背景・目的
Databricksにもサーバレスのサービスがいくつかあります。今回はServerless SQL Warehouse について整理してみます。
まとめ
下記の特徴があります。
| 特徴 | 説明 |
|---|---|
| アカウント | Databricksアカウントに存在する。利用者のコンピュートは利用しない。 |
| 契約 | Premiumプラン以上で使用可能 |
| サポートしているリージョン | ・ap-southeast-2 ・eu-central-1 ・eu-west-1 ・us-west-2 ・us-east-1 ・us-east-2 |
| 再起動のタイミング | ・クエリの実行 ・ジョブの実行(スケジュール) ・JDBC/ODBCから接続 ・クエリをSQLエディタで開く ・保存されたダッシュボードを開く |
| 制限事項 | ・クラスターポリシーはサポートされない ・サーバレスSQLWarehouseにはパブリックIPがない ・EBSストレージに顧客管理のCMKは使用しない |
| アーキテクチャ | ・コントロールプレーンとコンピュートプレーンは、Databricksアカウントで動く。 ・セキュリティレイヤーを使用して、異なるDatabricksの顧客ワークスペースを分離する。 ・パブリックIPがない ・EBSストレージに顧客管理のCMKは使用しない |
概要
Use serverless SQL warehousesを元に整理します。
サーバレス コンピュートでは、コンピュートレイヤーは AWS アカウントではなく Databricks アカウントに存在します。 これにより、アカウント内のユーザーは、フルマネージドの柔軟なコンピュートリソースに即座にアクセスできるようになります。 サーバレス コンピュートは、Databricks SQL での使用がサポートされています。 サーバレス コンピュートは、Databricks Runtime クラスターがノートブックやジョブとどのように連携するかには影響しません。
- Databricksアカウントに存在する。利用者のコンピュートは利用しない。
サーバレス SQLウェア ハウスにはパブリック IP アドレスがありません。 アーキテクチャの詳細については、「 サーバレス コンピュート」を参照してください。
サーバーレスコンピュートと他のDatabricksアーキテクチャの比較
サーバーレスコンピュートと他のDatabricksアーキテクチャの比較を元に整理します。
Databricks は、 コントロール プレーンと コンピュート プレーンで動作します。
- コントロールプレーンには、Databricksが自身のAWSアカウントで管理するバックエンドサービスが含まれています。Databricks SQLクエリー、ノートブックコマンド、およびその他の多くのワークスペースの設定はコントロールプレーンに保存され、保存時に暗号化されます。
- コンピュート・プレーンは、コンピュート・リソースのクラスターによってデータが処理される場所です。
- コントロールプレーンとコンピュート・プレーンの2つがある
従来のコンピュート プレーン (元の Databricks プラットフォーム アーキテクチャ) とサーバレス コンピュート プレーンの間には重要な違いがあります。
- 従来のコンピュートプレーンの場合、Databricks コンピュートリソースは AWS アカウントで実行されます。 クラスターは、クエリー (Databricks SQL の場合) またはノートブック (データサイエンス & エンジニアリングまたは Databricks Machine Learning 環境の場合) を使用して分散データ分析を実行します。
・ 新しいクラスターは、お客様のAWSアカウントの各ワークスペースの仮想ネットワーク内に作成されます。
・ 従来のコンピュートプレーンは、各顧客自身の AWS アカウントで実行されるため、自然に分離されます。
- 従来のコンピュートプレーンは、顧客側のAWSアカウントのVPCで実行される
- サーバレス コンピュート プレーンの場合、Databricks コンピュート リソースは Databricks アカウント内のコンピュート レイヤーで実行されます。
・ サーバレス コンピュート プレーンは、サーバレス SQLウェアハウス と モデルサービング に使用されます。 サーバレス コンピュートを有効にしても、Databricks Runtime クラスターがデータサイエンス & エンジニアリング環境または Databricks Machine Learning 環境でどのように動作するかは変わりません。
・ サーバレス コンピュート プレーン内の顧客データを保護するために、サーバレス コンピュートはワークスペースのネットワーク境界内で実行され、さまざまなセキュリティ レイヤーを使用して、異なる Databricks 顧客ワークスペースを分離し、同じ顧客のクラスター間で追加のネットワーク制御を行います。
- Databricksアカウント内のコンピュートレイヤで実行される。
- サーバレスコンピュートプレーンは、WorkspaceのNW境界内で実行され、セキュリティレイヤーを使用して、異なるDatabricksの顧客ワークスペースを分離する。
Databricks は、ワークスペースのクラシック コンピュート プレーンと同じ AWS リージョンにサーバレス コンピュート プレーンを作成します。
ワーカーノードはプライベートです。つまり、パブリックIPアドレスを持ちません。
Databricks コントロールプレーンとサーバレス コンピュートプレーン間の通信の場合:
- Databricks SQL Serverlessの場合、通信にはプライベート接続が使用されます。
- モデルサービングの場合、通信にはmTLS暗号化通信が使用されます。コントロールプレーンから接続が開始され、アクセスはコントロールプレーンIPアドレスに制限されます。
- AWSリージョンにサーバレスコンピュートプレーンを作成する
- ワーカーノードはパブリックIPを持たない
- Databricks通信にはプライベート接続
- モデルサービングでは、mTLS暗号化通信が使用される
ワークスペースと同じリージョンにあるAWS S3バケットに対して読み取りまたは書き込みを行う場合、サーバーレスSQLウェアハウスはAWSゲートウェイエンドポイントを使用してS3に直接アクセスするようになりました。これは、サーバーレスSQLウェアハウスがお客様のAWSアカウント内のワークスペースのルートS3バケットに対して読み取りまたは書き込みを行う場合と、同じリージョン内の他のS3データソースに対して読み取りまたは書き込みを行う場合に適用されます。
- サーバレスは、S3のVPCeを介してS3に直接アクセスできる
要件
アカウント要件
- Databricks アカウントは、プラットフォームの E2 バージョン上にある必要があります。
- Databricks アカウントはフリートライアルにあってはなりません。
- 2022 年 3 月 28 日より前に作成されたアカウントは、更新された 利用規約に同意する必要があります。
ワークスペースの要件
- Databricks ワークスペースは、 Premium プラン以上である必要があります。
- ワークスペースは、 Databricks SQL サーバレスをサポートするリージョンに存在する必要があります。
- ワークスペースでは、 外部の Hive レガシ メタストアを使用しないでください。 ただし、ワークスペースでは、 AWS Glue をワークスペースのレガシーメタストアとして使用できます。
- ワークスペースで S3 アクセスポリシーを使用しないでください。
-
Premiumプラン以上で使用可能
-
SQLサーバレスをサポートしているリージョンのみ利用可能
- 2023/12/31現在で下記のリージョンでサポートされている
- ap-southeast-2
- eu-central-1
- eu-west-1
- us-west-2
- us-east-1
- us-east-2
- 2023/12/31現在で下記のリージョンでサポートされている
-
Hive metastoreは使用しないこと
-
S3アクセスポリシーを使用しない
サーバレス SQLウェアハウスは、一部のリージョンでコンプライアンスセキュリティプロファイルをサポートしています
- この機能は パブリックプレビュー版です。
コンプライアンス・セキュリティ・プロファイルを使用したサーバレス SQLウェアハウスのサポートは、リージョンによって異なります。リージョン ページの サーバレス SQLウェアハウス の列で、サポートされているコンプライアンス セキュリティ プロファイルを探します。
これらのリージョンでは、サーバレスウェアハウスはコンプライアンスセキュリティプロファイルが有効になっているワークスペースをサポートします。 強化されたイメージ、暗号化されたノード間通信、ウイルス対策モニター、ファイル整合性モニター、および長時間実行されるサーバレス SQLウェアハウスの自動再起動があります。
これらのリージョン以外では、ワークスペースでコンプライアンス セキュリティ プロファイルが有効になっている場合、Databricks ではサーバレス SQLウェアハウスの起動が許可されません。
サーバレス SQLウェアハウスの自動再起動
サーバレス SQLウェアハウスは、次の条件で自動的に再起動します。
- 停止したウェアハウスを使用するクエリーを実行しようとしました。
- 停止したウェアハウスに割り当てられたジョブの実行がスケジュールされています。
- 停止したウェアハウスには、JDBC/ODBC インターフェースから接続します。
- 停止したウェアハウスに保存されているクエリーを SQL エディターで開きます。
- ダッシュボード レベルのウェアハウスが割り当てられた状態で保存されたダッシュボードが開きます。
自動的に再起動するタイミング
- クエリの実行
- ジョブの実行(スケジュール)
- JDBC/ODBCから接続
- クエリをSQLエディタで開く
- 保存されたダッシュボードを開く
制限事項
サーバレス ウェアハウスには、次の制限があります。
- クラスターポリシー (スポットインスタンスポリシーを含む ) はサポートされていません。
- 顧客管理VPC は、サーバレス SQLウェアハウスのコンピュートリソースには適用されません。
- 従来のコンピュートプレーンで AWS PrivateLink 接続を有効にしているかどうかに関係なく、サーバレス SQLウェアハウスは、ほぼすべてのケースで Databricks コントロールプレーンとサーバレスコンピュートプレーン間のプライベート接続を使用します。一部のレガシ us-east1 リージョン ワークスペースでは、代替のセキュリティで保護されたネットワーク接続が使用されます。
- サーバレス コンピュートプレーンは、 従来のコンピュートプレーンのセキュアクラスタ接続リレーを使用しませんが、サーバレス SQLウェア ハウスにはパブリック IP アドレスがありません。
- サーバレス SQLウェアハウスは、 ワークスペースストレージ機能構成の顧客管理キー のオプション部分である EBS ストレージ暗号化に顧客管理キーを使用しません。 サーバレス コンピュートリソースのディスクは存続期間が短く、サーバレスワークロードのライフサイクルに関連付けられています。 たとえば、サーバレス SQLウェアハウスが停止またはスケールダウンされると、VM とそのストレージが破棄されます。 「サーバレス コンピュート」および「顧客管理キー」を参照してください。
- クラスターポリシーはサポートされない
- サーバレスSQLWarehouseにはパブリックIPがない
- EBSストレージに顧客管理のCMKは使用しない
料金
Databricks SQLの料金は、$0.70/DBUです。
実践
Serverless SQL Warehouseの作成
-
ワークスペースにサインインします。
-
ナビゲーションペインで「Compute」をクリックします。
-
①「SQL warehouse」タブをクリックし、②「Create SQL warehouse」をクリックします。

-
Typeに「Serverless」を選択し、「Create」をクリックします。
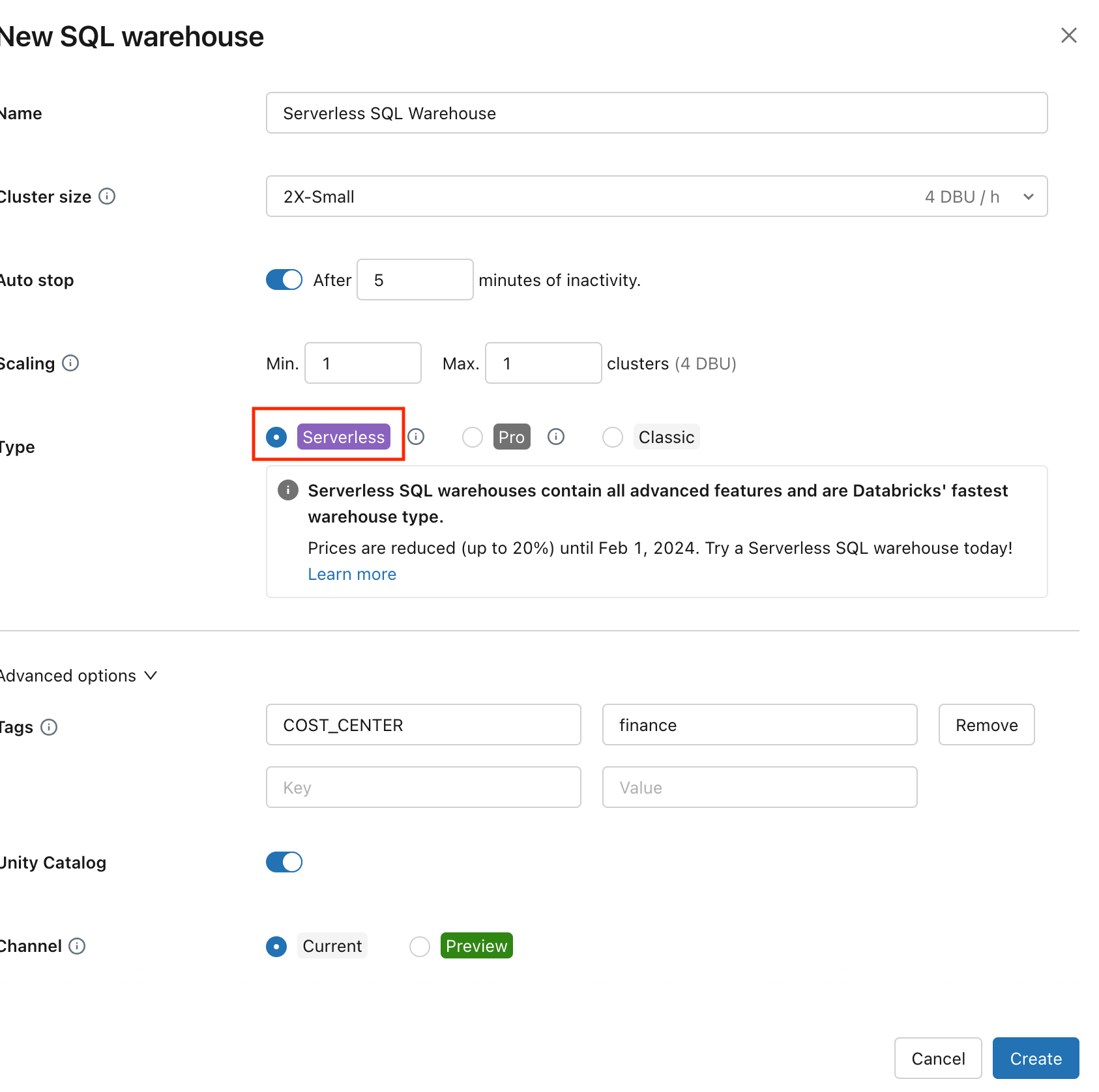
-
ポップアップが表示されます。
-
作成されました。

-
AWSには、コンピュートプレーンは作成されていません。

SQLの実行
- ナビゲーションペインで「SQL Editor」をクリックします。
- 作成した、Serverlessを選択します。

- 下記のクエリを実行します。
-- 顧客ごとの金額 SELECT customers.customer_id,amount FROM test.retail.customers customers LEFT OUTER JOIN ( SELECT customer_id,SUM(products.price * details.quantity) AS amount FROM test.retail.orders orders ,test.retail.order_details details ,test.retail.products products WHERE orders.order_id= details.order_id AND products.product_id = details.product_id GROUP BY customer_id ) tmp ON customers.customer_id=tmp.customer_id - 結果は下記のとおりです。

停止状態からの実行
-
Serverlessを停止します。下記の状態になりました。

-
下記のクエリを実行し、すぐに完了しました。
SELECT customers.customer_id,amount FROM test.retail.customers customers LEFT OUTER JOIN ( SELECT customer_id,SUM(products.price * details.quantity) AS amount FROM test.retail.orders orders ,test.retail.order_details details ,test.retail.products products WHERE orders.order_id= details.order_id AND products.product_id = details.product_id GROUP BY customer_id ) tmp ON customers.customer_id=tmp.customer_id
-
クラスタは起動されました。

停止を確認
5分間操作がなかった場合に自動停止するよう、Servlerssを設定したので確認します。
- 停止されました。

考察
今回、Servrless SQL Warehouseを試してみました。従来のManagedと比べて、起動が早い点と停止までの時間が短い(最短10分から5分)のが良いですね。コストに効きそうです。
使い方は、ある程度トラフィックが多い日中帯は従来型、夜間のクエリはServerlessなどが良いのではないかと思います。
参考