背景・目的
以前、こちらの記事でAthenaのパーティションインデックスの効果を検証した際に、パーティションをMSCK REPAIR TABLEで作成しました。
MSCK REPAIR TABLEの場合には、6時間9分46秒もの時間を要したので、Glue Crawlerで作った場合にはどれくらいの時間がかかるか検証したいと思います。
まとめ
- 9万弱のパーティションを作成するのに、MSCK REPAIR TABLEとGlueのCrawlerでおおよそ、5時間44分46秒(93.23%の削減率)もの差がありました。
- Glue Crawlerが圧倒的に速かったです。
- Glue Crawlerがどのようなアルゴリズムで実行されているのかは不明だが、プロダクション等で利用する場合はCrawlerを選択したほうが良いと思います。
実践
事前準備
- 前回同様の条件で実施するため、事前に確認します。
S3パスの確認
- 前回と同様に89,279件のS3パス(ファイル)があります。
$ aws s3 ls {バケット名} --recursive | grep json | wc -l
89279
$
テーブルの確認
- パーティションはyear,month,day,hourになります。
CREATE EXTERNAL TABLE `test`(
`key` string COMMENT 'from deserializer',
`value` bigint COMMENT 'from deserializer')
PARTITIONED BY (
`year` int,
`month` int,
`day` int,
`hour` int)
ROW FORMAT SERDE
'org.openx.data.jsonserde.JsonSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
's3://{バケット名}/'
TBLPROPERTIES (
'partition_filtering.enabled'='true',
'transient_lastDdlTime'='1650438649')
Crawlerの作成
1.Glueのマネコン画面で「Crawlerの追加」をクリックします。

2.Crawler名を入力します。

3.Source Typeを選択します。
- テーブルは既にあるので、Existing Catalog tablesを選択します。

4.テーブルを選択します。

5.IAMロールを作成します。

6.スケジューラータイプを「オンデマンド」で作成します。
7.出力を設定します。
- S3パス毎に単一のスキーマを作成するをチェックします。

- 以下のオプションを設定します。

8.最後に、確認画面で完了をクリックします。
実行と確認
1.クローラを実行します。

2.クローラーのステータスが「Starting」に変わります。

3.クローラーのステータスが「Ready」に変われば終了です。
- なんと、時間は25分でした。

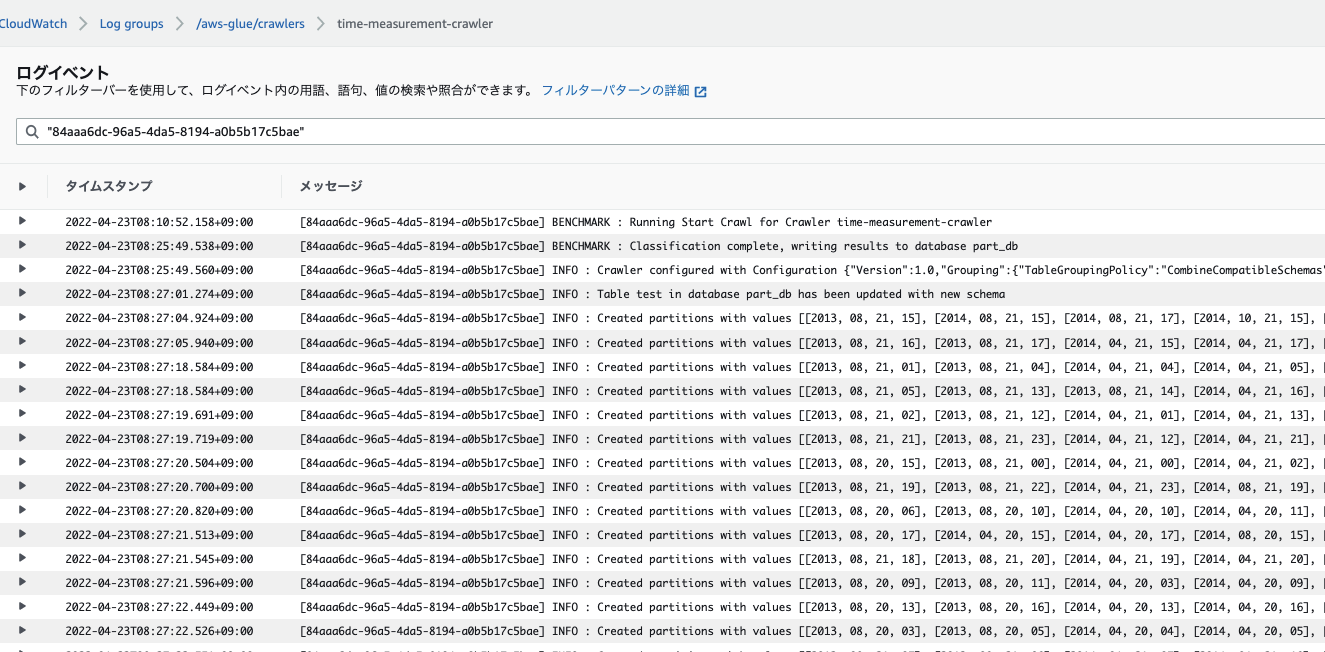
4.CloudWatch Logsを確認するとパーティションは作られていることは分かりました。
- 全部は載せられないので、一部だけ抜粋しています。
5.パーティションの値と、件数を確認します。
- 前回計測した際の件数と、一致していましたので作成は問題ありません。
$ aws glue get-partitions --database-name part_db --table-name test --max-items 3 | jq -r '.Partitions[].Values| @csv ' | tr -d "\""
2013,01,06,17
2013,01,07,03
2013,01,21,21
$ aws glue get-partitions --database-name part_db --table-name test | jq -r '.Partitions[].Values| @csv ' | tr -d "\"" | wc -l
89279
$
考察
結果
- 前回、MSCK REPAIR TABLEでパーティションを作成した際の時間の、6時間9分46秒に対して、Crawlerで作成した時間は25分でした。
- おおよそ、5時間44分46秒(93.23%の削減率)もの差がありました。
なぜ、同じ様にパーティションを作成するのに実行時間に違いがあるのか?
- なぜ、このように大きな実行時間に差があるのかは、こちらに書かれていました。
このエラーは、MSCK REPAIR TABLE コマンドの実行時に、Amazon Athena が Amazon Simple Storage Service (Amazon S3) 内のプレフィックスとオブジェクトを再帰的にリストすることから発生します。Amazon S3 のプレフィックスまたはオブジェクトが多すぎると、コマンドの完了に時間がかかる、またはタイムアウトする場合があります。
- S3のプレフィックスとオブジェクトを再帰的に読むため時間がかかる。またはタイムアウトが発生する。とのこと。
GlueのCrawlerはどの様に動作しているか?
- 上記のMSCK PEPAIR TABLEの解決策として、以下が示されていましたが、どの様に動作しているのでしょうか。
AWS Glue クローラーを使用して、Athena テーブルにパーティションを追加します。詳細については、クローラーの動作を参照してください。AWS Glue クローラーを使用することにより、Amazon S3 のプレフィックスが多い場合でも、パーティションのロードにかかる時間を短縮できます。詳細については、 AWS Glue の増分クロール を参照してください。
Amazon Simple Storage Service (Amazon S3) データソースに対して、増分クロールでは、前回のクローラ実行以降に追加されたフォルダのみをクロールします。このオプションを使用しない場合、クローラはデータセット全体をクロールします。増分クロールにより、時間とコストが大幅に節約できます。増分クロールを実行するには、AWS Glue コンソール で [Crawl new folders only] (新しいフォルダのみをクロールする) オプションを設定するか、API で CreateCrawler リクエストの RecrawlPolicy プロパティを設定します。
- ドキュメントを読むと、増分クロールを使用するから速いと書かれていましたが、今回は新規に作成するのでこれではなさそうです。
結論
- Glue Crawlerの速さの秘密は不明だが、S3のプレフィックスとオブジェクトを再帰的に読む仕組みとは違うというのは分かった。
参考