背景・目的
GlueからDynamoDBへの接続を試してみます。
まとめ
- GlueからDynamoDBへの接続には、ConnectionTypeをdynamodbに指定する事で利用できる。
- DynamoDBからの読み込みには、ETLコネクターとExportコネクターの2つが用意されている。
- ExportコネクターはDynamoDBのPITRを使用してS3に一度出力したものを読み込む。データサイズが大きい(マニュアルには80GBを超える場合と記載)ものに向いている。
概要
本ページは、Glue4.0をもとに整理しています。
Glueでは、ConnectionTypeパラメータを使用して接続タイプを指定します。ConnectionTypeパラメータにより、様々なDataSourceおよび、Sinkに接続が可能になります。
現在のところ、下記のConnectionType(接続先)が可能となっています。詳細はこちらをご確認ください。
| ConnectionType | 接続先 |
|---|---|
| custom.* | Spark、Athena、または JDBC データストア |
| documentdb | Amazon DocumentDB (MongoDB 互換) データベース |
| dynamodb | Amazon DynamoDB データベース |
| kafka | Kafka または Amazon Managed Streaming for Apache Kafka |
| kinesis | Amazon Kinesis Data Streams |
| marketplace.* | Spark、Athena、または JDBC データストア |
| mongodb | MongoDB データベース |
| mysql | MySQL データベース |
| oracle | Oracle データベース |
| orc | Apache Hive Optimized Row Columnar (ORC) ファイル形式で Amazon Simple Storage Service (Amazon S3) に保存されたファイル |
| parquet | Apache Parquet ファイル形式で Amazon S3 に保存されたファイル |
| postgresql | PostgreSQL データベース |
| Redshift | Amazon Redshift データベース |
| s3 | Simple Storage Service (Amazon S3) |
| sqlserver | Microsoft SQL Server データベース |
DynamoDB
本記事は、DynamoDBの接続タイプを元に整理します。
- connectionTypeには、dynamodbを指定します。
- 接続には、下記のとおり、SourceおよびSinkで別れており、さらにSourceでも2つのコネクタが用意されているため、個別に整理します。
- Source
- DynamoDB ETL コネクタ
- DynamoDB エクスポートコネクター
- Sink
- Source
Source>DynamoDB ETL コネクタ
DynamoDB ETL リーダーでは、フィルタまたはプッシュダウン述語は使用できないとのこと。
| パラメータ | 必須 | 設定値 | 説明 |
|---|---|---|---|
| dynamodb.input.tableName | ○ | 読み取り元の DynamoDB テーブル。 | |
| dynamodb.throughput.read.percent | ・デフォルトでは、"0.5" ・許容値は "0.1" から "1.5" |
・使用する読み込みキャパシティーユニット (RCU) の割合。 ・0.5 ではデフォルトの読み込み速度を表し、AWS Glue はテーブルのRCUの半分を消費しようとすることを意味する ・DynamoDB テーブルがオンデマンドモードの場合、AWS Glue はテーブルの読み取り容量を 40000 として処理するとのこと。 大きなテーブルをエクスポートする場合は、DynamoDB テーブルをオンデマンドモードに切り替えることを推奨とのこと。 |
|
| dynamodb.splits | ・デフォルトでは、"1" ・許容値は "1" から "1,000,000" |
・読み取り中にこの DynamoDB テーブルを分割するパーティションの数を定義する。 ・1 は並列処理がないことを意味している。より良いパフォーマンスを得るためには、より大きな値を指定することを強く推奨とのこと。 |
|
| dynamodb.sts.roleArn | ・クロスアカウントアクセスのために引き受ける IAM ロール の ARN。 | ||
| dynamodb.sts.roleSessionName | STS セッション名。デフォルトでは、「glue-dynamodb-read-sts-session」に設定されている。 |
Source>DynamoDB エクスポートコネクター
-
挙動について
- 本コネクターは、DynamoDB ExportTableToPointInTime リクエストを呼び出し、これを指定した Amazon S3 の場所に DynamoDB JSON 形式で保存します。
- そして、Glue は、Amazon S3 のエクスポート場所からデータを読み取ることによって DynamicFrame オブジェクトを作成するとのこと。
-
特徴
- DynamoDB テーブルサイズが 80 GB を超える場合、エクスポートコネクタは ETL コネクタよりもパフォーマンスが向上
- エクスポートリクエストが AWS Glue ジョブで Spark プロセスの外部で実行される場合、AWS Glue ジョブの自動スケーリングを有効にして、エクスポートリクエスト中の DPU 使用量を節約可能。
- エクスポートコネクタでは、Spark エグゼキューターの並列処理のためのスプリット数や、DynamoDB スループットの読み取り率を設定する必要がない。
| パラメータ | 必須 | 設定値 | 説明 |
|---|---|---|---|
| dynamodb.export | ○ | ddb,s3 | ・ddb に設定すると、AWS Glue DynamoDB エクスポートコネクタが有効になり、AWS Glue ジョブ中に新しい ExportTableToPointInTimeRequest が呼び出されるdynamodb.s3.bucket と dynamodb.s3.prefix から渡された場所で新しいエクスポートが生成される。 ・s3 に設定すると、AWS Glue DynamoDB エクスポートコネクタが有効になるが、新しい DynamoDB エクスポートの作成はスキップされ、代わりに dynamodb.s3.bucket と dynamodb.s3.prefix がそのテーブルの過去のエクスポートの Amazon S3 ロケーションとして使用される |
| dynamodb.tableArn | ○ | 読み取り元の DynamoDB テーブルのARN | |
| dynamodb.unnestDDBJson | ブール値 デフォルト値は false に設定 |
true に設定すると、エクスポートに存在する DynamoDB JSON 構造体のネスト解除の変換が実行される。 | |
| dynamodb.s3.bucket | DynamoDB ExportTableToPointInTime プロセスが実行される Simple Storage Service (Amazon S3) バケットの場所を示す | エクスポートファイル形式は DynamoDB JSON。 ・dynamodb.s3.prefixやdynamodb.s3.bucketOwnerなどのオプションもある。 |
|
| dynamodb.sts.roleArn | IAMロールのARN | DynamoDB テーブルのクロスアカウントアクセスおよび/またはクロスリージョンアクセスのために割り当てる IAM ロール の ARN。 | |
| dynamodb.sts.roleSessionName | STS セッション名 デフォルトでは、「glue-dynamodb-read-sts-session」に設定 |
Sink
| パラメータ | 必須 | 設定値 | 説明 |
|---|---|---|---|
| dynamodb.output.tableName | ○ | 書き込み先の DynamoDB テーブル。 | |
| dynamodb.throughput.write.percent | ・使用する書き込みキャパシティーユニット (WCU) の割合。 ・デフォルトでは、"0.5" ・許容値は "0.1" から "1.5" |
0.5 ではデフォルトの読み込み速度を表し、AWS Glue はテーブルの書き込み容量の半分を消費しようとすることを意味する。 上記の値を 0.5 より上に設定すると、AWS Glue は書き込みリクエストレートを増加させ、0.5 より低くした場合はそのリクエストレートを減少 ・DynamoDB テーブルがオンデマンドモードの場合、AWS Glue はテーブルの書き込み容量を 40000 として処理する。大きなテーブルをインポートする場合は、DynamoDB テーブルをオンデマンドモードに切り替えることを推奨。 |
|
| dynamodb.output.numParallelTasks | 同時に DynamoDB に書き込める並列タスクの数 | Spark タスクごとに許容される WCU を計算するために使用。 詳細は、マニュアルを確認してください。 |
|
| dynamodb.output.retry | ・再実行回数 ・デフォルトでは10 |
DynamoDB から ProvisionedThroughputExceededException が送られている場合の、再試行の実行回数を定義。 | |
| dynamodb.sts.roleArn | IAMロールのARN | クロスアカウントアクセスのために引き受ける IAM ロール の ARN。 | |
| dynamodb.sts.roleSessionName | (任意) STS セッション名。デフォルトでは、「glue-dynamodb-write-sts-session」に設定 |
実践
事前準備
DynamoDBの準備
-
DDBのテーブルを2つ(入力と出力)作成します。
-
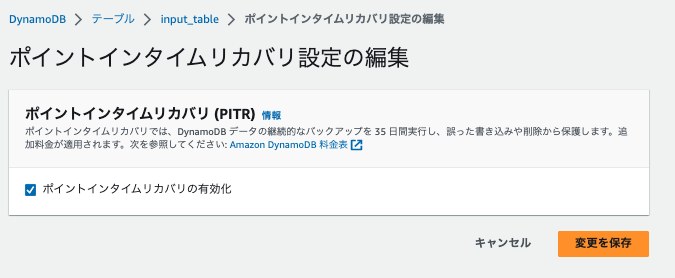
DynamoDB エクスポートコネクターを検証するために、入力側のテーブル(input_table)のPITRを有効にします。
-
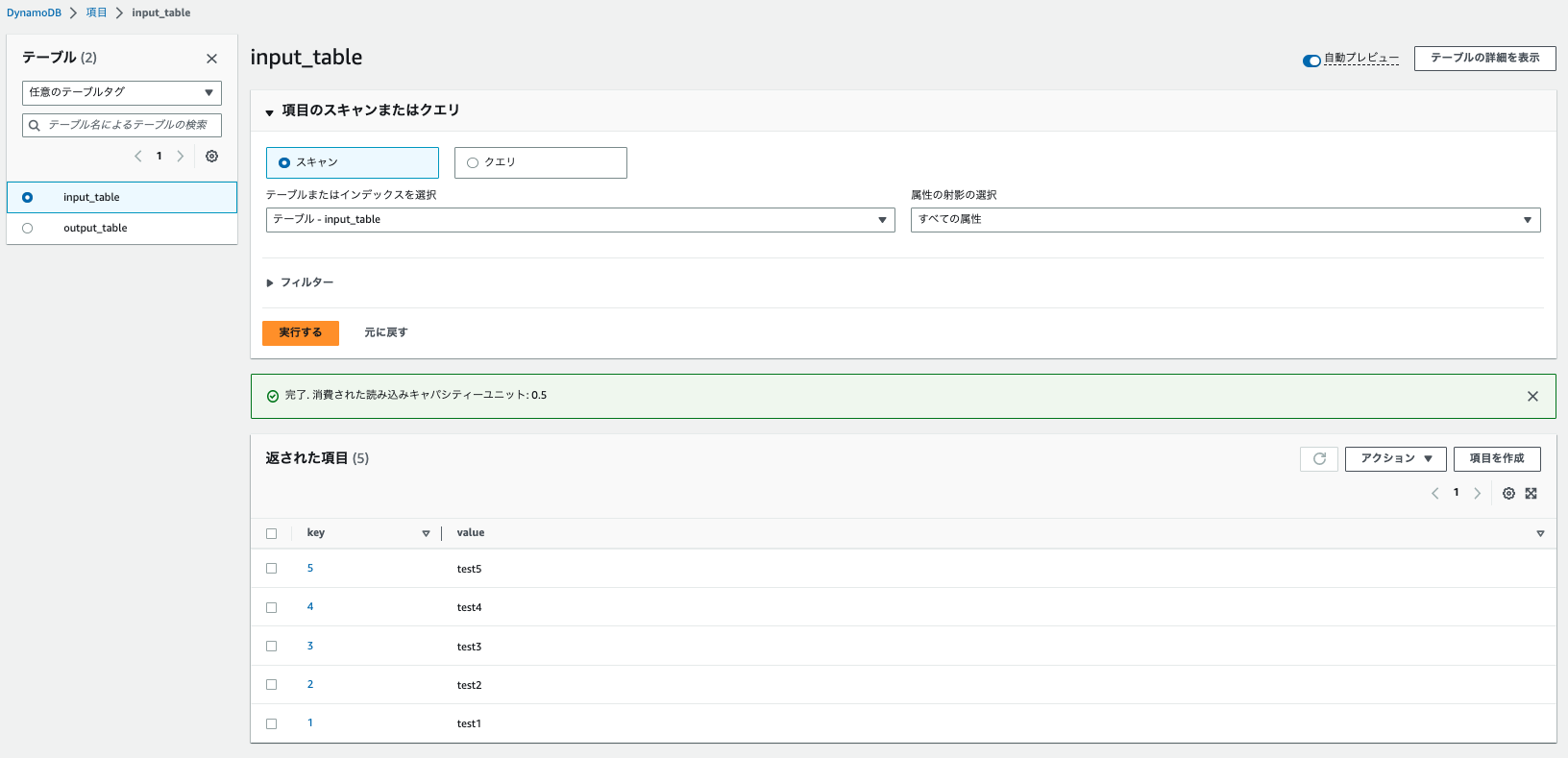
input_tableにデータを用意します。
IAMロールとポリシーの作成
- GlueやS3等に加えて、DynamoDBにアクセスできるようにIAMポリシーを設定します。
Source(DynamoDB ETL コネクタ)->Sink
DynamoDB ETL コネクタを使用したDynamoDBから読み込み、およびSinkへの書き込みを試します。
-
下記のコードを用意します。input_tableから読み込んでoutput_tableに書き込むシンプルなものです。
import sys from awsglue.transforms import * from awsglue.utils import getResolvedOptions from pyspark.context import SparkContext from awsglue.context import GlueContext from awsglue.job import Job args = getResolvedOptions(sys.argv, ["JOB_NAME"]) sc = SparkContext() glueContext = GlueContext(sc) spark = glueContext.spark_session job = Job(glueContext) job.init(args["JOB_NAME"], args) # Script generated for node Amazon DynamoDB AmazonDynamoDB_node1685067515426 = glueContext.create_dynamic_frame.from_options( connection_type="dynamodb", connection_options={ "dynamodb.input.tableName": "input_table", "dynamodb.throughput.read.percent": "1.0", "dynamodb.splits": "2" }, transformation_ctx="AmazonDynamoDB_node1685067515426", ) glueContext.write_dynamic_frame_from_options( frame=AmazonDynamoDB_node1685067515426, connection_type="dynamodb", connection_options={ "dynamodb.output.tableName": "output_table", "dynamodb.throughput.write.percent": "1.0" } ) job.commit() -
実行します。1分弱で終わりました。

-
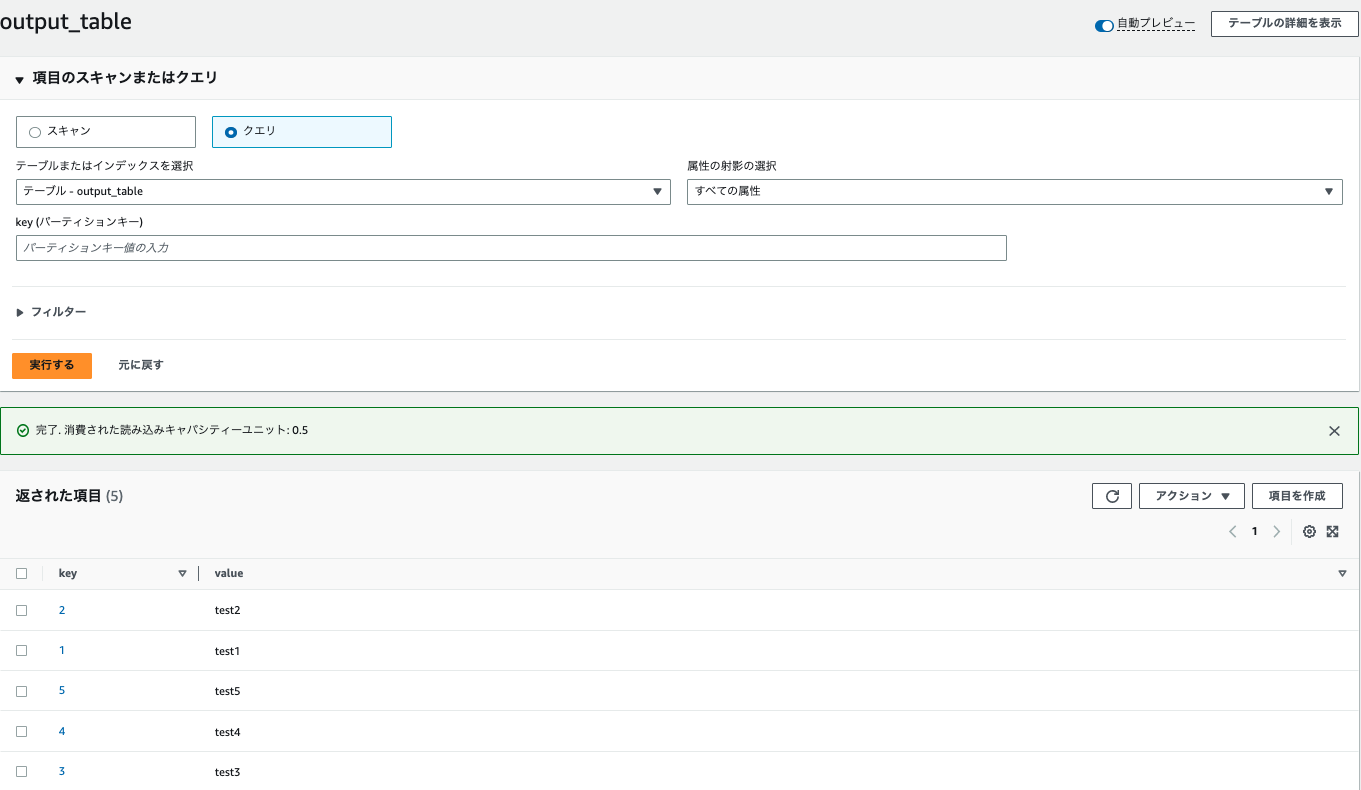
DynamoDBのoutputテーブルにも書かれていました。
Source(DynamoDB エクスポートコネクター)->Sink
DynamoDB ETL エクスポートコネクターを使用したDynamoDBから読み込み、およびSinkへの書き込みを試します。
-
実行前にoutputテーブルの値を削除しておきます。
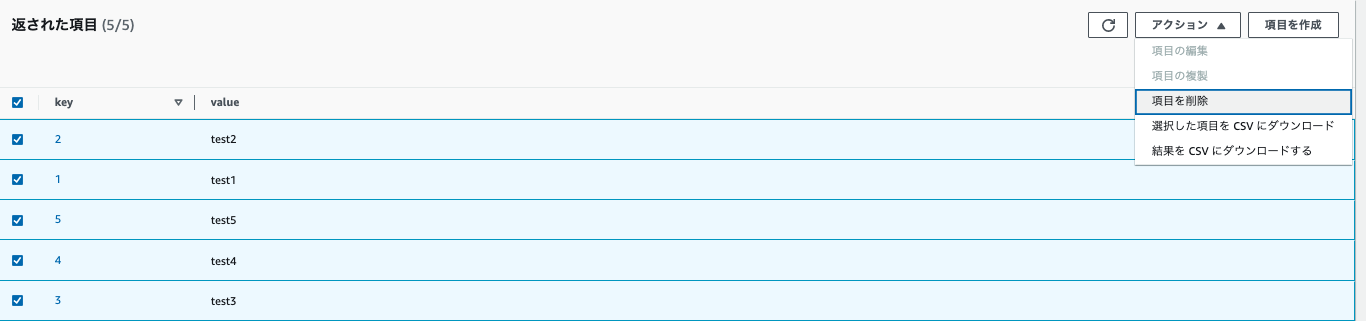
-
下記のコードを用意します。input_tableから読み込んでoutput_tableに書き込むシンプルなものです。
import sys from awsglue.transforms import * from awsglue.utils import getResolvedOptions from pyspark.context import SparkContext from awsglue.context import GlueContext from awsglue.job import Job args = getResolvedOptions(sys.argv, ["JOB_NAME"]) sc = SparkContext() glueContext = GlueContext(sc) spark = glueContext.spark_session job = Job(glueContext) job.init(args["JOB_NAME"], args) # Script generated for node Amazon DynamoDB AmazonDynamoDB_node1685072084094 = glueContext.create_dynamic_frame.from_options( connection_type="dynamodb", connection_options={ "dynamodb.export": "ddb", "dynamodb.s3.bucket": "xxxxxxxxx", "dynamodb.s3.prefix": "temporary/ddbexport/", "dynamodb.tableArn": "arn:aws:dynamodb:region:xxxxxx:table/input_table", "dynamodb.unnestDDBJson": True, }, transformation_ctx="AmazonDynamoDB_node1685072084094", ) glueContext.write_dynamic_frame_from_options( frame=AmazonDynamoDB_node1685072084094, connection_type="dynamodb", connection_options={ "dynamodb.output.tableName": "output_table", "dynamodb.throughput.write.percent": "1.0" } ) job.commit() -
実行します。6分36秒で終わりました。

-
ETLエクスポートコネクタは、一度S3にExportしてからロードするため、S3のファイルを確認してみます。
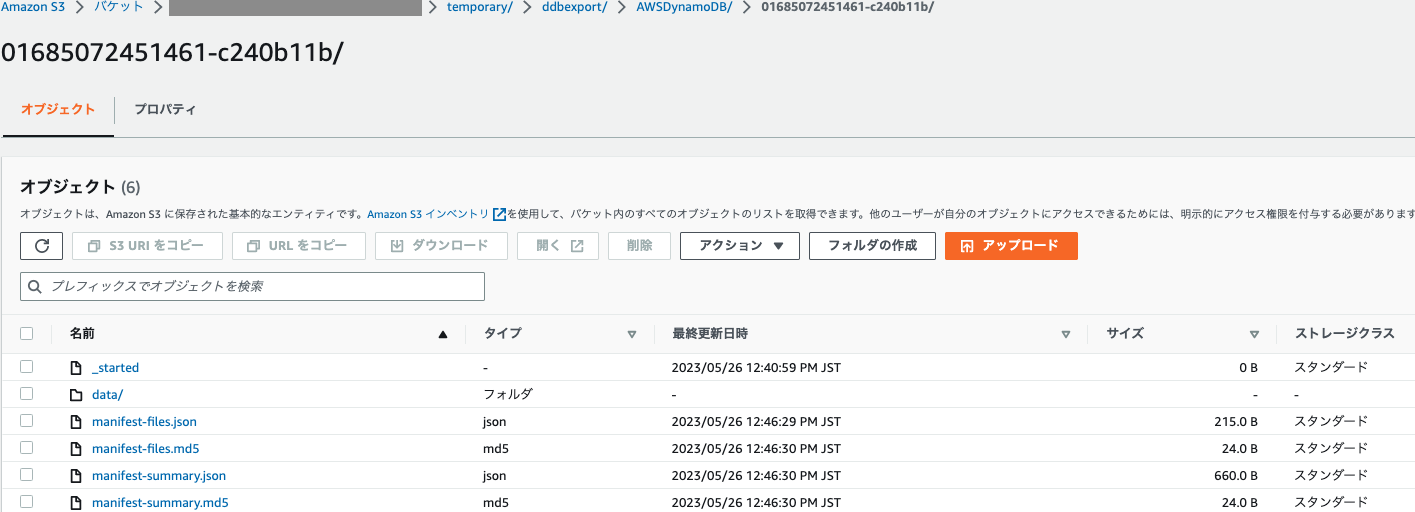
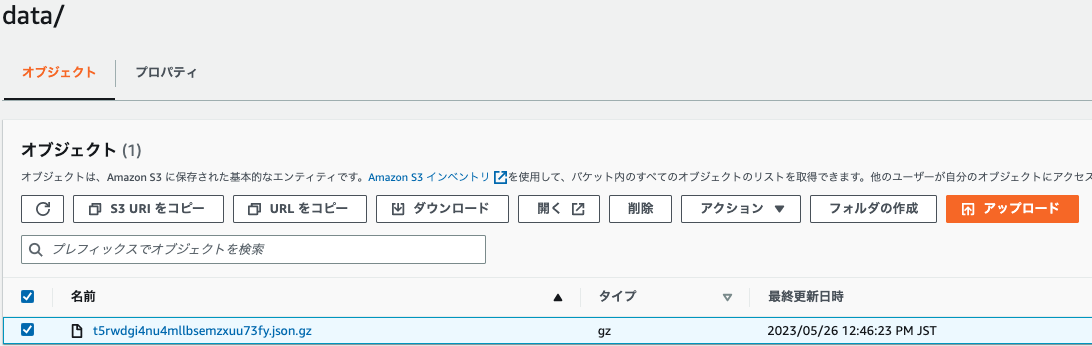
-
下記は、S3 SELECTの結果です。
SELECT * FROM s3object s LIMIT 5 ==== { "Item": { "key": { "S": "5" }, "value": { "S": "test5" } } } { "Item": { "key": { "S": "1" }, "value": { "S": "test1" } } } { "Item": { "key": { "S": "4" }, "value": { "S": "test4" } } } { "Item": { "key": { "S": "2" }, "value": { "S": "test2" } } } { "Item": { "key": { "S": "3" }, "value": { "S": "test3" } } } -
DynamoDBのoutputテーブルにも書かれていました。
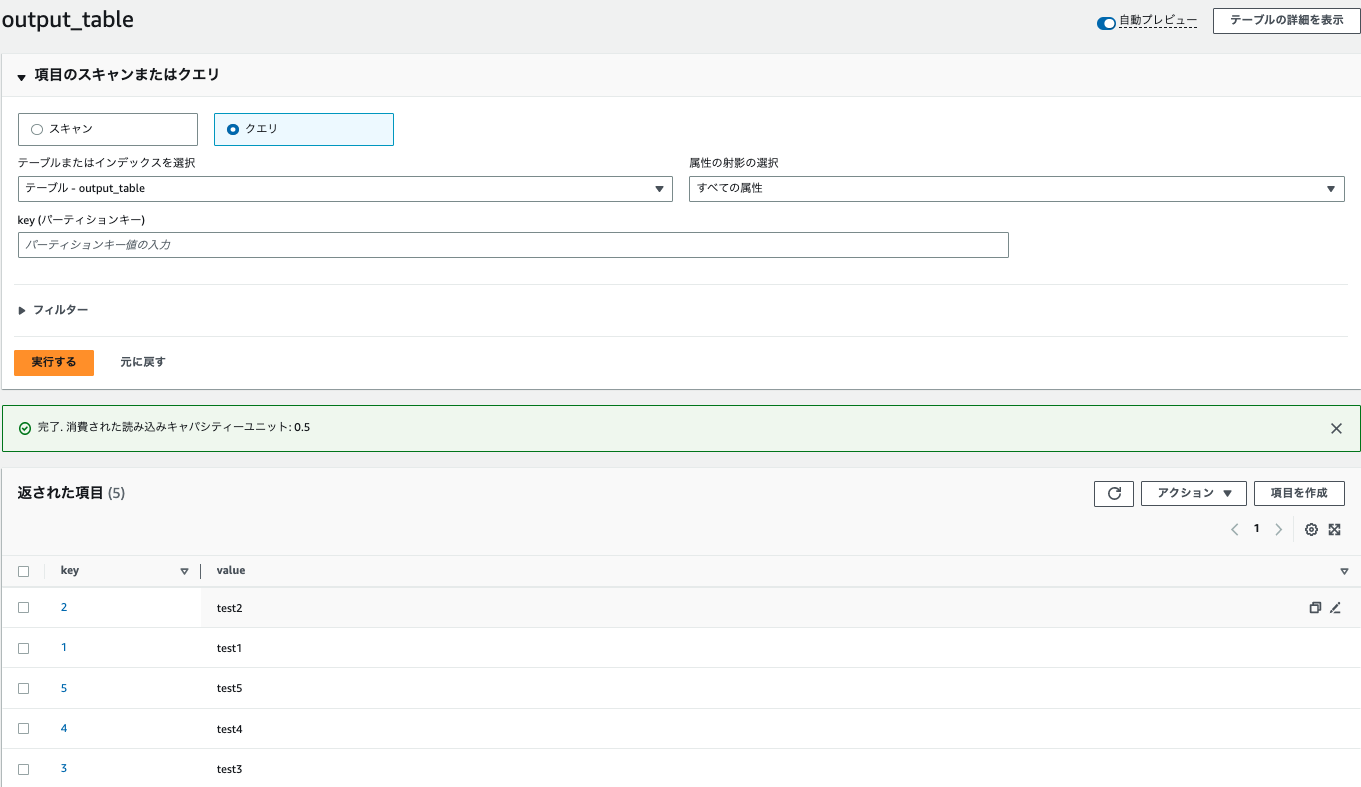
考察
今回は、GlueからのDynamoDBへの読み込みと書き込みを試してみました。
Glueからの読み込みには、ETLコネクタと、Exportコネクタの2種類があります。
Exportコネクタを使用した場合は、DynamoDBのPITRが必要になり、S3に一度出力してから読み込むため、ETLコネクタと比較した場合に実行時間がかかりました。※マニュアルにも80GBを超える場合に、Exportコネクタを使用したほうがパフォーマンスは向上するとのことでした。
今後は、大きいサイズでETLコネクタとExportコネクタで比較してみたいと思います。
参考