背景・目的
こちらの、AWS Glue ETL パフォーマンス・チューニング② チューニングパターン編を読んだ際に、読み取りデータ量を削減する機能の紹介として下記が紹介されてました。
- Partition Filtering
- Filter Pushdown
今回は、こちらを実際に試してみました。
まとめ
- Partition Filteringは、パーティション列を対象としており、パーティション配下のファイルを読み込む機能
- Filter Pushdownは、パーティション列に指定されていない列を対象としており、該当するブロックのみ絞り込む機能
概要
AWS Glue ETL パフォーマンス・チューニング② チューニングパターン編には、下記の説明があります。
Partition Filtering
- filter句やWhere句で指定されたパーティション内のファイルのみを読み取る機能
- Text/CSV/JSON/ORC/Parquetで利用可能
Filter Pushdown
- パーティション列に利用されていない列に対するfilter句やwhere句にヒットするブロックのみを読み取る機能
- AWS GlueではParquetを利用した場合に自動的に適用される
実践
事前準備
データ準備
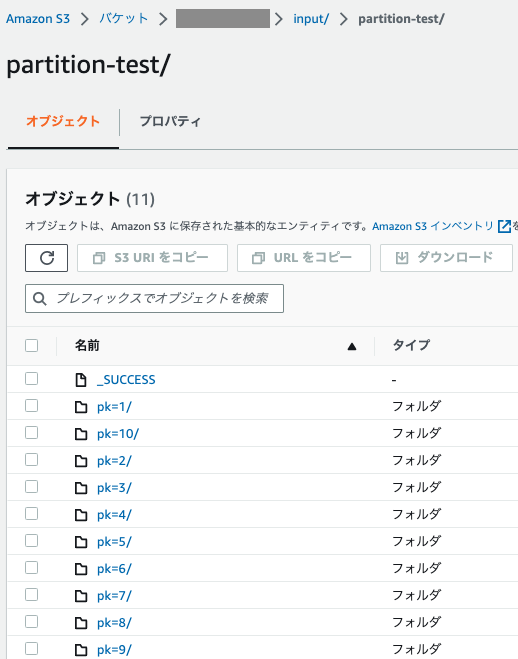
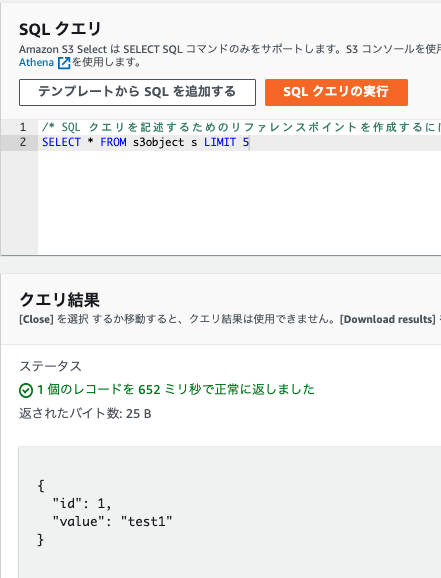
データをパーティションありと、パーティションなしで2つ準備します。
パーティションあり
パーティションなし
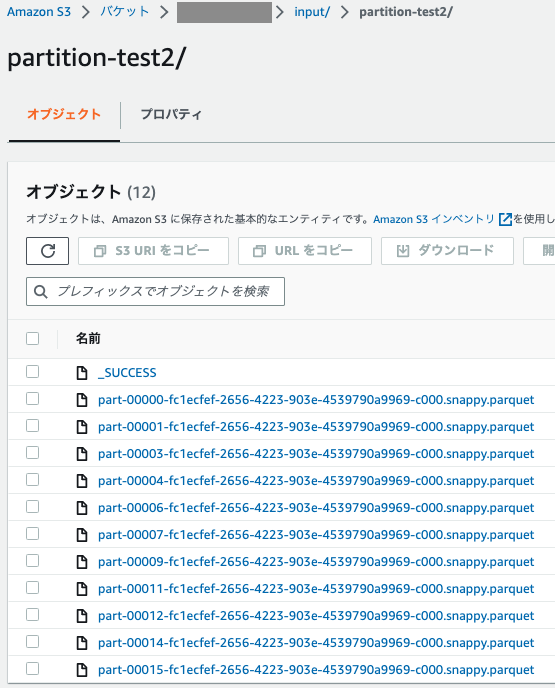
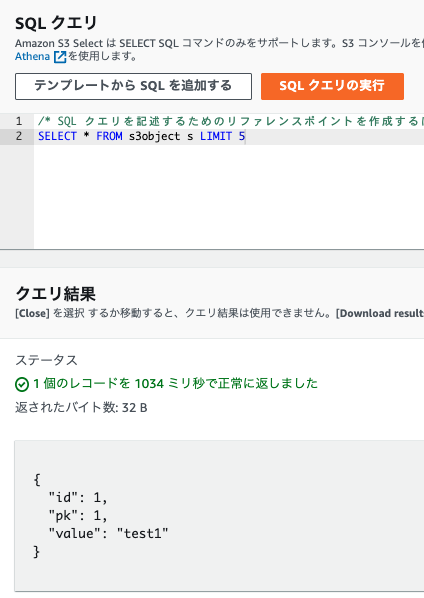
Partition Filteringを確認
フィルタなしで、パーティションありのデータを読み込む
-
フィルタなしでデータと実行計画を確認します。
from pyspark.sql import SparkSession,types as T,functions as F spark = SparkSession \ .builder \ .appName("Python example") \ .getOrCreate() df = spark.read.parquet("s3://xxxx/input/partition-test/") df.show() df.explain() -
結果を確認します。
- 結果は当然絞られません。
- PartitionFilters:[]のままです。
+---+------+---+ | id| value| pk| +---+------+---+ | 10|test10| 10| | 6| test6| 6| | 1| test1| 1| | 3| test3| 3| | 4| test4| 4| | 8| test8| 8| | 2| test2| 2| | 7| test7| 7| | 9| test9| 9| | 5| test5| 5| +---+------+---+ == Physical Plan == *(1) ColumnarToRow +- FileScan parquet [id#85L,value#86,pk#87] Batched: true, DataFilters: [], Format: Parquet, Location: InMemoryFileIndex(1 paths)[s3://XXXX/input/partition-test], PartitionFilters: [], PushedFilters: [], ReadSchema: struct<id:bigint,value:string>
フィルタありで、パーティションありのデータを読み込む
- フィルタありでデータと実行計画を確認します。
from pyspark.sql import SparkSession,types as T,functions as F spark = SparkSession \ .builder \ .appName("Python example") \ .getOrCreate() df = spark.read.parquet("s3://XXXX/input/partition-test/").filter(F.col('pk')==1) df.show() df.explain() - 結果を確認します。
- 結果が絞られています。
- PartitionFilters: [isnotnull(pk#119), (pk#119 = 1)]になっています。
+---+-----+---+ | id|value| pk| +---+-----+---+ | 1|test1| 1| +---+-----+---+ == Physical Plan == *(1) ColumnarToRow +- FileScan parquet [id#117L,value#118,pk#119] Batched: true, DataFilters: [], Format: Parquet, Location: InMemoryFileIndex(1 paths)[s3://XXXX/input/partition-test], PartitionFilters: [isnotnull(pk#119), (pk#119 = 1)], PushedFilters: [], ReadSchema: struct<id:bigint,value:string>
フィルタありで、パーティションありのデータを読み込む。(パーティションキーではない条件)
-
フィルタありでデータと実行計画を確認します。
from pyspark.sql import SparkSession,types as T,functions as F spark = SparkSession \ .builder \ .appName("Python example") \ .getOrCreate() df = spark.read.parquet("s3://XXXX/input/partition-test/").filter(F.col('id')==1) df.show() df.explain() -
結果を確認します。
- 結果が絞られています。
- PartitionFilters:[]のままです。
+---+-----+---+ | id|value| pk| +---+-----+---+ | 1|test1| 1| +---+-----+---+ == Physical Plan == *(1) Filter (isnotnull(id#137L) AND (id#137L = 1)) +- *(1) ColumnarToRow +- FileScan parquet [id#137L,value#138,pk#139] Batched: true, DataFilters: [isnotnull(id#137L), (id#137L = 1)], Format: Parquet, Location: InMemoryFileIndex(1 paths)[s3://XXXX/input/partition-test], PartitionFilters: [], PushedFilters: [IsNotNull(id), EqualTo(id,1)], ReadSchema: struct<id:bigint,value:string>
フィルタなしで、パーティションなしのデータを読み込む
- フィルタなしでデータと実行計画を確認します。
from pyspark.sql import SparkSession,types as T,functions as F spark = SparkSession \ .builder \ .appName("Python example") \ .getOrCreate() df = spark.read.parquet("s3://XXXX/input/partition-test2/") df.show() df.explain() - 結果を確認します。
- 結果は当然絞られません。
- PartitionFilters:[]のままです。
+---+---+------+ | id| pk| value| +---+---+------+ | 10| 10|test10| | 1| 1| test1| | 2| 2| test2| | 3| 3| test3| | 4| 4| test4| | 5| 5| test5| | 6| 6| test6| | 7| 7| test7| | 8| 8| test8| | 9| 9| test9| +---+---+------+ == Physical Plan == *(1) ColumnarToRow +- FileScan parquet [id#157L,pk#158L,value#159] Batched: true, DataFilters: [], Format: Parquet, Location: InMemoryFileIndex(1 paths)[s3://XXXX/input/partition-test2], PartitionFilters: [], PushedFilters: [], ReadSchema: struct<id:bigint,pk:bigint,value:string>
フィルタありで、パーティションなしのデータを読み込む
- フィルタありでデータと実行計画を確認します。
from pyspark.sql import SparkSession,types as T,functions as F spark = SparkSession \ .builder \ .appName("Python example") \ .getOrCreate() df = spark.read.parquet("s3://XXXX/input/partition-test2/").filter(F.col('pk')==1) df.show() df.explain() - 結果を確認します。
- 結果は絞られています。
- PartitionFilters:[]のままです。
+---+---+-----+ | id| pk|value| +---+---+-----+ | 1| 1|test1| +---+---+-----+ == Physical Plan == *(1) Filter (isnotnull(pk#178L) AND (pk#178L = 1)) +- *(1) ColumnarToRow +- FileScan parquet [id#177L,pk#178L,value#179] Batched: true, DataFilters: [isnotnull(pk#178L), (pk#178L = 1)], Format: Parquet, Location: InMemoryFileIndex(1 paths)[s3://XXXX/input/partition-test2], PartitionFilters: [], PushedFilters: [IsNotNull(pk), EqualTo(pk,1)], ReadSchema: struct<id:bigint,pk:bigint,value:string>
Filter Pushdownを確認
フィルタありでデータと実行計画を確認します。
- パーティションキーではない列でfilterをします。
from pyspark.sql import SparkSession,types as T,functions as F spark = SparkSession \ .builder \ .appName("Python example") \ .getOrCreate() df = spark.read.parquet("s3://XXXX/input/partition-test2/").filter(F.col('id')==1) df.show() df.explain() - 結果を確認します。
- 結果は絞られています。
- PushedFilters: [IsNotNull(id), EqualTo(id,1)]になっています。
+---+---+-----+ | id| pk|value| +---+---+-----+ | 1| 1|test1| +---+---+-----+ == Physical Plan == *(1) Filter (isnotnull(id#217L) AND (id#217L = 1)) +- *(1) ColumnarToRow +- FileScan parquet [id#217L,pk#218L,value#219] Batched: true, DataFilters: [isnotnull(id#217L), (id#217L = 1)], Format: Parquet, Location: InMemoryFileIndex(1 paths)[s3://XXXX/input/partition-test2], PartitionFilters: [], PushedFilters: [IsNotNull(id), EqualTo(id,1)], ReadSchema: struct<id:bigint,pk:bigint,value:string>
考察
今回、Partition FilteringとFilter Pushdownを試してみました。実行計画で変わっていることが確認できました。
参考