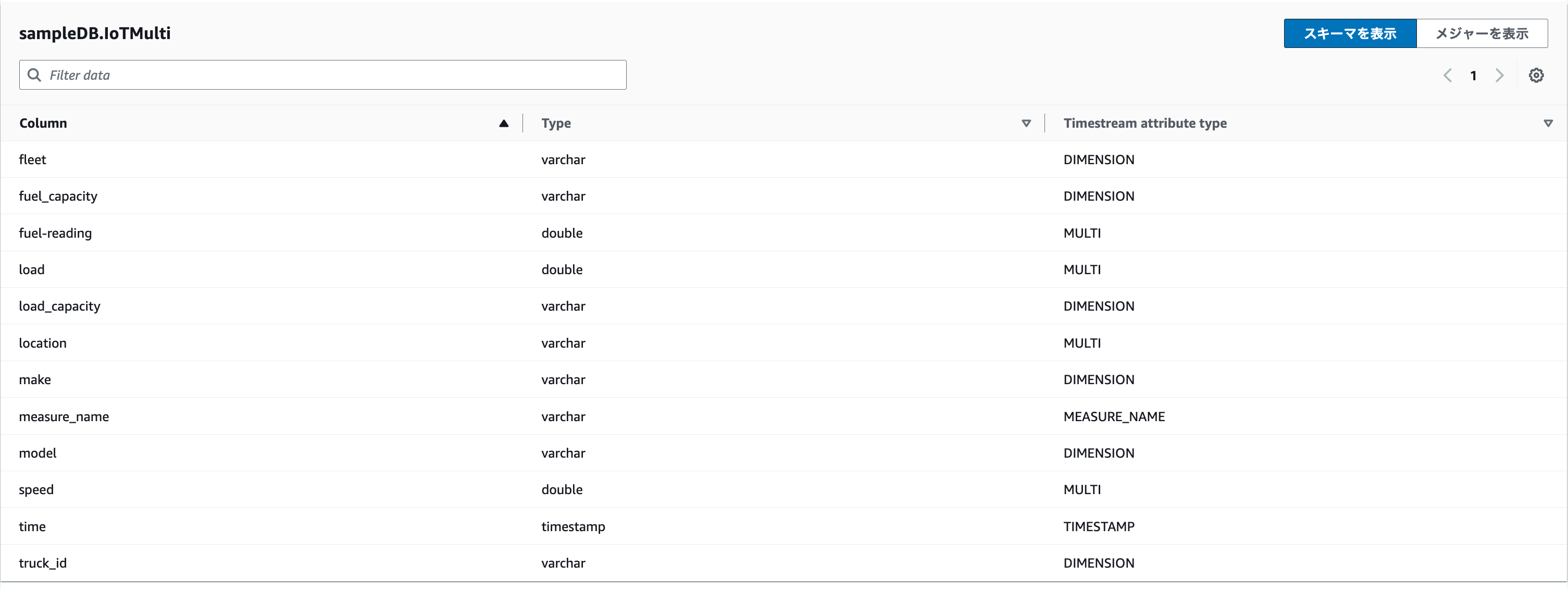
表示されました
- attribute typeには下記の4つがありました
- TIMESTAMP
- MULTI
- DIMENSION
- MEASURE_NAME
- attribute typeには下記の4つがありました
データを確認する
-
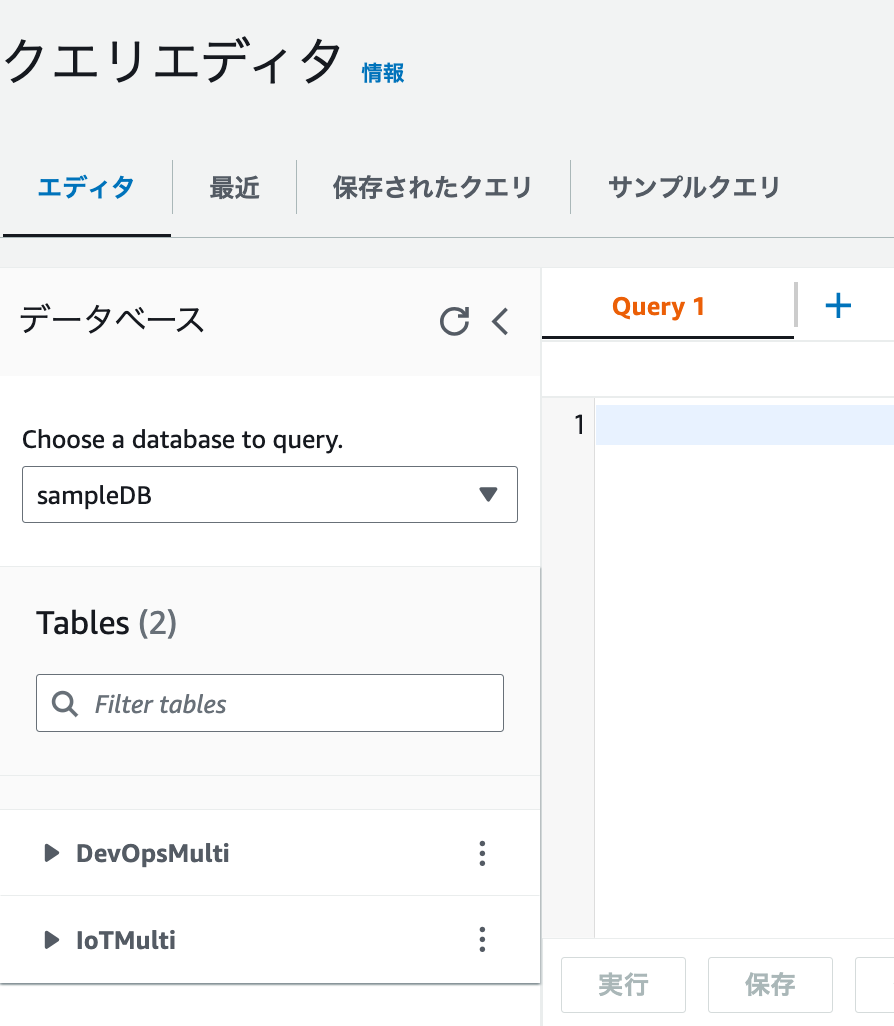
ナビゲーションペインで「クエリエディタ」をクリックします
-
2つのテーブルが、存在することがわかります
-
データをプレビューをクリックし、実行します
-
下記のクエリが実行されます
- 15分前〜直近までのレコードが確認できたようです
-- Get the 10 most recently added data points in the past 15 minutes. You can change the time period if you're not continuously ingesting data SELECT * FROM "sampleDB"."IoTMulti" WHERE time between ago(15m) and now() ORDER BY time DESC LIMIT 10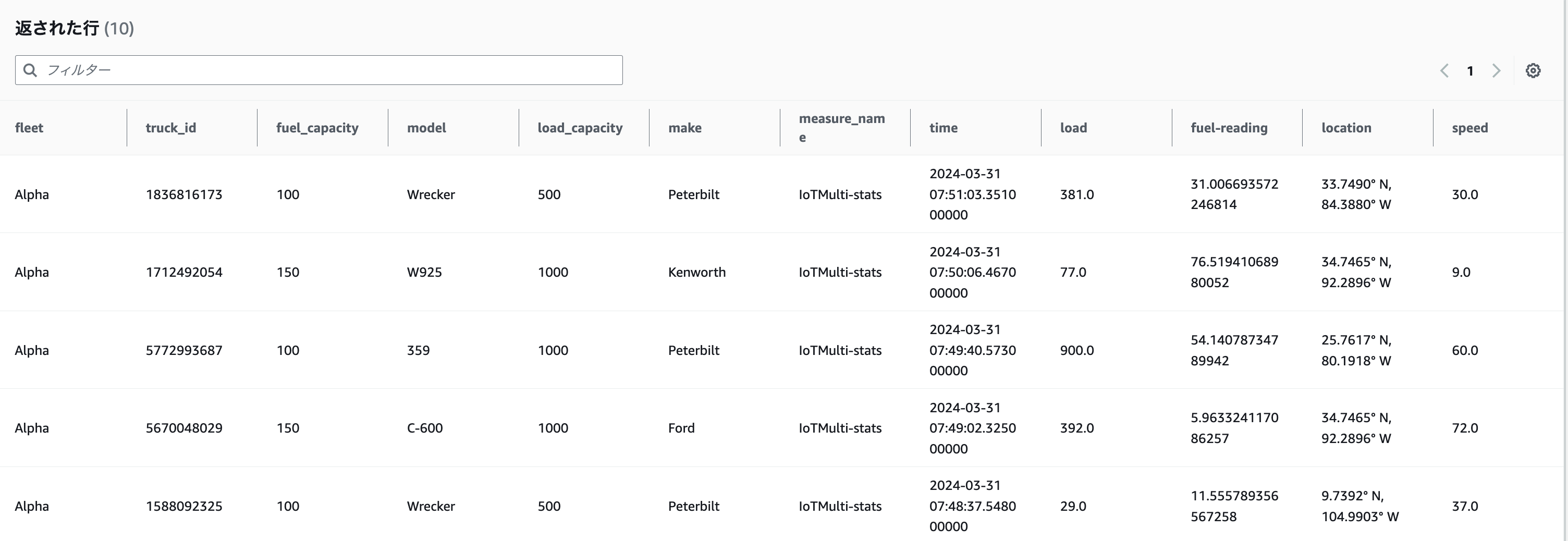
Measure nameを確認
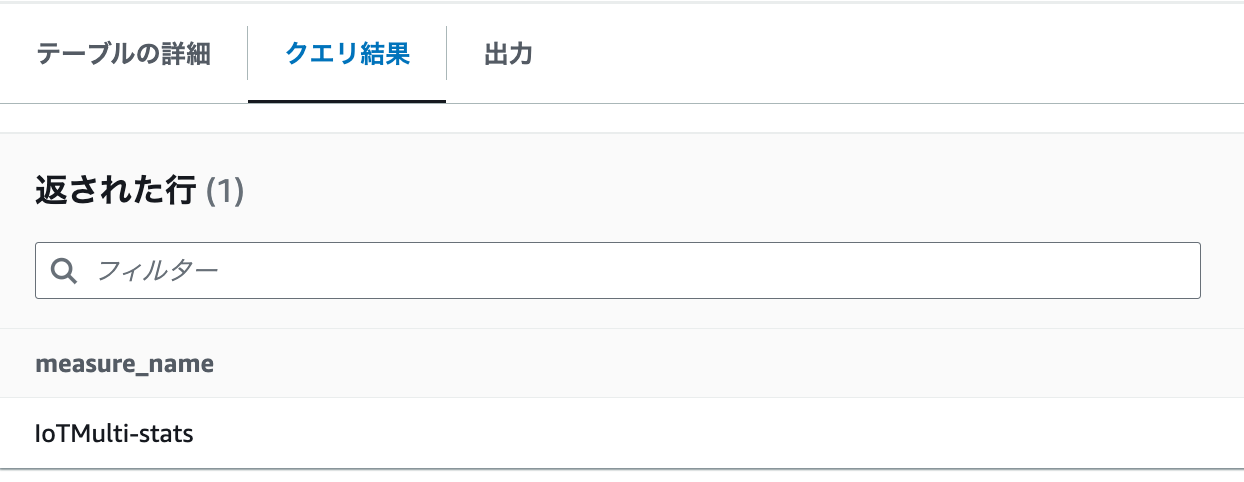
- 下記のクエリを確認します。1レコードしか入っていませんでした。
SELECT distinct measure_name from "sampleDB"."IoTMulti"
COUNT
- 下記のクエリを実行します
SELECT COUNT(1) from "sampleDB"."IoTMulti"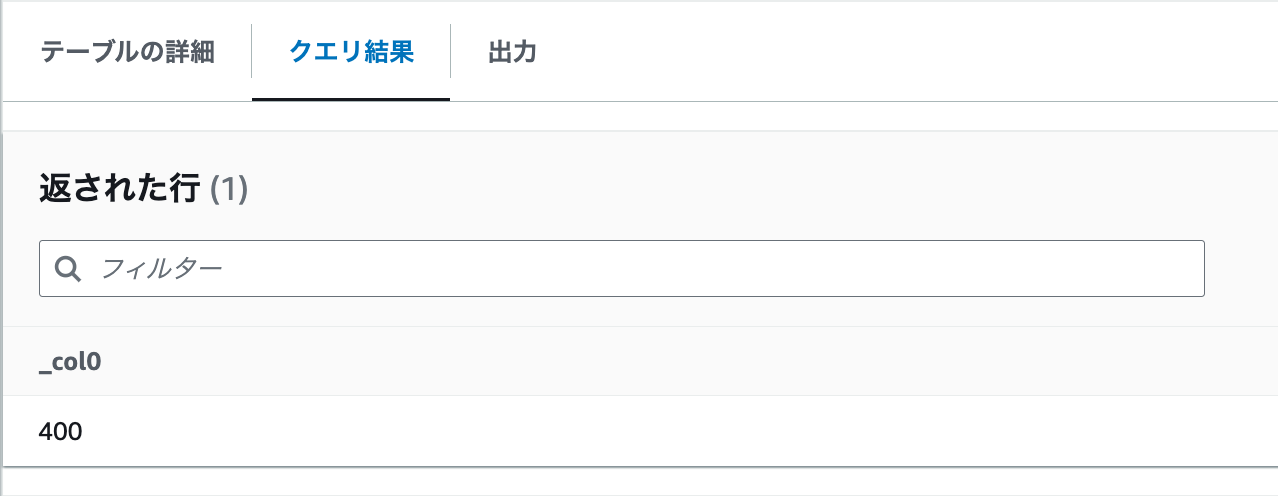
MAX
- 下記のクエリを実行します
SELECT MAX(fuel_capacity) from "sampleDB"."IoTMulti"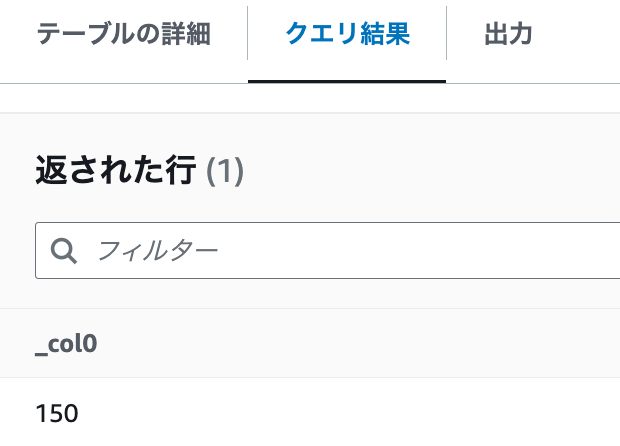
あと始末
-
データベースを選択し「削除」をクリックします

-
一度テーブルをきれいにしないといけないようです。
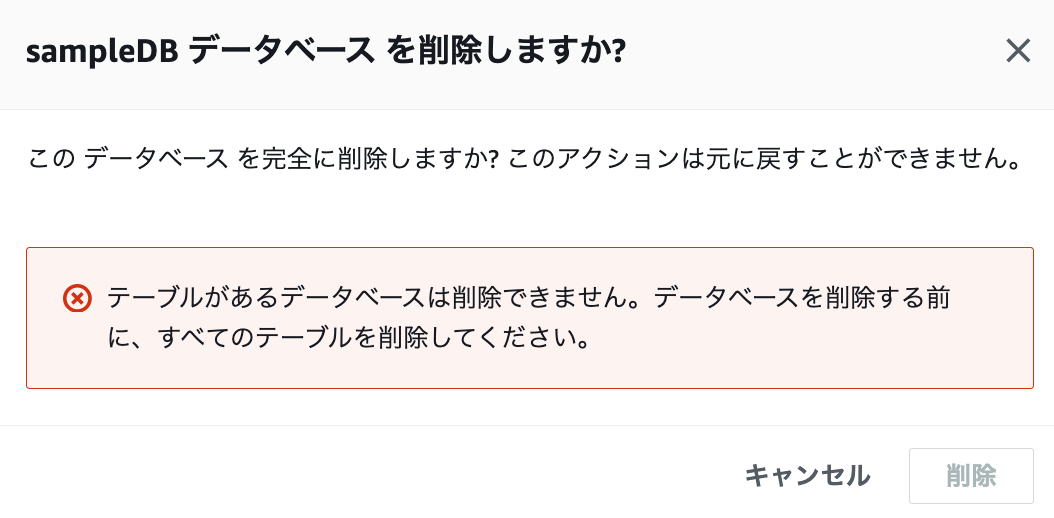
-
テーブルをクリックします
-
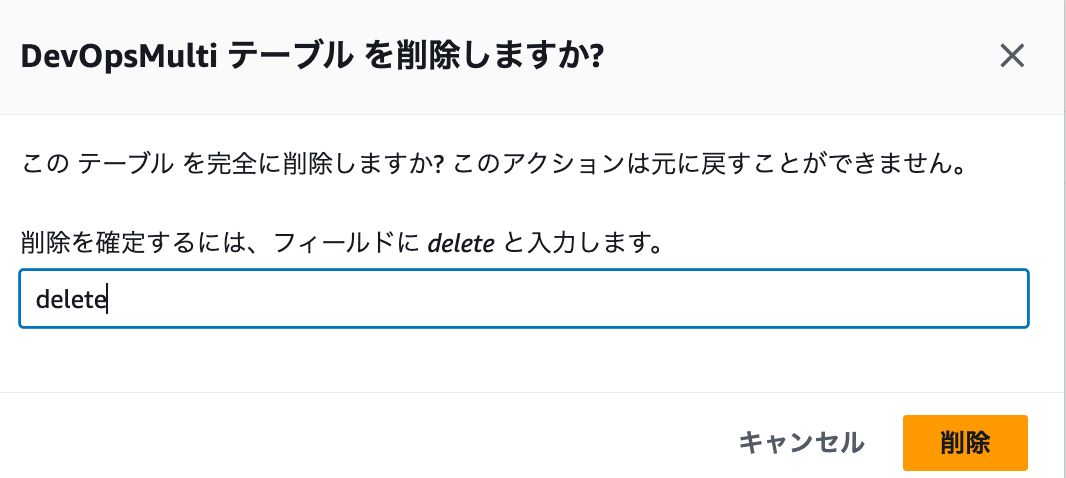
該当するテーブルを選択し、「削除」をクリックします

-
ポップアップが上がるので「delete」を入力し削除します
-
データベースをクリックします
-
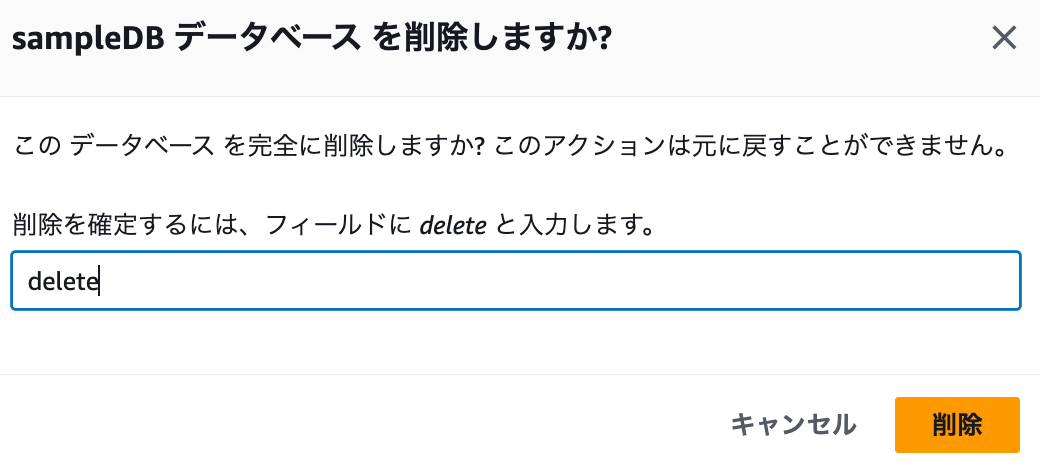
データベースを選択し、削除します
-
ポップアップが上がるので「delete」を入力し「削除」します
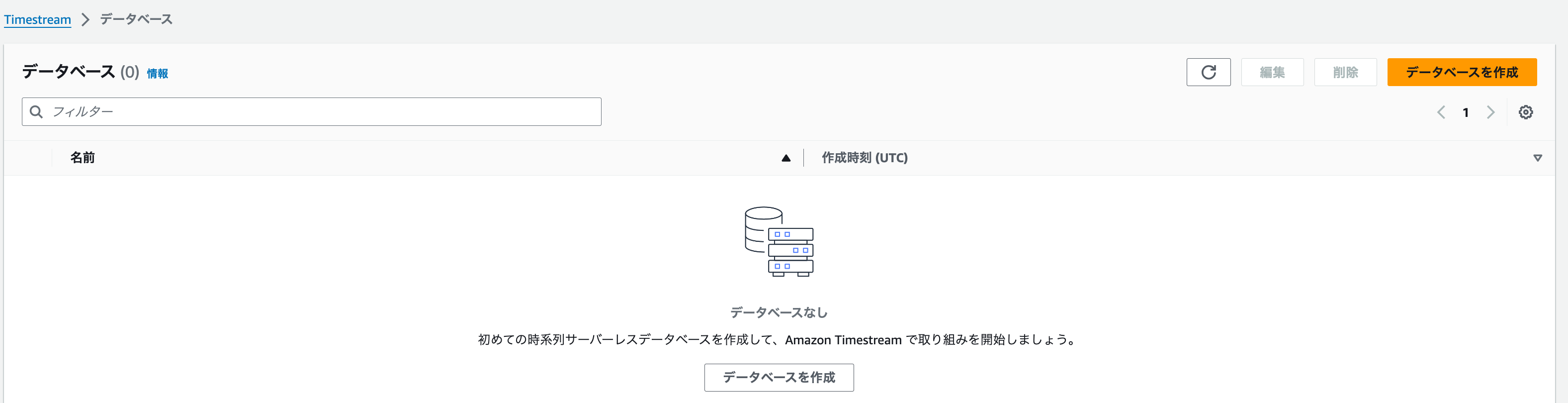
-
きれいになりました
考察
はじめて、Timestreamを触りました。時系列DB特有の考えがあり、新鮮でした。
属性タイプごとの意味が最初は、つかめませんでしたが、下記のように理解しました。(MEASURE_NAMEだけよくわからない)
- TIMESTAMP: レコードが記録された日時
- DIMENSION: レコードの切り口というかメタ情報のようなもの
- MEASURE: 計測した値
- MEASURE_NAME: どうやら顧客でパーティションキーを指定しない場合、measure_nmame列に基づくデフォルトパーティションを使用するようです
また、SQLもある程度使えそうなので、取り扱いには困らなそうです。
まだまだ、初歩の初歩なので、もっと理解すべく今後も利用していきたいと思います。
参考